Recognition: 2 theorem links
· Lean TheoremSafety Context Injection: Inference-Time Safety Alignment via Static Filtering and Agentic Analysis
Pith reviewed 2026-05-13 01:06 UTC · model grok-4.3
The pith
Prepending an external safety assessment report at inference time reduces jailbreak success and toxicity in large reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
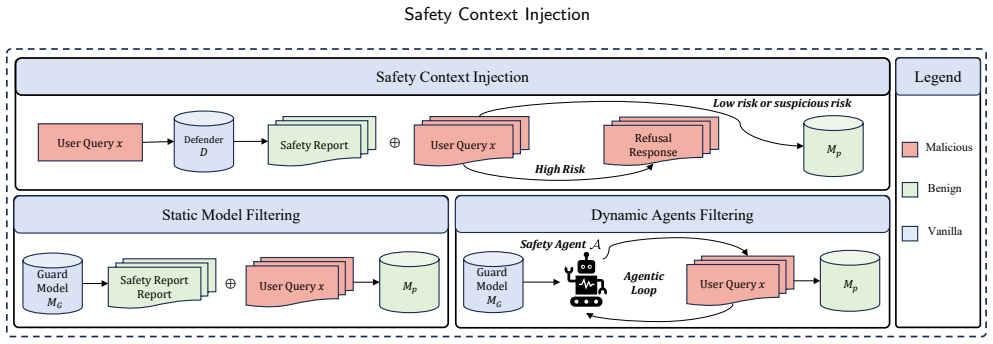
Safety Context Injection prepends a structured external risk report to the protected model's input so that the model generates its response while conditioned on that report. The report is produced either by Static Model Filtering, a single-pass guard, or by Dynamic Agents Filtering, which runs an agentic loop to gather evidence from ambiguous or extended contexts. This separation addresses the thinking-output gap and yields lower attack success rates and toxicity without any weight modification.
What carries the argument
Safety Context Injection, the mechanism of generating and prepending a structured external risk report before the user query reaches the protected model.
If this is right
- Both the static and dynamic variants lower attack success rate and toxicity across the tested benchmarks and models.
- Static filtering supplies low-latency protection for rapid deployment.
- Dynamic agentic analysis improves detection when intent is semantically disguised or spread across long contexts.
- The method applies to both base and reasoning models under multiple jailbreak families.
- The injected report narrows the gap between cautious reasoning and unsafe final outputs.
Where Pith is reading between the lines
- The separation of assessment from generation could be combined with other inference-time controls such as output sampling adjustments.
- The same injection pattern might extend to domains beyond safety, such as factual grounding or policy compliance.
- Scalability depends on the cost of the external analyzer relative to the protected model's inference budget.
Load-bearing premise
An external safety assessor can reliably surface hidden harmful intent even when it is framed educationally or dispersed over long contexts, and prepending that report will steer the model toward safe outputs.
What would settle it
A jailbreak prompt that passes both the static filter and the agentic analyzer with low reported risk yet still elicits a harmful final answer from the model.
Figures





read the original abstract
Large Reasoning Models (LRMs) improve performance on complex tasks, but they also make safety control harder at deployment time. In black-box settings, defenders cannot modify model weights and must instead intervene at inference time. This setting creates three practical challenges: harmful intent may be hidden by educational or role-play framing, deep safety analysis can introduce non-trivial latency, and long adversarial contexts can dilute the local cues that simpler filters rely on. These challenges can expose an apparent thinking--output gap, where the model appears cautious during reasoning but still produces an unsafe final answer. To address this problem, we propose Safety Context Injection (SCI), an inference-time framework that separates safety assessment from task generation and prepends a structured external risk report as injected safety context for the protected model. The framework is instantiated in two complementary variants: Static Model Filtering (SMF), a lightweight one-pass guard for fast deployment, and Dynamic Agents Filtering (DAF), an agentic-loop-based analyzer that iteratively gathers and synthesizes evidence for ambiguous or long-context attacks. Across AdvBench and GPTFuzz, spanning base and reasoning models under five jailbreak families, both variants reduce attack success rate and toxicity in the evaluated settings. SMF offers an efficient low-latency option, while DAF is more effective when harmful intent is semantically disguised or dispersed across long contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Safety Context Injection (SCI), an inference-time framework for black-box safety alignment of large reasoning models. It decouples safety assessment from task generation by generating a structured external risk report (via Static Model Filtering or Dynamic Agents Filtering) and prepending it as context to steer the protected model away from unsafe outputs. The approach targets challenges like hidden harmful intent in educational/role-play framing, latency, and dilution in long adversarial contexts. Empirical claims state that both SMF and DAF variants reduce attack success rate and toxicity across AdvBench and GPTFuzz benchmarks, spanning base and reasoning models under five jailbreak families.
