Recognition: 2 theorem links
· Lean TheoremReviving In-domain Fine-tuning Methods for Source-Free Cross-domain Few-shot Learning
Pith reviewed 2026-05-13 01:20 UTC · model grok-4.3
The pith
Rectifying collapsed attention in CLIP makes prompt-based fine-tuning competitive again for cross-domain few-shot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoRA's superiority in CDFSL stems from rectifying the collapsed attention of the visual CLS token, which enhances modality alignment and class separation by directing focus to text-related visual regions. Textual EOS tokens exhibit stronger attention to visual samples, while CLIP's standard contrastive loss provides only weak constraints on alignment. Semantic Probe is introduced as a general attention rectification framework that plugs into both adapter- and prompt-based methods to restore these benefits, delivering state-of-the-art performance on four CDFSL benchmarks.
What carries the argument
Semantic Probe, a plug-and-play attention rectification framework that adjusts the attention of visual CLS tokens in fine-tuning methods to restore focus on text-related regions and strengthen modality alignment.
If this is right
- Both adapter and prompt fine-tuning methods become viable for CDFSL once attention collapse is addressed.
- Focusing on text-related visual regions improves class separation in low-data cross-domain settings.
- Textual EOS tokens can serve as a stronger anchor for visual alignment than CLS tokens alone.
- Standard contrastive loss in CLIP needs supplementation to better enforce modality alignment across domains.
- The same rectification principle scales to multiple fine-tuning paradigms without architecture-specific redesign.
Where Pith is reading between the lines
- The same attention analysis could apply to other vision-language models that use CLS tokens and contrastive pretraining.
- Domains with strong visual-text mismatch, such as medical or satellite imagery, might benefit most from explicit rectification.
- Combining Semantic Probe with stronger alignment losses could yield further gains beyond current SOTA.
- Attention collapse may explain why some pretrained models fail to adapt quickly in few-shot regimes.
Load-bearing premise
The superiority of LoRA in cross-domain settings comes specifically from rectifying collapsed visual CLS token attention, and this fix can be turned into a general plug-and-play framework that works for prompt methods without creating new problems.
What would settle it
A controlled test where attention rectification is applied only to the visual CLS token in a prompt-based method like MaPLe, with all other components unchanged, and performance on CDFSL benchmarks shows no improvement or drops.
Figures









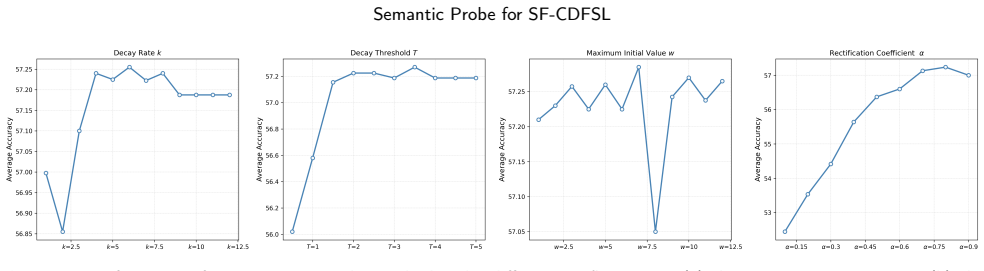

read the original abstract
Cross-Domain Few-Shot Learning (CDFSL) aims to adapt large-scale pretrained models to specialized target domains with limited samples, yet the few-shot fine-tuning of vision-language models like CLIP remains underexplored. By establishing multiple fine-tuning baselines of CLIP for CDFSL, we find adapter-based methods (e.g., LoRA) consistently outperform prompt-based ones (e.g., MaPLe), contrary to in-domain scenarios. To make those effective in-domain methods competitive again in CDFSL, we analyze this phenomenon and discover LoRA's superiority stems from rectifying the collapsed attention of visual CLS token, enhancing modality alignment and class separation by focusing on text-related visual regions. Further, we find textual EOS token exhibit much better attention to visual samples, and CLIP's standard contrastive loss weakly constrains modality alignment. Based on these insights, we propose Semantic Probe, a plug-and-play attention rectification framework for both adapter- and prompt-based methods. Extensive experiments on four CDFSL benchmarks validate our rationale, achieving state-of-the-art performance and benefiting both fine-tuning paradigms. Codes will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes multiple CLIP fine-tuning baselines for source-free cross-domain few-shot learning (CDFSL) and observes that adapter-based methods (e.g., LoRA) consistently outperform prompt-based methods (e.g., MaPLe), in contrast to in-domain behavior. Through analysis, it attributes LoRA's advantage to rectification of collapsed visual CLS-token attention (focusing on text-related regions and improving modality alignment and class separation), notes superior attention behavior of the textual EOS token, and identifies weak constraints from CLIP's contrastive loss. It proposes Semantic Probe, a plug-and-play attention-rectification framework applicable to both adapter and prompt paradigms, and reports state-of-the-art results on four CDFSL benchmarks.
