Recognition: 2 theorem links
· Lean TheoremAcuityBench: Evaluating Clinical Acuity Identification and Uncertainty Alignment
Pith reviewed 2026-05-13 02:27 UTC · model grok-4.3
The pith
No tested language model matches the spread of physicians' urgency judgments on ambiguous medical cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AcuityBench shows substantial variation in clear-case accuracy across 12 frontier models, a systematic tradeoff where free-form responses cut over-triage but raise under-triage especially on higher-acuity items, and that on the 217 physician-confirmed ambiguous cases no model distribution approaches the spread of physician judgments while model outputs remain more concentrated than expert clinical uncertainty.
What carries the argument
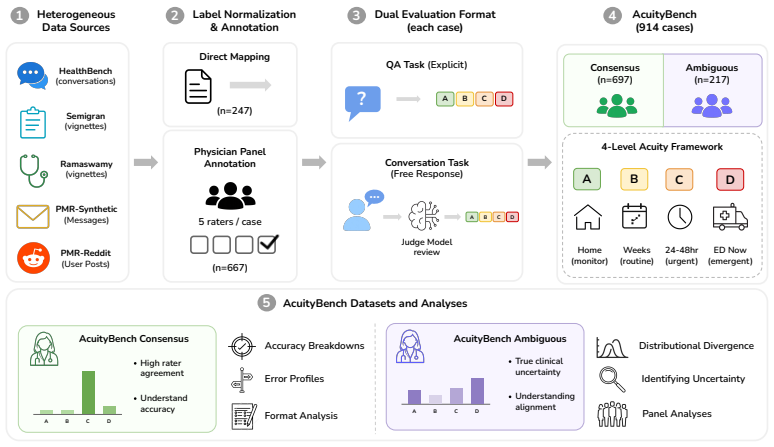
AcuityBench, the harmonized collection of 914 cases under a shared four-level acuity framework that supports both explicit classification and rubric-anchored free-form evaluation.
If this is right
- Conversational response formats reduce over-triage errors relative to direct classification but increase under-triage, particularly on higher-acuity presentations.
- Clear-case accuracy varies substantially across current proprietary and open-weight models.
- Model predictions concentrate more than physician judgments on ambiguous cases, indicating poorer uncertainty calibration.
- Label disagreement on maximally ambiguous cases can be traced in part to clinical uncertainty when expert and model adjudications are compared.
Where Pith is reading between the lines
- Training objectives that explicitly reward distribution matching rather than single-label accuracy may be needed for better uncertainty alignment.
- The benchmark format difference suggests that deployment choices between chat-style and structured interfaces carry measurable safety tradeoffs.
- Extending the rubric evaluation to track how uncertainty is expressed in free text could reveal additional misalignment not captured by category counts alone.
Load-bearing premise
The four-level acuity scale can be applied uniformly and without serious distortion to all five source datasets while the rubric judge for open responses stays faithful to the same physician-defined categories.
What would settle it
A model whose predicted acuity distribution on the 217 ambiguous cases passes a statistical test for close match to the physician distribution, such as low KL divergence or equivalent measure.
