Recognition: no theorem link
Every Bit, Everywhere, All at Once: A Binomial Multibit LLM Watermark
Pith reviewed 2026-05-13 01:11 UTC · model grok-4.3
The pith
Binomial encoding embeds every bit of a multibit payload at every token position in LLM text generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
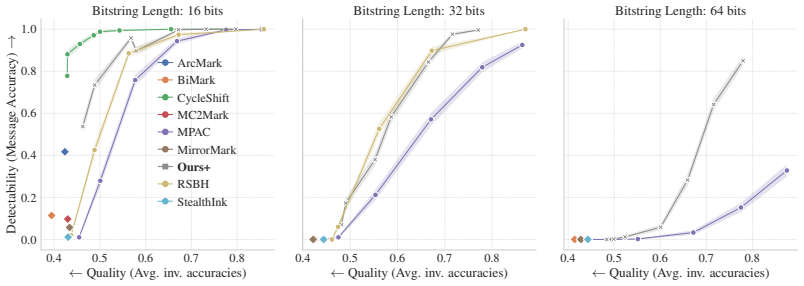
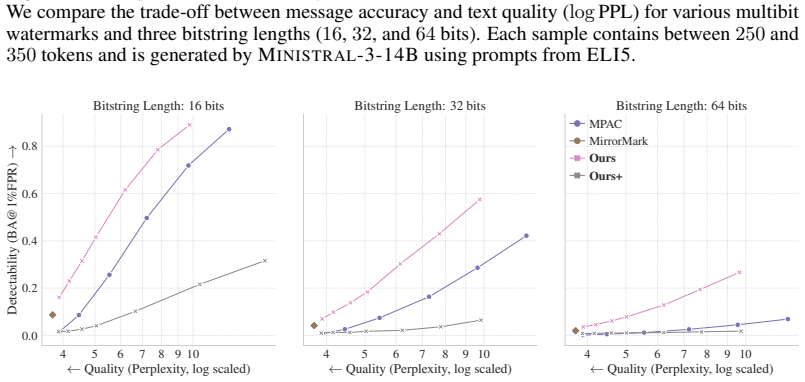
The authors claim that binomial encoding combined with stateful redirection during generation produces watermarks that recover the full payload more accurately and more robustly than existing multibit schemes, especially when the payload is large and the text must remain nearly unchanged. They demonstrate this on up to 64-bit messages and introduce per-bit confidence as an evaluation measure that better reflects real usability than aggregate metrics used before.
What carries the argument
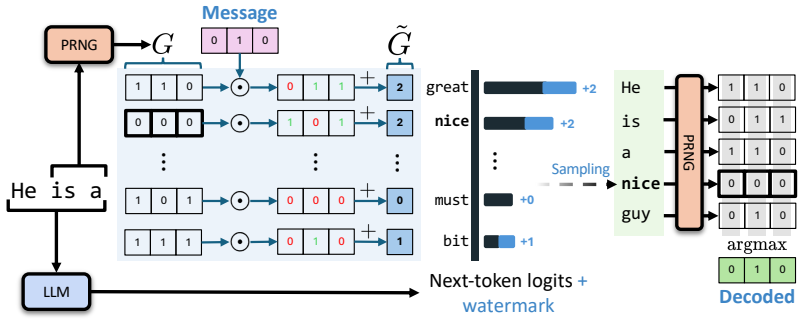
Binomial encoding, in which each payload bit is represented by a separate statistical bias in token probabilities at every position, together with a stateful encoder that tracks cumulative bit coverage and redirects selection pressure to lagging bits.
If this is right
- Message recovery rates stay high for payloads as large as 64 bits even when the allowed change to the text is small.
- Robustness against common modifications improves relative to prior methods, with the margin largest in the low-distortion regime.
- Per-bit scoring reveals which parts of the payload are most reliably detected, giving a finer view than whole-message accuracy alone.
