Recognition: 3 theorem links
· Lean TheoremNew AI-Driven Tools for Enhancing Campus Well-being: A Prevention and Intervention Approach
Pith reviewed 2026-05-12 04:20 UTC · model grok-4.3
The pith
A unified AI framework combines adaptive survey chatbots with stacked mental health detection models to enhance campus well-being.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dissertation establishes a cohesive framework that unifies prevention tools for improving feedback collection through personalized and adaptive conversations with intervention tools for advancing mental health detection using expressive narratives and multi-model reasoning, allowing adaptive survey insights to flow directly into specialized mental health detection models.
What carries the argument
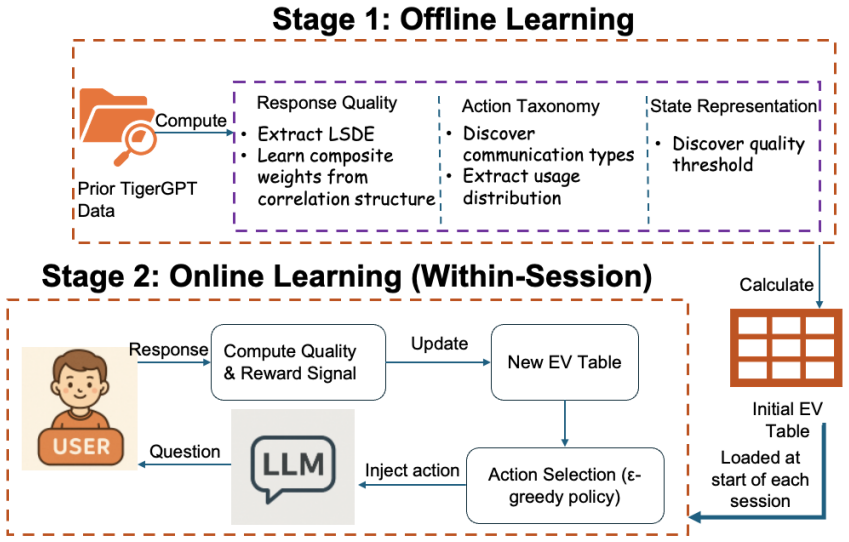
The cohesive framework enabling adaptive survey insights to flow directly into specialized mental health detection models, supported by AURA's reinforcement learning adaptation using LSDE quality signals and SMMR's layered expert models for task decomposition and reconciliation.
Where Pith is reading between the lines
- If the framework holds, real-world deployment could enable proactive identification of at-risk students through routine surveys.
- Integration with university systems might allow tailored interventions based on collected data.
- Extensions could test the framework's performance across different cultural or demographic student groups to address potential biases.
Load-bearing premise
The assumption that the LSDE quality signal accurately reflects conversation quality and that clinical guidelines combined with linguistic features can reliably detect mental health risks in campus populations without bias or hallucination.
What would settle it
Observing no significant difference in mental health detection accuracy or survey engagement metrics when comparing the proposed tools to standard methods in a controlled campus trial would challenge the central claims.
Figures


































read the original abstract
Campus well-being underpins academic success, yet many universities lack effective methods for monitoring satisfaction and detecting mental health risks. This dissertation addresses these gaps through prevention (improving feedback collection) and intervention (advancing mental health detection), unified under an integrated framework. For prevention, we developed TigerGPT, a personalized survey chatbot leveraging LLMs to engage users in context-aware conversations grounded in conversational design and engagement theory, achieving 75% usability and 81% satisfaction. To address its limitations in repetitiveness and response depth, we introduced AURA, a reinforcement-learning framework that adapts follow-up question types (validate, specify, reflect, probe) within a session using an LSDE quality signal (Length, Self-disclosure, Emotion, Specificity), initialized from 96 prior conversations. AURA achieved +0.12 mean quality gain (p=0.044, d=0.66), with 63% fewer specification prompts and 10x more validation behavior. For intervention, we examine Expressive Narrative Stories (ENS) for mental health screening, showing BERT(128) captures nuanced linguistic features without keyword cues, while conventional classifiers depend heavily on explicit mental health terms. We then developed PsychoGPT, an LLM built on DSM-5 and PHQ-8 guidelines that performs initial distress classification, symptom-level scoring, and reconciliation with external ratings for explainable assessment. To reduce hallucinations, we proposed Stacked Multi-Model Reasoning (SMMR), layering expert models where early layers handle localized subtasks and later layers reconcile findings, outperforming single-model solutions on DAIC-WOZ in accuracy, F1, and PHQ-8 scoring. Finally, a cohesive framework unifies these tools, enabling adaptive survey insights to flow directly into specialized mental health detection models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a dissertation developing AI tools for campus well-being: TigerGPT as a personalized LLM survey chatbot (75% usability, 81% satisfaction), AURA as an RL framework adapting question types via an LSDE quality signal on 96 prior conversations (+0.12 mean quality gain, p=0.044, d=0.66), PsychoGPT for DSM-5/PHQ-8 based distress classification and symptom scoring, and SMMR as stacked multi-model reasoning that outperforms single models on DAIC-WOZ in accuracy, F1, and PHQ-8 scoring. These are unified under a cohesive framework in which adaptive survey insights flow directly into specialized mental health detection models.
