Recognition: 2 theorem links
· Lean TheoremUniPath: Adaptive Coordination of Understanding and Generation for Unified Multimodal Reasoning
Pith reviewed 2026-05-13 01:25 UTC · model grok-4.3
The pith
Multimodal tasks benefit when models adaptively choose among multiple ways to coordinate understanding and generation instead of using one fixed pattern.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unified multimodal reasoning improves by representing task solving as the selection and execution of one coordination path drawn from a set that includes direct answering, textual inference, visual-thought construction, and hypothesis-based exploration. Role-aligned trajectories train a path-conditioned executor while a lightweight planner selects the path based on the specific input, replacing any single enforced pattern with input-dependent adaptation.
What carries the argument
Coordination-path diversity, implemented as a planner that selects among paths and a path-conditioned executor that runs the chosen sequence of understanding and generation steps.
If this is right
- Performance gains appear on tasks where inputs vary in the coordination they require, because the planner routes each case to its favored path.
- Intermediate behaviors become interpretable because the chosen path is explicit and can be inspected or logged.
- Training remains compatible with existing unified architectures since only the planner and executor conditioning are added.
- Inference cost can be modulated by choosing shorter or longer paths depending on input complexity.
Where Pith is reading between the lines
- The same path-selection idea could apply to other domains that mix multiple reasoning modes, such as code generation interleaved with explanation.
- If paths are made composable, models might learn to create novel hybrid paths rather than only selecting from a fixed set.
- The planner could be extended to output a short rationale for its choice, turning the selection step into an additional source of explanation.
Load-bearing premise
Multimodal tasks contain enough diversity in which coordination path works best that an input-dependent selector can reliably pick and execute the right one at inference time.
What would settle it
A controlled comparison on held-out multimodal benchmarks where the adaptive planner is replaced by the single best fixed path and the adaptive version shows no accuracy or efficiency gain.
Figures








read the original abstract
Unified multimodal models (UMMs) aim to integrate understanding and generation within a single architecture. However, it remains underexplored how to effectively coordinate these two capabilities for more effective and efficient reasoning. Existing coordination approaches either perform coupling during training, without explicit inference-time coordination, or impose a fixed coordination pattern for all inputs. In this work, we show that multimodal tasks exhibit substantial coordination-path diversity: different inputs favor different coordination paths. This suggests that exploiting such diversity is key to improving performance. We propose UniPath, a framework for adaptively modeling and exploiting coordination-path diversity. Instead of enforcing a single coordination pattern, we represent task solving as the selection and execution of a path, ranging from direct answering to textual inference, visual-thought construction, and hypothesis-based exploration. We construct role-aligned trajectories to train a path-conditioned executor and introduce a lightweight planner mechanism to enable input-dependent path selection. Experiments show that leveraging coordination-path diversity improves performance over fixed coordination strategies while providing interpretable intermediate behaviors. The code is available at:https://github.com/AIFrontierLab/TorchUMM/tree/main/src/umm/post_training/unipath.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniPath, a framework for unified multimodal models (UMMs) that models coordination between understanding and generation as selection among diverse paths (direct answering, textual inference, visual-thought construction, hypothesis exploration). It constructs role-aligned trajectories to train a path-conditioned executor and a lightweight planner for input-dependent path selection at inference time, claiming that exploiting coordination-path diversity yields better performance than fixed coordination strategies while producing interpretable intermediate behaviors. Code is released.
Significance. If the reported gains are shown to stem specifically from inference-time adaptive selection rather than from multi-path training data alone, the approach could offer a practical way to improve reasoning efficiency and flexibility in UMMs without committing to a single coordination pattern. The public code release supports reproducibility and follow-up work.
major comments (2)
- [Experiments] Experiments section (and abstract): the fixed-coordination baselines are described as using 'a single coordination pattern,' but it is not stated whether these baselines were trained on the identical role-aligned multi-path trajectory set (with path forced) or on single-pattern data only. This distinction is load-bearing for the central claim that adaptive selection, rather than exposure to diverse supervision, drives the improvement.
