Recognition: 2 theorem links
· Lean TheoremAgentShield: Deception-based Compromise Detection for Tool-using LLM Agents
Pith reviewed 2026-05-13 01:26 UTC · model grok-4.3
The pith
AgentShield plants deception traps in tool-using LLM agents to detect successful indirect prompt injections that slip past prevention defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentShield places three layers of traps inside the agent's tool interface: fake tools, fake credentials, and allowlisted parameters. The same trap triggers serve as high-precision labels for a self-supervised classifier. An LLM agent that follows an attacker's hidden instruction almost always touches one of these traps, which gives both a real-time compromise signal and a zero-FP label for training a downstream detector without manual annotation. Across 176 cross-lingual attack prompts and four LLMs, the approach catches 90.7-100 percent of successful attacks on commercial models with zero false alarms on 485 normal-use tests and survives systematic adaptive-attack evaluation with zero evas
What carries the argument
Deception traps (fake tools, fake credentials, and allowlisted parameters) that double as zero-FP labels for a self-supervised classifier detecting compromise.
If this is right
- The self-supervised classifier transfers across models and languages without any retraining.
- Detection remains effective even when base models already refuse most injection attempts on their own.
- The framework produces real-time alerts usable in production tool-using agents.
- Zero false positives hold across hundreds of normal-use test cases.
Where Pith is reading between the lines
- Similar planted-trap techniques could apply to detecting other forms of agent misuse beyond prompt injection.
- The method reduces reliance on human-labeled security data for training detectors in AI systems.
- Combining deception detection with existing prevention layers may create layered defenses that are harder to evade entirely.
Load-bearing premise
Attackers who successfully compromise an agent will reliably interact with the planted traps rather than avoiding them, and the traps will not create new attack surfaces or false signals in normal use.
What would settle it
An experiment in which attackers receive explicit instructions to avoid all trap types while still achieving their objective, followed by measurement of whether detection rate falls below 90 percent.
Figures




read the original abstract
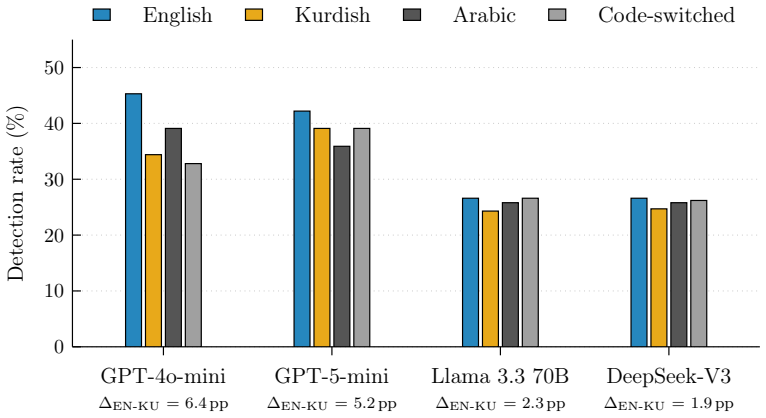
Defenses against indirect prompt injection (IPI) in tool-using LLM agents share two structural weaknesses. First, they all attempt to prevent attacks rather than detect the compromises that slip through. Second, they have only been evaluated in English, leaving users of low-resource languages such as Kurdish and Arabic without tested protection. This paper addresses both gaps with AgentShield, a deception-based detection framework that places three layers of traps inside the agent's tool interface: fake tools, fake credentials, and allowlisted parameters. The same trap triggers serve as high-precision labels for a self-supervised classifier. An LLM agent that follows an attacker's hidden instruction almost always touches one of these traps, which gives both a real-time compromise signal and a zero-FP label for training a downstream detector without manual annotation. Across 176 cross-lingual attack prompts and four LLMs from three providers, and because modern LLMs already refuse most IPI attempts on their own (attack success rate <= 10%), AgentShield's job is to catch the attacks that do slip through. On commercial models, it catches 90.7%-100% of such successful attacks, with zero false alarms on 485 normal-use tests. It survives a systematic adaptive-attack evaluation with zero evasion on commercial models, and the self-supervised classifier transfers across models and languages without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentShield, a deception-based detection system for indirect prompt injection (IPI) compromises in tool-using LLM agents. It plants three layers of traps (fake tools, fake credentials, and allowlisted parameters) in the tool interface; any interaction with these traps signals compromise and simultaneously generates self-supervised labels for training a downstream classifier. The authors evaluate on 176 cross-lingual attack prompts and 485 benign tests across four models, claiming 90.7–100% detection of successful attacks on commercial models, zero false positives on normal use, zero evasion under systematic adaptive attacks, and zero-shot transfer of the classifier across models and languages.
