Recognition: 2 theorem links
· Lean TheoremTask-Aware Calibration: Provably Optimal Decoding in LLMs
Pith reviewed 2026-05-12 02:52 UTC · model grok-4.3
The pith
Task calibration in latent output spaces makes Minimum Bayes Risk decoding provably optimal for LLM beliefs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Task calibration adjusts the model's predictive probabilities in the task-induced latent space so that Minimum Bayes Risk decoding on the resulting distribution becomes the optimal decoding rule with respect to the latent model beliefs, by direct application of a known decision-theoretic optimality result.
What carries the argument
Task calibration, which maps free-form LLM outputs to a semantically meaningful latent structure (discrete labels, integers, or sets) and calibrates the predictive distribution there, allowing MBR decoding to achieve optimality on model beliefs.
If this is right
- Generation quality improves consistently across tasks and existing decoding baselines when MBR is applied to the task-calibrated latent distribution.
- Task Calibration Error provides a direct, application-aware measure of how much loss is attributable to miscalibration.
- Model decisions become more reliable on tasks whose outputs admit a discrete or set-based latent representation without requiring retraining.
- The optimality guarantee holds relative to the model's latent beliefs once calibration in that space is achieved.
Where Pith is reading between the lines
- The same latent-calibration step could be tested on tasks whose outputs are naturally continuous or structured, such as code snippets or ranked lists, to check whether the optimality result extends.
- If the latent mapping itself can be learned from data rather than hand-specified, the method might apply to a wider range of open-ended generation problems.
- The framework suggests a general post-processing route for extracting calibrated decisions from any generative model whose outputs admit a task-relevant latent encoding.
Load-bearing premise
Free-form LLM outputs can be reliably interpreted through a semantically meaningful latent structure in which calibration is well-posed and the decision-theoretic optimality result applies without further qualification.
What would settle it
A controlled experiment on a task with an unambiguous latent structure (for example, integer answers to arithmetic questions) in which MBR decoding on the task-calibrated distribution fails to outperform standard decoding or other calibration baselines.
Figures










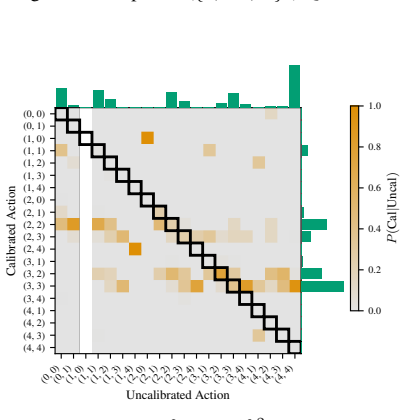
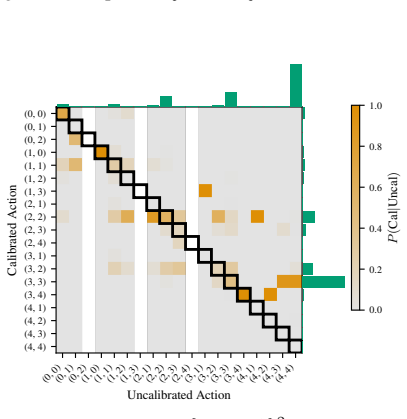

read the original abstract
LLM decoding often relies on the model's predictive distribution to generate an output. Consequently, misalignment with respect to the true generating distribution leads to suboptimal decisions in practice. While a natural solution is to calibrate the model's output distribution, for LLMs, this is ill-posed at the combinatorially vast level of free-form language. We address this by building on the insight that in many tasks, these free-form outputs can be interpreted in a semantically meaningful latent structure, for example, discrete class labels, integers, or sets. We introduce task calibration as a paradigm to calibrate the model's predictive distribution in the task-induced latent space. We apply a decision-theoretic result to show that Minimum Bayes Risk (MBR) decoding on the task-calibrated latent distribution is the optimal decoding strategy on latent model beliefs. Empirically, it consistently improves generation quality across different tasks and baselines. We also introduce Task Calibration Error (TCE), an application-aware calibration metric that quantifies the excess loss due to miscalibration. Our work demonstrates that task calibration enables more reliable model decisions across various tasks and applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes task calibration as a method to calibrate LLM predictive distributions in a task-induced latent space (e.g., discrete labels or sets) rather than the full token space. It applies a decision-theoretic result to argue that Minimum Bayes Risk (MBR) decoding on the task-calibrated latent distribution is provably optimal with respect to latent model beliefs. The authors introduce Task Calibration Error (TCE) as an application-aware metric for excess loss due to miscalibration and report empirical gains in generation quality across tasks and baselines.
