Recognition: no theorem link
When Reasoning Traces Become Performative: Step-Level Evidence that Chain-of-Thought Is an Imperfect Oversight Channel
Pith reviewed 2026-05-13 06:24 UTC · model grok-4.3
The pith
Chain-of-thought traces often keep generating text after models have internally committed to an answer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
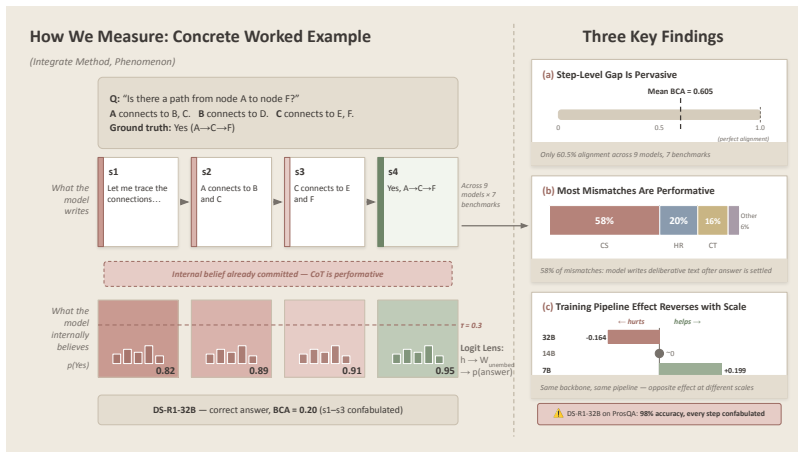
Across nine models and seven benchmarks, latent commitment and explicit answer arrival align on only 61.9% of steps on average. The dominant mismatch pattern is confabulated continuation: 58.0% of detected mismatch events occur after the answer-commitment proxy has already stabilized while the trace continues producing deliberative-looking text, and a vacuousness analysis shows that the committed answer does not change during these steps.
What carries the argument
A step-level Detect-Classify-Compare framework built around an answer-commitment proxy that is cross-validated with Patchscopes, tuned-lens probes, and causal direction ablation.
Load-bearing premise
The answer-commitment proxy accurately identifies the internal step at which the model forms its final answer.
What would settle it
A truncation experiment that stops generation right after the proxy signals commitment and checks whether the final answer stays the same in the great majority of cases; frequent changes would indicate the proxy is not capturing the true commitment point.
Figures






read the original abstract
Chain-of-thought (CoT) traces are increasingly used both to improve language model capability and to audit model behavior, implicitly assuming that the visible trace remains synchronized with the computation that determines the answer. We test this assumption with a step-level Detect-Classify-Compare framework built around an answer-commitment proxy that is cross-validated with Patchscopes, tuned-lens probes, and causal direction ablation. Across nine models and seven reasoning benchmarks, latent commitment and explicit answer arrival align on only 61.9% of steps on average. The dominant mismatch pattern is confabulated continuation: 58.0% of detected mismatch events occur after the answer-commitment proxy has already stabilized while the trace continues producing deliberative-looking text, and a vacuousness analysis shows that the committed answer does not change during these steps. In architecture-matched Qwen2.5/DeepSeek-R1-Distill comparisons, the reasoning pipeline changes failure composition more than aggregate alignment, most clearly at 32B where confabulated steps decrease as contradictory states increase. Lower step-level alignment is also associated with larger CoT utility, suggesting that the settings that benefit most from CoT are often the least temporally faithful. Paired truncation and a complementary donor-corruption test further indicate that much post-commitment text is not load-bearing for the final answer. These findings suggest that CoT can remain useful while still being an unreliable report of when the answer was formed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Chain-of-Thought (CoT) traces are imperfectly synchronized with the internal computation that forms the final answer. Using a Detect-Classify-Compare framework built on an answer-commitment proxy cross-validated via Patchscopes, tuned-lens probes, and causal-direction ablation, it reports that latent commitment and explicit answer arrival align on only 61.9% of steps across nine models and seven benchmarks. The dominant mismatch is confabulated continuation (58.0% of detected events), in which the trace continues generating deliberative text after the proxy has stabilized; truncation and donor-corruption tests indicate this post-commitment text is not load-bearing. Architecture-matched comparisons show that reasoning-pipeline failure composition changes more than aggregate alignment, and lower step-level alignment correlates with greater CoT utility.