Significance. If the proposed causal mechanism and transferability hold, the work would offer a practical, general-purpose way to revive strong in-domain fine-tuning techniques for cross-domain settings, addressing modality misalignment in CLIP-based CDFSL. The plug-and-play design and reported gains on multiple benchmarks could influence subsequent adapter/prompt research in few-shot and domain-adaptation literature.
major comments (3)
- [Analysis section] Analysis section (description of LoRA vs. prompt comparison): the claim that LoRA's superiority 'stems from rectifying the collapsed attention of visual CLS token' is presented as the key insight motivating Semantic Probe, yet the manuscript provides only observational comparisons without controlled ablations that isolate attention rectification from confounding factors such as parameter placement, optimization trajectory, or gradient flow differences between the two paradigms.
- [Semantic Probe framework] Semantic Probe framework description and experiments: while the method is claimed to be plug-and-play for prompt-based tuning, no ablation demonstrates that the attention rectification recovers the full performance gap observed with LoRA or that it avoids introducing new cross-domain failure modes (e.g., over-focusing on spurious text-related regions that hurt generalization on certain target domains).
- [Experiments] Experimental validation (four CDFSL benchmarks): the link between the proposed attention rectification and the reported SOTA gains is not supported by direct measurements (e.g., quantitative attention maps or modality-alignment metrics before/after Semantic Probe) that would confirm the mechanism rather than post-hoc correlation.
minor comments (3)
- The abstract states 'Codes will be released' but provides no repository link or supplementary material reference; this should be added for reproducibility.
- [Method] Notation for attention rectification (e.g., how the probe modifies CLS/EOS tokens) should be formalized with an equation or pseudocode to improve clarity.
- [Experiments] Ensure all baseline comparisons report mean and standard deviation over multiple random seeds or runs, and clarify whether the same hyperparameter search budget was used for adapters and prompts.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have addressed each of the major comments below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Analysis section] Analysis section (description of LoRA vs. prompt comparison): the claim that LoRA's superiority 'stems from rectifying the collapsed attention of visual CLS token' is presented as the key insight motivating Semantic Probe, yet the manuscript provides only observational comparisons without controlled ablations that isolate attention rectification from confounding factors such as parameter placement, optimization trajectory, or gradient flow differences between the two paradigms.
Authors: We acknowledge that our current analysis is based on observational comparisons. To strengthen the causal claim, we will perform additional controlled ablations in the revision. These will include isolating the attention rectification effect by applying similar constraints to prompt methods and analyzing differences in optimization and gradient flow. We believe this will better isolate the contribution of attention rectification. revision: yes
-
Referee: [Semantic Probe framework] Semantic Probe framework description and experiments: while the method is claimed to be plug-and-play for prompt-based tuning, no ablation demonstrates that the attention rectification recovers the full performance gap observed with LoRA or that it avoids introducing new cross-domain failure modes (e.g., over-focusing on spurious text-related regions that hurt generalization on certain target domains).