Significance. If the integration claim holds, the work offers a prevention-intervention pipeline with concrete, statistically supported gains in conversation quality and detection performance on established benchmarks like DAIC-WOZ. The use of RL for adaptive prompting and layered reasoning to mitigate hallucinations are promising directions for applied mental-health AI. However, the absence of end-to-end validation limits the assessed novelty and practical impact.
major comments (2)
- [Abstract] Abstract (final paragraph): the central claim that 'a cohesive framework unifies these tools, enabling adaptive survey insights to flow directly into specialized mental health detection models' is unsupported by any reported experiments, ablations, or case studies. AURA (LSDE-driven RL) and SMMR/PsychoGPT are evaluated in isolation on separate data (prior conversations and DAIC-WOZ); no results show that AURA-generated conversations improve downstream distress classification, PHQ-8 scoring, or reduce hallucinations when fed into the detection stack.
- [AURA section] AURA description and evaluation: the LSDE quality signal (Length, Self-disclosure, Emotion, Specificity) is used to adapt prompts and claim a +0.12 gain, yet the manuscript provides no validation of this signal against external human quality ratings, clinical outcomes, or inter-rater reliability. Without such grounding, it is unclear whether the reported behavioral changes (63% fewer specification prompts, 10x validation) translate to improved mental-health signals for the downstream models.
minor comments (2)
- [Abstract] The abstract reports 75% usability and 81% satisfaction for TigerGPT but does not specify the measurement instruments, sample size, or comparison baselines.
- [SMMR evaluation] SMMR is described as outperforming single-model solutions on DAIC-WOZ, but the manuscript does not detail the exact baselines, data splits, or whether the gains are statistically significant after multiple-comparison correction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We agree that the manuscript's description of the unified framework requires qualification, as the components were developed and evaluated independently. We will revise the abstract and add explicit discussion of limitations and future integration plans. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the central claim that 'a cohesive framework unifies these tools, enabling adaptive survey insights to flow directly into specialized mental health detection models' is unsupported by any reported experiments, ablations, or case studies. AURA (LSDE-driven RL) and SMMR/PsychoGPT are evaluated in isolation on separate data (prior conversations and DAIC-WOZ); no results show that AURA-generated conversations improve downstream distress classification, PHQ-8 scoring, or reduce hallucinations when fed into the detection stack.
Authors: We acknowledge that the abstract overstates the integration. The manuscript presents the tools as modular components within a proposed prevention-intervention pipeline, with AURA outputs conceptually feeding into PsychoGPT/SMMR, but no end-to-end experiments, ablations, or case studies were conducted. This is a genuine limitation of the dissertation, which compiles separate studies. We will revise the abstract to describe the framework as a conceptual unification based on design modularity rather than demonstrated data flow, and we will add a dedicated limitations paragraph in the discussion section outlining the need for future end-to-end validation on shared datasets. revision: yes
-
Referee: [AURA section] AURA description and evaluation: the LSDE quality signal (Length, Self-disclosure, Emotion, Specificity) is used to adapt prompts and claim a +0.12 gain, yet the manuscript provides no validation of this signal against external human quality ratings, clinical outcomes, or inter-rater reliability. Without such grounding, it is unclear whether the reported behavioral changes (63% fewer specification prompts, 10x validation) translate to improved mental-health signals for the downstream models.