Significance. If the results hold, the work is significant for interpretability and oversight research. It supplies step-level empirical evidence that CoT cannot be treated as a faithful report of when an answer is formed, with direct implications for using CoT in auditing or capability enhancement. The multi-method validation of the proxy, the load-bearing tests, and the finding that CoT utility is highest when temporal faithfulness is lowest are concrete contributions that could shift how CoT is deployed and evaluated.
major comments (2)
- The answer-commitment proxy is load-bearing for the 61.9% alignment and 58.0% confabulated-continuation statistics, yet the manuscript provides insufficient methodological detail on its exact construction, threshold rules, and quantitative agreement rates among the three validation methods (Patchscopes, tuned-lens, causal ablation). This absence prevents full assessment of the proxy's reliability and reproducibility of the central percentages.
- The reported association between lower step-level alignment and larger CoT utility is presented without error bars, sample sizes per comparison, or statistical controls, weakening the claim that the settings benefiting most from CoT are the least temporally faithful.
minor comments (3)
- The abstract and results sections report concrete percentages (61.9%, 58.0%) but omit confidence intervals or standard errors, which would help readers gauge variability across models and benchmarks.
- Data availability and code-release statements are missing; given the empirical nature of the work, these should be added to support verification of the alignment metrics and truncation experiments.
- Tables or figures summarizing per-model or per-benchmark alignment rates should include the number of steps or examples underlying each percentage to allow readers to assess statistical power.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on methodological transparency and statistical presentation. Both points identify areas where the manuscript can be strengthened for reproducibility and rigor, and we will incorporate the requested details in revision.
read point-by-point responses
-
Referee: The answer-commitment proxy is load-bearing for the 61.9% alignment and 58.0% confabulated-continuation statistics, yet the manuscript provides insufficient methodological detail on its exact construction, threshold rules, and quantitative agreement rates among the three validation methods (Patchscopes, tuned-lens, causal ablation). This absence prevents full assessment of the proxy's reliability and reproducibility of the central percentages.
Authors: We agree that additional detail is needed. In the revised manuscript we will insert a dedicated Methods subsection that specifies the exact construction of the answer-commitment proxy (including token-level scoring rules and stabilization criteria), the precise threshold values chosen, and quantitative agreement statistics (pairwise concordance percentages and Cohen's kappa) among Patchscopes, tuned-lens, and causal-ablation validations. These metrics were computed during the study but summarized for brevity; they will now be reported in full with supporting tables. revision: yes
-
Referee: The reported association between lower step-level alignment and larger CoT utility is presented without error bars, sample sizes per comparison, or statistical controls, weakening the claim that the settings benefiting most from CoT are the least temporally faithful.
Authors: We accept this critique. The revision will augment the relevant results section and figure with error bars (standard errors across seeds), explicit per-comparison sample sizes, and statistical controls (e.g., partial correlation or regression models that account for model scale and benchmark difficulty). These additions will allow readers to assess the robustness of the alignment-utility relationship. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation relies on empirical measurement of alignment between an answer-commitment proxy and explicit CoT steps, with the proxy cross-validated via Patchscopes, tuned-lens probes, causal-direction ablation, truncation experiments, and donor-corruption tests. These checks are independent of the target statistics (61.9% alignment, 58% confabulated continuation) and do not reduce any reported quantity to a fitted parameter or self-referential definition. No equations or claims in the abstract or context exhibit self-definitional structure, fitted-input-as-prediction, load-bearing self-citation, or ansatz smuggling; the central findings remain falsifiable observations rather than tautologies.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The answer-commitment proxy accurately detects the timing of internal answer formation
- domain assumption Patchscopes, tuned-lens probes, and causal direction ablation provide valid cross-validation of the proxy
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Chain-of-thought reasoning in the wild is not always faithful.arXiv preprint arXiv: 2503.08679, 2025
Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. Chain-of-thought reasoning in the wild is not always faithful.arXiv preprint arXiv:2503.08679, 2025