- The stateful redirection prevents any single bit from lagging too far behind, keeping overall payload completeness stable across long outputs.
Where Pith is reading between the lines
- Watermarking could support practical uses such as embedding timestamps or session identifiers without forcing noticeable changes to the generated text.
- The same encoding principle might be tested on other sequence models where statistical biases in token choice can be measured.
- Detection performance under stronger adversarial edits that specifically target binomial biases remains an open question the paper does not fully close.
Load-bearing premise
The statistical biases introduced by the encoding remain detectable and decodable even after the text has been edited or when the detector does not have complete records of the original generation choices.
What would settle it
An experiment that generates watermarked text with 32-bit or 64-bit payloads, applies realistic edits such as synonym swaps or sentence reordering, and then measures whether the recovered message accuracy falls below 70 percent using the proposed detector.
Figures















read the original abstract
With LLM watermarking already being deployed commercially, practical applications increasingly require multibit watermarks that encode more complex payloads, such as user IDs or timestamps, into the generated text. In this work, we propose a fundamentally new approach for multibit watermarking: introducing binomial encoding to directly encode every bit of the payload at every token position. We complement our approach with a stateful encoder that during generation dynamically redirects encoding pressure toward underencoded bits. Our evaluation against 8 baselines on up to 64-bit payloads shows that our scheme achieves superior message accuracy and robustness, with the gap to baseline methods widening in more relevant settings (i.e., large payloads and low-distortion regimes). At the same time, we challenge prior works' evaluation metrics, highlighting their lack of practical insights, and introduce per-bit confidence scoring as a practically relevant metric for evaluating multibit LLM watermarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multibit LLM watermarking method based on binomial encoding, which embeds every bit of a payload (e.g., user ID or timestamp) at every token position, paired with a stateful encoder that dynamically redirects encoding effort toward under-encoded bits during generation. Evaluations against 8 baselines on payloads up to 64 bits report superior message accuracy and robustness, with the performance gap increasing for larger payloads and lower distortion levels; the work also critiques existing evaluation metrics and introduces per-bit confidence scoring.
Significance. If the reported gains in accuracy and robustness are reproducible under standard black-box detection (key plus output text only), the binomial-plus-stateful approach would represent a meaningful advance for practical multibit watermarking in deployed LLMs. The per-bit confidence metric could also provide more actionable evaluation than aggregate accuracy alone, particularly when payload bits have unequal importance.
major comments (2)
- [Abstract and evaluation description] The central empirical claim of superior message accuracy/robustness (especially the widening gap for 64-bit payloads in low-distortion regimes) rests on the assumption that the stateful redirection can be inverted by a detector given only the secret key and final text. The abstract and evaluation description do not specify whether the detector must reconstruct per-token redirection state (e.g., counters of remaining under-encoded bits or prior-token history) or whether decoding is fully stateless; if the former, the accuracy advantage may not hold in standard black-box settings.
- [Evaluation section] The robustness experiments need to clarify the threat model for the reported gains: which specific attacks (e.g., paraphrasing, token substitution, or regeneration) are considered, and whether the stateful component remains recoverable after each attack. Without this, it is difficult to assess whether the binomial encoding itself or the redirection mechanism drives the improvement.
minor comments (2)
- [Abstract] The abstract refers to 'binomial encoding' without a brief inline definition or pointer to the formal construction; adding one sentence would improve accessibility for readers unfamiliar with the scheme.
- [Evaluation section] The paper should include a short table or paragraph comparing the new per-bit confidence metric against the prior aggregate metrics it critiques, with a concrete example on a small payload.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. These highlight important points about detector requirements and evaluation clarity that we will address through revisions. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract and evaluation description] The central empirical claim of superior message accuracy/robustness (especially the widening gap for 64-bit payloads in low-distortion regimes) rests on the assumption that the stateful redirection can be inverted by a detector given only the secret key and final text. The abstract and evaluation description do not specify whether the detector must reconstruct per-token redirection state (e.g., counters of remaining under-encoded bits or prior-token history) or whether decoding is fully stateless; if the former, the accuracy advantage may not hold in standard black-box settings.
