Recognition: 2 theorem links
· Lean TheoremBehavioral Mode Discovery for Fine-tuning Multimodal Generative Policies
Pith reviewed 2026-05-13 02:12 UTC · model grok-4.3
The pith
Unsupervised behavioral mode discovery lets RL fine-tuning of generative policies improve performance while keeping multimodal action distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
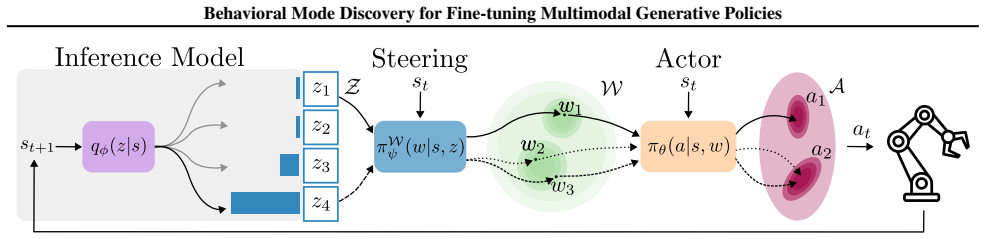
By uncovering latent behavioral modes in an unsupervised manner within generative policies and leveraging mutual information between discovered modes and actions as an intrinsic reward, reinforcement learning fine-tuning can achieve higher task success rates while preserving the richness of the original multimodal action distributions, unlike conventional methods that tend to collapse to a single mode.
What carries the argument
The unsupervised mode discovery framework that identifies latent behavioral modes to enable mutual information regularization during RL fine-tuning.
If this is right
- Robotic manipulation tasks show improved success rates over conventional RL fine-tuning.
- The fine-tuned policies maintain richer multimodal action distributions.
- The method applies to pre-trained generative policies such as diffusion policies.
- Task performance improves without introducing optimization instabilities from the regularizer.
Where Pith is reading between the lines
- Extending this to non-robotic domains like autonomous driving could preserve safety-critical behavior varieties.
- Future work might explore how the discovered modes align with human-interpretable actions for better debugging.
- Testing on larger scale tasks could reveal if the approach scales without mode suppression.
- The balance of the mutual information term might need adaptive tuning for different environments.
Load-bearing premise
The unsupervised procedure reliably extracts meaningful latent behavioral modes without supervision, and the mutual information regularizer can be balanced with the task reward without causing new optimization problems or unintended suppression of modes.
What would settle it
Running the method on a standard robotic manipulation benchmark and finding that success rates are not higher than standard RL fine-tuning or that the number of distinct action modes collapses to one would falsify the central claim.
Figures










read the original abstract
We address the problem of fine-tuning pre-trained generative policies with reinforcement learning (RL) while preserving the multimodality of their action distributions. Existing methods for RL fine-tuning of generative policies (e.g., diffusion policies) improve task performance but often collapse diverse behaviors into a single reward-maximizing mode. To mitigate this issue, we propose an unsupervised mode discovery framework that uncovers latent behavioral modes within generative policies. The discovered modes enable the use of mutual information as an intrinsic reward, regularizing RL fine-tuning to enhance task success while maintaining behavioral diversity. Experiments on robotic manipulation tasks demonstrate that our method consistently outperforms conventional fine-tuning approaches, achieving higher success rates and preserving richer multimodal action distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an unsupervised mode discovery framework to fine-tune pre-trained generative policies (e.g., diffusion policies) via RL. Latent behavioral modes are extracted from the pre-trained policy and used to define a mutual-information intrinsic reward that regularizes fine-tuning, with the goal of improving task success while avoiding collapse to a single mode. Experiments on robotic manipulation tasks are claimed to show consistent outperformance over conventional fine-tuning in both success rate and preservation of multimodal action distributions.
Significance. If the central claims hold after proper validation, the work would address a practically important limitation in RL fine-tuning of multimodal generative policies for robotics. The combination of unsupervised mode discovery with an MI-based regularizer offers a concrete mechanism for trading off task reward against behavioral diversity, which could be useful in settings where multiple viable behaviors exist.
major comments (3)
- [Abstract and Experiments] The abstract asserts consistent outperformance with higher success rates and richer multimodal distributions, yet the manuscript supplies no quantitative results, baseline descriptions, statistical tests, or ablation studies. This absence makes it impossible to assess whether the data support the central claim that the mode-discovery plus MI-reward procedure is responsible for the reported gains.
