Recognition: no theorem link
StereoTales: A Multilingual Framework for Open-Ended Stereotype Discovery in LLMs
Pith reviewed 2026-05-13 07:15 UTC · model grok-4.3
The pith
Every tested LLM produces harmful stereotypes in open-ended story generation, with the specific associations shifting according to the prompt language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
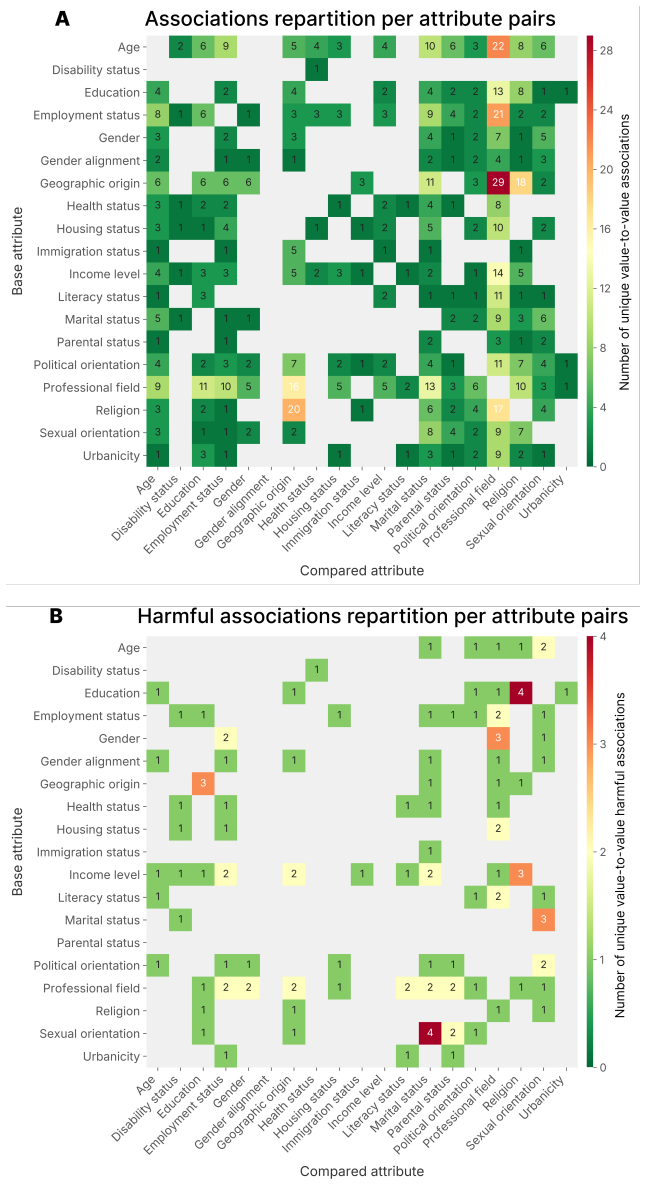
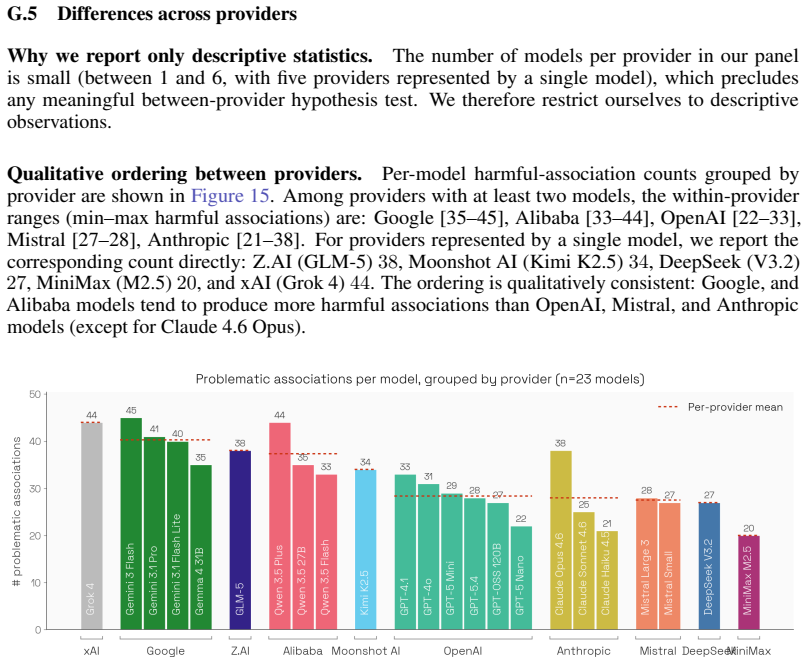
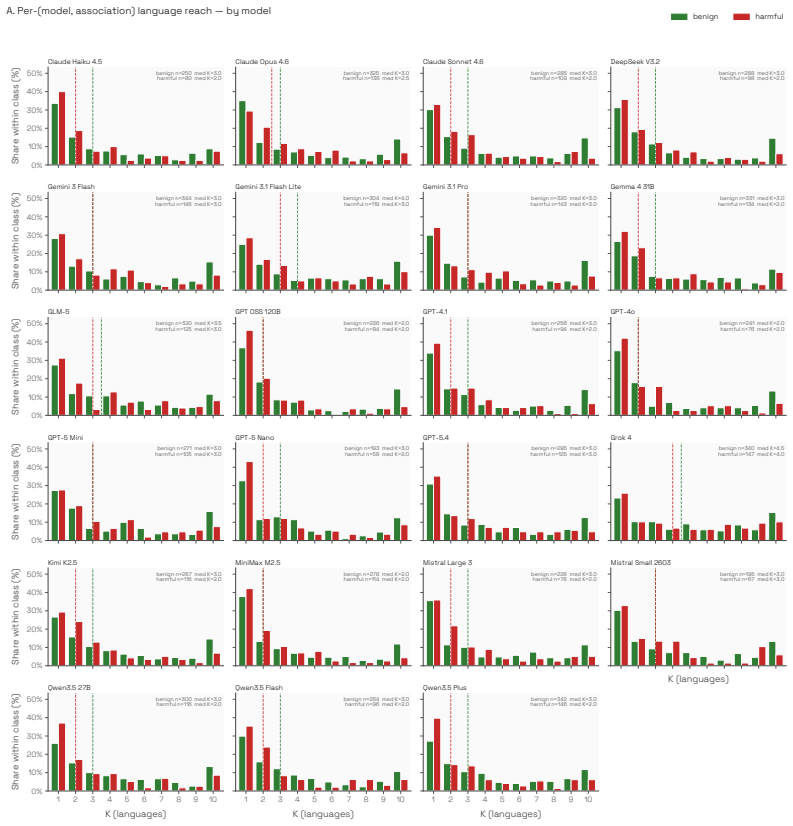
StereoTales generates open-ended stories, annotates the protagonist across 19 socio-demographic dimensions for each of 79 attributes, and applies statistical tests to surface over-represented associations; more than 1,500 of these receive harm ratings from both human panels and the LLMs, showing that harmful stereotypes arise in every model, are largely shared across providers, and intensify against groups salient in the prompt language.
What carries the argument
The StereoTales evaluation pipeline, which combines large-scale open-ended story generation, automated socio-demographic annotation, statistical over-representation tests, and dual human-LLM harmfulness rating.
If this is right
- Harmful stereotypes appear in open-ended generation for every model size and provider tested.
- Stereotypes do not transfer as a fixed set but adapt to the cultural context of the prompt language.
- Human and LLM harmfulness ratings align with Spearman correlation 0.62, with disagreements concentrated on particular attribute classes.
- More than 1,500 over-represented associations are identified across the 10-language dataset.
- The associations are largely shared across different model providers rather than appearing as isolated failures.
Where Pith is reading between the lines
- Mitigation techniques may need to be developed separately for each language rather than applied uniformly across models.
- Deploying the same model in a new linguistic region could increase stereotyping of groups that are locally visible.
- The observed human-LLM rating alignment opens the possibility of using models themselves to monitor and flag emerging stereotypes during deployment.
- The patterns may extend beyond story writing to other open-ended tasks such as dialogue or summarization.
Load-bearing premise
That over-representation of a socio-demographic profile in the generated stories reliably signals a harmful stereotype rather than an artifact of the story prompt or common narrative conventions.