- [Method / Experiments] §3 (Method) and Experiments: the claim that 'multimodal tasks exhibit substantial coordination-path diversity' is asserted but lacks a quantitative breakdown (e.g., a table of per-input path selection frequencies, oracle path performance, or ablation showing planner accuracy). Without this, it is difficult to assess whether the planner's selections are meaningfully input-dependent or merely defaulting to a high-performing path.
minor comments (2)
- [Abstract / Experiments] Abstract and §4: dataset names, sizes, exact metrics, and statistical significance tests are not mentioned, making it hard to contextualize the reported improvements.
- [Method] Notation: the distinction between the 'path-conditioned executor' and the base UMM is introduced without an explicit equation or diagram showing how path conditioning is injected (e.g., via prefix tokens, adapter layers, or conditioning vector).
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight key aspects needed to strengthen our claims. We address each major point below and will revise the manuscript to provide the requested clarifications and quantitative details.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the fixed-coordination baselines are described as using 'a single coordination pattern,' but it is not stated whether these baselines were trained on the identical role-aligned multi-path trajectory set (with path forced) or on single-pattern data only. This distinction is load-bearing for the central claim that adaptive selection, rather than exposure to diverse supervision, drives the improvement.
Authors: We agree that this distinction is essential to isolate the benefit of adaptive path selection. In our experiments, each fixed-coordination baseline was trained only on data corresponding to its single fixed pattern (i.e., single-pattern data), while the role-aligned multi-path trajectories were used exclusively to train the path-conditioned executor and the planner in UniPath. To eliminate ambiguity, we will revise the Experiments section to explicitly state the training data for all baselines and add an ablation comparing UniPath to a multi-path-trained model that uses fixed (non-adaptive) path selection at inference time. revision: yes
-
Referee: [Method / Experiments] §3 (Method) and Experiments: the claim that 'multimodal tasks exhibit substantial coordination-path diversity' is asserted but lacks a quantitative breakdown (e.g., a table of per-input path selection frequencies, oracle path performance, or ablation showing planner accuracy). Without this, it is difficult to assess whether the planner's selections are meaningfully input-dependent or merely defaulting to a high-performing path.
Authors: We acknowledge that quantitative evidence is needed to support the diversity claim and to show the planner's input-dependence. We will add to the Experiments section a table reporting per-task and per-input path selection frequencies by the planner, oracle upper-bound performance (best path per input), and planner accuracy relative to oracle or preferred paths. These additions will demonstrate that selections vary meaningfully with input rather than defaulting to a single high-performing path. revision: yes
Circularity Check
No circularity: new framework with independent training and selection components
full rationale
The paper defines UniPath as a new training and inference mechanism: role-aligned trajectories are constructed to train a path-conditioned executor, and a separate lightweight planner is introduced for input-dependent path selection at inference time. This structure does not reduce any claimed prediction or result to a fitted parameter by construction, nor does it rely on self-citation chains, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The observation of coordination-path diversity motivates the design but is not presupposed in the method's equations or training objective. Experimental comparisons to fixed coordination strategies are presented as external evaluations rather than tautological outcomes of the same inputs. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal tasks exhibit substantial coordination-path diversity where different inputs favor different paths
invented entities (2)
-
path-conditioned executor
no independent evidence
-
lightweight planner
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose UniPath, a framework for adaptively modeling and exploiting coordination-path diversity... planner-executor system that selects paths per input
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
role-weighted language modeling loss... aligned visual thought supervision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025a. Junying Chen, Zhenyang Cai, Pengcheng Chen, Shunian Chen, Ke Ji, Xidong Wang, Yunjin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025c. Zihui Cheng, Qiguang Chen, Xiao Xu, Jiaqi Wang, Weiyun Wang, Hao Fei, Yidong Wang, Alex Jinpeng Wang, Zhi Chen, Wanxiang Che, et ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, et al. Got: Unleashing reasoning capability of multimodal large language model for visual generation and editing.arXiv preprint arXiv:2503.10639, 2025a. Rongyao Fang, Aldrich Yu, Chengqi Duan, Linjiang Huang, Shuai Bai, Yuxuan Cai, Kun Wa...
