Recognition: 2 theorem links
· Lean TheoremReal vs. Semi-Simulated: Rethinking Evaluation for Treatment Effect Estimation
Pith reviewed 2026-05-12 04:33 UTC · model grok-4.3
The pith
Semi-simulated benchmarks with counterfactual metrics do not identify the treatment effect estimators that perform best under observable metrics on real data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
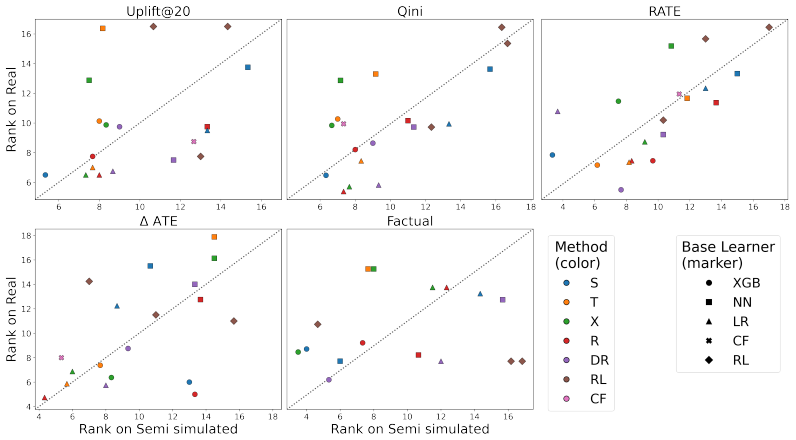
Our results reveal two complementary gaps. First, counterfactual metrics do not reliably recover the estimators preferred by observable metrics, even on the same semi-simulated benchmarks. Second, rankings obtained on semi-simulated benchmarks do not transfer to real datasets. We further find that simple meta-learners with strong base models are consistently competitive, in contrast to specialized causal models.
What carries the argument
Large-scale empirical comparison of meta-learners and specialized causal models across counterfactual metrics on semi-simulated benchmarks versus observable metrics on real datasets.
If this is right
- Treatment effect research should combine observable metrics and real-data validation with existing benchmark practices.
- Simple meta-learners with strong base models can serve as competitive baselines without requiring specialized causal architectures.
- Model selection for applications cannot rely solely on semi-simulated rankings.
- Specialized causal models require additional real-world evidence to demonstrate advantage over simpler alternatives.
Where Pith is reading between the lines
- New evaluation protocols could be built around proxy tasks that approximate observable outcomes without needing counterfactual ground truth.
- Emphasis may shift toward improving base learners rather than inventing more elaborate causal wrappers.
- Additional real datasets from domains such as medicine or policy could be collected to test whether the observed gaps persist.
Load-bearing premise
The chosen real-world datasets are representative of practical deployment and the observable metrics based on ranking or test outcomes accurately reflect the value of treatment effect estimates in those settings.
What would settle it
A new study that finds the same estimators consistently rank at the top under both counterfactual metrics on semi-simulated data and observable metrics on a broad collection of real datasets would contradict the reported gaps.
Figures





read the original abstract
Estimating heterogeneous treatment effects with machine learning has attracted substantial attention in both academic research and industrial practice. However, the two communities often evaluate models under markedly different conditions. Methodological work typically relies on semi-simulated benchmarks and metrics that require counterfactual outcomes, whereas real-world applications rely on observable metrics based on ranking or test outcomes. Despite the well-known gap between methodological progress and practical deployment, the relationship between these evaluation regimes has not been examined systematically. We conduct a large-scale empirical study of treatment effect evaluation across standard semi-simulated benchmark families and real-world datasets. Our benchmark covers meta-learners paired with multiple base learners, as well as specialized causal machine learning models. We evaluate these methods using observable metrics common in application-oriented literature, alongside counterfactual metrics commonly used in methods papers. Our results reveal two complementary gaps. First, counterfactual metrics do not reliably recover the estimators preferred by observable metrics, even on the same semi-simulated benchmarks. Second, rankings obtained on semi-simulated benchmarks do not transfer to real datasets. We further find that simple meta-learners with strong base models are consistently competitive, in contrast to specialized causal models. Overall, our findings suggest that progress in treatment effect estimation research should not be assessed solely through counterfactual metrics and semi-simulated benchmarks, but it would benefit from incorporating observable metrics and real-data validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a large-scale empirical study comparing treatment effect estimation methods under two evaluation regimes: counterfactual metrics on semi-simulated benchmarks versus observable metrics (ranking- or test-outcome-based) on real-world datasets. It covers meta-learners with various base learners and specialized causal models. The central claims are that counterfactual metrics fail to recover the estimators preferred by observable metrics even on identical semi-simulated benchmarks, that method rankings from semi-simulated data do not transfer to real datasets, and that simple meta-learners with strong base models are consistently competitive with specialized causal models.
