Recognition: 2 theorem links
· Lean TheoremTowards Model-Free Learning in Dynamic Population Games: An Application to Karma Economies
Pith reviewed 2026-05-13 01:13 UTC · model grok-4.3
The pith
A new agent learns a near-optimal policy in a Karma economy using only its own experience and Deep Q-Networks, with error bounds that shrink as replay buffer and population size grow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In Karma dynamic population games, a model-free learner that joins at the stationary Nash equilibrium incurs suboptimality of order O(1/sqrt(Ns)) from DQN approximation error plus O(1/N) from mean-field perturbation, where Ns is replay buffer size and N is population size. When agents must discover the equilibrium from scratch, combining deep RL with fictitious play and smoothed policy iteration produces policies that converge empirically to a point close to the centrally computed stationary Nash equilibrium.
What carries the argument
Deep Q-Networks trained on private trajectories inside the mean-field limit of the dynamic population game, augmented by fictitious play for from-scratch equilibrium search.
If this is right
- Larger replay buffers and larger populations both reduce the gap between learned and optimal policies.
- Karma economies become feasible in settings where no central authority can compute or broadcast the equilibrium in advance.
- Model-free methods extend the practical reach of dynamic population games beyond fully observed, centrally solved models.
Where Pith is reading between the lines
- The same DQN-plus-fictitious-play recipe may transfer to other mean-field resource allocation problems that lack closed-form equilibria.
- When all agents learn simultaneously the environment becomes non-stationary, which could slow or prevent convergence to the stationary Nash equilibrium.
- Tighter theoretical guarantees for the from-scratch learning procedure would close the gap between the provable one-sided result and the empirical two-sided result.
Load-bearing premise
That standard DQN convergence guarantees transfer directly to the Karma dynamic population game setting and that the mean-field approximation remains accurate for large but finite populations.
What would settle it
A controlled simulation of a Karma economy in which the measured suboptimality gap fails to decrease proportionally to 1 over square root of replay buffer size or 1 over population size as those quantities are increased.
Figures








read the original abstract
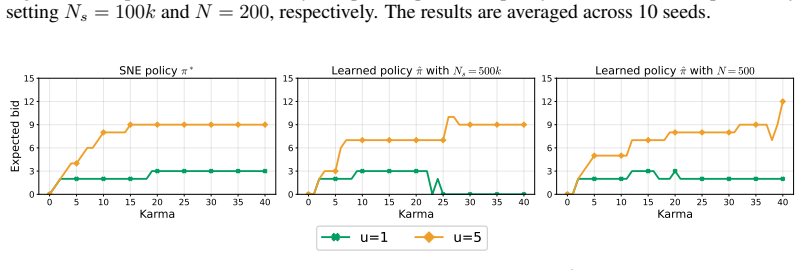
Dynamic Population Games (DPGs) provide a tractable framework for modeling strategic interactions in large populations of self-interested agents, and have been successfully applied to the design of Karma economies, a class of fair non-monetary resource allocation mechanisms. Despite their appealing theoretical properties, existing computational tools for DPGs assume full knowledge of the game model and operate in a centralized fashion, limiting their applicability in realistic settings where agents have access only to their own private experience. This paper takes a step towards addressing this gap by studying model-free equilibrium learning in Karma DPGs. First, we analyze the setting in which a novel agent joins a Karma DPG already at its Stationary Nash Equilibrium (SNE) and learns a policy via Deep Q-Networks (DQN) without knowledge of the game model. Leveraging recent convergence results for DQN, we establish a suboptimality bound consisting of a DQN approximation error of order $O(1/\sqrt{N_s})$ and a mean field perturbation error of order $O(1/N)$, where $N_s$ is the replay buffer size and $N$ is the population size. Second, we consider the challenging problem of learning the SNE from scratch. We show empirically that combining deep RL with fictitious play and smoothed policy iteration allows agents to converge, in a model-free fashion, to a configuration close to the centrally computed SNE. Together, these contributions support the vision of Karma economies as practical tools for fair resource allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies model-free learning in Dynamic Population Games (DPGs) applied to Karma economies. For an agent joining an existing Stationary Nash Equilibrium (SNE), it uses DQN and leverages external DQN convergence theorems to derive a suboptimality bound combining an O(1/√Ns) approximation error term (Ns = replay buffer size) with an O(1/N) mean-field perturbation term (N = population size). For learning the SNE from scratch, it empirically shows that deep RL combined with fictitious play and smoothed policy iteration yields configurations close to the centrally computed SNE.