Authors: The LSDE dimensions were selected from prior literature on conversational quality in mental-health dialogues as a practical proxy signal for RL training. The reported +0.12 mean quality gain, p-value, effect size, and behavioral shifts (63% fewer specification prompts, 10x validation) were computed directly from this internal signal on the 96 conversations. We agree that external validation against human ratings, clinical outcomes, or inter-rater reliability is absent and that this leaves open whether the improvements enhance downstream mental-health signals. We will add a limitations subsection in the AURA section explicitly stating the proxy nature of LSDE and recommending future human-evaluation studies to ground the signal. revision: partial
Circularity Check
No significant circularity; empirical claims rest on separate evaluations
full rationale
The paper reports experimental outcomes for TigerGPT (usability/satisfaction), AURA (LSDE-based RL quality gain on initialized conversations), ENS linguistic analysis, PsychoGPT, and SMMR (outperformance on DAIC-WOZ) as independent results. The final unified framework statement simply asserts integration of these components without any derivation, equation, or self-referential reduction that equates outputs to inputs by construction. No self-citations, fitted parameters renamed as predictions, or ansatzes are load-bearing in the provided chain. All performance metrics (p-values, F1, accuracy) are tied to external benchmarks or held-out data rather than tautological re-measurement of the optimization signal.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AURA achieved +0.12 mean quality gain (p=0.044, d=0.66), with 63% fewer specification prompts and 10x more validation behavior. SMMR outperforms single-model solutions on DAIC-WOZ in accuracy, F1, and PHQ-8 scoring.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a cohesive framework unifies these tools, enabling adaptive survey insights to flow directly into specialized mental health detection models
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LSDE quality signal (Length, Self-disclosure, Emotion, Specificity)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Assessment of campus climate to enhance student success
S. A. Vogel, J. K. Holt, S. Sligar, and E. Leake, “Assessment of campus climate to enhance student success.”Journal of Postsecondary Education and Disability, vol. 21, no. 1, pp. 15–31, 2008
work page 2008
-
[2]
D. A. Dillman, J. D. Smyth, and L. M. Christian,Internet, phone, mail, and mixed-mode surveys: The tailored design method. John Wiley & Sons, 2014
work page 2014
-
[3]
Effects of questionnaire length on participation and indicators of response quality in a web survey,
M. Galesic and M. Bosnjak, “Effects of questionnaire length on participation and indicators of response quality in a web survey,”Public opinion quarterly, vol. 73, no. 2, pp. 349–360, 2009
work page 2009
-
[4]
S. Sahlqvist, Y. Song, F. Bull, E. Adams, J. Preston, D. Ogilvie, and iConnect Consortium, “Effect of questionnaire length, personalisation and reminder type on response rate to a complex postal survey: randomised controlled trial,”BMC medical research methodology, vol. 11, pp. 1–8, 2011
work page 2011
-
[5]
Shortfall in mental health service utilisation,
G. Andrews, C. Issakidis, and G. Carter, “Shortfall in mental health service utilisation,”The British Journal of Psychiatry, vol. 179, no. 5, pp. 417–425, 2001
work page 2001
-
[6]
C. Blanco, M. Okuda, C. Wright, D. S. Hasin, B. F. Grant, S.-M. Liu, and M. Olfson, “Mental health of college students and their non–college-attending peers: results from the national epidemiologic study on alcohol and related conditions,”Archives of general psychiatry, vol. 65, no. 12, pp. 1429–1437, 2008. 146
work page 2008
-
[7]
A. Gulliver, K. M. Griffiths, and H. Christensen, “Perceived barriers and facilitators to mental health help-seeking in young people: a systematic review,” BMC psychiatry, vol. 10, no. 1, pp. 1–9, 2010
work page 2010
-
[8]
How do people come to use mental health services? current knowledge and changing perspectives