Significance. If the reported gaps prove robust, the work is significant for causal machine learning because it supplies concrete empirical evidence of misalignment between standard academic benchmarks and practical deployment criteria. This could prompt the field to broaden evaluation beyond counterfactual metrics and semi-simulated data. The study is strengthened by its scale and direct comparison of common methodological and application-oriented practices.
major comments (2)
- [Abstract] Abstract: the claim that 'rankings obtained on semi-simulated benchmarks do not transfer to real datasets' is load-bearing for the paper's main message. This conclusion rests on observable metrics serving as faithful proxies for CATE quality, yet such metrics can be driven by overall response-model accuracy, treatment-selection patterns, or non-causal signals; the manuscript should include targeted analyses (e.g., ablation on base-model performance or synthetic controls) to isolate the contribution of heterogeneous-effect recovery.
- [Abstract] Abstract: the statement that 'counterfactual metrics do not reliably recover the estimators preferred by observable metrics' requires explicit quantification of disagreement (e.g., rank correlation or top-k overlap) together with statistical tests and robustness checks across different observable metrics; without these, it is difficult to judge whether the observed mismatch is systematic or sensitive to metric choice.
minor comments (1)
- [Abstract] Abstract: naming the specific semi-simulated benchmark families (e.g., IHDP, ACIC) and real-world datasets, along with their key characteristics (sample size, treatment prevalence), would improve reproducibility and allow readers to assess generalizability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and outline revisions to strengthen the manuscript's claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'rankings obtained on semi-simulated benchmarks do not transfer to real datasets' is load-bearing for the paper's main message. This conclusion rests on observable metrics serving as faithful proxies for CATE quality, yet such metrics can be driven by overall response-model accuracy, treatment-selection patterns, or non-causal signals; the manuscript should include targeted analyses (e.g., ablation on base-model performance or synthetic controls) to isolate the contribution of heterogeneous-effect recovery.
Authors: We appreciate this observation. Observable metrics on real data can indeed capture non-causal signals, but they reflect the evaluation standards used in practical deployment, which is the core motivation for contrasting them with academic counterfactual metrics. To isolate the contribution of heterogeneous effect recovery, we will add ablations comparing meta-learners to direct base-learner regressions that ignore treatment assignment (i.e., no meta-learning for CATE). Where data permits, we will also incorporate synthetic control analyses. These will appear in a new subsection of the experiments and be linked explicitly to the transferability claim. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'counterfactual metrics do not reliably recover the estimators preferred by observable metrics' requires explicit quantification of disagreement (e.g., rank correlation or top-k overlap) together with statistical tests and robustness checks across different observable metrics; without these, it is difficult to judge whether the observed mismatch is systematic or sensitive to metric choice.
