Recognition: 2 theorem links
· Lean TheoremFrom Token to Token Pair: Efficient Prompt Compression for Large Language Models in Clinical Prediction
Pith reviewed 2026-05-13 06:35 UTC · model grok-4.3
The pith
MedTPE merges frequent medical token pairs to compress EHR sequences for LLMs, cutting input length up to 31% and latency up to 63% with no loss in clinical prediction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
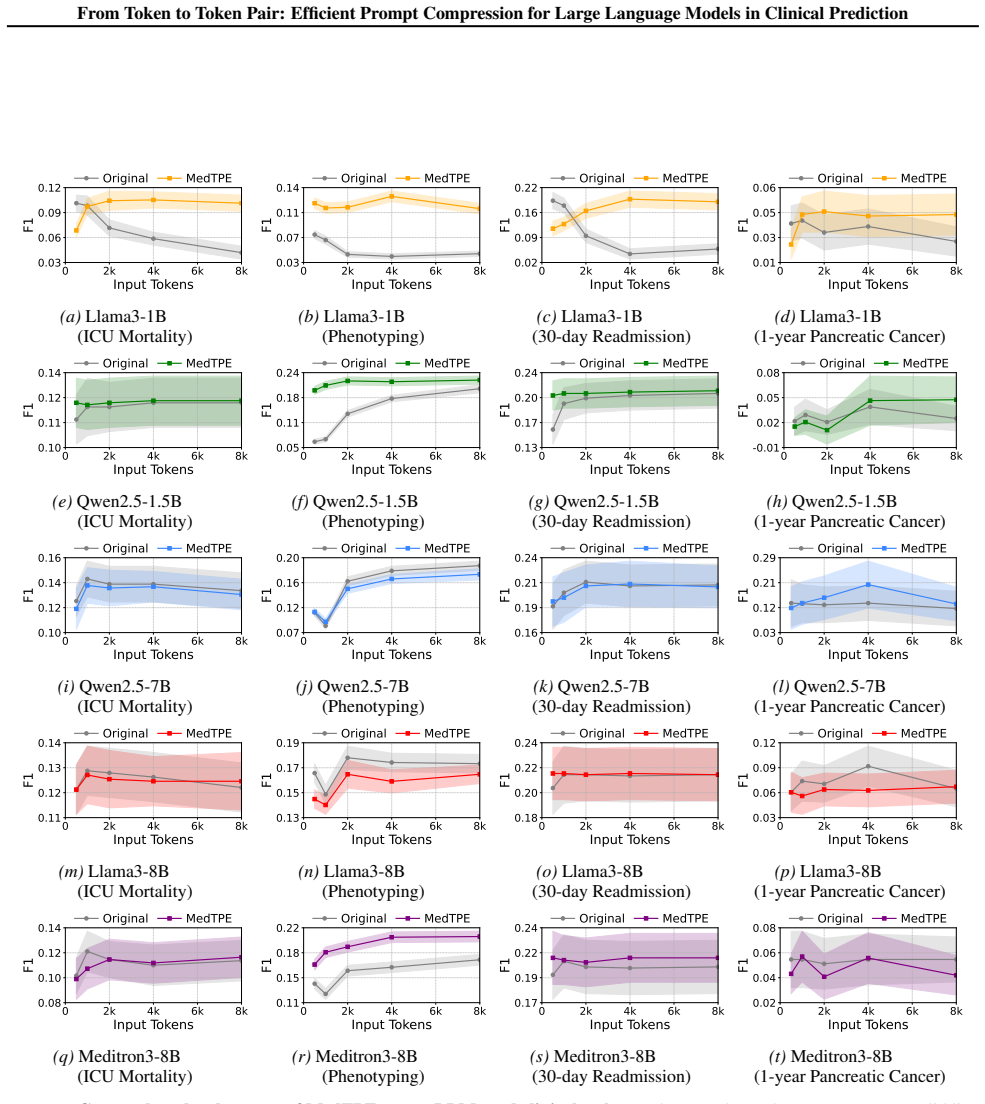
MedTPE extends standard tokenisation for EHR sequences by merging frequently co-occurring medical token pairs into composite tokens through a dependency-aware replacement strategy. This provides lossless compression while keeping the same computational complexity. Only the embeddings of the new tokens, which are 0.5-1.0% of the LLM parameters, are fine-tuned via self-supervised learning. On real-world datasets, it reduces input token length by up to 31% and inference latency by 34-63%, maintaining or improving predictive performance and output format compliance across multiple LLMs and four clinical prediction tasks.