Significance. If the optimality result is established without unaccounted approximation error in the latent mapping, the work provides a principled bridge between decision theory and LLM decoding for structured tasks. This could improve reliability in applications where outputs map to semantically meaningful latents. The TCE metric offers a practical tool for evaluating calibration beyond standard probability metrics. Empirical improvements are noted but their strength depends on controls for the latent mapping and baselines.
major comments (2)
- [theoretical development / optimality proof] The central optimality claim (abstract and theoretical development) applies a standard decision-theoretic fact (MBR optimality under a known distribution) to the task-calibrated latent distribution. However, this requires the latent distribution to be exactly the push-forward measure induced by a deterministic, surjective mapping from token sequences to latents. The manuscript should explicitly define this mapping and the induced marginal in the relevant theoretical section (likely §3 or §4) and confirm it is obtained without sampling approximations or top-k truncation; otherwise an error term must be derived to preserve the 'provably optimal' statement.
- [task calibration definition] Definition and computation of the task-calibrated distribution: if the calibration step itself relies on an estimator (e.g., sampling or auxiliary model) rather than the exact marginal, the optimality guarantee does not transfer directly. The paper must state whether the calibrated distribution is the exact push-forward or an approximation, and quantify any resulting sub-optimality gap.
minor comments (2)
- [notation / preliminaries] Clarify notation for the latent space and the mapping function; ensure consistent use of symbols for the token-level measure versus the induced latent measure.
- [experiments] In the experimental section, provide more detail on how the latent structures are extracted from free-form outputs for each task (e.g., parsing rules for sets or integers) to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which highlight important aspects of the theoretical development that we will clarify in the revision. We address each major comment below.
read point-by-point responses
-
Referee: The central optimality claim (abstract and theoretical development) applies a standard decision-theoretic fact (MBR optimality under a known distribution) to the task-calibrated latent distribution. However, this requires the latent distribution to be exactly the push-forward measure induced by a deterministic, surjective mapping from token sequences to latents. The manuscript should explicitly define this mapping and the induced marginal in the relevant theoretical section (likely §3 or §4) and confirm it is obtained without sampling approximations or top-k truncation; otherwise an error term must be derived to preserve the 'provably optimal' statement.
Authors: We agree that the optimality result is stated with respect to the exact push-forward measure. In §3 we define the latent mapping as a deterministic, surjective function from token sequences to the task-induced latent space (e.g., label extraction for classification or set parsing for structured outputs). The MBR optimality then holds exactly for the induced marginal over latents, which encodes the model's calibrated beliefs. We will add an explicit statement of this definition and the induced measure in the revised theoretical section. For the empirical results we will note that Monte Carlo sampling is used to estimate the marginal and will include a brief error analysis (via concentration bounds) in the appendix to quantify the gap from the exact case, thereby preserving the 'provably optimal' claim for the idealized distribution. revision: yes
-
Referee: Definition and computation of the task-calibrated distribution: if the calibration step itself relies on an estimator (e.g., sampling or auxiliary model) rather than the exact marginal, the optimality guarantee does not transfer directly. The paper must state whether the calibrated distribution is the exact push-forward or an approximation, and quantify any resulting sub-optimality gap.
Authors: Task calibration is defined as the exact marginal obtained by pushing the model's token-level predictive distribution forward through the deterministic latent mapping. The optimality guarantee therefore applies directly to this exact marginal. In practice the marginal is estimated by sampling; we will revise the definition paragraph to distinguish the exact quantity from its estimator and will derive a simple bound on the excess risk incurred by finite-sample estimation (using standard concentration inequalities). This makes the sub-optimality gap explicit while keeping the core claim intact for the exact calibrated distribution. revision: yes
Circularity Check
No circularity: optimality imported from external decision theory
full rationale
The paper defines task calibration on a latent structure induced by free-form outputs and then invokes a standard decision-theoretic result (MBR optimality under a known distribution and loss) to conclude that MBR on the calibrated latent distribution is optimal. This step does not reduce by construction to any fitted parameter, self-defined quantity, or prior self-citation within the paper; the optimality statement is an application of an independent external theorem to the newly defined object. No equations or claims in the abstract or description exhibit self-definition, renaming of known results, or load-bearing self-citation chains. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math A decision-theoretic result establishing optimality of MBR decoding under calibrated beliefs
invented entities (1)
-
Task Calibration Error (TCE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We apply a decision-theoretic result to show that Minimum Bayes Risk (MBR) decoding on the task-calibrated latent distribution is the optimal decoding strategy on latent model beliefs.