Authors: We thank the referee for highlighting this. In the revised manuscript, we will add ablations that apply Semantic Probe to prompt-based methods and measure how much of the LoRA performance gap is recovered. Additionally, we will examine attention maps across different target domains to check for potential over-focusing on spurious regions and ensure no new failure modes are introduced. revision: yes
-
Referee: [Experiments] Experimental validation (four CDFSL benchmarks): the link between the proposed attention rectification and the reported SOTA gains is not supported by direct measurements (e.g., quantitative attention maps or modality-alignment metrics before/after Semantic Probe) that would confirm the mechanism rather than post-hoc correlation.
Authors: We agree that direct quantitative evidence is important to confirm the mechanism. We will include in the revision quantitative attention metrics (such as the proportion of attention on text-related regions) and modality alignment scores before and after Semantic Probe application. This will provide stronger support for the link between attention rectification and the observed performance improvements. revision: yes
Circularity Check
No significant circularity; derivation rests on empirical observations of attention patterns
full rationale
The paper establishes baselines showing adapter methods outperform prompts in CDFSL, then reports observational analysis of CLS-token attention collapse in LoRA versus prompts, leading to the Semantic Probe framework. No equations, fitted parameters, or predictions reduce to inputs by construction. No self-citations serve as load-bearing uniqueness theorems or ansatzes. The central claims are grounded in benchmark experiments and attention visualizations rather than self-referential definitions or renamings of known results. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CLIP's standard contrastive loss weakly constrains modality alignment
invented entities (1)
-
Semantic Probe
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
propose Semantic Probe... EOS-guided Attention Rectification (EAR) module and a dynamic Balanced Alignment and Separation (BAS) loss
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoRA’s superiority stems from rectifying the collapsed attention of visual [CLS] token
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Codella, N., Rotemberg, V., Tschandl, P., Celebi, M.E., Dusza, S., Gutman, D., Helba, B., Kalloo, A., Liopyris, K., Marchetti, M., et al., 2019. Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic). arXiv preprint arXiv:1902.03368
work page Pith review arXiv 2019
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale, in: ICLR 2021
Dosovitskiy,A.,Beyer,L.,Kolesnikov,A.,Weissenborn,D.,Zhai,X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N., 2021. An image is worth 16x16 words: Transformers for image recognition at scale, in: ICLR 2021
work page 2021
-
[3]
arXiv preprint arXiv:2406.17639 (2024)
Eslami, S., de Melo, G., 2024. Mitigate the gap: Investigating approaches for improving cross-modal alignment in clip. arXiv preprint arXiv:2406.17639
-
[4]
Fu,Y.,Xie,Y.,Fu,Y.,Jiang,Y.,2023.Styleadv:Metastyleadversarial training for cross-domain few-shot learning, in: IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, IEEE. pp. 24575–24584
work page 2023
-
[5]
Clip-adapter: Better vision-language models with feature adapters
Gao,P.,Geng,S.,Zhang,R.,Ma,T.,Fang,R.,Zhang,Y.,Li,H.,Qiao, Y., 2024. Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer Vision 132, 581–595. Yaze Zhao and Yicong Liu et al.:Preprint submitted to ElsevierPage 13 of 16 Semantic Probe for SF-CDFSL Table 8 Comparison with state-of-the-art works by the 5-way 1-...