-
[3]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, 2023
work page 2023
-
[4]
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
work page 2022
-
[5]
Eliciting latent predictions from transformers with the tuned lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[6]
Reasoning theater: Disentangling model beliefs from chain-of- thought, 2026
Siddharth Boppana, Annabel Ma, Max Loeffler, Raphael Sarfati, Eric Bigelow, Atticus Geiger, Owen Lewis, and Jack Merullo. Reasoning theater: Disentangling model beliefs from chain-of- thought.arXiv preprint arXiv:2603.05488, 2026
-
[7]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InInternational Conference on Learning Representations, 2023
work page 2023
-
[8]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schul- man, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don’t always say what they think.arXiv preprint arXiv:2505.05410, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Faithful reasoning using large language models.arXiv preprint arXiv:2208.14271, 2022
Antonia Creswell and Murray Shanahan. Faithful reasoning using large language models.arXiv preprint arXiv:2208.14271, 2022
-
[11]
ERASER: A benchmark to evaluate rationalized NLP models
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. ERASER: A benchmark to evaluate rationalized NLP models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4443–4458, 2020
work page 2020
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Scott Emmons, Erik Jenner, David K Elson, Rif A Saurous, Senthooran Rajamanoharan, Heng Chen, Irhum Shafkat, and Rohin Shah. When chain of thought is necessary, language models struggle to evade monitors.arXiv preprint arXiv:2507.05246, 2025
-
[14]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, et al. Causal abstraction: A theoretical foundation for mechanistic interpretability.Journal of Machine Learning Research, 26(83):1–64, 2025
work page 2025
-
[15]
Patchscopes: A unifying framework for inspecting hidden representations of language models
Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva. Patchscopes: A unifying framework for inspecting hidden representations of language models. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[16]
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
-
[17]
Google DeepMind. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
work page 2025
-
[19]
Kilem L. Gwet. Computing inter-rater reliability and its variance in the presence of high agreement.British Journal of Mathematical and Statistical Psychology, 61(1):29–48, 2008. 10
work page 2008
-
[20]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Counterfactual simulation training for chain-of-thought faithfulness
Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness.arXiv preprint arXiv:2602.20710, 2026
-
[22]
Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Tsygankova, Alejandro Baez, et al. Teaching large language models to reason with reinforcement learning.arXiv preprint arXiv:2403.04642, 2024
-
[23]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
work page 2021
-
[24]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xiny- ing Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. In International Conference on Learning Representations, 2024
work page 2024
-
[25]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022
work page 2022
-
[27]
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
-
[28]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[30]
Persona Non Grata: Single-Method Safety Evaluation Is Incomplete for Persona-Imbued LLMs
Wenkai Li, Fan Yang, Shaunak A. Mehta, and Koichi Onoue. Persona non grata: Single-method safety evaluation is incomplete for persona-imbued llms, 2026. URL https://arxiv.org/ abs/2604.11120
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Bench- marking and improving generator-validator consistency of language models
Xiang Lisa Li, Vaishnavi Shrivastava, Siyan Li, Tatsunori Hashimoto, and Percy Liang. Bench- marking and improving generator-validator consistency of language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[32]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations, 2024
work page 2024
-
[33]
Matt MacDermott, Qiyao Wei, Rada Djoneva, and Francis Rhys Ward. Reasoning under pressure: How do training incentives influence chain-of-thought monitorability?arXiv preprint arXiv:2512.00218, 2025
-
[34]
Self-refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[35]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large lan- guage model representations of true/false datasets. InFirst Conference on Language Modeling, 2024
work page 2024
-
[36]
Austin Meek, Eitan Sprejer, Iván Arcuschin, Austin J Brockmeier, and Steven Basart. Mea- suring chain-of-thought monitorability through faithfulness and verbosity.arXiv preprint arXiv:2510.27378, 2025
-
[37]
Interpreting GPT: The logit lens.LessWrong, 2020
nostalgebraist. Interpreting GPT: The logit lens.LessWrong, 2020. https://www.lesswrong. com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens. 11
work page 2020
-
[38]
Show Your Work: Scratchpads for Intermediate Computation with Language Models