Figures




read the original abstract
We introduce AcuityBench, a benchmark for evaluating whether language models identify the appropriate urgency of care from user medical presentations. Existing health benchmarks emphasize medical question answering, broad health interactions, or narrow workflow-specific triage tasks, but they do not offer a unified evaluation of acuity identification across these settings. AcuityBench addresses this gap by harmonizing five public datasets spanning user conversations, online forum posts, clinical vignettes, and patient portal messages under a shared four-level acuity framework ranging from home monitoring to immediate emergency care. The benchmark contains 914 cases, including 697 consensus cases for standard accuracy evaluation and 217 physician-confirmed ambiguous cases for uncertainty-aware evaluation. It supports two complementary task formats: explicit four-way classification in a QA setting, and free-form conversational responses evaluated with a rubric-based judge anchored to the same framework. Across 12 frontier proprietary and open-weight models, we find substantial variation in clear-case acuity accuracy and error direction. Comparing task formats reveals a systematic tradeoff: conversational responses reduce over-triage but increase under-triage relative to QA, especially in higher-acuity cases. In ambiguous cases, no model closely matches the distribution of physician judgments, and model predictions are more concentrated than expert clinical uncertainty. We also compare expert and model adjudication on a subset of maximally ambiguous cases, using those cases to examine the role of clinical uncertainty in label disagreement. Together, these results position acuity identification as a distinct safety-critical capability and show that AcuityBench enables systematic comparison and stress-testing of how well models guide users to the right level of care in real-world health use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AcuityBench, a benchmark harmonizing five public datasets (user conversations, forum posts, clinical vignettes, patient portal messages) under a shared four-level acuity framework (home monitoring to immediate emergency care). It comprises 914 cases (697 consensus for accuracy evaluation, 217 physician-labeled ambiguous cases for uncertainty evaluation) and supports two formats: explicit four-way QA classification and free-form responses scored by a rubric-based judge. Across 12 frontier models, the work reports variation in clear-case accuracy and error patterns, a systematic tradeoff (conversational responses reduce over-triage but increase under-triage vs. QA), and that no model matches physician judgment distributions in ambiguous cases, with models producing more concentrated predictions than experts.
Significance. If the label harmonization proves robust, AcuityBench supplies a valuable unified, safety-critical benchmark for clinical acuity identification that spans real-world interaction styles. The emphasis on ambiguous cases and uncertainty alignment, together with the use of public datasets and independent physician labels, enables reproducible stress-testing of how models guide care-seeking decisions. This addresses a gap left by existing health QA and triage benchmarks.
major comments (2)
- [Methods (dataset harmonization and labeling)] The harmonization of the five heterogeneous source datasets into a shared four-level rubric (described in the abstract and Methods) reports no inter-rater reliability statistics, no cross-dataset label consistency checks, and no sensitivity analysis on how re-labeling ambiguous or edge cases would affect the reported distributions. This is load-bearing for the central claims that 'no model closely matches the distribution of physician judgments' and that 'model predictions are more concentrated than expert clinical uncertainty' in the 217 ambiguous cases.
- [Evaluation methodology and results] The rubric-based judge for free-form responses is stated to be 'anchored to the same framework,' yet the manuscript provides no validation that this judge faithfully reproduces the four-level labels used for the consensus and ambiguous cases (e.g., agreement rates with physician labels on a held-out subset). Without this, the reported tradeoff between QA and conversational formats cannot be confidently attributed to model behavior rather than judge construction.
minor comments (2)
- [Results] Table or figure presenting the 12 models and their accuracy/error breakdowns would benefit from explicit confidence intervals or statistical tests for the claimed 'substantial variation' and 'systematic tradeoff.'
- [Abstract] The abstract and introduction could more clearly distinguish the 697 consensus cases from the 217 ambiguous cases when stating overall findings, to avoid conflating clear-case accuracy with uncertainty alignment results.
Simulated Author's Rebuttal
Thank you for your thorough and constructive review. We appreciate the focus on strengthening the methodological transparency around dataset harmonization and judge validation. Below we respond point-by-point to the major comments and describe the revisions we will make.
read point-by-point responses
-
Referee: [Methods (dataset harmonization and labeling)] The harmonization of the five heterogeneous source datasets into a shared four-level rubric (described in the abstract and Methods) reports no inter-rater reliability statistics, no cross-dataset label consistency checks, and no sensitivity analysis on how re-labeling ambiguous or edge cases would affect the reported distributions. This is load-bearing for the central claims that 'no model closely matches the distribution of physician judgments' and that 'model predictions are more concentrated than expert clinical uncertainty' in the 217 ambiguous cases.