work page 2024
-
[6]
Cyclip: Cyclic contrastive language-image pretraining
Goel,S.,Bansal,H.,Bhatia,S.,Rossi,R.,Vinay,V.,Grover,A.,2022. Cyclip: Cyclic contrastive language-image pretraining. Advances in Neural Information Processing Systems 35, 6704–6719
work page 2022
-
[7]
Guo, Y., Codella, N.C., Karlinsky, L., Codella, J.V., Smith, J.R., Saenko, K., Rosing, T., Feris, R., 2020. A broader study of cross- domainfew-shotlearning,in:Computervision–ECCV2020:16thEu- ropean conference, glasgow, UK, August 23–28, 2020, proceedings, part XXVII 16, Springer. pp. 124–141
work page 2020
-
[8]
Guo, Y., Gu, X., 2025. MMRL: multi-modal representation learning for vision-language models, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, Computer Vision Foundation / IEEE. pp. 25015– 25025
work page 2025
-
[9]
Helber, P., Bischke, B., Dengel, A., Borth, D., 2019. Eurosat: A novel dataset and deep learning benchmark for land use and land coverclassification.IEEEJournalofSelectedTopicsinAppliedEarth Observations and Remote Sensing 12, 2217–2226
work page 2019
-
[10]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., 2022a. Lora: Low-rank adaptation of large language models, in: The Tenth International Conference on Learning Repre- sentations, ICLR 2022, Virtual Event, April 25-29, 2022, OpenRe- view.net
work page 2022
-
[11]
Hu, S.X., Li, D., Stühmer, J., Kim, M., Hospedales, T.M., 2022b. Pushingthelimitsofsimplepipelinesforfew-shotlearning:External data and fine-tuning make a difference, in: CVPR 2022, IEEE. pp. 9058–9067
work page 2022
-
[12]
Hu, Z., Wang, L., Lan, Y., Xu, W., Lim, E., Bing, L., Xu, X., Poria, S., Lee, R.K., 2023. Llm-adapters: An adapter family for parameter- efficientfine-tuningoflargelanguagemodels,in:Bouamor,H.,Pino, J., Bali, K. (Eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December6-10,2023,Associat...
work page 2023
-
[13]
Huang, Y., Shakeri, F., Dolz, J., Boudiaf, M., Bahig, H., Ayed, I.B.,
-
[14]
Lp++: A surprisingly strong linear probe for few-shot clip, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
-
[15]
Visual prompt tuning, in: European conference on computer vision, Springer
Jia,M.,Tang,L.,Chen,B.C.,Cardie,C.,Belongie,S.,Hariharan,B., Lim, S.N., 2022. Visual prompt tuning, in: European conference on computer vision, Springer. pp. 709–727. Yaze Zhao and Yicong Liu et al.:Preprint submitted to ElsevierPage 14 of 16 Semantic Probe for SF-CDFSL
work page 2022
-
[16]
Khattak, M.U., Rasheed, H., Maaz, M., Khan, S., Khan, F.S., 2023a. Maple: Multi-modal prompt learning, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 19113–19122
-
[17]
Khattak, M.U., Wasim, S.T., Naseer, M., Khan, S., Yang, M., Khan, F.S.,2023b. Self-regulatingprompts:Foundationalmodeladaptation without forgetting, in: IEEE/CVF International Conference on Com- puterVision,ICCV2023,Paris,France,October1-6,2023,IEEE.pp. 15144–15154
work page 2023
-
[18]
Li, S., Liu, F., Hao, Z., Wang, X., Li, L., Liu, X., Chen, P., Ma, W.,
-
[19]
Logits deconfusion with clip for few-shot learning, in: Pro- ceedingsoftheComputerVisionandPatternRecognitionConference (CVPR), pp. 25411–25421
- [20]
-
[21]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Liang, V.W., Zhang, Y., Kwon, Y., Yeung, S., Zou, J.Y., 2022. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems 35, 17612–17625
work page 2022
-
[22]
Llama Team, 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783. URL:https://arxiv.org/abs/2407.21783, doi:10. 48550/arXiv.2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Doubly stochastic neighbor embedding on spheres
Lu, Y., Corander, J., Yang, Z., 2016. Doubly stochastic neighbor embedding on spheres. arXiv preprint arXiv:1609.01977
-
[24]