Significance. If the suboptimality bound holds under the induced MDP structure, the work would meaningfully advance decentralized, model-free methods for large-population strategic interactions, with direct relevance to practical Karma economy design. The empirical demonstration of convergence from scratch provides supporting evidence for feasibility without centralized model knowledge. No machine-checked proofs or open reproducible code are referenced, but the explicit combination of external convergence results with mean-field analysis is a constructive step if the transfer conditions are verified.
major comments (2)
- [Abstract / theoretical bound derivation] Abstract and theoretical analysis section: the suboptimality bound is stated as following directly from 'leveraging recent convergence results for DQN' plus an O(1/N) mean-field term, but the manuscript provides no verification that the cited DQN theorems' assumptions (time-homogeneous transitions, bounded rewards, ergodicity or contraction conditions on the effective single-agent MDP) hold when the reward and transition kernels are induced by the stationary mean-field karma distribution at SNE. Without this check or an adapted derivation, the O(1/√Ns) term is not guaranteed to transfer.
- [Empirical results] Empirical evaluation section: the claim that agents 'converge, in a model-free fashion, to a configuration close to the centrally computed SNE' is presented without quantitative metrics (e.g., distance to SNE, regret, or statistical controls across runs), making it impossible to assess the strength of the empirical support for the second contribution.
minor comments (1)
- [Abstract] Notation for Ns (replay buffer size) and N (population size) should be introduced with explicit definitions and distinguished from other parameters in the DPG formulation.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the clarity and rigor of our work. We address each major comment below and outline the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / theoretical bound derivation] Abstract and theoretical analysis section: the suboptimality bound is stated as following directly from 'leveraging recent convergence results for DQN' plus an O(1/N) mean-field term, but the manuscript provides no verification that the cited DQN theorems' assumptions (time-homogeneous transitions, bounded rewards, ergodicity or contraction conditions on the effective single-agent MDP) hold when the reward and transition kernels are induced by the stationary mean-field karma distribution at SNE. Without this check or an adapted derivation, the O(1/√Ns) term is not guaranteed to transfer.
Authors: We acknowledge the importance of verifying the applicability of the DQN convergence theorems to our setting. In the revised manuscript, we will add a dedicated paragraph in the theoretical analysis section arguing that the assumptions hold under the stationary mean-field at SNE. Specifically, the induced MDP is time-homogeneous because the population distribution is fixed at equilibrium; rewards are bounded by the model assumptions on utility functions; and ergodicity follows from the positive probability of karma transitions in the Karma economy dynamics, ensuring the contraction conditions are satisfied. This will confirm the transfer of the O(1/√Ns) bound. revision: yes
-
Referee: [Empirical results] Empirical evaluation section: the claim that agents 'converge, in a model-free fashion, to a configuration close to the centrally computed SNE' is presented without quantitative metrics (e.g., distance to SNE, regret, or statistical controls across runs), making it impossible to assess the strength of the empirical support for the second contribution.