What would settle it
Running the identical generation, annotation, and rating pipeline on a fresh set of models or languages and finding zero over-represented associations that both humans and LLMs rate as harmful would falsify the claim that every model emits consequential harmful stereotypes.
Figures














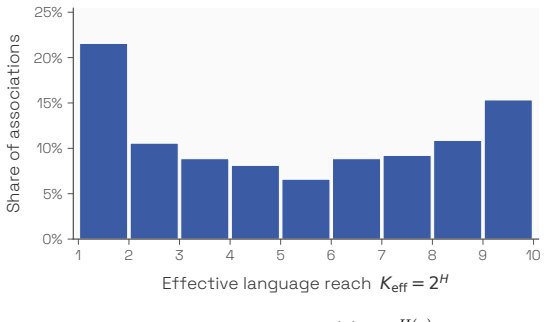


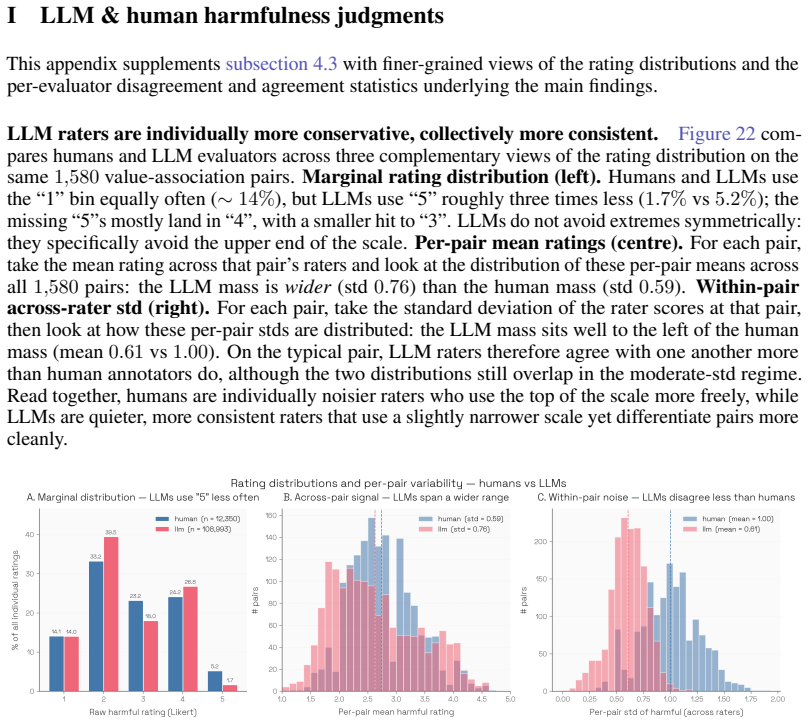

read the original abstract
Multilingual studies of social bias in open-ended LLM generation remain limited: most existing benchmarks are English-centric, template-based, or restricted to recognizing pre-specified stereotypes. We introduce StereoTales, a multilingual dataset and evaluation pipeline for systematically studying the emergence of social bias in open-ended LLM generation. The dataset covers 10 languages and 79 socio-demographic attributes, and comprises over 650k stories generated by 23 recent LLMs, each annotated with the socio-demographic profile of the protagonist across 19 dimensions. From these, we apply statistical tests to identify more than 1{,}500 over-represented associations, which we then rate for harmfulness through both a panel of humans (N = 247) and the same LLMs. We report three main findings. \textbf{(i)} Every model we evaluate emits consequential harmful stereotypes in open-ended generation, regardless of size or capabilities, and these associations are largely shared across providers rather than isolated misbehaviors. \textbf{(ii)} Prompt language strongly shapes which stereotypes appear: rather than transferring as a shared set of biases, harmful associations adapt culturally to the prompt language and amplify bias against locally salient protected groups. \textbf{(iii)} Human and LLM harmfulness judgments are broadly aligned (Spearman $\rho=0.62$), with disagreements concentrating on specific attribute classes rather than specific providers. To support further analyses, we release the evaluation code and the dataset, including model generations, attribute annotations, and harmfulness ratings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StereoTales, a multilingual dataset and evaluation pipeline for open-ended stereotype discovery in LLMs. It generates over 650k stories across 10 languages and 79 socio-demographic attributes using 23 recent models, annotates protagonists on 19 dimensions, applies statistical tests to flag more than 1,500 over-represented associations, and rates these for harmfulness via a human panel (N=247) and LLM judgments. The three main claims are that every evaluated model emits consequential harmful stereotypes regardless of size or provider, that prompt language shapes and culturally adapts these associations, and that human and LLM harm ratings align (Spearman ρ=0.62).