Authors: We agree that explicit quantification is needed for rigor. In the revision we will report Spearman's rho and Kendall's tau rank correlations between counterfactual-metric and observable-metric rankings on the semi-simulated benchmarks, together with top-k overlap percentages. We will apply permutation tests to assess whether the observed disagreements are statistically significant and will repeat the entire analysis across alternative observable metrics drawn from the application literature. These results and robustness checks will be added to Section 4 and the appendix. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations
full rationale
This paper conducts a large-scale empirical comparison of treatment effect estimators across semi-simulated benchmarks and real-world datasets, evaluating them with both counterfactual and observable metrics. The abstract and described content contain no mathematical derivations, equations, fitted parameters, or ansatzes that could reduce to self-definitions or prior self-citations. Claims about gaps between evaluation regimes rest directly on experimental runs against external data sources rather than internal constructions, rendering the study self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard causal assumptions (e.g., no unmeasured confounding, positivity) hold sufficiently in the real-world datasets for observable metrics to be meaningful.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate these methods using observable metrics common in application-oriented literature, alongside counterfactual metrics commonly used in methods papers.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Really doing great at estimating cate? a critical look at ml benchmarking practices in treatment effect estimation , author=. Thirty-fifth conference on neural information processing systems datasets and benchmarks track (round 2) , year=
-
[2]
Advances in neural information processing systems , volume=
Removing hidden confounding by experimental grounding , author=. Advances in neural information processing systems , volume=
-
[3]
Forty-second International Conference on Machine Learning , year=
Rethinking Causal Ranking: A Balanced Perspective on Uplift Model Evaluation , author=. Forty-second International Conference on Machine Learning , year=
-
[4]
Estimating Heterogeneous Treatment Effects with Real-World Health Data--A Scoping Review of Machine Learning Methods , author=. Value in Health , year=
-
[5]
Proceedings of the 13th international conference on web search and data mining , pages=
Learning individual causal effects from networked observational data , author=. Proceedings of the 13th international conference on web search and data mining , pages=
-
[6]
International Conference on Artificial Intelligence and Statistics , pages=
Counterfactual representation learning with balancing weights , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
work page 2021
-
[7]
International Symposium on Intelligent Data Analysis , pages=
Evaluation of uplift models with non-random assignment bias , author=. International Symposium on Intelligent Data Analysis , pages=. 2022 , organization=
work page 2022
-
[8]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Uplift modeling under limited supervision , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2024 , organization=
work page 2024
-
[9]
Journal of the American Statistical Association , volume=
Evaluating treatment prioritization rules via rank-weighted average treatment effects , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
work page 2025
-
[10]
International Conference on Machine Learning , pages=
How and why to use experimental data to evaluate methods for observational causal inference , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[11]
Annals of statistics , volume=
Performance guarantees for individualized treatment rules , author=. Annals of statistics , volume=
-
[12]
Clinical Pharmacology & Therapeutics , volume=
Using machine learning to individualize treatment effect estimation: challenges and opportunities , author=. Clinical Pharmacology & Therapeutics , volume=. 2024 , publisher=
work page 2024
-
[13]
International Conference on Machine Learning , pages=
In search of insights, not magic bullets: Towards demystification of the model selection dilemma in heterogeneous treatment effect estimation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[14]
International Conference on Machine Learning Position Paper Track , year=
Position: Causal Machine Learning Requires Rigorous Synthetic Experiments for Broader Adoption , author=. International Conference on Machine Learning Position Paper Track , year=
-
[15]
Proceedings of the KDD Workshop on Artificial Intelligence for Computational Advertising , year=
A large scale benchmark for uplift modeling , author=. Proceedings of the KDD Workshop on Artificial Intelligence for Computational Advertising , year=
-
[16]
Vito Walter Anelli and Daniele Malitesta and Claudio Pomo and Alejandro Bellog. Challenging the Myth of Graph Collaborative Filtering: a Reasoned and Reproducibility-driven Analysis , booktitle =
-
[17]
ICML Workshop on Clinical Data Analysis , volume=
Uplift modeling for clinical trial data , author=. ICML Workshop on Clinical Data Analysis , volume=
-
[18]
Knowledge and Information Systems , volume=
A review on matrix completion for recommender systems , author=. Knowledge and Information Systems , volume=. 2022 , publisher=
work page 2022
-
[19]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Graph infomax adversarial learning for treatment effect estimation with networked observational data , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[20]