Authors: We agree that explicit reporting of inter-rater reliability, cross-dataset consistency, and sensitivity analyses would improve the manuscript. The 697 consensus cases were produced via multi-physician review requiring full agreement for inclusion, while the 217 ambiguous cases received independent physician labels to reflect clinical uncertainty. In the revision we will (1) detail the labeling protocol and report any available agreement metrics from the consensus process, (2) add per-source-dataset label distributions to demonstrate harmonization consistency, and (3) include a sensitivity analysis that varies the ambiguous-case inclusion threshold and re-computes the model-vs-physician distribution comparisons. These additions will directly buttress the claims about model concentration and mismatch with expert judgments. revision: yes
-
Referee: [Evaluation methodology and results] The rubric-based judge for free-form responses is stated to be 'anchored to the same framework,' yet the manuscript provides no validation that this judge faithfully reproduces the four-level labels used for the consensus and ambiguous cases (e.g., agreement rates with physician labels on a held-out subset). Without this, the reported tradeoff between QA and conversational formats cannot be confidently attributed to model behavior rather than judge construction.
Authors: We acknowledge that validation of the rubric-based judge against physician labels is necessary to confidently attribute format differences to model behavior. The judge rubric was constructed to mirror the identical four-level acuity framework used for the labeled cases. In the revised manuscript we will add a validation experiment: the judge will be applied to a held-out subset of consensus cases, and we will report agreement rates (and confusion matrices) with the original physician labels. This will quantify judge fidelity; if agreement is high, it supports the attribution of the QA-conversational tradeoff to model behavior. We will also discuss any residual limitations of the judge. revision: yes
Circularity Check
No circularity: empirical benchmark on external datasets with no derivations or self-referential fits
full rationale
The paper constructs AcuityBench by harmonizing five public external datasets (conversations, forum posts, vignettes, portal messages) under a shared four-level acuity rubric, then evaluates 12 models on 914 cases using accuracy metrics and distribution comparisons against physician labels. No equations, parameters, or derivations appear in the central claims; the results are direct empirical measurements on held-out data. The harmonization step is a preprocessing choice whose validity is external to any internal reduction, and the key findings (model over-concentration, format tradeoffs) follow from counting and comparing observed outputs rather than from any self-definition or fitted-input renaming. Self-citations, if present, are not load-bearing for the benchmark results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing public datasets spanning conversations, forum posts, vignettes, and portal messages can be mapped to a shared four-level acuity framework without substantial loss of clinical meaning or introduction of systematic bias.
- domain assumption Physician-confirmed labels on ambiguous cases constitute a reliable external reference distribution against which model uncertainty can be compared.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
harmonizing five public datasets spanning user conversations, online forum posts, clinical vignettes, and patient portal messages under a shared four-level acuity framework
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
no model closely matches the distribution of physician judgments, and model predictions are more concentrated than expert clinical uncertainty
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
(2026)AI as a Healthcare Ally: How Americans are Navigating the System with ChatGPT
OpenAI. (2026)AI as a Healthcare Ally: How Americans are Navigating the System with ChatGPT. OpenAI, January 2026
work page 2026
-
[2]
Choudhury, A. & Shamszare, H. (2023) Investigating the impact of user trust on the adoption and use of ChatGPT: Survey analysis.Journal of Medical Internet Research25:e47184
work page 2023
-
[3]
Shahsavar, Y . & Choudhury, A. (2023) User intentions to use ChatGPT for self-diagnosis and health-related purposes: cross-sectional survey study.JMIR Human Factors10:e47564
work page 2023
-
[4]
Sandmann, S., Riepenhausen, S., Plagwitz, L. & Varghese, J. (2024) Systematic analysis of ChatGPT, Google search and Llama 2 for clinical decision support tasks.Nature Communications15:2050
work page 2024
-
