Recognition: 2 theorem links
· Lean TheoremDCVD: Dual-Channel Cross-Modal Fusion for Joint Vulnerability Detection and Localization
Pith reviewed 2026-05-13 01:50 UTC · model grok-4.3
The pith
DCVD fuses control-dependency and semantic features from code via contrastive alignment and bidirectional cross-attention, with explicit joint supervision, to detect vulnerable functions and localize vulnerable statements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
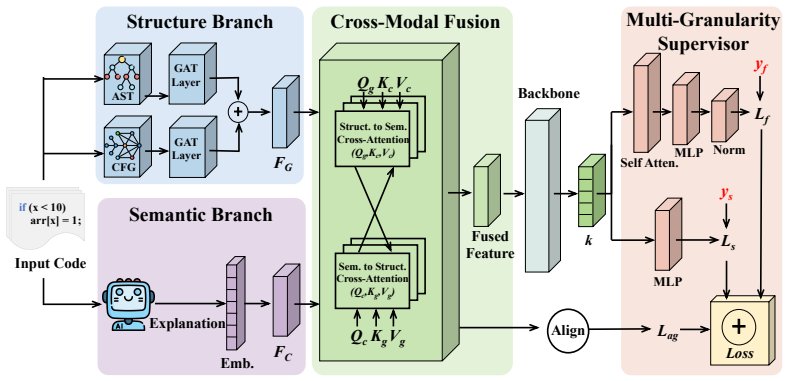
DCVD extracts control-dependency and semantic features through two parallel branches and integrates them via contrastive alignment coupled with bidirectional cross-attention, effectively bridging the cross-modal representation gap. It further introduces explicit supervision signals at both the function and statement levels, enabling collaborative optimization across the two granularities.
What carries the argument
Dual-channel cross-modal fusion that applies contrastive alignment and bidirectional cross-attention to control-dependency and semantic features while adding explicit supervision at function and statement levels.
If this is right
- The model achieves higher accuracy on function-level vulnerability detection than single-modality or non-joint baselines.
- It delivers better statement-level localization by using direct line supervision instead of treating it as a byproduct.
- Joint optimization across detection and localization granularities yields collaborative improvements on benchmark data.
- The fusion closes cross-modal gaps more effectively than prior single-source methods on real-world code.
Where Pith is reading between the lines
- Similar dual-branch fusion with alignment could apply to other code tasks such as defect prediction where multiple representations of the same code are available.
- The joint supervision pattern might reduce the cost of collecting separate labels for detection versus localization in future datasets.
- If the alignment holds, the approach could support incremental updates when new vulnerability patterns appear without retraining from scratch.
Load-bearing premise
Control-dependency features and semantic features are complementary enough that contrastive alignment plus bidirectional cross-attention can close their representation gap, and joint supervision at both levels produces gains rather than conflicts.
What would settle it
Evaluating DCVD on the large-scale real-world vulnerability benchmark and observing that it fails to exceed state-of-the-art accuracy on function-level detection or statement-level localization metrics would falsify the performance claim.
Figures

read the original abstract
Software vulnerability detection plays a critical role in ensuring system security, where real-world auditing requires not only determining whether a function is vulnerable but also pinpointing the specific lines responsible. However, existing approaches either rely on a single information source -- sequential, structural, or semantic -- failing to jointly exploit the complementary strengths across modalities, or treat statement-level localization merely as a byproduct of function-level detection without explicit line-level supervision. To address these limitations, we propose DCVD (Dual-Channel Cross-Modal Vulnerability Detection), a unified framework that performs joint function-level detection and statement-level localization. DCVD extracts control-dependency and semantic features through two parallel branches and integrates them via contrastive alignment coupled with bidirectional cross-attention, effectively bridging the cross-modal representation gap. It further introduces explicit supervision signals at both the function and statement levels, enabling collaborative optimization across the two granularities. Extensive experiments on a large-scale real-world vulnerability benchmark demonstrate that DCVD consistently outperforms state-of-the-art methods on both function-level detection and statement-level localization. Our code is available at https://github.com/vinsontang1/DCVD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DCVD, a unified framework for joint function-level vulnerability detection and statement-level localization. It extracts control-dependency features and semantic features via two parallel branches, fuses them using contrastive alignment together with bidirectional cross-attention, and applies explicit joint supervision at both granularities. Experiments on a large-scale real-world vulnerability benchmark are reported to show consistent outperformance over state-of-the-art methods on both tasks; code is released publicly.