B. A. Pescosolido and C. A. Boyer, “How do people come to use mental health services? current knowledge and changing perspectives.” 1999
work page 1999
-
[9]
M. Zhou, L. Liu, and Y. Feng, “Building citizen trust to enhance satisfaction in digital public services: the role of empathetic chatbot communication,” Behaviour & Information Technology, pp. 1–20, 2025
work page 2025
-
[10]
Z. Xiao, M. X. Zhou, Q. V. Liao, G. Mark, C. Chi, W. Chen, and H. Yang, “Tell me about yourself: Using an ai-powered chatbot to conduct conversational surveys with open-ended questions,”ACM Transactions on Computer-Human Interaction (TOCHI), vol. 27, no. 3, pp. 1–37, 2020
work page 2020
-
[11]
Opinebot: Class feedback reimagined using a conversational llm,
H. Tanwar, K. Shrivastva, R. Singh, and D. Kumar, “Opinebot: Class feedback reimagined using a conversational llm,”arXiv preprint arXiv:2401.15589, 2024
-
[12]
Decoding linguistic nuances in mental health text classification using expressive narrative stories,
J. Tang, Q. Guo, Y. Zhao, and Y. Shang, “Decoding linguistic nuances in mental health text classification using expressive narrative stories,” in2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI). IEEE, 2024, pp. 207–216
work page 2024
-
[13]
Advancing mental health pre-screening: A new custom gpt for psychological distress assessment,
J. Tang and Y. Shang, “Advancing mental health pre-screening: A new custom gpt for psychological distress assessment,” in2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI). IEEE, 2024, pp. 162–171
work page 2024
-
[14]
Tigergpt: A theory-driven ai chatbot for adaptive campus climate surveys,
J. Tang, S. Chen, and Y. Shang, “Tigergpt: A theory-driven ai chatbot for adaptive campus climate surveys,” in2025 IEEE International Conference on Future Machine Learning and Data Science (FMLDS). IEEE, 2025, pp. 668–673. 147
work page 2025
-
[15]
Aura: A reinforcement learning framework for ai-driven adaptive conversational surveys,
J. Tang and Y. Shang, “Aura: A reinforcement learning framework for ai-driven adaptive conversational surveys,”arXiv preprint arXiv:2510.27126, 2025
-
[16]
A layered multi-expert framework for long-context mental health assessments,
J. Tang, Q. Guo, W. Sun, and Y. Shang, “A layered multi-expert framework for long-context mental health assessments,” in2025 IEEE Conference on Artificial Intelligence (CAI), 2025, pp. 435–440
work page 2025
-
[17]
University student surveys using chatbots: artificial intelligence conversational agents,
N. Abbas, T. Pickard, E. Atwell, and A. Walker, “University student surveys using chatbots: artificial intelligence conversational agents,” inInternational Conference on Human-Computer Interaction. Springer, 2021, pp. 155–169
work page 2021
-
[18]
Engaging students to fill surveys using chatbots: University case study,
N. Belhaj, A. Hamdane, N. E. H. Chaoui, H. Chaoui, and M. El Bekkali, “Engaging students to fill surveys using chatbots: University case study,” Indones. J. Electr. Eng. Comput. Sci, vol. 24, no. 1, pp. 473–483, 2021
work page 2021
-
[19]
Online chat and chatbots to enhance mature student engagement in higher education,
N. Abbas, J. Whitfield, E. Atwell, H. Bowman, T. Pickard, and A. Walker, “Online chat and chatbots to enhance mature student engagement in higher education,”International Journal of Lifelong Education, vol. 41, no. 3, pp. 308–326, 2022
work page 2022
-
[20]
Ai-driven student assistance: chatbots redefining university support,
S. Martinez-Requejo, E. J. García, S. R. Duarte, J. R. Lázaro, E. P. Sanz, and G. M. Vivas, “Ai-driven student assistance: chatbots redefining university support,” inINTED2024 Proceedings. IATED, 2024, pp. 617–625
work page 2024
-
[21]
R. Liu, C. Zenke, C. Liu, A. Holmes, P. Thornton, and D. J. Malan, “Teaching cs50 with ai,”Portland, OR, US: ACM, 2024
work page 2024
-
[22]
Conversational survey chatbot: User experience and perception,
A. Njegušet al., “Conversational survey chatbot: User experience and perception,” inSinteza 2021-International Scientific Conference on Information Technology and Data Related Research. Singidunum University, 2021, pp. 322–327