Authors: We appreciate this observation and agree that the detector specification requires explicit clarification. Our detector is fully black-box and stateless in operation: it requires only the secret key and output text. The redirection state (counters for under-encoded bits) is reconstructed deterministically during detection by sequentially processing the text, decoding each token's contribution to the payload bits, and updating the same counters the encoder would have used. This reconstruction uses the decoded bits themselves to drive the state transitions, ensuring no additional information beyond key and text is needed. All reported accuracy and robustness numbers were obtained with this exact detector. We will revise the abstract and evaluation section to describe this reconstruction procedure in detail and to confirm that the black-box setting was used throughout. revision: yes
-
Referee: [Evaluation section] The robustness experiments need to clarify the threat model for the reported gains: which specific attacks (e.g., paraphrasing, token substitution, or regeneration) are considered, and whether the stateful component remains recoverable after each attack. Without this, it is difficult to assess whether the binomial encoding itself or the redirection mechanism drives the improvement.
Authors: We agree that the threat model and attack details should be stated more explicitly. Our robustness evaluation considers three attacks: (1) paraphrasing via an auxiliary LLM, (2) random token substitution at varying rates, and (3) regeneration from a modified prompt. For each, we measure end-to-end message accuracy and per-bit confidence after the attack. The stateful redirection is recovered post-attack by the same sequential reconstruction process used in clean detection; attacks that corrupt tokens naturally lower the per-bit confidence scores for affected bits, which is precisely why we report per-bit metrics. The performance gains arise from the combination of binomial encoding (which places every bit at every position) and redirection (which balances encoding effort), both of which remain beneficial even after state reconstruction on attacked text. We will add a new subsection detailing the threat model, the three attacks, and the post-attack state reconstruction procedure. revision: yes
Circularity Check
No significant circularity in binomial multibit watermarking proposal
full rationale
The paper introduces a new encoding scheme (binomial per-bit encoding at every token plus stateful redirection) and evaluates it empirically against baselines on message accuracy and robustness. No derivation step reduces by construction to a fitted parameter, self-definition, or prior self-citation; the central claims rest on the explicit algorithmic description and reported experimental outcomes rather than tautological renaming or imported uniqueness theorems. The introduced per-bit confidence metric is presented as an alternative evaluation tool without depending on the scheme's own fitted results. The derivation chain from the proposed encoder to the accuracy claims is self-contained and externally falsifiable via the described black-box detection procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generative ai transparency: Identifi- cation of machine-generated content
Hamon R, Sanchez I, Fernandez Llorca D, and Gomez E. Generative ai transparency: Identifi- cation of machine-generated content. Scientific analysis or review, Ispra (Italy), 2024
work page 2024
-
[2]
Advancing beyond identification: Multi-bit watermark for large language models, 2024
KiYoon Yoo, Wonhyuk Ahn, and Nojun Kwak. Advancing beyond identification: Multi-bit watermark for large language models, 2024. URLhttps://arxiv.org/abs/2308.00221
-
[3]
Provably robust multi-bit watermarking for ai-generated text,
Wenjie Qu, Wengrui Zheng, Tianyang Tao, Dong Yin, Yanze Jiang, Zhihua Tian, Wei Zou, Jinyuan Jia, and Jiaheng Zhang. Provably robust multi-bit watermarking for ai-generated text,
- [4]
-
[5]
MirrorMark: Generalizable Mirrored Sampling for Multi-bit LLM Watermarking