Authors: We agree that quantitative metrics would strengthen the empirical claims. In the revision, we will include additional figures and tables reporting the L1 distance between the empirical population distribution and the SNE, average per-agent regret compared to the SNE policy, and results averaged over multiple independent runs with standard deviations to provide statistical controls. revision: yes
Circularity Check
No significant circularity: bound combines external DQN results with independent mean-field term
full rationale
The paper's central theoretical claim is a suboptimality bound obtained by adding an O(1/√Ns) DQN approximation error (taken from cited external convergence theorems) to an O(1/N) mean-field perturbation error. This addition does not reduce to any self-definitional loop, fitted input renamed as prediction, or self-citation chain within the paper. The empirical section on learning the SNE from scratch via deep RL plus fictitious play is presented as separate experimental evidence rather than a derived result that loops back to its own inputs. No ansatz is smuggled via citation, no uniqueness theorem is imported from the authors' prior work, and no known empirical pattern is merely renamed. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Recent convergence results for DQN apply to the Karma DPG setting
- domain assumption Mean-field approximation is valid for finite population size N
Reference graph
Works this paper leans on
-
[1]
Increasing the action gap: New operators for reinforcement learning
Marc G Bellemare, Georg Ostrovski, Arthur Guez, Philip Thomas, and Rémi Munos. Increasing the action gap: New operators for reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
work page 2016
-
[2]
Iterative solution of games by fictitious play.Act
George W Brown. Iterative solution of games by fictitious play.Act. Anal. Prod Allocation, 13(1):374, 1951
work page 1951
-
[3]
Learning in mean field games: the fictitious play
Pierre Cardaliaguet and Saeed Hadikhanloo. Learning in mean field games: the fictitious play. ESAIM: Control, Optimisation and Calculus of Variations, 23(2):569–591, 2017
work page 2017
-
[4]
Pierre Cardaliaguet and Charles-Albert Lehalle. Mean field game of controls and an application to trade crowding.Mathematics and Financial Economics, 12(3):335–363, 2018
work page 2018
-
[5]
Towards fair and efficient allocation of mobility-on-demand resources through a karma economy
Matteo Cederle, Saverio Bolognani, and Gian Antonio Susto. Towards fair and efficient allocation of mobility-on-demand resources through a karma economy. InProceedings of the 24th European Control Conference (ECC), 2026
work page 2026
-
[6]
Andrea Censi, Saverio Bolognani, Julian G Zilly, Shima Sadat Mousavi, and Emilio Frazzoli. Today me, tomorrow thee: Efficient resource allocation in competitive settings using karma games.arXiv preprint arXiv:1907.09198, 2019
-
[7]
Approximately solving mean field games via entropy-regularized deep reinforcement learning
Kai Cui and Heinz Koeppl. Approximately solving mean field games via entropy-regularized deep reinforcement learning. InInternational Conference on Artificial Intelligence and Statistics, pages 1909–1917. PMLR, 2021
work page 1909
-
[8]
On the convergence of model free learning in mean field games
Romuald Elie, Julien Perolat, Mathieu Laurière, Matthieu Geist, and Olivier Pietquin. On the convergence of model free learning in mean field games. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7143–7150, 2020
work page 2020
-
[9]
Ezzat Elokda, Saverio Bolognani, Andrea Censi, Florian Dörfler, and Emilio Frazzoli. Dynamic population games: A tractable intersection of mean-field games and population games.IEEE Control Systems Letters, 8:1072–1077, 2024
work page 2024
-
[10]
Ezzat Elokda, Saverio Bolognani, Andrea Censi, Florian Dörfler, and Emilio Frazzoli. A self-contained karma economy for the dynamic allocation of common resources.Dynamic Games and Applications, 14(3):578–610, 2024
work page 2024
-
[11]