work page 2021
-
[23]
B. Zarouali, T. Araujo, J. Ohme, and C. de Vreese, “Comparing chatbots and online surveys for (longitudinal) data collection: an investigation of response 148 characteristics, data quality, and user evaluation,”Communication Methods and Measures, vol. 18, no. 1, pp. 72–91, 2024
work page 2024
-
[24]
S. Kim, J. Lee, and G. Gweon, “Comparing data from chatbot and web surveys: Effects of platform and conversational style on survey response quality,” in Proceedings of the 2019 CHI conference on human factors in computing systems, 2019, pp. 1–12
work page 2019
-
[25]
A review on implementation issues of rule-based chatbot systems,
S. A. Thorat and V. Jadhav, “A review on implementation issues of rule-based chatbot systems,” inProceedings of the international conference on innovative computing & communications (ICICC), 2020
work page 2020
-
[26]
W. Maeng and J. Lee, “Designing a chatbot for survivors of sexual violence: Exploratory study for hybrid approach combining rule-based chatbot and ml-based chatbot,” inProceedings of the Asian CHI Symposium 2021, 2021, pp. 160–166
work page 2021
-
[27]
The challenges in designing a prevention chatbot for eating disorders: observational study,
W. W. Chan, E. E. Fitzsimmons-Craft, A. C. Smith, M.-L. Firebaugh, L. A. Fowler, B. DePietro, N. Topooco, D. E. Wilfley, C. B. Taylor, and N. C. Jacobson, “The challenges in designing a prevention chatbot for eating disorders: observational study,”JMIR Formative Research, vol. 6, no. 1, p. e28003, 2022
work page 2022
-
[28]
E-mail subject lines and their effect on web survey viewing and response,
S. R. Porter and M. E. Whitcomb, “E-mail subject lines and their effect on web survey viewing and response,”Social Science Computer Review, vol. 23, no. 3, pp. 380–387, 2005
work page 2005
-
[29]
The psychological meaning of words: Liwc and computerized text analysis methods,
Y. R. Tausczik and J. W. Pennebaker, “The psychological meaning of words: Liwc and computerized text analysis methods,”Journal of language and social psychology, vol. 29, no. 1, pp. 24–54, 2010
work page 2010
-
[30]
Concreteness ratings for 40 thousand generally known english word lemmas,
M. Brysbaert, A. B. Warriner, and V. Kuperman, “Concreteness ratings for 40 thousand generally known english word lemmas,”Behavior research methods, vol. 46, no. 3, pp. 904–911, 2014. 149
work page 2014
-
[31]
The measurement of trust and its relationship to self-disclosure,
L. R. Wheeless and J. Grotz, “The measurement of trust and its relationship to self-disclosure,”Human Communication Research, vol. 3, no. 3, pp. 250–257, 1977
work page 1977
-
[32]
W. B. Gudykunst and S. Ting-Toomey,Culture and interpersonal communication. Sage Publications, 1988
work page 1988
-
[33]
Linguistic styles: Language use as an individual difference,
J. W. Pennebaker and L. A. King, “Linguistic styles: Language use as an individual difference,”Journal of Personality and Social Psychology, vol. 77, no. 6, pp. 1296–1312, 1999
work page 1999
-
[34]
R. Tourangeau, L. J. Rips, and K. Rasinski,The psychology of survey response. Cambridge University Press, 2000
work page 2000
-
[35]
Cognitive burden of survey questions and response times: A psycholinguistic experiment,
T. Lenzner, L. Kaczmirek, and A. Lenzner, “Cognitive burden of survey questions and response times: A psycholinguistic experiment,”Applied cognitive psychology, vol. 24, no. 7, pp. 1003–1020, 2010
work page 2010
-
[36]
Conducting sensitive interviews: A review of reflections,
A. Melville and D. Hincks, “Conducting sensitive interviews: A review of reflections,”Law and Method, vol. 1, no. 1, pp. 1–26, 2016
work page 2016
-
[37]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
work page 1998
-
[38]
Dynamic policy networks for task-oriented dialogue with reinforcement learning,
P.-H. Su, M. Gasic, S. Young, M. Gašić, and S. Young, “Dynamic policy networks for task-oriented dialogue with reinforcement learning,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL). ACL, 2021, pp. 341–352
