Recognition: 2 theorem links
· Lean TheoremSelective Off-Policy Reference Tuning with Plan Guidance
Pith reviewed 2026-05-14 21:17 UTC · model grok-4.3
The pith
SORT derives a plan from the reference solution to selectively weight tokens that become more predictable under plan conditioning, turning all-failed rollouts into structure-aware learning signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SORT derives a plan from the reference solution, compares token probabilities with and without that plan, and gives higher weight to tokens that become more predictable under plan conditioning. This turns all-wrong prompts into selective, structure-aware learning signals instead of uniform imitation.
What carries the argument
The selective weighting rule that upweights tokens whose probability increases under conditioning on a plan derived from the reference solution.
If this is right
- Performance improves on reasoning benchmarks where all sampled rollouts fail.
- Gains appear across three different model backbones and eight benchmarks, with larger benefits for weaker models.
- The method requires no change to the rollout sampling process.
- It outperforms both standard GRPO and existing guidance baselines.
Where Pith is reading between the lines
- SORT could be combined with standard success-based updates to handle mixed success-failure batches in a single training loop.
- The plan-comparison idea might generalize to other structured generation tasks where a reference outline is available during training.
- If plans can be approximated without full references, the approach might reduce dependence on high-quality labeled solutions at scale.
Load-bearing premise
A plan derived from the reference solution supplies unbiased conditioning that identifies meaningful structure-aware tokens without adding artifacts.
What would settle it
Apply SORT using deliberately incorrect or random plans instead of reference-derived plans and check whether the performance gains on reasoning benchmarks disappear.
Figures


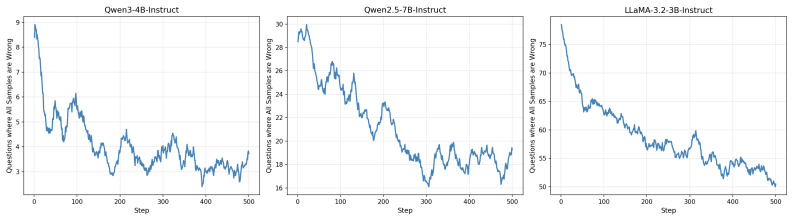




read the original abstract
Reinforcement learning with verifiable rewards helps reasoning, but GRPO-style methods stall on hard prompts where all sampled rollouts fail. SORT adds a repair update for those failures without changing rollout generation: it derives a plan from the reference solution, compares token probabilities with and without that plan, and gives higher weight to tokens that become more predictable under plan conditioning. This turns all-wrong prompts into selective, structure-aware learning signals instead of uniform imitation. Across three backbones and eight reasoning benchmarks, SORT improves over GRPO and guidance baselines, with largest gains on weaker models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Selective Off-Policy Reference Tuning (SORT) as an extension to GRPO-style RL for reasoning. For hard prompts where all rollouts fail, SORT derives a plan from the reference solution, compares token probabilities under prompt-only vs. prompt-plus-plan conditioning, and upweights tokens that become more predictable under the plan. This is claimed to convert uniform failure signals into selective, structure-aware updates without altering rollout generation. Empirical results across three backbones and eight reasoning benchmarks show gains over GRPO and guidance baselines, largest on weaker models.
Significance. If the weighting mechanism can be shown to extract general structure without reference leakage, SORT would usefully extend RLVR applicability to difficult cases that currently yield zero reward. The multi-backbone evaluation is a strength, as is the focus on turning complete failures into usable signals rather than discarding them.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): The weighting rule is stated only qualitatively ('gives higher weight to tokens that become more predictable under plan conditioning'). No explicit equation, pseudocode, or definition of the plan injection (tokenization, masking, or conditioning format) is provided. Without this, it cannot be verified whether the ratio reduces to a fitted hyperparameter or introduces direct reference leakage, as the skeptic note flags.
- [§4] §4 (experiments): The abstract asserts gains on eight benchmarks but supplies no quantitative tables, error bars, or controls for plan quality. The central claim that the method yields 'structure-aware' rather than reference-imitation signals therefore lacks the load-bearing empirical support needed to assess whether the improvement is robust or artifactual.
minor comments (1)
- [Abstract] Abstract: 'eight reasoning benchmarks' is mentioned without naming them or giving effect sizes; a one-sentence summary of the largest gains would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each point below and will update the manuscript accordingly to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): The weighting rule is stated only qualitatively ('gives higher weight to tokens that become more predictable under plan conditioning'). No explicit equation, pseudocode, or definition of the plan injection (tokenization, masking, or conditioning format) is provided. Without this, it cannot be verified whether the ratio reduces to a fitted hyperparameter or introduces direct reference leakage, as the skeptic note flags.