Significance. If the reductions in ASR and toxicity are robustly demonstrated with proper controls, this would offer a practical, deployable inference-time defense that does not require weight modification. The separation of assessment and generation, plus the agentic variant for ambiguous cases, addresses a real gap in current black-box alignment. However, the absence of quantitative results, baselines, error bars, or false-negative analysis in the provided description limits assessment of whether the method generalizes beyond tested families or actually conditions the model on the injected report.
major comments (2)
- Abstract and results description: The central claim that both variants 'reduce attack success rate and toxicity in the evaluated settings' is stated without any quantitative values, error bars, baseline comparisons (e.g., against simple guardrails or no-injection controls), or details on how risk reports are generated and scored. This leaves the empirical support for the framework's effectiveness weakly grounded and prevents evaluation of effect sizes or statistical reliability.
- Evaluation setup (implied in abstract's benchmark claims): The skeptic concern about external safety assessment failing on disguised intent is load-bearing. No evidence is supplied on false-negative rates for dispersed harmful intent in long/role-play/educational contexts, nor on whether the protected model actually conditions on the prepended report rather than ignoring it during reasoning. If detection or steering fails in these regimes, the reported reductions do not support generalization claims.
minor comments (2)
- Abstract: The phrasing 'in the evaluated settings' is vague; specify the exact models, jailbreak families, and metrics used.
- Notation and terminology: 'thinking--output gap' is introduced without a formal definition or example; clarify how it is measured.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas where the presentation of our empirical results and evaluation rigor can be strengthened. We address each major comment below and commit to revising the manuscript to provide clearer quantitative grounding and additional analysis.
read point-by-point responses
-
Referee: Abstract and results description: The central claim that both variants 'reduce attack success rate and toxicity in the evaluated settings' is stated without any quantitative values, error bars, baseline comparisons (e.g., against simple guardrails or no-injection controls), or details on how risk reports are generated and scored. This leaves the empirical support for the framework's effectiveness weakly grounded and prevents evaluation of effect sizes or statistical reliability.
Authors: We agree that the abstract would be strengthened by including specific quantitative highlights. The full manuscript reports detailed ASR and toxicity reductions across AdvBench and GPTFuzz for both SMF and DAF variants, with baseline comparisons (including no-injection controls and simple guardrails) and error bars derived from multiple evaluation runs. We will revise the abstract to incorporate key effect sizes and statistical details, while expanding the methods section to explicitly describe risk report generation, scoring criteria, and how baselines were implemented. This addresses the concern about weakly grounded claims without altering the core findings. revision: yes
-
Referee: Evaluation setup (implied in abstract's benchmark claims): The skeptic concern about external safety assessment failing on disguised intent is load-bearing. No evidence is supplied on false-negative rates for dispersed harmful intent in long/role-play/educational contexts, nor on whether the protected model actually conditions on the prepended report rather than ignoring it during reasoning. If detection or steering fails in these regimes, the reported reductions do not support generalization claims.