Ezzat Elokda, Carlo Cenedese, Kenan Zhang, Andrea Censi, John Lygeros, Emilio Frazzoli, and Florian Dörfler. Carma: Fair and efficient bottleneck congestion management via nontradable karma credits.Transportation Science, 59(2):340–359, 2025
work page 2025
-
[12]
Ezzat Elokda, Andrea Censi, Emilio Frazzoli, Florian Dörfler, and Saverio Bolognani. A vision for trustworthy, fair, and efficient socio-technical control using karma economies.Annual Reviews in Control, 60:101026, 2025
work page 2025
-
[13]
Jean-Pierre Fouque, Mathieu Laurière, and Mengrui Zhang. Convergence of actor-critic learning for mean field games and mean field control in continuous spaces.arXiv preprint arXiv:2511.06812, 2025. 10
-
[14]
Yuan Gao, Alex Peysakhovich, and Christian Kroer. Online market equilibrium with application to fair division.Advances in Neural Information Processing Systems, 34:27305–27318, 2021
work page 2021
-
[15]
Learning mean-field games.Advances in neural information processing systems, 32, 2019
Xin Guo, Anran Hu, Renyuan Xu, and Junzi Zhang. Learning mean-field games.Advances in neural information processing systems, 32, 2019
work page 2019
-
[16]
Xin Guo, Anran Hu, Renyuan Xu, and Junzi Zhang. A general framework for learning mean- field games.Mathematics of Operations Research, 48(2):656–686, 2023
work page 2023
-
[17]
Minyi Huang, Roland P Malhamé, and Peter E Caines. Large population stochastic dynamic games: closed-loop mckean-vlasov systems and the nash certainty equivalence principle. 2006
work page 2006
-
[18]
Strategy proofness of voting procedures with lotteries as outcomes and infinite sets of strategies
Aanund Hylland. Strategy proofness of voting procedures with lotteries as outcomes and infinite sets of strategies. Technical report, mimeo, 1980
work page 1980
-
[19]
The efficient allocation of individuals to positions
Aanund Hylland and Richard Zeckhauser. The efficient allocation of individuals to positions. Journal of Political economy, 87(2):293–314, 1979
work page 1979
-
[20]
Mean field games.Japanese journal of mathematics, 2(1):229–260, 2007
Jean-Michel Lasry and Pierre-Louis Lions. Mean field games.Japanese journal of mathematics, 2(1):229–260, 2007
work page 2007
-
[21]
Scalable deep rein- forcement learning algorithms for mean field games
Mathieu Lauriere, Sarah Perrin, Sertan Girgin, Paul Muller, Ayush Jain, Theophile Cabannes, Georgios Piliouras, Julien Pérolat, Romuald Elie, Olivier Pietquin, et al. Scalable deep rein- forcement learning algorithms for mean field games. InInternational conference on machine learning, pages 12078–12095. PMLR, 2022
work page 2022
-
[22]
Learning in mean field games: A survey.arXiv preprint arXiv:2205.12944, 2022
Mathieu Laurière, Sarah Perrin, Julien Pérolat, Sertan Girgin, Paul Muller, Romuald Élie, Matthieu Geist, and Olivier Pietquin. Learning in mean field games: A survey.arXiv preprint arXiv:2205.12944, 2022
-
[23]
Mathieu Laurière, Jiahao Song, and Qing Tang. Policy iteration method for time-dependent mean field games systems with non-separable hamiltonians.Applied Mathematics & Optimization, 87(2):17, 2023
work page 2023
-
[24]
Lorenzo Magnino, Jiacheng Shen, Matthieu Geist, Olivier Pietquin, and Mathieu Laurière. Bench-mfg: A benchmark suite for learning in stationary mean field games.arXiv preprint arXiv:2602.12517, 2026
-
[25]
Weichao Mao, Haoran Qiu, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Ravishankar Iyer, and Tamer Basar. A mean-field game approach to cloud resource management with function approximation.Advances in Neural Information Processing Systems, 35:36243–36258, 2022
work page 2022
-
[26]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
work page 2015
-
[27]
Antonio Ocello, Daniil Tiapkin, Lorenzo Mancini, Mathieu Lauriere, and Eric Moulines. Finite- sample convergence bounds for trust region policy optimization in mean-field games.arXiv preprint arXiv:2505.22781, 2025
-
[28]
Scaling up mean field games with online mirror descent
Julien Perolat, Sarah Perrin, Romuald Elie, Mathieu Laurière, Georgios Piliouras, Matthieu Geist, Karl Tuyls, and Olivier Pietquin. Scaling up mean field games with online mirror descent. arXiv preprint arXiv:2103.00623, 2021
-
[29]
Mean field games flock! the reinforcement learning way.arXiv preprint arXiv:2105.07933, 2021