What carries the argument
MedTPE, a layered extension of tokenisation that merges co-occurring medical token pairs into composite tokens via dependency-aware replacement to deliver lossless compression of EHR sequences.
If this is right
- Input token length reduced by up to 31 percent.
- Inference latency reduced by 34-63 percent.
- Predictive performance and output format compliance maintained or improved across LLMs and tasks.
- Robustness to varying input context lengths.
- Generalisation to scientific texts, financial texts, and non-English languages.
Where Pith is reading between the lines
- The pair-merging idea could extend to other repetitive long-sequence domains such as legal documents or software logs.
- Hospitals could lower compute costs for routine AI-based patient risk scoring without retraining full models.
- Similar lightweight compression might improve efficiency for any LLM handling structured or semi-structured data streams.
Load-bearing premise
Merging co-occurring token pairs via dependency-aware replacement preserves all clinically relevant information without introducing ambiguities or context loss in longitudinal EHR sequences.
What would settle it
Applying MedTPE to the same patient EHR sequences and observing that the LLM produces different clinical predictions or drops key medical details compared with the uncompressed versions.
Figures





read the original abstract
By processing electronic health records (EHRs) as natural language sequences, large language models (LLMs) have shown potential in clinical prediction tasks such as mortality prediction and phenotyping. However, longitudinal or highly frequent EHRs often yield excessively long token sequences that result in high computational costs and even reduced performance. Existing solutions either add modules for compression or remove less important tokens, which introduce additional inference latency or risk losing clinical information. To achieve lossless compression of token sequences without additional cost or loss of performance, we propose Medical Token-Pair Encoding (MedTPE), a layered method that extends standard tokenisation for EHR sequences. MedTPE merges frequently co-occurring medical token pairs into composite tokens, providing lossless compression while preserving the computational complexity through a dependency-aware replacement strategy. Only the embeddings of the newly introduced tokens of merely 0.5-1.0% of the LLM's parameters are fine-tuned via self-supervised learning. Experiments on real-world datasets for two clinical scenarios demonstrate that MedTPE reduces input token length by up to 31% and inference latency by 34-63%, while maintaining or even improving both predictive performance and output format compliance across multiple LLMs and four clinical prediction tasks. Furthermore, MedTPE demonstrates robustness across different input context lengths and generalisability to scientific and financial domains and different languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Medical Token-Pair Encoding (MedTPE), a layered extension to standard tokenization for EHR sequences that merges frequently co-occurring medical token pairs into composite tokens using a dependency-aware replacement strategy. Only the embeddings of the newly introduced tokens (0.5-1.0% of LLM parameters) are fine-tuned via self-supervised learning. Experiments on real-world datasets for two clinical scenarios report up to 31% reduction in input token length and 34-63% lower inference latency, while maintaining or improving predictive performance and output format compliance across multiple LLMs and four clinical prediction tasks; additional claims include robustness to context length and generalizability to scientific/financial domains and other languages.
Significance. If the lossless property and performance parity hold under the reported conditions, MedTPE would offer a practical, low-overhead route to scaling LLM-based clinical prediction on long longitudinal EHRs without auxiliary compression modules. The parameter-efficient adaptation and cross-domain claims, if substantiated, could influence prompt-compression research in resource-constrained NLP settings.
major comments (3)
- [MedTPE method description] The central lossless claim rests on the dependency-aware replacement strategy (described in the MedTPE method section). It is unclear whether the merging rule conditions on the full surrounding dependency graph or timing information in longitudinal sequences; repeated token pairs (e.g., lab-result + medication) can carry distinct clinical semantics depending on order or context, and the current description does not provide a formal criterion or pseudocode showing that distinct contexts are preserved after replacement.
- [Experiments] Experiments section: the abstract states positive outcomes on real datasets but supplies no information on the exact baselines, statistical significance tests, the precise frequency threshold or dependency criteria used for pair merging, or any direct verification (beyond end-task parity) that the composite tokens do not alter the input distribution seen by the frozen LLM weights. These omissions make it impossible to assess whether the reported 31% length reduction is achieved without hidden information loss.