Authors: We agree the description is insufficiently precise. In the revision we will insert the explicit weighting formula w_t = p(x_t | prompt + plan) / p(x_t | prompt) (with log-space implementation for stability), together with pseudocode for plan extraction from the reference and the exact conditioning format used during probability computation. We will also add a short paragraph clarifying that the plan is used only for off-policy weighting on failed rollouts and does not appear in the policy gradient itself, thereby avoiding direct imitation. revision: yes
-
Referee: [§4] §4 (experiments): The abstract asserts gains on eight benchmarks but supplies no quantitative tables, error bars, or controls for plan quality. The central claim that the method yields 'structure-aware' rather than reference-imitation signals therefore lacks the load-bearing empirical support needed to assess whether the improvement is robust or artifactual.
Authors: The current §4 contains summary tables of accuracy improvements across the eight benchmarks and three backbones. To address the concern, we will expand these tables to include per-benchmark numbers with standard-error bars from three random seeds and add a new ablation that replaces reference-derived plans with random or noisy plans. The latter control directly tests whether gains require coherent plan structure rather than mere reference exposure. revision: yes
Circularity Check
Derivation self-contained; no reduction to inputs by construction
full rationale
The paper introduces SORT as a repair update that derives a plan from the reference solution and reweights tokens according to the change in their conditional probabilities when the plan is added as conditioning. This weighting rule is defined directly from the probability comparison operation itself rather than being fitted to a target or reduced to a prior self-citation. No equations, uniqueness theorems, or ansatzes are shown that would make the reweighting equivalent to the reference trajectory by construction. The central claim therefore rests on an independent computation performed on the model's own distribution and does not collapse into a tautology or load-bearing self-reference.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
ωi,t = sg(√(pbase i,t * pplan i,t)) ... LSORT(Mk) = −1/|S(Mk)| Σ ωi,t log πθ(y⋆i,t | BASEPROMPT(qi), y⋆i,<t)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
σi,t := log πθ(y⋆i,t | qi, Si, y⋆i,<t) / πθ(y⋆i,t | qi, y⋆i,<t) ... plan-regret bound under Assumption 3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Learning to reason under off-policy guidance, 2025
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance, 2025. URL https://arxiv.org/abs/2504. 14945
work page 2025
-
[4]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Bin Cui, and Wentao Zhang. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions, 2026. URL https://arxiv.org/abs/2506.07527
-
[5]
Scaf-grpo: Scaffolded group relative policy optimization for enhancing llm reasoning, 2026
Xichen Zhang, Sitong Wu, Yinghao Zhu, Haoru Tan, Shaozuo Yu, Ziyi He, and Jiaya Jia. Scaf-grpo: Scaffolded group relative policy optimization for enhancing llm reasoning, 2026. URLhttps://arxiv.org/abs/2510.19807
-
[6]
Expo: Unlocking hard reasoning with self-explanation-guided reinforcement learning, 2026
Ruiyang Zhou, Shuozhe Li, Amy Zhang, and Liu Leqi. Expo: Unlocking hard reasoning with self-explanation-guided reinforcement learning, 2026. URL https://arxiv.org/abs/2507. 02834
work page 2026
-
[7]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, and Hanze Dong. A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025. URLhttps://arxiv.org/abs/2504.11343
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Knapsack rl: Unlocking exploration of llms via optimizing budget allocation,
Ziniu Li, Congliang Chen, Tianyun Yang, Tian Ding, Ruoyu Sun, Ge Zhang, Wenhao Huang, and Zhi-Quan Luo. Knapsack rl: Unlocking exploration of llms via optimizing budget allocation,
- [10]
-
[11]
Nudging the boundaries of llm reasoning,
Justin Chih-Yao Chen, Becky Xiangyu Peng, Prafulla Kumar Choubey, Kung-Hsiang Huang, Jiaxin Zhang, Mohit Bansal, and Chien-Sheng Wu. Nudging the boundaries of llm reasoning,
- [12]
-
[13]
Kimi Team, Yifan Bai, Yiping Bao, Y . Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong G...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026. URLhttps://arxiv.org/abs/2508.05629
-
[15]
Thanh-Long V . Le, Myeongho Jeon, Kim Trong Vu, Viet Dac Lai, and Eunho Yang. No prompt left behind: Exploiting zero-variance prompts in llm reinforcement learning via entropy-guided advantage shaping, 2026. URLhttps://arxiv.org/abs/2509.21880. ICLR 2026
-
[16]
Adaptive rollout allocation for online reinforcement learning with verifiable rewards, 2026
Hieu Trung Nguyen, Bao Nguyen, Wenao Ma, Yuzhi Zhao, Ruifeng She, and Viet Anh Nguyen. Adaptive rollout allocation for online reinforcement learning with verifiable rewards, 2026. URLhttps://arxiv.org/abs/2602.01601. ICLR 2026
-
[17]
Self-hinting language models enhance reinforcement learning, 2026
Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian. Self-hinting language models enhance reinforcement learning, 2026. URL https://arxiv.org/abs/2602.03143