Ma, R., Zou, Y., Li, Y., Li, R., 2025. Reconstruction target matters in masked image modeling for cross-domain few-shot learning, in: Walsh, T., Shah, J., Kolter, Z. (Eds.), AAAI-25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25-March4,2025,Philadelphia,PA,USA,AAAIPress.pp.19305– 19313
work page 2025
-
[25]
Using deep learning for image-based plant disease detection
Mohanty, S.P., Hughes, D.P., Salathé, M., 2016. Using deep learning for image-based plant disease detection. Frontiers in plant science 7, 215232
work page 2016
-
[26]
Representation Learning with Contrastive Predictive Coding
van den Oord, A., Li, Y., Vinyals, O., 2018. Representation learning withcontrastivepredictivecoding. arXivpreprintarXiv:1807.03748. URL:https://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Pratt, S.M., Covert, I., Liu, R., Farhadi, A., 2023. What does a platy- pus look like? generating customized prompts for zero-shot image classification, in: IEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, IEEE. pp. 15645–15655
work page 2023
-
[28]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S.,Sastry,G.,Askell,A.,Mishkin,P.,Clark,J.,etal.,2021. Learning transferable visual models from natural language supervision, in: Internationalconferenceonmachinelearning,PmLR.pp.8748–8763
work page 2021
-
[29]
Schrodi, S., Hoffmann, D.T., Argus, M., Fischer, V., Brox, T., 2024. Two effects, one trigger: on the modality gap, object bias, and information imbalance in contrastive vision-language representation learning. arXiv preprint arXiv:2404.07983
-
[30]
Tang, Y., Lin, Z., Wang, Q., Zhu, P., Hu, Q., 2024. Amu-tuning: Effective logit bias for clip-based few-shot learning, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, IEEE. pp. 23323–23333
work page 2024
-
[31]
arXiv preprint arXiv:2001.08735
Tseng,H.Y.,Lee,H.Y.,Huang,J.B.,Yang,M.H.,2020.Cross-domain few-shotclassificationvialearnedfeature-wisetransformation. arXiv preprint arXiv:2001.08735
-
[32]
On isotropy of multimodal embed- dings
Tyshchuk, K., Karpikova, P., Spiridonov, A., Prutianova, A., Razzhi- gaev, A., Panchenko, A., 2023. On isotropy of multimodal embed- dings. Information 14, 392
work page 2023
-
[33]
Masked embedding modeling with rapid domain adjustment for few-shot image classi- fication
Walsh, R., Osman, I.I., Shehata, M.S., 2023. Masked embedding modeling with rapid domain adjustment for few-shot image classi- fication. IEEE Trans. Image Process. , 4907–4920
work page 2023
-
[34]
Cross-domain few-shot classification via adversarial task augmentation
Wang, H., Deng, Z.H., 2021. Cross-domain few-shot classification via adversarial task augmentation. arXiv preprint arXiv:2104.14385
-
[35]
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.,
-
[36]
Chestx-ray8: Hospital-scale chest x-ray database and bench- marks on weakly-supervised classification and localization of com- mon thorax diseases, in: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21- 26, 2017, IEEE Computer Society. pp. 3462–3471
work page 2017
-
[37]
Flair: Vlm with fine-grained language-informed image representa- tions
Xiao, R., Kim, S., Georgescu, M.I., Akata, Z., Alaniz, S., 2024. Flair: Vlm with fine-grained language-informed image representa- tions. arXiv preprint arXiv:2412.03561
-
[38]
Xu, H., Liu, L., Zhi, S., Fu, S., Su, Z., Cheng, M., Liu, Y., 2024a. Enhancinginformationmaximizationwithdistance-awarecontrastive learningforsource-freecross-domainfew-shotlearning. IEEETrans. Image Process. , 2058–2073
work page 2058
-
[39]
Xu, H., Liu, Y., Liu, L., Zhi, S., Sun, S., Liu, T., Cheng, M.M., 2024b. Step-wise distribution alignment guided style prompt tun- ing for source-free cross-domain few-shot learning. arXiv preprint arXiv:2411.10070. URL:https://arxiv.org/abs/2411.10070
-
[40]
Yang, L., Zhang, R.Y., Wang, Y., Xie, X., 2024. Mma: Multi-modal adapterforvision-languagemodels,in:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 23826–23837