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Definition 3.1. An LLM’s latent push-forward distribution p̂ is (distributionally) task-calibrated … EX,Y[gT(Y)|p̂(X)=q]=q.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Linguistic calibration of long-form generations, 2024
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form generations, 2024. URLhttps://arxiv.org/abs/2404.00474
-
[2]
Semeval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation
Daniel Cer, Mona Diab, Eneko Agirre, Inigo Lopez-Gazpio, and Lucia Specia. Semeval- 2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017), pages 1–14, 2017
work page 2017
-
[3]
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.arXiv preprint arXiv:2502.11028, 2025
-
[4]
The comparison and evaluation of forecasters
Morris H DeGroot and Stephen E Fienberg. The comparison and evaluation of forecasters. Journal of the Royal Statistical Society: Series D (The Statistician), 32(1-2):12–22, 1983
work page 1983
-
[5]
Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf, 2023
Yi Dong, Zhilin Wang, Makesh Narsimhan Sreedhar, Xianchao Wu, and Oleksii Kuchaiev. Steerlm: Attribute conditioned sft as an (user-steerable) alternative to rlhf, 2023
work page 2023
-
[6]
Cynthia Dwork, Michael P Kim, Omer Reingold, Guy N Rothblum, and Gal Yona. Outcome indistinguishability. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, 2021
work page 2021
-
[7]
Sampling-based approximations to minimum Bayes risk decoding for neural machine translation
Bryan Eikema and Wilker Aziz. Sampling-based approximations to minimum Bayes risk decoding for neural machine translation. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Lan- guage Processing, pages 10978–10993, Abu Dhabi, United Arab Emirates, December 2022. Association for C...
-
[8]
Hierarchical neural story generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018
work page 2018
-
[9]
Beam search strategies for neural machine translation
Markus Freitag and Yaser Al-Onaizan. Beam search strategies for neural machine translation. InProceedings of the First Workshop on Neural Machine Translation, pages 56–60, 2017
work page 2017
-
[10]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. Bias and fairness in large language models: A survey.Computational linguistics, 50(3):1097–1179, 2024
work page 2024
-
[11]
Gemma 3 technical report, 2025
Gemma Team. Gemma 3 technical report, 2025. URL https://arxiv.org/abs/2503. 19786
work page 2025
-
[12]
Safe probability.Journal of Statistical Planning and Inference, 2018
Peter Grünwald. Safe probability.Journal of Statistical Planning and Inference, 2018
work page 2018
-
[13]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge, 2025. URL https://arxiv.org/abs/ 2411.15594
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InInternational conference on machine learning, pages 1321–1330. PMLR, 2017. 10
work page 2017
-
[15]
Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge, 2026
Lukas Haas, Gal Yona, Giovanni D’Antonio, Sasha Goldshtein, and Dipanjan Das. Simpleqa verified: A reliable factuality benchmark to measure parametric knowledge, 2026. URL https://arxiv.org/abs/2509.07968
-
[16]
Wataru Hashimoto, Hidetaka Kamigaito, and Taro Watanabe. Decoding uncertainty: The impact of decoding strategies for uncertainty estimation in large language models. InFindings of the Association for Computational Linguistics, 2025
work page 2025
-
[17]
Deberta: Decoding-enhanced bert with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention. InInternational Conference on Learning Representations,
-
[18]
URLhttps://openreview.net/forum?id=XPZIaotutsD
-
[19]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https: //arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [20]
-
[21]
Calibrating long-form generations from large language models, 2024
Yukun Huang, Yixin Liu, Raghuveer Thirukovalluru, Arman Cohan, and Bhuwan Dhingra. Calibrating long-form generations from large language models, 2024. URL https://arxiv. org/abs/2402.06544
-
[22]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension, 2017. URL https://arxiv. org/abs/1705.03551