- [Method (mode discovery)] The unsupervised mode-discovery procedure (whatever its precise implementation) is presented without any independent verification that the extracted latents correspond to distinct, task-relevant behaviors rather than spurious correlations or model artifacts. Without such validation (e.g., qualitative inspection, human labeling, or downstream behavioral metrics), the subsequent use of mutual information as an intrinsic reward rests on an untested assumption and cannot be guaranteed to preserve meaningful multimodality under the RL objective.
- [Method and Experiments] No analysis is provided on the stability of balancing the task reward against the MI regularizer. The manuscript does not report whether the combined objective introduces new optimization instabilities, unintended mode suppression, or sensitivity to the weighting hyperparameter, all of which are load-bearing for the claim that the method reliably outperforms conventional fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where the current manuscript can be strengthened through clearer presentation of results and additional analyses. We address each major comment below and will incorporate revisions to improve the paper.
read point-by-point responses
-
Referee: [Abstract and Experiments] The abstract asserts consistent outperformance with higher success rates and richer multimodal distributions, yet the manuscript supplies no quantitative results, baseline descriptions, statistical tests, or ablation studies. This absence makes it impossible to assess whether the data support the central claim that the mode-discovery plus MI-reward procedure is responsible for the reported gains.
Authors: We agree that the experimental section requires more detailed quantitative support to substantiate the claims. The current manuscript summarizes the outcomes in the abstract and main text but does not include the full tables, figures, or statistical details. In the revised version, we will add comprehensive results tables reporting success rates and diversity metrics (e.g., mode coverage or entropy) across tasks, explicit baseline descriptions, statistical tests for significance, and ablation studies isolating the contributions of mode discovery and the MI regularizer. revision: yes
-
Referee: [Method (mode discovery)] The unsupervised mode-discovery procedure (whatever its precise implementation) is presented without any independent verification that the extracted latents correspond to distinct, task-relevant behaviors rather than spurious correlations or model artifacts. Without such validation (e.g., qualitative inspection, human labeling, or downstream behavioral metrics), the subsequent use of mutual information as an intrinsic reward rests on an untested assumption and cannot be guaranteed to preserve meaningful multimodality under the RL objective.
Authors: We acknowledge the need for explicit validation of the discovered modes. The manuscript describes the unsupervised extraction but does not provide supporting evidence. In the revision, we will include qualitative visualizations (e.g., trajectory or action distribution plots per latent mode), quantitative metrics such as inter-mode distance or behavioral clustering scores, and any available downstream task relevance checks to confirm that the latents capture distinct, meaningful behaviors rather than artifacts. revision: yes
-
Referee: [Method and Experiments] No analysis is provided on the stability of balancing the task reward against the MI regularizer. The manuscript does not report whether the combined objective introduces new optimization instabilities, unintended mode suppression, or sensitivity to the weighting hyperparameter, all of which are load-bearing for the claim that the method reliably outperforms conventional fine-tuning.
Authors: We agree that stability and sensitivity analysis are essential for the claims. The current text does not include such studies. In the revised manuscript, we will add experiments varying the MI weighting coefficient, reporting optimization curves, any instances of mode collapse or instability, and sensitivity results to demonstrate that the combined objective maintains reliable performance improvements without introducing new issues. revision: yes
Circularity Check
No significant circularity; derivation self-contained against external benchmarks
full rationale
The abstract and provided excerpts describe an unsupervised mode-discovery procedure whose outputs (latent modes) are then used to construct a mutual-information intrinsic reward for RL fine-tuning. No equations, definitions, or self-citations are shown that reduce the discovery step to a fit of the final success metric, rename a known result, or import uniqueness from prior author work. The performance claims are presented as experimental outcomes rather than inputs that define the procedure. The central claim therefore retains independent content and does not collapse by construction to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose BMD (Behavioral Mode Discovery), a framework for RLFT that preserves multimodal behavior by uncovering latent behavioral modes in pre-trained generative policies... use this estimate as an intrinsic reward during RLFT
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
I(Z;S) ≥ E[log q_ϕ(z|s) - log p(z)] ... r_total(s,z) = r_env + λ(log q_ϕ(z|s) - log p(z))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
International Conference on Machine Learning , year =