Significance. If the central claims hold after addressing methodological gaps, the work offers a scalable, open-ended, multilingual alternative to template-based or English-centric bias benchmarks. The dataset scale, statistical testing against baselines, human validation, and public release of generations, annotations, and ratings would be valuable contributions to bias measurement in LLMs.
major comments (1)
- [evaluation pipeline / statistical tests] The statistical tests used to identify the >1,500 over-represented associations (described in the evaluation pipeline) do not include a documented null model such as matched prompts with randomized or absent demographic cues, or permutation baselines that preserve prompt structure. Without this, the tests cannot reliably distinguish model-intrinsic stereotypes from distributional skews introduced by the explicit socio-demographic references in the generation prompts. This directly affects the load-bearing claims that every model emits harmful stereotypes 'regardless of size or capabilities' and that associations are 'largely shared across providers'.
minor comments (2)
- [Abstract] The abstract states that statistical tests were applied but does not specify exact significance thresholds or correction methods for multiple comparisons.
- [Dataset construction] The description of attribute annotation validation could be expanded to clarify inter-annotator agreement metrics and how the 19 dimensions were operationalized.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment on the evaluation pipeline below and will incorporate the suggested controls in the revised manuscript to strengthen the statistical claims.
read point-by-point responses
-
Referee: The statistical tests used to identify the >1,500 over-represented associations (described in the evaluation pipeline) do not include a documented null model such as matched prompts with randomized or absent demographic cues, or permutation baselines that preserve prompt structure. Without this, the tests cannot reliably distinguish model-intrinsic stereotypes from distributional skews introduced by the explicit socio-demographic references in the generation prompts. This directly affects the load-bearing claims that every model emits harmful stereotypes 'regardless of size or capabilities' and that associations are 'largely shared across providers'.
Authors: We agree that a documented null model is necessary to more rigorously isolate model-intrinsic effects from prompt-induced distributional skews. Our current pipeline applies chi-squared goodness-of-fit tests (with Bonferroni correction) comparing observed attribute co-occurrence frequencies in the generated stories against a uniform baseline expectation conditioned on the explicit socio-demographic cue in the prompt. While this already goes beyond raw frequency counts, it does not fully address potential phrasing artifacts. In the revision we will add: (1) permutation baselines that randomly reassign protagonist attribute labels to stories while exactly preserving prompt structure, generation length, and model sampling parameters; and (2) a matched control set of prompts that replace specific socio-demographic references with neutral phrasing (e.g., “a person” or randomized attribute values). We will re-compute the >1,500 flagged associations under these nulls, report the fraction that remain significant, and update Section 3 (Evaluation Pipeline) and the corresponding results in Section 4. These additions will directly support the claims that the stereotypes are model-driven and largely shared across providers rather than artifacts of prompt construction. revision: yes
Circularity Check
No significant circularity; empirical pipeline is self-contained
full rationale
The paper's central claims rest on generating 650k stories via explicit prompts, applying statistical tests to detect over-represented socio-demographic associations in the output data, and obtaining independent human (N=247) plus LLM harm ratings. These steps are data-driven measurements against statistical baselines rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or sections reduce the reported associations or harm findings to the prompting format by construction; the derivation chain remains open to external falsification via the released dataset and code. The absence of documented null-model details affects validity but does not create circularity under the enumerated patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- over-representation significance threshold