-
[18]
Adaptive guidance accelerates reinforcement learning of reasoning models, 2025
Vaskar Nath, Elaine Lau, Anisha Gunjal, Manasi Sharma, Nikhil Baharte, and Sean Hendryx. Adaptive guidance accelerates reinforcement learning of reasoning models, 2025. URL https: //arxiv.org/abs/2506.13923
-
[19]
Stepwise guided policy optimiza- tion: Coloring your incorrect reasoning in grpo, 2026
Peter Chen, Xiaopeng Li, Ziniu Li, Xi Chen, and Tianyi Lin. Stepwise guided policy optimiza- tion: Coloring your incorrect reasoning in grpo, 2026. URL https://arxiv.org/abs/2505. 11595
work page 2026
-
[20]
First return, entropy-eliciting explore, 2025
Tianyu Zheng, Tianshun Xing, Qingshui Gu, Taoran Liang, Xingwei Qu, Xin Zhou, Yizhi Li, Zhoufutu Wen, Chenghua Lin, Wenhao Huang, Qian Liu, Ge Zhang, and Zejun Ma. First return, entropy-eliciting explore, 2025. URLhttps://arxiv.org/abs/2507.07017
-
[21]
Xiaoyuan Liu, Tian Liang, Zhiwei He, Jiahao Xu, Wenxuan Wang, Pinjia He, Zhaopeng Tu, Haitao Mi, and Dong Yu. Trust, but verify: A self-verification approach to reinforcement learn- ing with verifiable rewards, 2025. URL https://arxiv.org/abs/2505.13445. NeurIPS 2025
-
[22]
Rubric as reward: Decomposing verification signals for logical reasoning in grpo
Ishaan Gangwani and Aayam Bansal. Rubric as reward: Decomposing verification signals for logical reasoning in grpo. ICLR 2026 Workshop on LLM Reasoning, 2026. URL https: //openreview.net/forum?id=LFBnQEGh23
work page 2026
-
[23]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning, 2026. URLhttps://arxiv.org/abs/2601.19897
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Rlpr: Extrapolating rlvr to general domains without verifiers, 2025
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, and Tat-Seng Chua. Rlpr: Extrapolating rlvr to general domains without verifiers, 2025. URLhttps://arxiv.org/abs/2506.18254
-
[25]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516. Association for Computational Linguistics, 2025. doi: 10.18653/v1/ 202...
-
[26]
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models.arXiv preprint arXiv:2505.07686, 2025. URL https://arxiv.org/abs/ 2505.07686. 12
-
[27]
Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024. URLhttps://arxiv.org/abs/2412.01981
-
[28]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025. URLhttps://arxiv.org/abs/2502.01456
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning, 2025. URL https://arxiv. org/abs...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Ignore the kl penalty! boosting exploration on critical tokens to enhance rl fine-tuning, 2025
Jean Vassoyan, Nathanael Beau, and Roman Plaud. Ignore the kl penalty! boosting exploration on critical tokens to enhance rl fine-tuning, 2025. URL https://arxiv.org/abs/2502. 06533
work page 2025
-
[31]
Preserving diversity in supervised fine-tuning of large language models, 2025
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, and Ruoyu Sun. Preserving diversity in supervised fine-tuning of large language models, 2025. URL https://arxiv.org/abs/2408.16673
-
[32]
SED-SFT: Selectively encouraging diversity in supervised fine-tuning, 2026
Yijie Chen, Yijin Liu, and Fandong Meng. SED-SFT: Selectively encouraging diversity in supervised fine-tuning, 2026. URLhttps://arxiv.org/abs/2602.07464
-
[33]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
work page 2024
-
[37]
MAA Committees. Aime problems and solutions. https://artofproblemsolving.com/ wiki/index.php/AIME_Problems_and_Solutions, 2024. Art of Problem Solving
work page 2024
-
[38]
MAA Committees. Aime problems and solutions. https://artofproblemsolving.com/ wiki/index.php/AIME_Problems_and_Solutions, 2025. Art of Problem Solving
work page 2025
-
[39]
American mathematics competitions (amc) 2023
Mathematical Association of America. American mathematics competitions (amc) 2023. https://maa.org, 2023. AMC 8, AMC 10, and AMC 12 competition problems
work page 2023
-
[40]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Pro- ceedings of the Neural Information Processing Systems Track on Datasets and Bench- marks 1, NeurIPS Datasets and Benchmarks ...
work page 2021
-
[41]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay V . Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. O...
work page 2022
-
[42]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceed...
-
[43]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023. doi: 10.48550/ARXIV .2311.12022. URL https://doi.org/10.48550/arXiv.2311.12022. 15
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[44]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
work page 2024
-
[45]
HybridFlow: A Flexible and Efficient RLHF Framework , url=
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM, March 2025. doi: 10.1145/3689031.3696075. URL http://dx.doi.org/ 10.1145/3689031.3696075
-
[46]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention, 2023. URL https://arxiv.org/abs/2309. 06180
work page 2023
-
[47]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of llms?, 2026. URLhttps://arxiv.org/abs/2603.24472. A Algorithm B Limitations & Broader Impacts Limitations.First, SORT assumes a verified reference solution is available for ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.