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation, 2023. URL https://arxiv.org/ abs/2302.09664
work page internal anchor Pith review arXiv 2023
-
[25]
Meelis Kull and Peter Flach. Novel decompositions of proper scoring rules for classification: Score adjustment as precursor to calibration. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 68–85. Springer, 2015
work page 2015
-
[26]
Meelis Kull, Miquel Perello Nieto, Markus Kängsepp, Telmo Silva Filho, Hao Song, and Peter Flach. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration.Advances in neural information processing systems, 32, 2019
work page 2019
-
[27]
How to correctly report llm-as-a-judge evaluations, 2026
Chungpa Lee, Thomas Zeng, Jongwon Jeong, Jy yong Sohn, and Kangwook Lee. How to correctly report llm-as-a-judge evaluations, 2026. URL https://arxiv.org/abs/2511. 21140
work page 2026
-
[28]
Large language models are miscalibrated in-context learners
Chengzu Li, Han Zhou, Goran Glavaš, Anna Korhonen, and Ivan Vuli ´c. Large language models are miscalibrated in-context learners. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11575–11596, 2025
work page 2025
-
[29]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), 2023
work page 2023
-
[30]
Conftuner: Training large language models to express their confidence verbally, 2025
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally, 2025. URLhttps://arxiv.org/abs/2508.18847. 11
-
[31]
arXiv preprint arXiv:2403.04182 (2024)
Michal Lukasik, Harikrishna Narasimhan, Aditya Krishna Menon, Felix Yu, and Sanjiv Kumar. Regression-aware inference with llms, 2024. URLhttps://arxiv.org/abs/2403.04182
-
[32]
Revisiting the calibration of modern neural networks
Matthias Minderer, Josip Djolonga, Rob Romijnders, Frances Hubis, Xiaohua Zhai, Neil Houlsby, Dustin Tran, and Mario Lucic. Revisiting the calibration of modern neural networks. Advances in neural information processing systems, 34:15682–15694, 2021
work page 2021
-
[33]
Understanding the properties of minimum Bayes risk decoding in neural machine translation
Mathias Müller and Rico Sennrich. Understanding the properties of minimum Bayes risk decoding in neural machine translation. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (...
-
[34]
Is there a {object} in the image?
Preetum Nakkiran, Arwen Bradley, Adam Goli´nski, Eugene Ndiaye, Michael Kirchhof, and Sinead Williamson. Trained on tokens, calibrated on concepts: The emergence of semantic calibration in llms, 2025. URLhttps://arxiv.org/abs/2511.04869
-
[35]
Measuring calibration in deep learning
Jeremy Nixon, Michael W Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. Measuring calibration in deep learning. InCVPR workshops, volume 2, 2019
work page 2019
-
[36]
Calibration for decision making: A principled ap- proach to trustworthy ml, 2024
Georgy Noarov and Aaron Roth. Calibration for decision making: A principled ap- proach to trustworthy ml, 2024. URL https://www.let-all.com/blog/2024/03/13/ calibration-for-decision-making-a-principled-approach-to-trustworthy-ml/
work page 2024
-
[37]
Maja Pavlovic. Understanding model calibration - a gentle introduction and visual ex- ploration of calibration and the expected calibration error (ece). InICLR Blogposts 2025, 2025. URL https://iclr-blogposts.github.io/2025/blog/calibration/. https://iclr-blogposts.github.io/2025/blog/calibration/
work page 2025
-
[38]
John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
work page 1999
-
[39]
arXiv preprint arXiv:2402.13213 , year=
Benjamin Plaut, Nguyen X. Khanh, and Tu Trinh. Probabilities of chat llms are miscalibrated but still predict correctness on multiple-choice q&a, 2025. URL https://arxiv.org/abs/ 2402.13213
- [40]
-
[41]
Qwen Team. Qwen3 technical report, 2025. URLhttps://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
When2Call: When (not) to call tools
Hayley Ross, Ameya Sunil Mahabaleshwarkar, and Yoshi Suhara. When2Call: When (not) to call tools. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 3391–3409, Albuquerque, ...