Authors: We acknowledge that explicit false-negative analysis for disguised intent and direct evidence of model conditioning on the injected report are essential for supporting generalization. Our experiments already span five jailbreak families that include role-play, educational, and long-context scenarios, with results showing consistent reductions under these conditions. To address the gap, we will add a dedicated subsection with quantitative false-negative rates for dispersed harmful intent and controlled ablations (with vs. without the risk report) demonstrating that the protected model conditions on the prepended context. These additions will be included in the revised evaluation section. revision: yes
Circularity Check
No significant circularity: empirical proposal without derivations or self-referential reductions
full rationale
The paper describes an inference-time framework (SCI with SMF/DAF variants) and reports empirical reductions in attack success rate and toxicity across AdvBench and GPTFuzz under multiple jailbreak families. No equations, parameter fittings, uniqueness theorems, or derivations are referenced in the abstract or framing. Claims rest on direct benchmark measurements rather than any step that reduces by construction to inputs, fitted parameters, or self-citations. This is a standard non-circular empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption External safety assessment can accurately identify hidden harmful intent without model internals.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Safety Context Injection (SCI) ... Static Model Filtering (SMF) ... Dynamic Agents Filtering (DAF) ... prepends a structured external risk report
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
agentic-loop-based analyzer that iteratively gathers and synthesizes evidence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anil,C.,Durmus,E.,Panickssery,N.,Sharma,M.,Benton,J.,Kundu, S., Batson, J., Tong, M., Mu, J., Ford, D., et al., 2024. Many-shot jailbreaking. Advances in Neural Information Processing Systems 37, 129696–129742
work page 2024
-
[2]
Chain-of-lure: A universal jailbreak attack framework using uncon- strained synthetic narratives
Chang, W., Zhu, T., Zhao, Y., Song, S., Xiong, P., Zhou, W., 2026. Chain-of-lure: A universal jailbreak attack framework using uncon- strained synthetic narratives. URL:https://arxiv.org/abs/2505. 17519,arXiv:2505.17519
-
[3]
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G.J., Wong, E., 2025. Jailbreaking black box large language models in twenty queries, in: 2025 IEEE Conference on Secure and Trustworthy Ma- chine Learning (SaTML), IEEE. pp. 23–42
work page 2025
-
[4]
En- hancing container security through phase-based system call filtering
Chen, K., Lu, H., Yao, Y., Fang, B., Liu, Y., Tian, Z., 2025a. En- hancing container security through phase-based system call filtering. IEEE Transactions on Cloud Computing 13, 983–994. doi:10.1109/ TCC.2025.3583414
-
[5]
Chen, S., Piet, J., Sitawarin, C., Wagner, D., 2025b. StruQ: De- fending against prompt injection with structured queries, in: 34th USENIXSecuritySymposium(USENIXSecurity25),USENIXAs- sociation.pp.2383–2400. URL:https://www.usenix.org/conference/ usenixsecurity25/presentation/chen-sizhe
-
[6]
Khanov, M., Burapacheep, J., Li, Y., 2024. ARGS: Alignment as reward-guided search, in: The Twelfth International Conference on Learning Representations. URL:https://openreview.net/forum?id= shgx0eqdw6
work page 2024
-
[7]
Li, H., Liu, X., Zhang, N., Xiao, C., 2025. PIGuard: Prompt injection guardrail via mitigating overdefense for free, in: Pro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Vienna, Austria. pp. 30420–30437. URL:https://aclanthology.org/2025.acl-long.1...
work page 2025
-
[8]
Li, Z., Peng, B., He, P., Yan, X., 2024. Evaluating the instruction- followingrobustnessoflargelanguagemodelstopromptinjection,in: Proceedingsofthe2024ConferenceonEmpiricalMethodsinNatural Language Processing, Association for Computational Linguistics, Miami,Florida,USA.pp.557–568. URL:https://aclanthology.org/ 2024.emnlp-main.33/, doi:10.18653/v1/2024.em...
-
[9]
AutoRAN: Automated Hijacking of Safety Reasoning in Large Reasoning Models
Liang, J., Jiang, T., Wang, Y., Zhu, R., Ma, F., Wang, T., 2025. Autoran: Automated hijacking of safety reasoning in large reasoning models. URL:https://arxiv.org/abs/2505.10846,arXiv:2505.10846
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Liu, Q., Zhou, Z., He, L., Liu, Y., Zhang, W., Su, S., 2024a. Alignment-enhanced decoding: Defending jailbreaks via token-level adaptive refining of probability distributions, in: Proceedings of the 2024ConferenceonEmpiricalMethodsinNaturalLanguageProcess- ing,AssociationforComputationalLinguistics,Miami,Florida,USA. pp. 2802–2816. URL:https://aclantholog...
-
[11]
Liu, T., Zhang, Y., Zhao, Z., Dong, Y., Meng, G., Chen, K., 2024b. Making them ask and answer: Jailbreaking large language models in few queries via disguise and reconstruction, in: 33rd USENIX Security Symposium (USENIX Security 24), USENIX Association, Philadelphia, PA. pp. 4711–4728. URL:https://www.usenix.org/ conference/usenixsecurity24/presentation/liu-tong
-
[12]
Liu, X., Xu, N., Chen, M., Xiao, C., 2024c. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models, in: The TwelfthInternationalConferenceonLearningRepresentations.URL: https://openreview.net/forum?id=7Jwpw4qKkb
-
[13]
Lu, Y., Cheng, J., Zhang, Z., Cui, S., Wang, C., Gu, X., Dong, Y., Tang, J., Wang, H., Huang, M., 2025. Longsafety: Evaluating long- context safety of large language models, in: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 31705–31725
work page 2025
-
[14]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J.,Hilton,J.,Kelton,F.,Miller,L.,Simens, M.,Askell,A.,Welinder, P., Christiano, P.F., Leike, J., Lowe, R., 2022. Training language models to follow instructions with human feedback, in: Advances in Neural Information Processing ...
work page 2022
-
[15]
Reimers, N., Gurevych, I., 2019. Sentence-BERT: Sentence embed- dings using siamese BERT-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Pro- cessing (EMNLP-IJCNLP), Association for Computational Linguis- tics,HongKong,China.pp.3982–3992.URL...