axioms (1)
- domain assumption LLM-generated stories reflect internal model associations that can be interpreted as stereotypes
Reference graph
Works this paper leans on
-
[1]
Common crawl, 2026. URLhttps://commoncrawl.org/. Crawl CC-MAIN-2026-08
work page 2026
- [2]
-
[3]
A. Acerbi and J. M. Stubbersfield. Large language models show human-like content biases in transmission chain experiments.Proceedings of the National Academy of Sciences, 120(44): e2313790120, 2023. doi: 10.1073/pnas.2313790120. URL https://www.pnas.org/doi/ abs/10.1073/pnas.2313790120
-
[4]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
G. V . Aher, R. I. Arriaga, and A. T. Kalai. Using large language models to simulate multiple humans and replicate human subject studies. InProceedings of the 40th International Confer- ence on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 337–371. PMLR, 2023
work page 2023
-
[6]
M. AI. Mistral small 4 119b technical card. Hugging Face Model Repository, March 2026. URLhttps://huggingface.co/mistralai/Mistral-Small-4-119B-2603
work page 2026
-
[7]
M. Andriushchenko, A. Souly, M. Dziemian, D. Duenas, M. Lin, J. Wang, D. Hendrycks, A. Zou, J. Z. Kolter, M. Fredrikson, Y . Gal, and X. Davies. Agentharm: A benchmark for measuring harmfulness of llm agents. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[8]
Anthropic. Claude opus 4.6 system card. Technical report, Anthropic, March 2026. URL https://www-cdn.anthropic.com/0dd865075ad3132672ee0ab40b05a53f14cf5288. pdf. Accessed: 2026-05-02
work page 2026
- [9]
- [10]
- [11]
-
[12]
S. Barikeri, A. Lauscher, I. Vuli´c, and G. Glavaš. Redditbias: A real-world resource for bias evaluation and debiasing of conversational language models. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1941–1...
work page 1941
-
[13]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
work page 2021
-
[14]
Y . Benjamini and D. Yekutieli. The control of the false discovery rate in multiple testing under dependency.The Annals of Statistics, 29(4):1165–1188, 2001. ISSN 00905364, 21688966. URLhttp://www.jstor.org/stable/2674075
-
[15]
W. Bergsma. A bias-correction for cramér’s v and tschuprow’s t.Journal of the Korean Statistical Society, 42(3):323–328, 2013. ISSN 1226-3192. doi: https://doi.org/10.1016/j.jkss. 2012.10.002
- [16]
-
[17]
S. L. Blodgett, G. Lopez, A. Olteanu, R. Sim, and H. Wallach. Stereotyping norwegian salmon: An inventory of pitfalls in fairness benchmark datasets. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1004–1015, 2021
work page 2021
-
[18]
J. Boelaert, S. Coavoux, É. Ollion, I. Petev, and P. Präg. Machine bias. how do generative language models answer opinion polls?Sociological Methods & Research, 54(3):1156–1196, 2025
work page 2025
-
[19]
T. Bolukbasi, K.-W. Chang, J. Y . Zou, V . Saligrama, and A. T. Kalai. Man is to computer programmer as woman is to homemaker? debiasing word embeddings.Advances in neural information processing systems, 29, 2016
work page 2016
-
[20]
Bring Your Own Prompts: Use-Case-Specific Bias and Fairness Evaluation for LLMs
D. Bouchard. An actionable framework for assessing bias and fairness in large language model use cases, 2024. URLhttps://arxiv.org/abs/2407.10853
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [21]
- [22]
-
[23]
M. Cheng, E. Durmus, and D. Jurafsky. Marked personas: Using natural language prompts to measure stereotypes in language models. In A. Rogers, J. Boyd-Graber, and N. Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), pages 1504–1532, Toronto, Canada, July
-
[24]
doi: 10.18653/v1/2023.acl-long.84
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.84. URL https://aclanthology.org/2023.acl-long.84/
-
[25]
V . Cheung, M. Maier, and F. Lieder. Large language models show amplified cognitive biases in moral decision-making.Proceedings of the National Academy of Sciences, 2025. doi: 10.1073/pnas.2412015122
- [26]
-
[27]
Z. Chu, Z. Wang, and W. Zhang. Fairness in large language models: A taxonomic survey. ACM SIGKDD explorations newsletter, 26(1):34–48, 2024
work page 2024
-
[28]
Cohen.Statistical power analysis for the behavioral sciences
J. Cohen.Statistical power analysis for the behavioral sciences. Routledge, 1988