work page 2024
-
[41]
Yang,Y.,Deng,J.,Li,W.,Duan,L.,2025. Resclip:Residualattention fortraining-freedensevision-languageinference,in:IEEE/CVFCon- ference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville,TN,USA,June11-15,2025,ComputerVisionFoundation / IEEE. pp. 29968–29978
work page 2025
-
[42]
Yazdanpanah, M., Moradi, P., 2022. Visual domain bridge: A source-freedomainadaptationforcross-domainfew-shotlearning,in: IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, IEEE. pp. 2867–2876. URL:https://doi.org/10.1109/ CVPRW56347.2022.00324, doi:10.1109/CVPRW56347.2022.00324
-
[43]
Zanella, M., Ayed, I.B., 2024. Low-rank few-shot adaptation of vision-language models, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024 - Workshops, Seattle, WA, USA, June 17-18, 2024, IEEE. pp. 1593–1603
work page 2024
-
[44]
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L., 2023. Sigmoid loss for language image pre-training, in: Proceedings of the IEEE/CVF international conference on computer vision, pp. 11975–11986
work page 2023
-
[45]
arXiv preprint arXiv:2111.03930 , year=
Zhang, R., Fang, R., Zhang, W., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H., 2021. Tip-adapter: Training-free clip-adapter for better vision- language modeling. arXiv preprint arXiv:2111.03930
-
[46]
Zhang, R., Zhang, W., Fang, R., Gao, P., Li, K., Dai, J., Qiao, Y., Li, H., 2022. Tip-adapter: Training-free adaption of CLIP for few-shot classification, in: Computer Vision - ECCV 2022 - 17th European Conference, pp. 493–510
work page 2022
-
[47]
Zhou, F., Wang, P., Zhang, L., Wei, W., Zhang, Y., 2023. Revisiting prototypicalnetworkforcrossdomainfew-shotlearning,in:Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 20061–20070
work page 2023
-
[48]
Learning to prompt for vision-language models
Zhou, K., Yang, J., Loy, C.C., Liu, Z., 2022. Learning to prompt for vision-language models. International Journal of Computer Vision 130, 2337–2348
work page 2022
-
[49]
Zhuo, L., Wang, Z., Fu, Y., Qian, T., 2024. Prompt as free lunch: Enhancing diversity in source-free cross-domain few-shot learning through semantic-guided prompting. arXiv preprint arXiv:2412.00767. URL:https://arxiv.org/abs/2412.00767
-
[50]
Flatten long-range loss landscapes for cross-domain few-shot learning, in: CVPR 2024, IEEE
Zou, Y., Liu, Y., Hu, Y., Li, Y., Li, R., 2024a. Flatten long-range loss landscapes for cross-domain few-shot learning, in: CVPR 2024, IEEE. pp. 23575–23584
work page 2024
-
[51]
Attention temperature matters in vit-based cross-domain few-shot learning
Zou, Y., Ma, R., Li, Y., Li, R., 2024b. Attention temperature matters in vit-based cross-domain few-shot learning. Advances in Neural Information Processing Systems 37, 116332–116354
-
[52]
A closer look at the CLS token for cross-domain few-shot learning, in: NeurIPS 2024
Zou, Y., Yi, S., Li, Y., Li, R., 2024c. A closer look at the CLS token for cross-domain few-shot learning, in: NeurIPS 2024. Yaze Zhao and Yicong Liu et al.:Preprint submitted to ElsevierPage 15 of 16 Semantic Probe for SF-CDFSL Yaze Zhaoreceived the B.S. degree from the School of Computer Science and Technology, Huazhong University of Science and Technol...
work page 2024
-
[53]
She was a visiting scholar at the University of California, Santa Barbara
She is currently a Professor in the School of Computer Science and Technology, Huazhong University of Science and Technology. She was a visiting scholar at the University of California, Santa Barbara. She has published more than 60 journal and conference papers (NeurIPS, TKDE, SIGIR,WWW,ICDM,IJCAI).Sheisalsoasenior memberoftheChinaComputerFederation(CCF)....
work page 1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.