work page 2021
-
[39]
Contextual bandits for adaptive dialogue management,
Y. Sun, X. Li, K. Zhou, and X. Wang, “Contextual bandits for adaptive dialogue management,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1152–1163, 2023
work page 2023
-
[40]
D. A. Regier, W. E. Narrow, D. S. Rae, R. W. Manderscheid, B. Z. Locke, and F. K. Goodwin, “The de facto us mental and addictive disorders service system: 150 Epidemiologic catchment area prospective 1-year prevalence rates of disorders and services,”Archives of general psychiatry, vol. 50, no. 2, pp. 85–94, 1993
work page 1993
-
[41]
R. OpenAI, “Gpt-4 technical report. arxiv 2303.08774,”View in Article, vol. 2, p. 13, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Advancing mental health pre-screening: A new custom gpt for psychological distress assessment,
J. Tang and Y. Shang, “Advancing mental health pre-screening: A new custom gpt for psychological distress assessment,” in2024 IEEE 6th International Conference on Cognitive Machine Intelligence (CogMI), 2024, pp. 162–171
work page 2024
-
[43]
J. Ohse, B. Hadžić, P. Mohammed, N. Peperkorn, M. Danner, A. Yorita, N. Kubota, M. Rätsch, and Y. Shiban, “Zero-shot strike: Testing the generalisation capabilities of out-of-the-box llm models for depression detection,” Computer Speech & Language, vol. 88, p. 101663, 2024
work page 2024
-
[44]
A depression detection model based on sentiment analysis in micro-blog social network,
X. Wang, C. Zhang, Y. Ji, L. Sun, L. Wu, and Z. Bao, “A depression detection model based on sentiment analysis in micro-blog social network,” inTrends and Applications in Knowledge Discovery and Data Mining: PAKDD 2013 International Workshops: DMApps, DANTH, QIMIE, BDM, CDA, CloudSD, Gold Coast, QLD, Australia, April 14-17, 2013, Revised Selected Papers 1...
work page 2013
-
[45]
Depression and self-harm risk assessment in online forums,
A. Yates, A. Cohan, and N. Goharian, “Depression and self-harm risk assessment in online forums,”arXiv preprint arXiv:1709.01848, 2017
-
[46]
Semi-supervised approach to monitoring clinical depressive symptoms in social media,
A. H. Yazdavar, H. S. Al-Olimat, M. Ebrahimi, G. Bajaj, T. Banerjee, K. Thirunarayan, J. Pathak, and A. Sheth, “Semi-supervised approach to monitoring clinical depressive symptoms in social media,” inProceedings of the 2017 IEEE/ACM international conference on advances in social networks analysis and mining 2017, 2017, pp. 1191–1198
work page 2017
-
[47]
The distress analysis 151 interview corpus of human and computer interviews
J. Gratch, R. Artstein, G. M. Lucas, G. Stratou, S. Scherer, A. Nazarian, R. Wood, J. Boberg, D. DeVault, S. Marsellaet al., “The distress analysis 151 interview corpus of human and computer interviews.” inLREC. Reykjavik, 2014, pp. 3123–3128
work page 2014
-
[48]
Simsensei kiosk: A virtual human interviewer for healthcare decision support,
D. DeVault, R. Artstein, G. Benn, T. Dey, E. Fast, A. Gainer, K. Georgila, J. Gratch, A. Hartholt, M. Lhommetet al., “Simsensei kiosk: A virtual human interviewer for healthcare decision support,” inProceedings of the 2014 international conference on Autonomous agents and multi-agent systems, 2014, pp. 1061–1068
work page 2014
-
[49]
F. Ringeval, B. Schuller, M. Valstar, N. Cummins, R. Cowie, L. Tavabi, M. Schmitt, S. Alisamir, S. Amiriparian, E.-M. Messneret al., “Avec 2019 workshop and challenge: state-of-mind, detecting depression with ai, and cross-cultural affect recognition,” inProceedings of the 9th International on Audio/visual Emotion Challenge and Workshop, 2019, pp. 3–12
work page 2019
-
[50]
Comparison of natural language processing models for depression detection in chatbot dialogues,
C. A. Belser, “Comparison of natural language processing models for depression detection in chatbot dialogues,” Ph.D. dissertation, Massachusetts Institute of Technology, 2023
work page 2023
-
[51]
A novel automated depression detection technique using text transcript,
U. Yadav and A. K. Sharma, “A novel automated depression detection technique using text transcript,”International Journal of Imaging Systems and Technology, vol. 33, no. 1, pp. 108–122, 2023