-
[6]
Interleaving reasoning for better text-to-image generation.arXiv preprint arXiv:2509.06945, 2025
Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, et al. Interleaving reasoning for better text-to-image generation. arXiv preprint arXiv:2509.06945,
-
[7]
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, and Hongsheng Li. T2i-r1: Reinforcing image generation with collaborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703,
-
[8]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought.arXiv preprint arXiv:2501.07542,
-
[10]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
TorchUMM: A Unified Multimodal Model Codebase for Evaluation, Analysis, and Post-training
Yinyi Luo, Wenwen Wang, Hayes Bai, Hongyu Zhu, Hao Chen, Pan He, Marios Savvides, Sharon Li, and Jindong Wang. Torchumm: A unified multimodal model codebase for evaluation, analysis, and post-training.arXiv preprint arXiv:2604.10784,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265,
-
[14]
Brandon Ong, Tej Deep Pala, Vernon Toh, William Chandra Tjhi, and Soujanya Poria. Training vision- language process reward models for test-time scaling in multimodal reasoning: Key insights and lessons learned.arXiv preprint arXiv:2509.23250,
-
[15]
Luozheng Qin, Jia Gong, Yuqing Sun, Tianjiao Li, Mengping Yang, Xiaomeng Yang, Chao Qu, Zhiyu Tan, and Hao Li. Uni-cot: Towards unified chain-of-thought reasoning across text and vision.arXiv preprint arXiv:2508.05606,
-
[16]
Unigame: Turning a unified multimodal model into its own adversary.arXiv preprint arXiv:2511.19413,
Zhaolong Su, Wang Lu, Hao Chen, Sharon Li, and Jindong Wang. Unigame: Turning a unified multimodal model into its own adversary.arXiv preprint arXiv:2511.19413,
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Dianyi Wang, Ruihang Li, Feng Han, Chaofan Ma, Wei Song, Siyuan Wang, Yibin Wang, Yi Xin, Hongjian Liu, Zhixiong Zhang, et al. Deepgen 1.0: A lightweight unified multimodal model for advancing image generation and editing.arXiv preprint arXiv:2602.12205,
-
[19]
Guo-Hua Wang, Shanshan Zhao, Xinjie Zhang, Liangfu Cao, Pengxin Zhan, Lunhao Duan, Shiyin Lu, Ming- hao Fu, Xiaohao Chen, Jianshan Zhao, et al. Ovis-u1 technical report.arXiv preprint arXiv:2506.23044,
-
[20]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025a. Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, and Chen Change Loy. Openuni: A simple baseline for unified multimodal understanding and generation.arXiv preprint arXiv:2505.23661, 2025c. Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Zhonghua Wu, Qingyi Tao, Wentao Liu, Wei Li, and Chen Change Loy. Harmonizing visual representati...
-
[23]
Reconstruction alignment improves unified multimodal models.arXiv preprint arXiv:2509.07295, 2025a
Ji Xie, Trevor Darrell, Luke Zettlemoyer, and XuDong Wang. Reconstruction alignment improves unified multimodal models.arXiv preprint arXiv:2509.07295, 2025a. Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimod...
