SleepWalk: A Three-Tier Benchmark for Stress-Testing Instruction-Guided Vision-Language Navigation
Pith reviewed 2026-05-12 04:23 UTC · model grok-4.3
The pith
SleepWalk benchmark shows current vision-language models systematically fail at grounded spatial reasoning for instructions in 3D scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
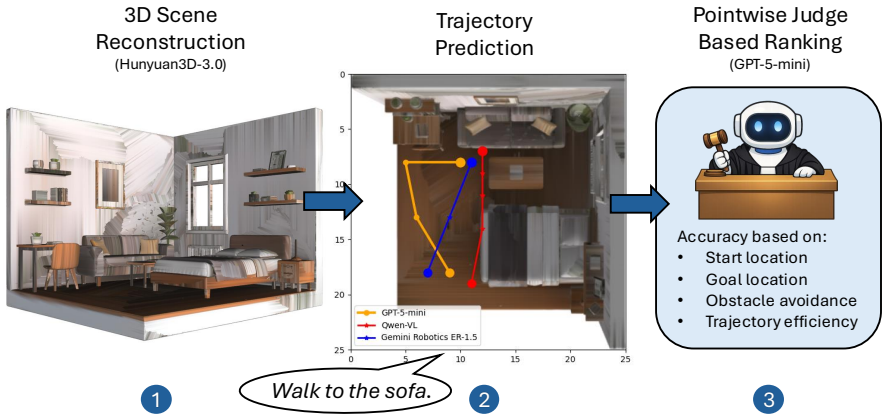
SleepWalk organizes instruction-grounded trajectory prediction into three tiers of spatial and temporal difficulty in single-scene 3D worlds. Given rendered views and a language instruction, a model must output a trajectory that stays geometrically valid, collision-free, and action-compatible. Tests across 2,472 scenes and nine instructions per scene show systematic shortfalls in grounded reasoning that grow with difficulty, while models retain partial ability to produce coherent and executable paths.
What carries the argument
The three-tier SleepWalk benchmark that generates navigable 3D scenes from text descriptions and scores predicted trajectories for geometric validity, executability, and instruction alignment via a pointwise judge protocol.
If this is right
- Accuracy declines as tasks move from simple spatial steps to occluded or multi-step instructions.
- Models frequently violate scene geometry or interaction constraints even when trajectories remain broadly plausible.
- The benchmark isolates localized interaction-centric failures that differ from long-range exploration benchmarks.
- Partial success on basic tiers indicates models can handle some spatial coherence but not under compositional load.
Where Pith is reading between the lines
- The results point to a need for training regimes that explicitly reward 3D geometry awareness rather than language-visual matching alone.
- Extending the benchmark to dynamic scenes with moving objects could test whether current failures stem from static layout understanding.
- Success on SleepWalk might serve as a proxy signal for improving real-robot instruction following in cluttered indoor settings.
- The tiered structure offers a template for diagnosing similar grounding gaps in other multimodal planning tasks.
Load-bearing premise
Scenes created from textual descriptions and filtered for navigability form an unbiased stand-in for real-world spatial challenges, and the pointwise judge accurately measures how well trajectories match instructions.
What would settle it
Running the same models on physically captured real-world 3D scans or comparing pointwise judge scores against direct human ratings of trajectory quality would show whether the synthetic scenes and evaluation protocol produce the claimed failure patterns.
Figures




read the original abstract
Vision-Language Models (VLMs) have advanced rapidly in multimodal perception and language understanding, yet it remains unclear whether they can reliably ground language into spatially coherent, plausibly executable actions in 3D digital environments. We introduce SleepWalk, a benchmark for evaluating instruction-grounded trajectory prediction in single-scene 3D worlds generated from textual scene descriptions and filtered for navigability. Unlike prior navigation benchmarks centered on long-range exploration across rooms, SleepWalk targets localized, interaction-centric embodied reasoning: given rendered visual observations and a natural-language instruction, a model must predict a trajectory that respects scene geometry, avoids collisions, and terminates at an action-compatible location. The benchmark covers diverse indoor and outdoor environments and organizes tasks into three tiers of spatial and temporal difficulty, enabling fine-grained analysis of grounding under increasing compositional complexity. Using a standardized pointwise judge-based evaluation protocol, we evaluate three frontier VLMs on 2,472 curated 3D environments with nine instructions per scene. Results reveal systematic failures in grounded spatial reasoning, especially under occlusion, interaction constraints, and multi-step instructions: performance drops as the difficulty level of the tasks increase. In general, current VLMs can somewhat produce trajectories that are simultaneously spatially coherent, plausibly executable, and aligned with intended actions. By exposing failures in a controlled yet scalable setting, SleepWalk provides a critical benchmark for advancing grounded multimodal reasoning, embodied planning, vision-language navigation, and action-capable agents in 3D environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SleepWalk, a benchmark for instruction-guided vision-language navigation consisting of 2,472 single-scene 3D environments generated from textual descriptions and filtered for navigability. Tasks are organized into three tiers of increasing spatial and temporal difficulty, with models required to predict trajectories from rendered observations and natural-language instructions that respect geometry, avoid collisions, and align with actions. Three frontier VLMs are evaluated using a standardized pointwise judge protocol, revealing performance drops with difficulty and systematic failures in grounded spatial reasoning under occlusion, interaction constraints, and multi-step instructions.