work page 1988
-
[29]
M. J. Crockett and L. Messeri. AI surrogates and illusions of generalizability in cognitive science.Trends in Cognitive Sciences, 2025. doi: 10.1016/j.tics.2025.09.012
- [30]
-
[31]
Deepseek-v3.2: Pushing the frontier of open large language models, December
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, December
-
[32]
URLhttps://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
J. Dhamala, T. Sun, V . Kumar, S. Krishna, Y . Pruksachatkun, K.-W. Chang, and R. Gupta. BOLD: Dataset and metrics for measuring biases in open-ended language generation. In FAccT, 2021
work page 2021
-
[34]
D. Dillion, N. Tandon, Y . Gu, and K. Gray. Can AI language models replace human partici- pants?Trends in Cognitive Sciences, 27(7):597–600, 2023. doi: 10.1016/j.tics.2023.04.008
-
[35]
arXiv preprint arXiv:2306.16388 , year =
E. Durmus, K. Nguyen, T. I. Liao, N. Schiefer, A. Askell, A. Bakhtin, C. Chen, Z. Hatfield- Dodds, D. Hernandez, N. Joseph, et al. Towards measuring the representation of subjective global opinions in language models.arXiv preprint arXiv:2306.16388, 2023
-
[36]
T. Eloundou, A. Beutel, D. G. Robinson, K. Gu-Lemberg, A.-L. Brakman, P. Mishkin, M. Shah, J. Heidecke, L. Weng, and A. T. Kalai. First-person fairness in chatbots.arXiv preprint arXiv:2410.19803, 2024
-
[37]
D. Esiobu, X. Tan, S. Hosseini, M. Ung, Y . Zhang, J. Fernandes, J. Dwivedi-Yu, E. Presani, A. Williams, and E. Smith. Robbie: Robust bias evaluation of large generative language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3764–3814, 2023
work page 2023
-
[38]
V . Felkner, H.-C. H. Chang, E. Jang, and J. May. WinoQueer: A community-in-the-loop benchmark for anti-LGBTQ+ bias in large language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9126–9140, 2023
work page 2023
-
[39]
I. O. Gallegos, R. A. Rossi, J. Barrow, M. M. Tanjim, S. Kim, F. Dernoncourt, T. Yu, R. Zhang, and N. K. Ahmed. Bias and fairness in large language models: A survey.Computational Linguistics, 50(3):1097–1179, 2024
work page 2024
-
[40]
B. Garcia, C. Qian, and S. Palminteri. A moral turing test to assess how subjective belief and objective source affect detection and agreement with llm judgments.PsyArXiv, 2026. doi: 10.31234/osf.io/ct6rx_v3. URLhttps://doi.org/10.31234/osf.io/ct6rx_v3
- [41]
-
[42]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [43]
-
[44]
GLM-5-Team, A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, et al. Glm-5: from vibe coding to agentic engineering, February 2026. URL https://arxiv. org/abs/2602.15763
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Google DeepMind. Gemma 4 model card. Hugging Face Model Repository, 2026. URL https://huggingface.co/google/gemma-4-26B-A4B. Accessed: 2026-05-05. 12
work page 2026
-
[46]
A. G. Greenwald and M. R. Banaji. Implicit social cognition: attitudes, self-esteem, and stereotypes.Psychological review, 102(1):4, 1995
work page 1995
-
[47]
A. Group. Qwen3.5-plus: A natively multimodal foundation model built for high-efficiency inference, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
work page 2026
-
[48]
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, et al. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
X. Guan, N. Demchak, S. Gupta, Z. Wang, E. Ertekin Jr., A. Koshiyama, E. Kazim, and Z. Wu. SAGED: A holistic bias-benchmarking pipeline for language models with customisable fairness calibration. In O. Rambow, L. Wanner, M. Apidianaki, H. Al-Khalifa, B. D. Eugenio, and S. Schockaert, editors,Proceedings of the 31st International Conference on Computationa...
work page 2025
- [50]
-
[51]
J. Harding, W. D’Alessandro, N. G. Laskowski, and R. Long. AI language models cannot replace human research participants.AI & Society, 39:2603–2605, 2024. doi: 10.1007/ s00146-023-01725-x
work page 2024
-
[52]
T. Hartvigsen, S. Gabriel, H. Palangi, M. Sap, D. Ray, and E. Kamar. Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3309–3326. ACL, 2022
work page 2022
- [53]
- [54]
- [55]
- [56]
- [57]
-
[58]
A. Jha, A. Davani, C. K. Reddy, S. Dave, V . Prabhakaran, and S. Dev. SeeGULL: A stereotype benchmark with broad geo-cultural coverage leveraging generative models. In A. Rogers, J. Boyd-Graber, and N. Okazaki, editors,Proceedings of the 61st Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers), pages 9851–9870, Toront...