-
[16]
Shen, X., Chen, Z., Backes, M., Shen, Y., Zhang, Y., 2024. “do anything now”: Characterizing and evaluating in-the-wild jailbreak promptsonlargelanguagemodels,in:Proceedingsofthe2024ACM SIGSAC Conference on Computer and Communications Security, Association for Computing Machinery. pp. 1671–1685. URL:https: //doi.org/10.1145/3658644.3670388, doi:10.1145/36...
-
[17]
Wei, A., Haghtalab, N., Steinhardt, J., 2023. Jailbroken: How does LLM safety training fail?, in: Advances in Neural Information Processing Systems, pp. 80079–80110. URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ fd6613131889a4b656206c50a8bd7790-Abstract-Conference.html
work page 2023
-
[18]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q.V., Zhou, D., 2022. Chain-of-thought prompting elicits reasoning in large language models, in: Ad- vances in Neural Information Processing Systems, pp. 24824– 24837. URL:https://proceedings.neurips.cc/paper/2022/hash/ 9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html
work page 2022
-
[19]
Wu, T., Zhang, S., Song, K., Xu, S., Zhao, S., Agrawal, R., Indurthi, S.R., Xiang, C., Mittal, P., Zhou, W., 2025. Instructional segment embedding:ImprovingLLMsafetywithinstructionhierarchy,in:The Thirteenth International Conference on Learning Representations. URL:https://openreview.net/forum?id=sjWG7B8dvt
work page 2025
-
[20]
URL:https://aclanthology.org/2025
Xiong,C.,Qi,X.,Chen,P.Y.,Ho,T.Y.,2025.Defensivepromptpatch: A robust and generalizable defense of large language models against jailbreak attacks, in: Findings of the Association for Computational Linguistics: ACL 2025, Association for Computational Linguistics, Vienna,Austria.pp.409–437. URL:https://aclanthology.org/2025. findings-acl.23/, doi:10.18653/v...
-
[21]
Xu, Z., Jiang, F., Niu, L., Jia, J., Lin, B.Y., Poovendran, R., 2024. SafeDecoding: Defending against jailbreak attacks via safety-aware decoding, in: Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Bangkok, Thailand. pp. 5587–5605. URL:https://ac...
-
[22]
Yan,J.,Yadav,V.,Li,S.,Chen,L.,Tang,Z.,Wang,H.,Srinivasan,V., Ren,X.,Jin,H.,2024. Backdooringinstruction-tunedlargelanguage models with virtual prompt injection, in: Proceedings of the 2024 Conference of the North American Chapter of the Association for ComputationalLinguistics:HumanLanguageTechnologies(Volume 1: Long Papers), Association for Computational...
-
[23]
Yu, J., Lin, X., Yu, Z., Xing, X., 2024a. LLM-Fuzzer: Scaling assessment of large language model jailbreaks, in: 33rd USENIX Security Symposium (USENIX Security 24), USENIX Association, Philadelphia, PA. pp. 4657–4674. URL:https://www.usenix.org/ conference/usenixsecurity24/presentation/yu-jiahao
-
[24]
Yu, Z., Liu, X., Liang, S., Cameron, Z., Xiao, C., Zhang, N., 2024b. Don’t listen to me: Understanding and exploring jail- break prompts of large language models, in: 33rd USENIX Security Symposium (USENIX Security 24), USENIX Association, Philadel- phia, PA. pp. 4675–4692. URL:https://www.usenix.org/conference/ usenixsecurity24/presentation/yu-zhiyuan
-
[25]
Zhang, Z., Yang, J., Ke, P., Mi, F., Wang, H., Huang, M., 2024. Defendinglargelanguagemodelsagainstjailbreakingattacksthrough goal prioritization, in: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers),AssociationforComputationalLinguistics,Bangkok,Thailand. pp.8865–8887. URL:https://aclanthol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.