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Biber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models.arXiv preprint arXiv:2112.00114, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
OpenAI. Learning to reason with LLMs. https://openai.com/index/ learning-to-reason-with-llms/, 2024
work page 2024
-
[40]
Vardhan Palod, Karthik Valmeekam, Kaya Stechly, and Subbarao Kambhampati. Performative thinking? the brittle correlation between cot length and problem complexity.arXiv preprint arXiv:2509.07339, 2025
-
[41]
Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15012–15032, 2024
work page 2024
-
[42]
Ansh Radhakrishnan, Karina Nguyen, Anna Chen, Carol Chen, Carson Denison, Danny Her- nandez, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamil ˙e Lukoši¯ut˙e, et al. Ques- tion decomposition improves the faithfulness of model-generated reasoning.arXiv preprint arXiv:2307.11768, 2023
-
[43]
GPQA: A graduate-level Google-proof Q&A benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level Google-proof Q&A benchmark. InFirst Conference on Language Modeling, 2024
work page 2024
-
[44]
Preventing language models from hiding their reasoning
Fabien Roger and Ryan Greenblatt. Preventing language models from hiding their reasoning. arXiv preprint arXiv:2310.18512, 2023
-
[45]
Language models are greedy reasoners: A systematic formal analysis of chain-of-thought
Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. InInternational Conference on Learning Representations, 2023
work page 2023
-
[46]
Testing the general deductive reasoning capacity of large lan- guage models using OOD examples
Abulhair Saparov, Richard Yuanzhe Pang, Vishakh Padmakumar, Nitish Joshi, Mehran Kazemi, Najoung Kim, and He He. Testing the general deductive reasoning capacity of large lan- guage models using OOD examples. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[47]
Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning
Xu Shen, Song Wang, Zhen Tan, Laura Yao, Xinyu Zhao, Kaidi Xu, Xin Wang, and Tianlong Chen. Faithcot-bench: Benchmarking instance-level faithfulness of chain-of-thought reasoning. arXiv preprint arXiv:2510.04040, 2025
-
[48]
Challenging BIG-Bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Challenging BIG-Bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, 2023
work page 2023
-
[49]
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, and Himabindu Lakkaraju. On the hardness of faithful chain-of-thought reasoning in large language models.arXiv preprint arXiv:2406.10625, 2024
-
[50]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[51]
Measuring chain of thought faithfulness by unlearning reasoning steps
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasovi´c, and Yonatan Belinkov. Measuring chain of thought faithfulness by unlearning reasoning steps. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9946–9971, 2025
work page 2025
-
[52]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Investigating gender bias in language models using causal mediation analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis. InAdvances in Neural Information Processing Systems, volume 33, pages 12388–12401, 2020
work page 2020
-
[54]
Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Run-Ze Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024. 12
work page 2024
-
[55]
Chain-of-thought reasoning without prompting
Xuezhi Wang and Denny Zhou. Chain-of-thought reasoning without prompting. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[56]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[57]
MMLU-Pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[58]
Zhenyu Wang. LogitLens4LLMs: Extending logit lens analysis to modern large language models.arXiv preprint arXiv:2503.11667, 2025
-
[59]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
work page 2022
-
[60]
Teach me to explain: A review of datasets for explainable NLP
Sarah Wiegreffe and Ana Marasovic. Teach me to explain: A review of datasets for explainable NLP. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
work page 2021
-
[61]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[64]
Donald Ye, Max Loffgren, Om Kotadia, and Linus Wong. Mechanistic evidence for faithfulness decay in chain-of-thought reasoning.arXiv preprint arXiv:2602.11201, 2026
-
[65]
Richard J Young. Lie to me: How faithful is chain-of-thought reasoning in reasoning models? arXiv preprint arXiv:2603.22582, 2026
-
[66]
Richard J Young. Why models know but don’t say: Chain-of-thought faithfulness diver- gence between thinking tokens and answers in open-weight reasoning models.arXiv preprint arXiv:2603.26410, 2026
-
[67]
STaR: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[68]
Artur Zolkowski, Wen Xing, David Lindner, Florian Tramèr, and Erik Jenner. Can reasoning models obfuscate reasoning? stress-testing chain-of-thought monitorability.arXiv preprint arXiv:2510.19851, 2025
-
[69]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. A Model and Benchmark Specifications Table 2 provides the full architectural specifications for all mo...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.