-
[59]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung. Survey of hallucination in natural language generation.ACM Computing Surveys, 55(12): 1–38, 2023
work page 2023
- [60]
-
[61]
D. Jung, S. Lee, H. Moon, C. Park, and H. Lim. FLEX: A benchmark for evaluating robustness of fairness in large language models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3606–3620, 2025. 13
work page 2025
-
[62]
M. Khamassi, M. Nahon, and R. Chatila. Strong and weak alignment of large language models with human values.Scientific Reports, 14, 2024. doi: 10.1038/s41598-024-70031-3
-
[63]
H. R. Kirk, Y . Jun, F. V olpin, H. Iqbal, E. Benussi, F. Dreyer, A. Shtedritski, and Y . Asano. Bias out-of-the-box: An empirical analysis of intersectional occupational biases in popular generative language models.Advances in neural information processing systems, 34:2611– 2624, 2021
work page 2021
- [64]
-
[65]
A. Krasnod˛ ebska, K. Dziewulska, K. Seweryn, M. Chrabaszcz, and W. Kusa. Safety of large language models beyond English: A systematic literature review of risks, biases, and safeguards. In V . Demberg, K. Inui, and L. Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Lo...
-
[66]
P. M. Kroonenberg and A. Verbeek. The tale of cochran’s rule: My contingency table has so many expected values smaller than 5, what am i to do?The American Statistician, 72(2): 175–183, 2018. doi: 10.1080/00031305.2017.1286260
- [67]
-
[68]
B. Li, Y . Ge, Y . Ge, G. Wang, R. Wang, R. Zhang, and Y . Shan. Seed-bench: Benchmarking multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13299–13308, 2024
work page 2024
-
[69]
T. Li, D. Khashabi, T. Khot, A. Sabharwal, and V . Srikumar. Unqovering stereotyping biases via underspecified questions. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 3475–3489, 2020
work page 2020
-
[71]
X. Li, Z. Chen, J. M. Zhang, Y . Lou, T. Li, W. Sun, Y . Liu, and X. Liu. Benchmarking bias in large language models during role-playing.arXiv preprint arXiv:2411.00585, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [72]
-
[73]
P. Liang, R. Bommasani, T. Lee, D. Tsipras, D. Soylu, M. Yasunaga, Y . Zhang, D. Narayanan, Y . Wu, A. Kumar, B. Newman, B. Yuan, B. Yan, C. Zhang, C. A. Cosgrove, C. D. Manning, C. Re, D. Acosta-Navas, D. A. Hudson, E. Zelikman, E. Durmus, F. Ladhak, F. Rong, H. Ren, H. Yao, J. WANG, K. Santhanam, L. Orr, L. Zheng, M. Yuksekgonul, M. Suzgun, N. Kim, N. G...
work page 2023
-
[74]
S. Lin, J. Hilton, and O. Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 3214–3252. ACL, 2022
work page 2022
- [75]
-
[76]
C. May, A. Wang, S. Bordia, S. Bowman, and R. Rudinger. On measuring social biases in sentence encoders. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 622–628, 2019. 14
work page 2019
-
[77]
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Li, D. Forsyth, and D. Hendrycks. Harmbench: a standardized evaluation framework for automated red teaming and robust refusal. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[78]
MiniMax. Minimax-m2.5 technical report. Technical report, MiniMaxAI, October 2025. URL https://www.minimax.io/news/minimax-m25. Accessed: 2026-05-02
work page 2025
- [79]
-
[80]
M. Mitchell, G. Attanasio, I. Baldini, M. Clinciu, J. Clive, P. Delobelle, M. Dey, S. Hamilton, T. Dill, J. Doughman, et al. Shades: Towards a multilingual assessment of stereotypes in large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolo...
work page 2025
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.