-
[43]
A thorough examination of decoding methods in the era of llms
Chufan Shi, Haoran Yang, Deng Cai, Zhisong Zhang, Yifan Wang, Yujiu Yang, and Wai Lam. A thorough examination of decoding methods in the era of llms. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8601–8629, 2024
work page 2024
-
[44]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush V osoughi. Judging the judges: A systematic study of position bias in LLM-as-a-judge. In Kentaro Inui, Sakriani Sakti, Haofen Wang, Derek F. Wong, Pushpak Bhattacharyya, Biplab Banerjee, Asif Ekbal, Tanmoy Chakraborty, and Dhirendra Pratap Singh, editors,Proceedings of the 14th Inter...
-
[45]
Therneau and Elizabeth Atkinson
Terry M. Therneau and Elizabeth Atkinson. Concordance. Vignette of the survival R pack- age, December 2024. URL https://cran.r-project.org/web/packages/survival/ vignettes/concordance.pdf. Accessed: 2025-08-29
work page 2024
-
[46]
Task-awareness improves llm generations and uncertainty, 2026
Tim Tomov, Dominik Fuchsgruber, and Stephan Günnemann. Task-awareness improves llm generations and uncertainty, 2026. URLhttps://arxiv.org/abs/2601.21500
-
[47]
Evaluating model calibration in classification
Juozas Vaicenavicius, David Widmann, Carl Andersson, Fredrik Lindsten, Jacob Roll, and Thomas Schön. Evaluating model calibration in classification. InInternational conference on artificial intelligence and statistics, 2019
work page 2019
-
[48]
Helpsteer: Multi-attribute helpfulness dataset for steerlm, 2023
Zhilin Wang, Yi Dong, Jiaqi Zeng, Virginia Adams, Makesh Narsimhan Sreedhar, Daniel Egert, Olivier Delalleau, Jane Polak Scowcroft, Neel Kant, Aidan Swope, and Oleksii Kuchaiev. Helpsteer: Multi-attribute helpfulness dataset for steerlm, 2023
work page 2023
-
[49]
Gustafsson, Edward Phillips, Boyan Gao, Anshul Thakur, and David A
Sean Wu, Fredrik K. Gustafsson, Edward Phillips, Boyan Gao, Anshul Thakur, and David A. Clifton. Bas: A decision-theoretic approach to evaluating large language model confidence,
-
[50]
URLhttps://arxiv.org/abs/2604.03216
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
What (and what not) are calibrated probabilities actually use- ful for? InICLR Blogposts 2026, 2026
Guoxuan Xia. What (and what not) are calibrated probabilities actually use- ful for? InICLR Blogposts 2026, 2026. URL https://iclr-blogposts. github.io/2026/blog/2026/useful-calibrated-uncertainties/. https://iclr- blogposts.github.io/2026/blog/2026/useful-calibrated-uncertainties/
work page 2026
-
[52]
Calibrating language models with adaptive temperature scaling
Johnathan Xie, Annie S Chen, Yoonho Lee, Eric Mitchell, and Chelsea Finn. Calibrating language models with adaptive temperature scaling. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18128–18138, Miami, Florida, USA, November 2024. Association for...
-
[53]
Maqa: Evaluating uncertainty quantification in llms regarding data uncertainty, 2025
Yongjin Yang, Haneul Yoo, and Hwaran Lee. Maqa: Evaluating uncertainty quantification in llms regarding data uncertainty, 2025. URLhttps://arxiv.org/abs/2408.06816
-
[54]
Atomic calibration of llms in long-form generations, 2025
Caiqi Zhang, Ruihan Yang, Zhisong Zhang, Xinting Huang, Sen Yang, Dong Yu, and Nigel Collier. Atomic calibration of llms in long-form generations, 2025. URL https://arxiv. org/abs/2410.13246
-
[55]
Shengjia Zhao, Michael P. Kim, Roshni Sahoo, Tengyu Ma, and Stefano Ermon. Calibrating predictions to decisions: A novel approach to multi-class calibration, 2021. URL https: //arxiv.org/abs/2107.05719. 13 A Impact Statement In this work, we examine how calibration can improve the generation performance of Large Language Models. While any research may be ...
-
[56]
The value of the resulting score can be interpreted analogously to the traditional Area-under-the-Precision-Recall-Curve (AUC-ROC) metrics, with 0.5 corresponding to random chance and 1 to perfect ranking ability. In our case, we evaluate the Bayes risk (Equation (2) like Tomov et al. [45] as a proxy for per-instance uncertainty and measure how well it pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.