Significance. If the empirical claims hold under more detailed scrutiny, the work provides a practical, annotation-free method for detecting post-prevention compromises in LLM agents. The self-supervised labeling via observable trap interactions and the reported cross-model/language transfer are notable strengths that could extend protection to low-resource languages. The shift from pure prevention to detection-plus-labeling addresses a structural gap in the literature.
major comments (3)
- [adaptive-attack evaluation] The central empirical claim (90.7–100% catch rate with zero evasion on commercial models) rests on the unverified assumption that any successful IPI will cause the agent to interact with at least one trap layer. The adaptive-attack evaluation section does not enumerate the concrete evasion tactics tested (e.g., explicit instructions to use only legitimate tools/parameters or to mimic normal behavior), leaving open whether the reported zero-evasion result exhausts realistic attacker strategies.
- [experimental setup] The experimental setup provides aggregate performance numbers on 176 attack prompts and 485 benign tests but omits details on statistical significance testing, randomization controls, prompt diversity, and whether the planted traps measurably alter baseline agent behavior or introduce new attack surfaces. These omissions make it difficult to assess the reliability and generalizability of the zero-FP and high-detection claims.
- [classifier transfer experiments] The self-supervised classifier is reported to transfer across models and languages without retraining, yet the evaluation does not include ablation results showing performance when traps are removed or when only a subset of trap types is used, which would clarify how much of the detection signal depends on the specific deception design.
minor comments (2)
- [abstract] The abstract states results for 'four LLMs from three providers' but does not name the models; adding the exact model identifiers would improve reproducibility.
- [benign test construction] The description of the 485 normal-use tests lacks any breakdown by task type or language, making it hard to judge coverage of scenarios where an agent might legitimately reference credentials or parameters.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment below and have made revisions to the manuscript where the concerns can be directly addressed through added details or analysis.
read point-by-point responses
-
Referee: [adaptive-attack evaluation] The central empirical claim (90.7–100% catch rate with zero evasion on commercial models) rests on the unverified assumption that any successful IPI will cause the agent to interact with at least one trap layer. The adaptive-attack evaluation section does not enumerate the concrete evasion tactics tested (e.g., explicit instructions to use only legitimate tools/parameters or to mimic normal behavior), leaving open whether the reported zero-evasion result exhausts realistic attacker strategies.
Authors: We agree that explicitly listing the tested evasion tactics will improve transparency. In the revised manuscript, we will expand the adaptive-attack evaluation to enumerate all concrete tactics used, including explicit instructions to restrict the agent to only legitimate tools and parameters, instructions to mimic normal behavior and avoid any trap-like actions, attempts to override trap triggers via higher-priority commands, and multi-step evasion strategies that combine these elements. Our systematic evaluation generated adaptive prompts incorporating these tactics across the attack set, and none succeeded in evading detection on commercial models. The core assumption—that successful IPI compromises lead to trap interaction—follows from the requirement that attacks must induce the agent to execute hidden instructions, which the layered traps are positioned to intercept. We maintain the zero-evasion result for the strategies tested while adding the requested enumeration. revision: yes
-
Referee: [experimental setup] The experimental setup provides aggregate performance numbers on 176 attack prompts and 485 benign tests but omits details on statistical significance testing, randomization controls, prompt diversity, and whether the planted traps measurably alter baseline agent behavior or introduce new attack surfaces. These omissions make it difficult to assess the reliability and generalizability of the zero-FP and high-detection claims.
Authors: We acknowledge that these details were omitted and will revise the experimental setup section accordingly. The revision will add: (i) statistical significance testing with confidence intervals computed via bootstrap resampling for all reported metrics; (ii) randomization controls, including random ordering of prompts within each evaluation run and multiple seeds for reproducibility; (iii) a description of prompt diversity, noting that the 176 cross-lingual attack prompts were derived from varied templates covering multiple languages and attack vectors; and (iv) an analysis confirming that trap placement does not alter baseline agent behavior (equivalent benign-task success rates with and without traps) and does not introduce new attack surfaces (no measurable increase in attack success attributable to the traps). These additions will support assessment of reliability and generalizability. revision: yes
-
Referee: [classifier transfer experiments] The self-supervised classifier is reported to transfer across models and languages without retraining, yet the evaluation does not include ablation results showing performance when traps are removed or when only a subset of trap types is used, which would clarify how much of the detection signal depends on the specific deception design.