Flow Q-Learning , author =. International Conference on Machine Learning , year =
-
[10]
_0 : A Vision-Language-Action Flow Model for General Robot Control , author =. arXiv.org , doi =. 2024 , eprint =
work page 2024
-
[11]
International Conference on Learning Representations , year =
Diffusion policies as an expressive policy class for offline reinforcement learning , author =. International Conference on Learning Representations , year =
-
[12]
Advances in Neural Information Processing Systems , volume=
Efficient diffusion policies for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2311.02198 , year=
Imitation bootstrapped reinforcement learning , author=. arXiv preprint arXiv:2311.02198 , year=
-
[14]
Conference on Robot Learning , year=
Steering Your Diffusion Policy with Latent Space Reinforcement Learning , author=. Conference on Robot Learning , year=
-
[15]
IEEE International Conference on Robotics and Automation , year =
From Imitation to Refinement--Residual RL for Precise Assembly , author =. IEEE International Conference on Robotics and Automation , year =
-
[16]
International Conference on Learning Representations , year =
Flow matching for generative modeling , author =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
Towards diverse behaviors: A benchmark for imitation learning with human demonstrations , author =. International Conference on Learning Representations , year =
-
[18]
Planning with Diffusion for Flexible Behavior Synthesis
Planning with diffusion for flexible behavior synthesis , author=. arXiv preprint arXiv:2205.09991 , year=
work page internal anchor Pith review arXiv
-
[19]
International Conference on Machine Learning , pages=
Efficient online reinforcement learning with offline data , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[20]
International Conference on Learning Representations , year =
Policy decorator: Model-agnostic online refinement for large policy model , author =. International Conference on Learning Representations , year =
-
[21]
Stone Tao and Fanbo Xiang and Arth Shukla and Yuzhe Qin and Xander Hinrichsen and Xiaodi Yuan and Chen Bao and Xinsong Lin and Yulin Liu and Tse-Kai Chan and Yuan Gao and Xuanlin Li and Tongzhou Mu and Nan Xiao and Arnav Gurha and Viswesh N and Yong Woo Choi and Yen-Ru Chen and Zhiao Huang and Roberto Calandra and Rui Chen and Shan Luo and Hao Su , bookti...
work page 2025
-
[22]
arXiv preprint arXiv:2403.12203 , year=
Bootstrapping reinforcement learning with imitation for vision-based agile flight , author=. arXiv preprint arXiv:2403.12203 , year=
-
[23]
International Conference on Learning Representations , year =
Denoising diffusion implicit models , author =. International Conference on Learning Representations , year =
-
[24]
British Machine Vision Conference , year =
Mish: A self regularized non-monotonic activation function , author =. British Machine Vision Conference , year =. doi:10.5244/c.34.191 , publisher =
-
[25]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[26]
Flow-GRPO: Training Flow Matching Models via Online RL
Flow-grpo: Training flow matching models via online rl , author=. arXiv preprint arXiv:2505.05470 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in Neural Information Processing Systems , volume=
Rethinking inverse reinforcement learning: from data alignment to task alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
International conference on machine learning , pages=
Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[29]
Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control , author=. arXiv preprint arXiv:2409.08861 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Learning multimodal behaviors from scratch with diffusion policy gradient , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2305.13122 , year=
Policy representation via diffusion probability model for reinforcement learning , author=. arXiv preprint arXiv:2305.13122 , year=
-
[32]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep q-learning from demonstrations , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[33]
The International Journal of Robotics Research , pages=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. The International Journal of Robotics Research , pages=. 2023 , publisher=
work page 2023
- [34]
-
[35]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards , author=. arXiv preprint arXiv:1707.08817 , year=
-
[36]
Maximum a posteriori policy optimisation
Maximum a posteriori policy optimisation , author=. arXiv preprint arXiv:1806.06920 , year=
-
[37]
Hierarchical mixtures of experts and the EM algorithm , author=. Neural computation , volume=. 1994 , publisher=
work page 1994
-
[38]
International Conference on Learning Representations , year=
Variational intrinsic control , author=. International Conference on Learning Representations , year=
-
[39]
arXiv preprint arXiv:1807.10299 , year=
Variational option discovery algorithms , author=. arXiv preprint arXiv:1807.10299 , year=
-
[40]
International Conference on Learning Representations , year =
Fast task inference with variational intrinsic successor features , author =. International Conference on Learning Representations , year =
-
[41]
International Conference on Learning Representations , year =
Dynamics-aware unsupervised discovery of skills , author =. International Conference on Learning Representations , year =
- [42]
-
[43]
International Conference on Machine Learning , pages=
Aps: Active pretraining with successor features , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[44]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning , author=. 2020 , eprint=