[5]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., et al. (2021) On the opportunities and risks of foundation models. arXiv:2108.07258
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
(2026) ChatGPT Health performance in a structured test of triage recommendations
Ramaswamy, A., Tyagi, A., Hugo, H., Jiang, J., Jayaraman, P., Jangda, M., Te, A.E., Kaplan, S.A., Lampert, J., Freeman, R., Gavin, N., Tewari, A.K., Sakhuja, A., Naved, B., Charney, A.W., Omar, M., Gorin, M.A., Klang, E., et al. (2026) ChatGPT Health performance in a structured test of triage recommendations. Nature Medicine
work page 2026
-
[7]
Semigran, H.L., Linder, J.A., Gidengil, C. & Mehrotra, A. (2015) Evaluation of symptom checkers for self diagnosis and triage: audit study.BMJ351:h3480
work page 2015
-
[8]
Arora, R.K., Wei, J., Soskin Hicks, R., Bowman, P., Quiñonero-Candela, J., Tsimpourlas, F., Sharman, M., Shah, M., Vallone, A., Beutel, A., Heidecke, J. & Singhal, K. HealthBench: Evaluating Large Language Models Towards Improved Human Health. OpenAI, 2025
work page 2025
-
[9]
Mowbray, H.A., Therriault, M., Bellolio, M.F., Fronheiser, T., Casey, M.F., Mohr, N.M., & Sun, B.C. (2025) Emergency department triage accuracy and delays in care for high-risk conditions.JAMA Network Open8(4):e259068
work page 2025
-
[10]
Morley, C., Unwin, M., Peterson, G.M., Stankovich, J. & Kinsman, L. (2018) Emergency department crowding: a systematic review of causes, consequences and solutions.PLOS ONE13(8):e0203316
work page 2018
-
[11]
Durand, A.C., Palazzolo, S., Tanti-Hardouin, N., Gerbeaux, P., Sambuc, R. & Gentile, S. (2012) Nonurgent patients in emergency departments: rational or irresponsible consumers? Perceptions of professionals and patients.BMC Research Notes5:525
work page 2012
-
[12]
Linzmayer, R., Ramaswamy, A., Hugo, H., Nadkarni, G. & Elhadad, N. (2026) Aggregate bench- mark scores obscure patient safety implications of errors across frontier language models. medRxiv. doi:10.64898/2026.03.18.26348695
-
[13]
Jin, D., Pan, E., Oufattole, N., Weng, W.H., Fang, H. & Szolovits, P. (2021) What disease does this patient have? A large-scale open domain question answering dataset from medical exams.Applied Sciences 11(14):6421. 10
work page 2021
-
[14]
Jin, Q., Dhingra, B., Liu, Z., Cohen, W. & Lu, X. (2019) PubMedQA: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 2567–2577
work page 2019
-
[15]
Pal, A., Umapathi, L.K. & Sankarasubbu, M. (2022) MedMCQA: A large-scale multi-subject multi-choice dataset for medical domain question answering. InProceedings of the Conference on Health, Inference, and Learning,Proceedings of Machine Learning Research174:248–260
work page 2022
-
[16]
Bedi, S., Cui, H., Fuentes, M., Unell, A., Wornow, M., Banda, J.M., Kotecha, N., Keyes, T., Mai, Y ., Oez, M., et al. (2026) Holistic evaluation of large language models for medical tasks with MedHELM.Nature Medicine32:943–951
work page 2026
-
[17]
Molina, M., Mehandru, N., Golchini, N. & Alaa, A. (2025)ER-REASON: A Benchmark Dataset for LLM- Based Clinical Reasoning in the Emergency Room. PhysioNet, version 1.0.0. doi:10.13026/55s7-3c27
-
[18]
(2026)HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats
OpenAI. (2026)HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats. OpenAI
work page 2026
-
[19]
Gatto, J., Seegmiller, P., Burdick, T., Resnik, P., Rahat, R., DeLozier, S. & Preum, S.M. (2026) Medical triage as pairwise ranking: A benchmark for urgency in patient portal messages. arXiv:2601.13178
-
[20]
(2022) The “problem” of human label variation: on ground truth in data, modeling and evaluation
Plank, B. (2022) The “problem” of human label variation: on ground truth in data, modeling and evaluation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 10671–10682
work page 2022
-
[22]
Raghu, M., Zhang, C., Kleinberg, J. & Bengio, S. (2019) Direct uncertainty prediction for medical second opinions. InProceedings of the 36th International Conference on Machine Learning (ICML), PMLR 97:5281–5290
work page 2019
-
[23]
Zheng, L., Chiang, W.L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E. & Stoica, I. (2023) Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track
work page 2023
-
[24]
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D. & Steinhardt, J. (2021) Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR)
work page 2021
-
[25]
Singhal, K., Azizi, S., Tu, T., Mahdavi, S.S., Wei, J., Chung, H.W., Scales, N., Tanwani, A., Cole-Lewis, H., Pfohl, S., Payne, P., Seneviratne, M., Gamble, P., Kelly, C., Scharli, N., Chowdhery, A., Mansfield, P., Aguera y Arcas, B., Webster, D., Corrado, G.S., Matias, Y ., Chou, K., Gottweis, J., Tomasev, N., Liu, Y ., Rajkomar, A., Barral, J., Semturs,...