Significance. If the experimental claims hold under scrutiny, the work offers a practical advance in automated vulnerability analysis by combining complementary code modalities and supplying explicit line-level supervision rather than treating localization as a byproduct. The public code release is a clear strength that supports reproducibility and follow-on research.
major comments (1)
- §4 (Experiments): the central claim of consistent outperformance on both function-level detection and statement-level localization rests on the reported benchmark results, yet the manuscript must supply complete tables with all baselines, ablation variants, exact metrics (precision, recall, F1, IoU, etc.), and statistical significance tests; without these the claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [—] §4 (Experiments): the central claim of consistent outperformance on both function-level detection and statement-level localization rests on the reported benchmark results, yet the manuscript must supply complete tables with all baselines, ablation variants, exact metrics (precision, recall, F1, IoU, etc.), and statistical significance tests; without these the claim cannot be evaluated.
Authors: We agree that complete experimental reporting is required to substantiate the claims. The current manuscript presents main results and selected ablations in Tables 1–3 but does not include every baseline variant, the full metric suite (e.g., IoU for localization), or statistical significance tests. In the revised version we will expand Section 4 with comprehensive tables that list all baselines, additional ablation configurations, precision/recall/F1/IoU (and any other relevant metrics), and statistical significance tests (e.g., paired t-tests or McNemar’s test with p-values). These additions will be made without altering the experimental protocol or results. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a standard multimodal fusion architecture (dual branches for control-dependency and semantic features, contrastive alignment, bidirectional cross-attention, joint supervision) without any equations, derivations, or parameter-fitting steps that reduce claimed performance to inputs by construction. Central claims rest on empirical benchmark results rather than self-referential definitions or self-citation chains. No load-bearing self-citations, ansatzes smuggled via prior work, or renamings of known results appear; the method is presented as an engineering combination of established techniques whose effectiveness is evaluated externally.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DCVD extracts control-dependency and semantic features through two parallel branches and integrates them via contrastive alignment coupled with bidirectional cross-attention... explicit supervision signals at both the function and statement levels
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The alignment loss is Lalign = -1/B sum log exp(sim(gi,ci)/τ) ... total training objective L = α(Lf + β·Lalign) + (1-α)·Ls
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
DARPA Information Survivability Conference and Expo (DISCEX) , volume=
Buffer overflows: Attacks and defenses for the vulnerability of the decade , author=. DARPA Information Survivability Conference and Expo (DISCEX) , volume=
-
[2]
Software: practice and experience , volume=
Buffer overflow and format string overflow vulnerabilities , author=. Software: practice and experience , volume=. 2003 , publisher=
work page 2003
-
[3]
Proceedings of the 2012 International Symposium on Software Testing and Analysis , pages=
Undangle: early detection of dangling pointers in use-after-free and double-free vulnerabilities , author=. Proceedings of the 2012 International Symposium on Software Testing and Analysis , pages=
work page 2012
- [4]
-
[5]
Defining code-injection attacks , author=. Acm Sigplan Notices , volume=. 2012 , publisher=
work page 2012
- [6]
-
[7]
Tsinghua Science and Technology , volume=
Software vulnerabilities overview: A descriptive study , author=. Tsinghua Science and Technology , volume=. 2019 , publisher=
work page 2019
-
[8]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
Pre-training by predicting program dependencies for vulnerability analysis tasks , author=. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
-
[9]
Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
Combining structured static code information and dynamic symbolic traces for software vulnerability prediction , author=. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering , pages=
-
[10]
IEEE Transactions on Software Engineering , volume=
Vulnerability detection by learning from syntax-based execution paths of code , author=. IEEE Transactions on Software Engineering , volume=. 2023 , publisher=
work page 2023
-
[11]
Scale: Constructing structured natural language comment trees for software vulnerability detection , author=. Proceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis , pages=
-
[12]
2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
When less is enough: Positive and unlabeled learning model for vulnerability detection , author=. 2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2023 , organization=
work page 2023
-
[13]
arXiv preprint arXiv:2406.05892 , year=
Security vulnerability detection with multitask self-instructed fine-tuning of large language models , author=. arXiv preprint arXiv:2406.05892 , year=
-
[14]
Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