Sarah Perrin, Mathieu Laurière, Julien Pérolat, Matthieu Geist, Romuald Élie, and Olivier Pietquin. Mean field games flock! the reinforcement learning way.arXiv preprint arXiv:2105.07933, 2021
-
[30]
Fictitious play for mean field games: Continuous time analysis and applications
Sarah Perrin, Julien Pérolat, Mathieu Laurière, Matthieu Geist, Romuald Elie, and Olivier Pietquin. Fictitious play for mean field games: Continuous time analysis and applications. Advances in neural information processing systems, 33:13199–13213, 2020. 11
work page 2020
-
[31]
Mean field game for modeling of covid-19 spread
Viktoriya Petrakova and Olga Krivorotko. Mean field game for modeling of covid-19 spread. Journal of Mathematical Analysis and Applications, 514(1):126271, 2022
work page 2022
-
[32]
William H Sandholm.Population games and evolutionary dynamics. MIT press, 2010
work page 2010
-
[33]
Reinforcement learning in stationary mean- field games
Jayakumar Subramanian and Aditya Mahajan. Reinforcement learning in stationary mean- field games. InProceedings of the 18th international conference on autonomous agents and multiagent systems, pages 251–259, 2019
work page 2019
-
[34]
Mohammad Amin Tajeddini and Hamed Kebriaei. A mean-field game method for decentralized charging coordination of a large population of plug-in electric vehicles.IEEE Systems Journal, 13(1):854–863, 2018
work page 2018
-
[35]
Qing Tang and Jiahao Song. Learning optimal policies in potential mean field games: Smoothed policy iteration algorithms.SIAM Journal on Control and Optimization, 62(1):351–375, 2024
work page 2024
-
[36]
Deep reinforcement learning with double q-learning
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
work page 2016
-
[37]
William Vickrey. Counterspeculation, auctions, and competitive sealed tenders.The Journal of finance, 16(1):8–37, 1961
work page 1961
-
[38]
Congestion theory and transport investment.The American economic review, 59(2):251–260, 1969
William S Vickrey. Congestion theory and transport investment.The American economic review, 59(2):251–260, 1969
work page 1969
-
[39]
Cédric Villani et al.Optimal transport: old and new, volume 338. Springer, 2009
work page 2009
-
[40]
Zida Wu, Mathieu Laurière, Samuel Jia Cong Chua, Matthieu Geist, Olivier Pietquin, and Ankur Mehta. Population-aware online mirror descent for mean-field games by deep reinforcement learning.arXiv preprint arXiv:2403.03552, 2024
-
[41]
Learning while playing in mean-field games: Convergence and optimality
Qiaomin Xie, Zhuoran Yang, Zhaoran Wang, and Andreea Minca. Learning while playing in mean-field games: Convergence and optimality. InInternational Conference on Machine Learning, pages 11436–11447. PMLR, 2021
work page 2021
-
[42]
Mean field multi-agent reinforcement learning
Yaodong Yang, Rui Luo, Minne Li, Ming Zhou, Weinan Zhang, and Jun Wang. Mean field multi-agent reinforcement learning. InInternational conference on machine learning, pages 5571–5580. PMLR, 2018
work page 2018
-
[43]
Policy mirror ascent for efficient and independent learning in mean field games
Batuhan Yardim, Semih Cayci, Matthieu Geist, and Niao He. Policy mirror ascent for efficient and independent learning in mean field games. InInternational Conference on Machine Learning, pages 39722–39754. PMLR, 2023
work page 2023
-
[44]
A policy optimization approach to the solution of unregularized mean field games
Sihan Zeng, Sujay Bhatt, Alec Koppel, and Sumitra Ganesh. A policy optimization approach to the solution of unregularized mean field games. InICML 2024 Workshop: Foundations of Reinforcement Learning and Control–Connections and Perspectives, 2024
work page 2024
-
[45]
Shuai Zhang, Hongkang Li, Meng Wang, Miao Liu, Pin-Yu Chen, Songtao Lu, Sijia Liu, Keerthiram Murugesan, and Subhajit Chaudhury. On the convergence and sample complexity analysis of deep q-networks with ε-greedy exploration.Advances in Neural Information Processing Systems, 36:13064–13102, 2023. 12 A Appendix This appendix provides theoretical derivations...
work page 2023
-
[46]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.