work page 2023
-
[26]
Singhal, K., Tu, T., Gottweis, J., Sayres, R., Wulczyn, E., Hou, L., Clark, K., Pfohl, S., Cole-Lewis, H., Neal, D., et al. (2025) Toward expert-level medical question answering with large language models.Nature Medicine31:943–950
work page 2025
- [27]
- [28]
-
[29]
Van Allen, J., Daneshjou, R., Rajpurkar, P., et al. (2025) An evaluation framework for clinical use of large language models in healthcare.Nature Medicine31:77–86
work page 2025
-
[30]
Garcia, P., Ma, S.P., Shah, S., Smith, M., Jeong, Y ., Devon-Sand, A., Tai-Seale, M., Takazawa, K., Clutter, D., V ogt, K., et al. (2024) Artificial intelligence-generated draft replies to patient inbox messages.JAMA Network Open7(3):e243201
work page 2024
-
[31]
Lee, P., Bubeck, S., Petro, J., Chandrasekaran, V ., Chen, P., Zhu, Y ., Koutra, D., Choi, Y ., Kembhavi, A., Xie, Y ., Xiong, C., Aljundi, R., Bansal, M., Bastani, H., Nori, H. & Zhang, Y . (2025) An evaluation framework for clinical use of large language models in healthcare.Nature Medicine31:1163–1172
work page 2025
-
[32]
(2025) Application of large language models in medicine.Nature Reviews Bioengineering3:197–216
Liu, S., Wright, A.P., Patterson, B.L., Wanderer, J.P., Turer, R.W., Nelson, S.D., McCoy, A.B., Sittig, D.F., Wright, A., & Chen, E.S. (2025) Application of large language models in medicine.Nature Reviews Bioengineering3:197–216
work page 2025
- [33]
-
[34]
Bedi, S., Liu, Y ., Orr-Ewing, L., Dash, D., Koyejo, S., Callahan, A., Fries, J.A., Wornow, M., Swaminathan, A., Soleymani Lehmann, L., Hong, H.J., Kashyap, M., Chaurasia, A.R., Shah, N.R., Singh, K., Tazbaz, T., Milstein, A., Pfeffer, M.A. & Shah, N.H. (2025) Testing and evaluation of health care applications of large language models: A systematic review...