Matsvd: Boosting statement-level vulnerability detection via dependency-based attention , author=. Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
-
[15]
Proceedings of the IEEE/ACM 46th international conference on software engineering , pages=
Towards causal deep learning for vulnerability detection , author=. Proceedings of the IEEE/ACM 46th international conference on software engineering , pages=
-
[16]
PTLVD: Program slicing and transformer-based line-level vulnerability detection system , author=. 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM) , pages=. 2023 , organization=
work page 2023
-
[17]
Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
Dfept: data flow embedding for enhancing pre-trained model based vulnerability detection , author=. Proceedings of the 15th Asia-Pacific Symposium on Internetware , pages=
-
[18]
Leveraging user-defined identifiers for counterfactual data generation in source code vulnerability detection , author=. 2023 IEEE 23rd International Working Conference on Source Code Analysis and Manipulation (SCAM) , pages=. 2023 , organization=
work page 2023
-
[19]
Proceedings of the 19th international conference on mining software repositories , pages=
Linevul: A transformer-based line-level vulnerability prediction , author=. Proceedings of the 19th international conference on mining software repositories , pages=
-
[20]
2022 International joint conference on neural networks (IJCNN) , pages=
Vulberta: Simplified source code pre-training for vulnerability detection , author=. 2022 International joint conference on neural networks (IJCNN) , pages=. 2022 , organization=
work page 2022
-
[21]
Graph attention networks , author=. arXiv preprint arXiv:1710.10903 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Codebert: A pre-trained model for programming and natural languages , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
work page 2020
-
[23]
arXiv preprint arXiv:2309.08715 , year=
Formalizing BPE tokenization , author=. arXiv preprint arXiv:2309.08715 , year=
-
[24]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[25]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Generalization-enhanced code vulnerability detection via multi-task instruction fine-tuning , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
work page 2024
-
[26]
GraphCodeBERT: Pre-training Code Representations with Data Flow
Graphcodebert: Pre-training code representations with data flow , author=. arXiv preprint arXiv:2009.08366 , year=
work page internal anchor Pith review arXiv 2009
-
[27]
Proceedings of the 17th international conference on mining software repositories , pages=
AC/C++ code vulnerability dataset with code changes and CVE summaries , author=. Proceedings of the 17th international conference on mining software repositories , pages=
-
[28]
Improving text classification with weighted word embeddings via a multi-channel TextCNN model , author=. Neurocomputing , volume=. 2019 , publisher=
work page 2019
-
[29]
Vulnerability detection with fine-grained interpretations , author=. Proceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering , pages=
-
[30]
Proceedings of the 19th international conference on mining software repositories , pages=
Linevd: Statement-level vulnerability detection using graph neural networks , author=. Proceedings of the 19th international conference on mining software repositories , pages=
-
[31]
VELVET: a noVel Ensemble Learning approach to automatically locate VulnErable sTatements , author=. 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER) , pages=. 2022 , organization=
work page 2022
-
[32]
2021 International Joint Conference on Neural Networks (IJCNN) , pages=
Information-theoretic source code vulnerability highlighting , author=. 2021 International Joint Conference on Neural Networks (IJCNN) , pages=. 2021 , organization=
work page 2021
-
[33]
arXiv preprint arXiv:2509.21782 , year=
Benchmarking mllm-based web understanding: Reasoning, robustness and safety , author=. arXiv preprint arXiv:2509.21782 , year=
-
[34]
arXiv preprint arXiv:2509.12159 , year=
Efficientuicoder: Efficient mllm-based ui code generation via input and output token compression , author=. arXiv preprint arXiv:2509.12159 , year=
-
[35]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Queryattack: Jailbreaking aligned large language models using structured non-natural query language , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[36]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Slidecoder: Layout-aware rag-enhanced hierarchical slide generation from design , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[37]
arXiv preprint arXiv:2603.00155 , year=
EfficientPosterGen: Semantic-aware Efficient Poster Generation via Token Compression and Accurate Violation Detection , author=. arXiv preprint arXiv:2603.00155 , year=
-
[38]
2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=
Interaction2code: Benchmarking mllm-based interactive webpage code generation from interactive prototyping , author=. 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , pages=. 2025 , organization=
work page 2025
-
[39]
arXiv preprint arXiv:2506.06251 , year=
Designbench: A comprehensive benchmark for mllm-based front-end code generation , author=. arXiv preprint arXiv:2506.06251 , year=
-
[40]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Rethinking Multimodal Point Cloud Completion: A Completion-by-Correction Perspective , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.