Ya Jiang, Massieh Kordi Boroujeny, Surender Suresh Kumar, and Kai Zeng. Mirrormark: A distortion-free multi-bit watermark for large language models, 2026. URL https://arxiv. org/abs/2601.22246
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
Pierre Fernandez, Antoine Chaffin, Karim Tit, Vivien Chappelier, and Teddy Furon. Three bricks to consolidate watermarks for large language models.2023 IEEE International Workshop on Information Forensics and Security (WIFS), 2023
work page 2023
-
[8]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. InInternational Conference on Machine Learning, pages 17061–17084. PMLR, 2023
work page 2023
-
[9]
Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, et al. Scalable watermarking for identifying large language model outputs.Nature, 634(8035):818–823, 2024
work page 2024
-
[10]
Watermarking of large language models
Scott Aaronson. Watermarking of large language models. InWorkshop on Large Language Models and Transformers, Simons Institute, UC Berkeley, 2023
work page 2023
-
[11]
Dipmark: A stealthy, efficient and resilient watermark for large language models
Yihan Wu, Zhengmian Hu, Hongyang Zhang, and Heng Huang. Dipmark: A stealthy, efficient and resilient watermark for large language models. 2023
work page 2023
-
[12]
Improved unbiased watermark for large language models.CoRR, 2025
Ruibo Chen, Yihan Wu, Junfeng Guo, and Heng Huang. Improved unbiased watermark for large language models.CoRR, 2025
work page 2025
-
[13]
Robust distortion- free watermarks for language models.TMLR, 2024
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion- free watermarks for language models.TMLR, 2024
work page 2024
-
[14]
Stealthink: A multi-bit and stealthy watermark for large language models, 2025
Ya Jiang, Chuxiong Wu, Massieh Kordi Boroujeny, Brian Mark, and Kai Zeng. Stealthink: A multi-bit and stealthy watermark for large language models, 2025. URL https://arxiv.org/ abs/2506.05502
-
[15]
Bimark: Unbiased multilayer watermarking for large language models, 2025
Xiaoyan Feng, He Zhang, Yanjun Zhang, Leo Yu Zhang, and Shirui Pan. Bimark: Unbiased multilayer watermarking for large language models, 2025. URL https://arxiv.org/abs/ 2506.21602
-
[16]
Mc 2mark: Distortion-free multi-bit watermarking for long messages, 2026
Xuehao Cui, Ruibo Chen, Yihan Wu, and Heng Huang. Mc 2mark: Distortion-free multi-bit watermarking for long messages, 2026. URLhttps://arxiv.org/abs/2602.14030
-
[17]
A unified framework for llm watermarks, 2026
Thibaud Gloaguen, Robin Staab, Nikola Jovanovi´c, and Martin Vechev. A unified framework for llm watermarks, 2026. URLhttps://arxiv.org/abs/2602.06754
-
[18]
Eli5: Long form question answering, 2019
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. Eli5: Long form question answering, 2019. URLhttps://arxiv.org/abs/1907.09190
-
[19]
W. W. Peterson and D. T. Brown. Cyclic codes for error detection.Proceedings of the IRE, 49 (1):228–235, 1961. doi: 10.1109/JRPROC.1961.287814. 10
-
[20]
Leyi Pan, Aiwei Liu, Zhiwei He, Zitian Gao, Xuandong Zhao, Yijian Lu, Binglin Zhou, Shuliang Liu, Xuming Hu, Lijie Wen, Irwin King, and Philip S. Yu. MarkLLM: An open-source toolkit for LLM watermarking. In Delia Irazu Hernandez Farias, Tom Hope, and Manling Li, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processin...
work page 2024
-
[21]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[22]
Watermarking diffusion language models
Thibaud Gloaguen, Robin Staab, Nikola Jovanovi´c, and Martin Vechev. Watermarking diffusion language models. InThe Fourteenth International Conference on Learning Representations,
-
[23]
URLhttps://openreview.net/forum?id=3aBWTYGcaT
-
[24]
The language model evaluation harness, 07 2024.https://zenodo.org/records/12608602
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[25]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page 2021
-
[27]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021. 11 A Experimental Details In this section, we describe precisely the experimental setup used in our evaluation (Sec. 5), with ...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.