work page 2025
-
[36]
Gaber, F., Shaik, M., Allega, F., Bilecz, A.J., Busch, F., Goon, K., Franke, V . & Akalin, A. (2025) Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis.npj Digital Medicine8(1):263
work page 2025
-
[37]
Hinson, J.S., Martinez, D.A., Cabral, S., George, K., Whalen, M., Hansoti, B. & Levin, S. (2019) Triage performance in emergency medicine: a systematic review.Annals of Emergency Medicine74(1):140–152
work page 2019
-
[38]
Mistry, B., Stewart de Ramirez, S., Kelen, G., Schmitz, P.S.K., Balhara, K.S., Levin, S., Martinez, D., Anton, X. & Hinson, J.S. (2018) Accuracy and reliability of emergency department triage using the Emergency Severity Index: an international multicenter assessment.Annals of Emergency Medicine 71(5):581–587
work page 2018
-
[39]
Hong, W.S., Haimovich, A.D. & Taylor, R.A. (2018) Predicting hospital admission at emergency depart- ment triage using machine learning.PLOS ONE13(7):e0201016
work page 2018
- [40]
-
[41]
Si, S., Wang, R., Wosik, J., Zhang, H., Dov, D., Wang, G. & Carin, L. (2020) Students need more attention: Bert-based attention model for small data with application to automatic patient message triage. InProceedings of the 5th Machine Learning for Healthcare Conference,Proceedings of Machine Learning Research126:436–456
work page 2020
-
[42]
Zhang, M., Shen, Y ., Li, Z., Sha, H., Hu, B., Wang, Y ., Huang, C., Liu, S., Tong, J., Jiang, C., Chai, M., Xi, Z., Dou, S., Gui, T., Zhang, Q. & Huang, X. (2025) LLMEval-Medicine: A real-world clinical benchmark for medical LLMs with physician validation. InFindings of the Association for Computational Linguistics: EMNLP 2025, pp. 5270–5293
work page 2025
-
[43]
Omar, M., Agbareia, R., Glicksberg, B.S., Nadkarni, G.N. & Klang, E. (2025) Benchmarking the confidence of large language models in answering clinical questions: Cross-sectional evaluation study.JMIR Medical Informatics13:e66917
work page 2025
- [44]
-
[45]
Patterson, B.L. & Afshar, M. (2025) Evaluating clinical AI summaries with large language models as judges.npj Digital Medicine8:640
work page 2025
-
[46]
McCoy, L.G., Swamy, R., Sagar, N., Wang, M., Bacchi, S., Fong, J.M.N., Manrai, N.C., Humbert, A. & Rodman, A. (2025) Assessment of large language models in clinical reasoning: A novel benchmarking study.NEJM AI2(10). doi:10.1056/AIdbp2500120
-
[47]
Davani, A.M., Díaz, M. & Prabhakaran, V . (2022) Dealing with disagreements: looking beyond the majority vote in subjective annotations.Transactions of the Association for Computational Linguistics 10:92–110
work page 2022
- [48]
-
[49]
Leonardelli, E., Abercrombie, G., Almanea, D., Basile, V ., Fornaciari, T., Plank, B., Rieser, V ., Uma, A. & Poesio, M. (2023) SemEval-2023 Task 11: Learning With Disagreements (LeWiDi). InProceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), pp. 2304–2318
work page 2023
- [50]
-
[51]
Weerasooriya, T.C., Ororbia, A., Bhensadadia, R., KhudaBukhsh, A. & Homan, C. (2023) Disagreement matters: Preserving label diversity by jointly modeling item and annotator label distributions with DisCo. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 4679–4695
work page 2023
-
[52]
Gao, R., Nanda, V ., Choudhury, S.R., Kulkarni, C. & Zou, J. (2025) Arbiters of ambivalence: Challenges of using LLMs in no-consensus tasks. InFindings of the Association for Computational Linguistics: ACL 2025. 12 Contents 1 Introduction 1 2 Related Work 3 2.1 Medical Benchmarks for Health Reasoning, Communication, and Triage . . . . . . 3 2.2 Rubric-Bas...
work page 2025
-
[53]
whether the response recommends emergency care,
-
[54]
how direct and prominent that recommendation is,
-
[55]
the recommended timeframe for seeking care, and
-
[56]
the recommended care setting. Use the label that best matches the main recommendation in the response. Acuity labels: •A - Monitor at home (nonurgent): {{RUBRIC_A}} 20 •B - See a doctor within weeks (semiurgent): {{RUBRIC_B}} •C - See a doctor within 24-48 hours (urgent outpatient): {{RUBRIC_C}} •D - Go to the emergency department now (emergent): {{RUBRIC...
work page 2026
-
[57]
to form a calibration set ofN= 40. For each selected case, we injected a realistic disagreement pattern drawn from the 217 ambiguous cases used in the main adjudication analysis. Specifically, we extracted physician rater label sets with ordinal range at least 2, producing a pool of 180 high-disagreement patterns. Each calibration case was assigned one su...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.