arXiv preprint arXiv:2107.12420 , year=
Efficient treatment effect estimation in observational studies under heterogeneous partial interference , author=. arXiv preprint arXiv:2107.12420 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Near-optimal bayesian active learning with noisy observations , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Policy learning with observational data , author=. Econometrica , volume=. 2021 , publisher=
work page 2021
-
[23]
Proceedings of the ACM Web Conference 2022 , pages=
Assessing the causal impact of COVID-19 related policies on outbreak dynamics: A case study in the US , author=. Proceedings of the ACM Web Conference 2022 , pages=
work page 2022
-
[24]
Inferring network effects from observational data , author=. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages=
-
[25]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
A Look into Causal Effects under Entangled Treatment in Graphs: Investigating the Impact of Contact on MRSA Infection , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[26]
Advances in Neural Information Processing Systems , volume=
Interventions, where and how? experimental design for causal models at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the 40th International Conference on Machine Learning , year=
Uncertainty Estimation for Molecules: Desiderata and Methods , author=. Proceedings of the 40th International Conference on Machine Learning , year=
-
[28]
Proceedings of the 32nd International Conference on Machine Learning , pages=
Submodularity in data subset selection and active learning , author=. Proceedings of the 32nd International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[29]
Universal sentence encoder , author=. arXiv preprint arXiv:1803.11175 , year=
-
[30]
The Journal of Machine Learning Research , volume=
Batch greedy maximization of non-submodular functions: Guarantees and applications to experimental design , author=. The Journal of Machine Learning Research , volume=. 2021 , publisher=
work page 2021
-
[31]
Proceedings of the KDD International Workshop on Mining and Learning with Graphs , year=
Network experiment design for estimating direct treatment effects , author=. Proceedings of the KDD International Workshop on Mining and Learning with Graphs , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
Using embeddings for causal estimation of peer influence in social networks , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
Estimating Causal Effects on Networked Observational Data via Representation Learning , author=. Proceedings of the 31st ACM International Conference on Information & Knowledge Management , pages=
-
[34]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Estimating Treatment Effects Under Heterogeneous Interference , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2023 , organization=
work page 2023
-
[35]
NeurIPS 2022 Workshop on Causality for Real-world Impact , year=
A Causal Inference Framework for Network Interference with Panel Data , author=. NeurIPS 2022 Workshop on Causality for Real-world Impact , year=
work page 2022
-
[36]
arXiv preprint arXiv:2405.02183 , year=
Metalearners for Ranking Treatment Effects , author=. arXiv preprint arXiv:2405.02183 , year=
-
[37]
Journal of the American Statistical Association , volume=
Estimation and inference of heterogeneous treatment effects using random forests , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[38]
International Conference on Machine Learning , pages=
Deep IV: A flexible approach for counterfactual prediction , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[39]
Data Mining and Knowledge Discovery , volume=
Linear regression for uplift modeling , author=. Data Mining and Knowledge Discovery , volume=. 2018 , publisher=
work page 2018
-
[40]
arXiv preprint arXiv:1807.07909 , year=
Boosting algorithms for uplift modeling , author=. arXiv preprint arXiv:1807.07909 , year=
-
[41]
Causal machine learning for predicting treatment outcomes , author=. Nature Medicine , volume=. 2024 , publisher=
work page 2024
-
[42]
Advances in neural information processing systems , volume=
Organite: Optimal transplant donor organ offering using an individual treatment effect , author=. Advances in neural information processing systems , volume=
-
[43]
European Journal of Operational Research , volume=
To do or not to do: cost-sensitive causal decision-making , author=. European Journal of Operational Research , volume=
-
[44]
Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=
Regularization for Uplift Regression , author=. Joint European Conference on Machine Learning and Knowledge Discovery in Databases , pages=. 2023 , organization=
work page 2023
-
[45]
arXiv preprint arXiv:2306.03929 , year=
Finding Counterfactually Optimal Action Sequences in Continuous State Spaces , author=. arXiv preprint arXiv:2306.03929 , year=
-
[46]
arXiv preprint arXiv:2301.12292 , year=
Zero-shot causal learning , author=. arXiv preprint arXiv:2301.12292 , year=
-
[47]
International Conference on Machine Learning , pages=
Improving screening processes via calibrated subset selection , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[48]
Clinical Pharmacology & Therapeutics , volume=
From real-world patient data to individualized treatment effects using machine learning: current and future methods to address underlying challenges , author=. Clinical Pharmacology & Therapeutics , volume=. 2021 , publisher=
work page 2021
-
[49]
arXiv; 2023.http://arxiv.org/abs/2011.08047, arXiv:2011.08047 [stat]
Causal inference methods for combining randomized trials and observational studies: a review , author=. arXiv preprint arXiv:2011.08047 , year=