work page 2023
-
[52]
Towards automatic text-based estimation of depression through symptom prediction,
K. Milintsevich, K. Sirts, and G. Dias, “Towards automatic text-based estimation of depression through symptom prediction,”Brain Informatics, vol. 10, no. 1, pp. 1–14, 2023
work page 2023
-
[53]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qinet al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,”ACM Transactions on Information Systems, 2023. 152
work page 2023
-
[54]
Large legal fictions: Profiling legal hallucinations in large language models,
M. Dahl, V. Magesh, M. Suzgun, and D. E. Ho, “Large legal fictions: Profiling legal hallucinations in large language models,”Journal of Legal Analysis, vol. 16, no. 1, pp. 64–93, 2024
work page 2024
-
[55]
Machine learning and natural language processing in mental health: systematic review,
A. Le Glaz, Y. Haralambous, D.-H. Kim-Dufor, P. Lenca, R. Billot, T. C. Ryan, J. Marsh, J. Devylder, M. Walter, S. Berrouiguetet al., “Machine learning and natural language processing in mental health: systematic review,”Journal of Medical Internet Research, vol. 23, no. 5, p. e15708, 2021
work page 2021
-
[56]
Predicting mental conditions based on “history of present illness
T. Tran and R. Kavuluru, “Predicting mental conditions based on “history of present illness” in psychiatric notes with deep neural networks,”Journal of biomedical informatics, vol. 75, pp. S138–S148, 2017
work page 2017
-
[57]
Natural language processing applied to mental illness detection: a narrative review,
T. Zhang, A. M. Schoene, S. Ji, and S. Ananiadou, “Natural language processing applied to mental illness detection: a narrative review,”NPJ digital medicine, vol. 5, no. 1, p. 46, 2022
work page 2022
-
[58]
Artificial intelligence for mental health and mental illnesses: an overview,
S. Graham, C. Depp, E. E. Lee, C. Nebeker, X. Tu, H.-C. Kim, and D. V. Jeste, “Artificial intelligence for mental health and mental illnesses: an overview,” Current psychiatry reports, vol. 21, pp. 1–18, 2019
work page 2019
-
[59]
Machine learning in mental health: a scoping review of methods and applications,
A. B. Shatte, D. M. Hutchinson, and S. J. Teague, “Machine learning in mental health: a scoping review of methods and applications,”Psychological medicine, vol. 49, no. 9, pp. 1426–1448, 2019
work page 2019
-
[60]
Provider perspectives on integrating sensor-captured patient-generated data in mental health care,
A. Ng, R. Kornfield, S. M. Schueller, A. K. Zalta, M. Brennan, and M. Reddy, “Provider perspectives on integrating sensor-captured patient-generated data in mental health care,”Proceedings of the ACM on human-computer interaction, vol. 3, no. CSCW, pp. 1–25, 2019
work page 2019
-
[61]
M. Marsolek, S. Emert, J. R. Dietch, E. Tucker, and D. Taylor, “0969 predicting differences between objective and subjective sleep parameters with 153 mental health questionnaires,”SLEEP, 2024. [Online]. Available: https://api.semanticscholar.org/CorpusID:269288613
work page 2024
-
[62]
A content analysis of depression-related tweets,
P. A. Cavazos-Rehg, M. J. Krauss, S. Sowles, S. Connolly, C. Rosas, M. Bharadwaj, and L. J. Bierut, “A content analysis of depression-related tweets,”Computers in human behavior, vol. 54, pp. 351–357, 2016
work page 2016
-
[63]
Psychological aspects of natural language use: Our words, our selves,
J. W. Pennebaker, M. R. Mehl, and K. G. Niederhoffer, “Psychological aspects of natural language use: Our words, our selves,”Annual review of psychology, vol. 54, no. 1, pp. 547–577, 2003
work page 2003
-
[64]
Redeveloping diction: theoretical considerations,
R. P. Hart, “Redeveloping diction: theoretical considerations,”Progress in communication sciences, pp. 43–60, 2001
work page 2001
-
[65]
Confronting a traumatic event: toward an understanding of inhibition and disease
J. W. Pennebaker and S. K. Beall, “Confronting a traumatic event: toward an understanding of inhibition and disease.”Journal of abnormal psychology, vol. 95, no. 3, p. 274, 1986
work page 1986
-
[66]