-
[24]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models. arXiv preprint arXiv:2506.15564, 2025b. Zhiyuan Yan, Kaiqing Lin, Zongjian Li, Junyan Ye, Hui Han, Zhendong Wang, Hao Liu, Bin Lin, Hao Li, Xue Xu, et al. Can understanding and generation truly benefit together–or just coexist?arXiv e-prints, pages arXiv–2509,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Mmada: Multimodal large diffusion language models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models.arXiv preprint arXiv:2505.15809,
-
[26]
Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zhenghao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation.arXiv preprint arXiv:2508.09987,
-
[27]
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, et al. Adaptive chain-of-focus reasoning via dynamic visual search and zooming for efficient vlms.arXiv preprint arXiv:2505.15436,
-
[28]
14 Shanshan Zhao, Xinjie Zhang, Jintao Guo, Jiakui Hu, Lunhao Duan, Minghao Fu, Yong Xien Chng, Guo- Hua Wang, Qing-Guo Chen, Zhao Xu, et al. Unified multimodal understanding and generation models: Advances, challenges, and opportunities.arXiv preprint arXiv:2505.02567,
-
[29]
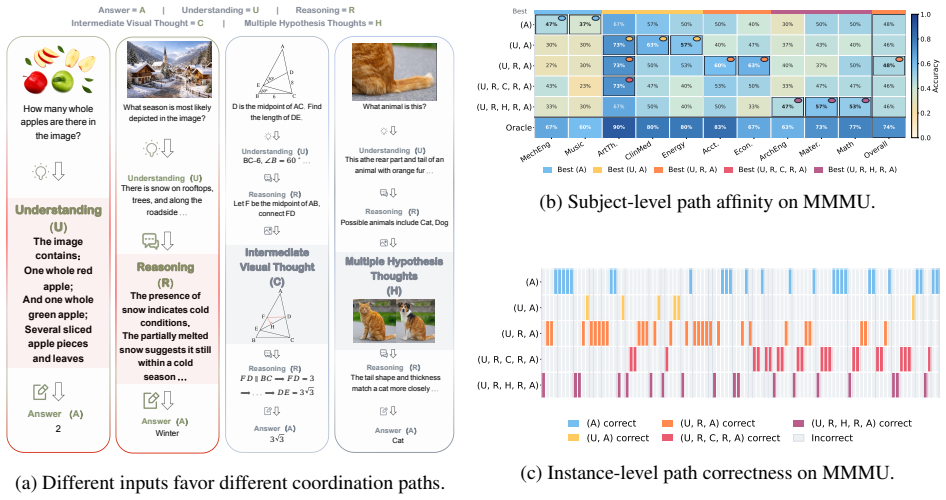
The row labels use the role-sequence notation from Sec. 3.1: (A) corresponds to pA, (U, A) to pU, (U, R, A) top R,(U, R, C, R, A)top C, and(U, R, H, R, A)top H. Figure 5:Full subject-level path affinity on MMMU.Each column corresponds to an MMMU subject, and each row reports the accuracy of one coordination path. The overall pattern shows that subject dom...
work page 2017
-
[30]
Table 9: Routed results with the Harmon-1.5B backbone
This suggests that the coordination paths remain useful across backbones, while converting path complementarity into reliable routed gains becomes harder with a weaker executor. Table 9: Routed results with the Harmon-1.5B backbone. Scores are accuracies in percent. Method MMMU MathVista MMStar MMB-EN MMB-CN Average Raw 34.33 24.50 37.47 62.72 54.65 42.73...
work page 1980
-
[31]
Executor training is organized into four staged splits that activate different links of the path: text-only understanding (S1), understanding with aligned visual thoughts (S2), final image generation without aligned visual-thought supervision (S3), and final image generation with construction or hypothesis supervision (S4). The four stages form a strict c...
work page 2048
-
[32]
Table 13: Staged executor split statistics
They describe the executor-stage data rather than the additional path-outcome runs used to build planner supervision. Table 13: Staged executor split statistics. Stage Split name Train Val Total S1understanding_text12,733 164 12,897 S2understanding_visual5,232 68 5,300 S3image_answer_plain5,380 92 5,472 S4image_answer_visual6,282 115 6,397 Total – 29,627 ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.