Significance. If the synthetic scenes and judge protocol prove representative, the benchmark would offer a scalable, controlled testbed for localized embodied reasoning in VLMs, complementing long-range exploration benchmarks. The tiered design and large scale (2,472 scenes, nine instructions each) enable fine-grained diagnosis of failures, which could usefully guide development of action-capable agents. The work explicitly provides a reproducible evaluation protocol and highlights gaps in current models' spatial grounding.
major comments (3)
- [§3.1] §3.1 (Scene Generation): The description of how 3D scenes are constructed from textual descriptions and the exact navigability filtering criteria are insufficiently detailed. This is load-bearing for the central claim, as the reported systematic failures in occlusion handling and interaction constraints could arise from simplified geometry or language-visual correlations in the generated scenes rather than genuine model limitations.
- [§4.2] §4.2 (Evaluation Protocol): The pointwise judge implementation is presented without human correlation studies, inter-annotator agreement, or ablation against alternative judges. This directly affects interpretation of the performance drops across tiers (e.g., in the results tables), since the judge may share VLM-like biases in scoring trajectory alignment.
- [Results] Results (e.g., Table 2 and tier-wise analysis): While drops in success metrics with increasing difficulty are shown, no control baselines (random trajectories, language-only predictors, or non-embodied VLMs) are reported. This weakens the claim that current VLMs 'can somewhat produce' coherent trajectories, as the absolute levels of failure cannot be contextualized.
minor comments (3)
- [Abstract] The abstract states 'nine instructions per scene' without specifying generation or selection criteria, which would aid reproducibility.
- [Figures] Figure captions for tier examples could more explicitly label the specific spatial challenges (occlusion, constraints) being tested in each panel.
- [§3] Notation for trajectory representation (e.g., sequence of actions or waypoints) is introduced but could be formalized earlier with a clear equation or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to improve reproducibility, evaluation rigor, and contextualization of results.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Scene Generation): The description of how 3D scenes are constructed from textual descriptions and the exact navigability filtering criteria are insufficiently detailed. This is load-bearing for the central claim, as the reported systematic failures in occlusion handling and interaction constraints could arise from simplified geometry or language-visual correlations in the generated scenes rather than genuine model limitations.
Authors: We agree that greater detail on scene generation is needed for full reproducibility and to rule out artifacts. In the revised manuscript, we will expand §3.1 with the complete textual prompt templates, the precise navigability filtering criteria (including minimum path length, collision checks via the 3D engine, and interaction constraints), and quantitative scene statistics such as average object density, occlusion rates, and geometric complexity measures. These additions will clarify that the environments incorporate realistic 3D structure and support our interpretation of model failures as stemming from limitations in spatial grounding. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Protocol): The pointwise judge implementation is presented without human correlation studies, inter-annotator agreement, or ablation against alternative judges. This directly affects interpretation of the performance drops across tiers (e.g., in the results tables), since the judge may share VLM-like biases in scoring trajectory alignment.
Authors: We acknowledge the value of human validation for the judge protocol. The original design prioritized scalability for the 22,000+ evaluations. In revision, we will augment §4.2 with fuller implementation details, any available pilot inter-annotator agreement figures, and an ablation against alternative metrics (e.g., geometric overlap or action-sequence similarity). We will also add an explicit discussion of potential judge biases and limitations. A comprehensive new human correlation study is resource-intensive but we will pursue a targeted pilot if feasible for the camera-ready version. revision: partial
-
Referee: [Results] Results (e.g., Table 2 and tier-wise analysis): While drops in success metrics with increasing difficulty are shown, no control baselines (random trajectories, language-only predictors, or non-embodied VLMs) are reported. This weakens the claim that current VLMs 'can somewhat produce' coherent trajectories, as the absolute levels of failure cannot be contextualized.