-
[50]
Journal of the American Statistical Association , volume=
Causal inference using potential outcomes: Design, modeling, decisions , author=. Journal of the American Statistical Association , volume=. 2005 , publisher=
work page 2005
-
[51]
Advances in Neural Information Processing Systems , volume=
Staggered rollout designs enable causal inference under interference without network knowledge , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Advances in Neural Information Processing Systems , volume=
Causal effect inference with deep latent-variable models , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
arXiv preprint arXiv:1801.07310 , year=
Propensity score methodology in the presence of network entanglement between treatments , author=. arXiv preprint arXiv:1801.07310 , year=
-
[54]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks , author=. arXiv preprint arXiv:1609.02907 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
ICML Workshop on Structured Probabilistic Inference & Generative Modeling , year=
Graph Neural Network Powered Bayesian Optimization for Large Molecular Spaces , author=. ICML Workshop on Structured Probabilistic Inference & Generative Modeling , year=
-
[56]
Journal of Computational and Graphical Statistics , volume=
Bayesian nonparametric modeling for causal inference , author=. Journal of Computational and Graphical Statistics , volume=. 2011 , publisher=
work page 2011
-
[57]
arXiv preprint arXiv:2211.01939 , year=
Empirical analysis of model selection for heterogeneous causal effect estimation , author=. arXiv preprint arXiv:2211.01939 , year=
-
[58]
arXiv preprint arXiv:1804.05146 , year=
A comparison of methods for model selection when estimating individual treatment effects , author=. arXiv preprint arXiv:1804.05146 , year=
-
[59]
International Conference on Machine Learning , pages=
Counterfactual cross-validation: Stable model selection procedure for causal inference models , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[60]
Advances in Neural Information Processing Systems , volume=
Causal normalizing flows: from theory to practice , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Uplift modeling: From causal inference to personalization , author=. Proceedings of the 32nd ACM International Conference on Information and Knowledge Management , pages=
-
[62]
International conference on machine learning , pages=
Causal transformer for estimating counterfactual outcomes , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[63]
International Conference on Machine Learning , pages=
Validating causal inference models via influence functions , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[64]
Foundation models for causal inference via prior-data fitted networks, 2025
Foundation models for causal inference via prior-data fitted networks , author=. arXiv preprint arXiv:2506.10914 , year=
-
[65]
Automated versus Do-It-Yourself Methods for Causal Inference: Lessons Learned from a Data Analysis Competition , author=. Statistical Science , volume=
-
[66]
The MineThatData E-Mail Analytics and Data Mining Challenge , author=. 2008 , howpublished=
work page 2008
- [67]
-
[68]
arXiv preprint arXiv:1906.00442 , year=
An Evaluation Toolkit to Guide Model Selection and Cohort Definition in Causal Inference , author=. arXiv preprint arXiv:1906.00442 , year=
-
[69]
International conference on learning representations , year=
GANITE: Estimation of individualized treatment effects using generative adversarial nets , author=. International conference on learning representations , year=
-
[70]
Advances in neural information processing systems , volume=
Bayesian inference of individualized treatment effects using multi-task gaussian processes , author=. Advances in neural information processing systems , volume=
-
[71]
Proceedings of the AAAI conference on artificial intelligence , volume=
Learning counterfactual representations for estimating individual dose-response curves , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[72]
Drug discovery today , volume=
Application of statistical ‘design of experiments’ methods in drug discovery , author=. Drug discovery today , volume=. 2004 , publisher=
work page 2004
-
[73]
Quasi-oracle estimation of heterogeneous treatment effects , author=. Biometrika , volume=. 2021 , publisher=
work page 2021
-
[74]
arXiv preprint arXiv:2002.11631 , year=
Causalml: Python package for causal machine learning , author=. arXiv preprint arXiv:2002.11631 , year=
-
[75]
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Mar- garet Mitchell, Dhruv Batra, C
Prediction-powered inference , author=. arXiv preprint arXiv:2301.09633 , year=
-
[76]
Evidential deep learning for guided molecular property prediction and discovery , author=. ACS Central Science , volume=. 2021 , publisher=
work page 2021
-
[77]
Machine Learning for Marketing Decision Support , year=
Revenue uplift modeling , author=. Machine Learning for Marketing Decision Support , year=
-
[78]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Conditional independence in statistical theory , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1979 , publisher=
work page 1979
-
[79]
Knowledge and Information Systems , volume=
Decision trees for uplift modeling with single and multiple treatments , author=. Knowledge and Information Systems , volume=. 2012 , publisher=
work page 2012
-
[80]
Proceedings of the ACM Web Conference 2023 , pages=
Graph Neural Network with Two Uplift Estimators for Label-Scarcity Individual Uplift Modeling , author=. Proceedings of the ACM Web Conference 2023 , pages=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.