work page 2020
-
[45]
International Conference on Machine Learning , year =
Unsupervised skill discovery with bottleneck option learning , author =. International Conference on Machine Learning , year =
-
[46]
International Conference on Learning Representations , year =
Hierarchical reinforcement learning by discovering intrinsic options , author =. International Conference on Learning Representations , year =
-
[47]
International Conference on Learning Representations , year =
Eigenoption discovery through the deep successor representation , author =. International Conference on Learning Representations , year =
-
[48]
Advances in Neural Information Processing Systems , volume=
Behavior from the void: Unsupervised active pre-training , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations , author=. arXiv preprint arXiv:2107.14483 , year=
-
[50]
Advances in neural information processing systems , volume=
Multi-modal imitation learning from unstructured demonstrations using generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[51]
Gemini Robotics: Bringing AI into the Physical World
Gemini robotics: Bringing ai into the physical world , author=. arXiv preprint arXiv:2503.20020 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
International Conference on Learning Representations , year =
Diversity is all you need: Learning skills without a reward function , author =. International Conference on Learning Representations , year =
-
[53]
Xi Chen and Ali Ghadirzadeh and Tianhe Yu and Jianhao Wang and Yuan Gao and Wenzhe Li and Liang Bin and Chelsea Finn and Chongjie Zhang , booktitle=. 2022 , url=
work page 2022
-
[54]
MolmoAct: Action Reasoning Models that can Reason in Space
MolmoAct: Action Reasoning Models that can Reason in Space , author=. arXiv preprint arXiv:2508.07917 , year=
work page internal anchor Pith review arXiv
-
[55]
Imitation learning as f-divergence minimization , author=. Algorithmic Foundations of Robotics XIV: Proceedings of the Fourteenth Workshop on the Algorithmic Foundations of Robotics 14 , pages=. 2021 , organization=
work page 2021
-
[56]
International conference on machine learning , pages=
Variational inference with normalizing flows , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[57]
FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models
Ffjord: Free-form continuous dynamics for scalable reversible generative models , author=. arXiv preprint arXiv:1810.01367 , year=
-
[58]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[59]
Conference on Robot Learning , year =
Openvla: An open-source vision-language-action model , author =. Conference on Robot Learning , year =
-
[60]
International Conference on Machine Learning , year =
Learning a diffusion model policy from rewards via q-score matching , author =. International Conference on Machine Learning , year =
-
[61]
International Conference on Learning Representations , year =
Diffusion policy policy optimization , author =. International Conference on Learning Representations , year =
-
[62]
Neural Information Processing Systems , year =
Diffusion policies creating a trust region for offline reinforcement learning , author =. Neural Information Processing Systems , year =. doi:10.48550/arXiv.2405.19690 , publisher =
-
[63]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[65]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[66]
Advances in Neural Information Processing Systems , volume=
Critic regularized regression , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Awac: Accelerating online reinforcement learning with offline datasets , author=. arXiv preprint arXiv:2006.09359 , year=
work page internal anchor Pith review arXiv 2006
-
[68]
International Conference on Machine Learning , pages=
Reparameterized policy learning for multimodal trajectory optimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[69]
Safe multi-agent navigation guided by goal- conditioned safe reinforcement learning
How to Train Your Robots? The Impact of Demonstration Modality on Imitation Learning , author =. IEEE International Conference on Robotics and Automation , year =. doi:10.1109/ICRA55743.2025.11128520 , publisher =
-
[70]
Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations
Learning complex dexterous manipulation with deep reinforcement learning and demonstrations , author=. arXiv preprint arXiv:1709.10087 , year=
-
[71]
arXiv preprint arXiv:2402.02868 , year=
Fine-tuning reinforcement learning models is secretly a forgetting mitigation problem , author=. arXiv preprint arXiv:2402.02868 , year=
- [72]
-
[73]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[74]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[75]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [76]
-
[77]
International Conference on Learning Representations , year=
Language Guided Skill Discovery , author=. International Conference on Learning Representations , year=
-
[78]
2024 International Conference on Robotics and Automation (ICRA) , year=
SLIM: Skill Learning with Multiple Critics , author=. 2024 International Conference on Robotics and Automation (ICRA) , year=
work page 2024
-
[79]
International Conference on Machine Learning , year=
Controllability-Aware Unsupervised Skill Discovery , author=. International Conference on Machine Learning , year=
-
[80]
International Conference on Learning Representations , year=
Mutual Information State Intrinsic Control , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.