Authors: We agree that control baselines would strengthen interpretation of the absolute performance levels and the tier-wise trends. In the revised manuscript, we will add results for random trajectory sampling, language-only predictors (visual input ablated), and non-embodied VLM baselines. These will be integrated into Table 2 and the tier-wise analysis to better contextualize the claim that current VLMs can produce somewhat coherent trajectories while exposing their specific shortcomings in grounded spatial reasoning. revision: yes
Circularity Check
No circularity: empirical benchmark with external models and new scenes
full rationale
The paper introduces SleepWalk as a new benchmark consisting of 2,472 text-generated 3D scenes filtered for navigability, with tasks organized into three difficulty tiers. It evaluates three external frontier VLMs using a pointwise judge protocol and reports observed performance drops under occlusion, interaction constraints, and multi-step instructions. No equations, fitted parameters, self-defined quantities, or derivation chains are present; the central claims are direct empirical measurements on independent VLMs and scenes rather than any reduction of results to prior self-generated inputs by construction. Self-citations, if present, are not load-bearing for the reported failures.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Textual scene descriptions can be converted into 3D environments that are sufficiently realistic for testing spatial navigation after navigability filtering.
- domain assumption A pointwise judge-based protocol can reliably assess whether predicted trajectories are spatially coherent, executable, and instruction-aligned.
invented entities (1)
-
SleepWalk three-tier benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce SleepWalk, a benchmark for evaluating instruction-grounded trajectory prediction in single-scene 3D worlds generated from textual scene descriptions and filtered for navigability... three tiers of spatial and temporal difficulty... pointwise judge-based evaluation protocol
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results reveal systematic failures in grounded spatial reasoning, especially under occlusion, interaction constraints, and multi-step instructions: performance drops as the difficulty level of the tasks increase.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The benchmark covers diverse indoor and outdoor environments and organizes tasks into three tiers of spatial and temporal difficulty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
a single-scene, interaction-centric benchmark setting for grounded trajectory reasoning,
-
[2]
a scalable construction pipeline that reconstructs 3D scenes, generates tiered instructions, and evaluates predicted paths, and
-
[3]
an empirical diagnosis showing that current frontier VLMs degrade substantially on composi- tional, interaction-heavy, and multi-step instructions. Why this matters. The paper should not be read as claiming that any one component—for exam- ple, the judge or the scene generator—is the sole novelty. Rather, the novelty lies in defining and instantiating a b...
-
[4]
Start Location Consistency,
-
[5]
Obstacle Avoidance, and
-
[6]
Trajectory Efficiency. This means the evaluation is designed to reflect not only where a model ends up, but whether it gets there through a path that is spatially plausible and aligned with the intended action. What the paper does and does not claim. The manuscript does not claim that judge-based eval- uation is perfect. It makes the narrower methodologic...
-
[7]
the benchmark differentiates strong models,
-
[8]
the revealed failures are systematic rather than trivial, and
-
[9]
current VLMs are bad at navi- gation
performance degrades under higher compositional and interaction demands. What the results already show. Among the evaluated models, GPT-5-mini performs best across all four reported factors, but even the strongest system degrades as the tasks become harder. This supports the benchmark’s central diagnostic claim. Takeaway. Broader model coverage would cert...
-
[10]
Image 1: Oblique View (Perspective)
-
[11]
Image 2: Top-Down View (Map) ### Critical Pre-Condition Analyze the Top-Down View first. If the Top-Down view is incomplete, obstructed, or not clearly visible, you must ignore all other instructions and output ONLY this exact phrase:,→ ”The view is not clear to generate instructions” --- ### Phase 1: Environment Analysis If the views are clear, analyze b...
-
[12]
Object Grounding: - Every START and END location must refer to a specific, visible object found in the images.,→ - Correct: ”Start: Near the red chair” - Incorrect: ”Start: Near the wall” or ”Start: At the start point”
-
[13]
Forbidden Terminology (Spatial Hallucination): - NEVER use viewpoint-dependent or relative directional terms. - BANNED WORDS: left, right, front, back, center, centre, middle, top, bottom, upper, lower.,→ - Tasks must be valid regardless of the agent 's facing direction
-
[14]
Only reference items clearly visible in the provided images
Object Consistency: - Do not hallucinate objects. Only reference items clearly visible in the provided images. --- ### Output Format Step 1: Provide an *ENVIRONMENT SUMMARY* (2-3 sentences describing the room type and listing 10-15 key visible objects).,→ Step 2: Output the task list following this exact schema: LEVEL_1 | TASK: <instruction> | START: Near...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.