Disclosure of traumas and immune function: health implications for psychotherapy
J. W. Pennebaker, J. K. Kiecolt-Glaser, and R. Glaser, “Disclosure of traumas and immune function: health implications for psychotherapy.”Journal of consulting and clinical psychology, vol. 56, no. 2, p. 239, 1988
work page 1988
-
[67]
Expressive writing and blood pressure
K. Davidson, A. R. Schwartz, D. Sheffield, R. S. McCord, S. J. Lepore, and W. Gerin, “Expressive writing and blood pressure.” 2002
work page 2002
-
[68]
The effects of expressive writing on adjustment to hiv,
I. D. Rivkin, J. Gustafson, I. Weingarten, and D. Chin, “The effects of expressive writing on adjustment to hiv,”AIDS and Behavior, vol. 10, pp. 13–26, 2006
work page 2006
-
[69]
Machine learning driven mental stress detection on reddit posts using natural language processing,
S. Inamdar, R. Chapekar, S. Gite, and B. Pradhan, “Machine learning driven mental stress detection on reddit posts using natural language processing,” Human-Centric Intelligent Systems, vol. 3, no. 2, pp. 80–91, 2023
work page 2023
-
[70]
R. K. Garg, V. L. Urs, A. A. Agarwal, S. K. Chaudhary, V. Paliwal, and S. K. Kar, “Exploring the role of chatgpt in patient care (diagnosis and treatment) 154 and medical research: A systematic review,”Health Promotion Perspectives, vol. 13, no. 3, p. 183, 2023
work page 2023
-
[71]
Toward expert-level medical question answering with large language models,
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewiset al., “Toward expert-level medical question answering with large language models,”Nature Medicine, pp. 1–8, 2025
work page 2025
-
[72]
Clinical text summarization: adapting large language models can outperform human experts,
D. Van Veen, C. Van Uden, L. Blankemeier, J.-B. Delbrouck, A. Aali, C. Bluethgen, A. Pareek, M. Polacin, E. P. Reis, A. Seehofnerovaet al., “Clinical text summarization: adapting large language models can outperform human experts,”Research square, pp. rs–3, 2023
work page 2023
-
[73]
A. Agrawal, “Illuminate: A novel approach for depression detection with explainable analysis and proactive therapy using prompt engineering,”arXiv preprint arXiv:2402.05127, 2024
-
[74]
Q. Guo, J. Tang, W. Sun, H. Tang, Y. Shang, and W. Wang, “Soullmate: An application enhancing diverse mental health support with adaptive llms, prompt engineering, and rag techniques,”arXiv preprint arXiv:2410.16322, 2024
-
[75]
——, “Soullmate: An adaptive llm-driven system for advanced mental health support and assessment, based on a systematic application survey,”arXiv preprint arXiv:2410.11859, 2024
-
[76]
Large language models for mental health applications: Systematic review,
Z. Guo, A. Lai, J. H. Thygesen, J. Farrington, T. Keen, K. Liet al., “Large language models for mental health applications: Systematic review,”JMIR mental health, vol. 11, no. 1, p. e57400, 2024
work page 2024
-
[77]
J. Song, J. Chim, A. Tsakalidis, J. Ive, D. Atzil-Slonim, and M. Liakata, “Combining hierachical vaes with llms for clinically meaningful timeline summarisation in social media,”arXiv preprint arXiv:2401.16240, 2024. 155
-
[78]
G. Soman, M. Judy, and A. M. Abou, “Human guided empathetic ai agent for mental health support leveraging reinforcement learning-enhanced retrieval-augmented generation,”Cognitive Systems Research, vol. 90, p. 101337, 2025
work page 2025
-
[79]
Mental-llm: Leveraging large language models for mental health prediction via online text data,
X. Xu, B. Yao, Y. Dong, S. Gabriel, H. Yu, J. Hendler, M. Ghassemi, A. K. Dey, and D. Wang, “Mental-llm: Leveraging large language models for mental health prediction via online text data,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 8, no. 1, pp. 1–32, 2024
work page 2024
-
[80]
The personalization of conversational agents in health care: systematic review,
A. B. Kocaballi, S. Berkovsky, J. C. Quiroz, L. Laranjo, H. L. Tong, D. Rezazadegan, A. Briatore, and E. Coiera, “The personalization of conversational agents in health care: systematic review,”Journal of medical Internet research, vol. 21, no. 11, p. e15360, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.