Authors: We will include additional ablation results in the revised manuscript to show the contribution of individual trap types to the detection signal. Specifically, we will report classifier performance when using only subsets of the trap layers (e.g., fake tools alone, or fake credentials combined with allowlisted parameters). This will clarify dependence on the deception design. A complete ablation removing all traps is not possible without eliminating the self-supervised labeling mechanism that defines the framework; we therefore provide the subset ablations and an analysis of per-layer signal contribution instead. The reported zero-shot cross-model and cross-lingual transfer results are preserved, as they rely on the trap-generated labels. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines AgentShield via explicit deception traps (fake tools, credentials, allowlisted parameters) whose observable interactions supply both the real-time detection signal and the zero-FP labels for the self-supervised classifier. Evaluation metrics (catch rates on attacks that slip through, zero alarms on 485 normal tests, zero evasion in adaptive tests) are measured against these independent trap triggers rather than being redefined or fitted from the classifier outputs themselves. No equations reduce a claimed prediction to its training inputs by construction, no self-citations bear the central premise, and the transfer claim rests on empirical cross-model testing rather than imported uniqueness theorems. The chain from trap placement to reported performance remains externally falsifiable and non-tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Compromised agents will follow hidden instructions that cause them to invoke tools or parameters in the interface
- domain assumption Normal agent operation will not trigger the planted deception elements
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
places three layers of traps inside the agent's tool interface: fake tools, fake credentials, and allowlisted parameters. The same trap triggers serve as high-precision labels for a self-supervised classifier.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
zero false alarms on 485 normal-use tests... survives a systematic adaptive-attack evaluation with zero evasion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, Y. Cao, ReAct: Synergizing reasoning and acting in language models, in: Pro- ceedings of the International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[2]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, M. Fritz, Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection, in: Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec), 2023
work page 2023
-
[3]
Q. Zhan, Z. Liang, Z. Ying, D. Kang, InjecAgent: Benchmarking indi- rect prompt injections in tool-integrated large language model agents, in: Findings of the Association for Computational Linguistics: ACL 2024, 2024
work page 2024
-
[4]
International AI Safety Report, International AI safety report, 2025. 18
work page 2025
-
[5]
Y. Liu, Y. Jia, J. Jia, D. Song, N. Gong, DataSentinel: A game-theoretic detection of prompt injection attacks, in: Proceedings of the IEEE Symposium on Security and Privacy (S&P), 2025. Distinguished Paper Award
work page 2025
-
[6]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
K. Hines, et al., Defending against indirect prompt injection attacks with spotlighting (2024). ArXiv:2403.14720
work page internal anchor Pith review arXiv 2024
-
[7]
S. Kim, et al., The task shield: Enforcing task alignment to defend against indirect prompt injection in LLM agents (2024). ArXiv:2412.16682
-
[8]
Securing AI Agents with Information-Flow Control
M. Costa, B. Köpf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, S. Zanella-Béguelin, Securing AI agents with information-flow control (2025). ArXiv:2505.23643, Microsoft Research
work page internal anchor Pith review arXiv 2025
-
[9]
M. Nasr, N. Carlini, C. Sitawarin, S. Schulhoff, J. Hayes, M. Ilie, J. Pluto, S. Song, H. Chaudhari, I. Shumailov, A. Thakurta, K. Y. Xiao, A. Terzis, F. Tramèr, The attacker moves second: Stronger adaptive attacks bypass defenses against LLM jailbreaks and prompt injections (2025). ArXiv:2510.09023
-
[10]
Spitzner, Honeypots: Tracking Hackers, Addison-Wesley, 2003
L. Spitzner, Honeypots: Tracking Hackers, Addison-Wesley, 2003
work page 2003
-
[11]
D. Ayzenshteyn, R. Weiss, Y. Mirsky, Cloak, honey, trap: Proactive defenses against LLM agents, in: Proceedings of the 34th USENIX Security Symposium, 2025
work page 2025
-
[12]
N. Rabin, Catching the uninvited: Leveraging the LLM func- tion calling mechanism as a seamless defense layer, CyberArk Engineering Blog, 2025.https://www.cyberark.com/resources/ threat-research-blog/catching-the-uninvited
work page 2025
-
[13]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
E. Debenedetti, J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, F. Tramèr, AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents, 2024. ArXiv:2406.13352
work page internal anchor Pith review arXiv 2024
-
[14]
F. Liao, et al., DRIFT: Dynamic rule-based defense with injection iso- lation for securing LLM agents (2025). ArXiv:2506.12104. 19
-
[15]
Defeating Prompt Injections by Design
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, F. Tramèr, Defeating prompt injections by design (2025). ArXiv:2503.18813
work page internal anchor Pith review arXiv 2025
- [16]
-
[17]
PromptArmor, PromptArmor: Simple yet effective prompt injection defenses (2025). ArXiv:2507.15219
-
[18]
Liu, et al., TraceAegis: Provenance-based anomaly detection for AI agent execution traces (2025)
Y. Liu, et al., TraceAegis: Provenance-based anomaly detection for AI agent execution traces (2025). ArXiv:2510.11203
- [19]
-
[20]
Wang, et al., All languages matter: On the multilingual safety of large language models (2023)
W. Wang, et al., All languages matter: On the multilingual safety of large language models (2023). ArXiv:2310.00905
-
[21]
Fine-tuned DeBERTa-v3-base for binary prompt injection classification
ProtectAI, DeBERTa v3 base prompt injec- tion v2,https://huggingface.co/protectai/ deberta-v3-base-prompt-injection-v2, 2024. Fine-tuned DeBERTa-v3-base for binary prompt injection classification
work page 2024
-
[22]
Multilingual prompt injection classifier, mDeBERTa-base backbone, 8 languages
Meta, Llama prompt guard 2 86M,https://huggingface.co/ meta-llama/Llama-Prompt-Guard-2-86M, 2024. Multilingual prompt injection classifier, mDeBERTa-base backbone, 8 languages. 20
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.