- [Abstract and results] Abstract and results: the claim that performance is 'maintained or even improved' while only 0.5-1% of parameters are updated requires explicit comparison tables showing per-task metrics, confidence intervals, and ablation on the merging step itself; without these, the performance-parity argument remains under-supported for the load-bearing lossless guarantee.
minor comments (2)
- [Method] Clarify the exact self-supervised objective used for embedding fine-tuning and whether it operates on the original or already-merged sequences.
- [Discussion] Add a limitations paragraph addressing potential failure modes when the same token pair appears in semantically divergent clinical contexts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have revised the paper to address the concerns about method clarity, experimental details, and result reporting. Our point-by-point responses follow.
read point-by-point responses
-
Referee: The central lossless claim rests on the dependency-aware replacement strategy (described in the MedTPE method section). It is unclear whether the merging rule conditions on the full surrounding dependency graph or timing information in longitudinal sequences; repeated token pairs (e.g., lab-result + medication) can carry distinct clinical semantics depending on order or context, and the current description does not provide a formal criterion or pseudocode showing that distinct contexts are preserved after replacement.
Authors: We appreciate the referee highlighting this ambiguity in our description. The MedTPE dependency-aware strategy explicitly incorporates temporal ordering and local context from longitudinal EHR sequences to avoid merging pairs with distinct clinical meanings (e.g., by checking adjacency within patient timelines). To resolve the lack of formality, we have added a precise criterion and pseudocode to Section 3.2 of the revised manuscript, demonstrating how replacements preserve original sequence semantics and maintain the lossless property. revision: yes
-
Referee: Experiments section: the abstract states positive outcomes on real datasets but supplies no information on the exact baselines, statistical significance tests, the precise frequency threshold or dependency criteria used for pair merging, or any direct verification (beyond end-task parity) that the composite tokens do not alter the input distribution seen by the frozen LLM weights. These omissions make it impossible to assess whether the reported 31% length reduction is achieved without hidden information loss.
Authors: We agree these details are necessary for full evaluation. The revised Experiments section now specifies: baselines (standard tokenization plus two recent compression approaches), statistical tests (paired t-tests with reported p-values), frequency threshold (pairs exceeding 5% co-occurrence rate), and dependency criteria (temporal proximity within EHR events). We also added a direct verification comparing pre- and post-merge token distributions to frozen layers, confirming no hidden alteration and validating the 31% reduction as lossless. revision: yes
-
Referee: Abstract and results: the claim that performance is 'maintained or even improved' while only 0.5-1% of parameters are updated requires explicit comparison tables showing per-task metrics, confidence intervals, and ablation on the merging step itself; without these, the performance-parity argument remains under-supported for the load-bearing lossless guarantee.
Authors: We acknowledge the need for stronger quantitative support. The revised Results section includes new tables (Tables 2-4) with per-task metrics, means, and 95% confidence intervals across all models and tasks. We further added an ablation isolating the merging step, which shows performance parity or gains are attributable to MedTPE while preserving the 0.5-1% parameter update and lossless compression. revision: yes
Circularity Check
No circularity: claims rest on empirical measurements from held-out clinical data
full rationale
The paper defines MedTPE as a token-merging procedure followed by limited embedding fine-tuning, then reports token-length reduction, latency, and predictive performance as direct experimental outcomes on real-world EHR datasets across multiple LLMs and tasks. No equation or central claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the lossless property is asserted via observed parity on held-out data rather than definitional equivalence. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Merging frequently co-occurring medical token pairs preserves semantic and clinical meaning without loss
- domain assumption Dependency-aware replacement maintains sequence integrity and model compatibility
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MedTPE merges frequently co-occurring medical token pairs into composite tokens... dependency-aware replacement strategy... only the embeddings of the newly introduced tokens... are fine-tuned via self-supervised learning
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves lossless compression of EHR sequences... preserving the computational complexity through a dependency-aware replacement strategy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Arnrich, B., Choi, E., Fries, J. A., McDermott, M. B., Oh, J., Pollard, T., Shah, N., Steinberg, E., Wornow, M., and van de Water, R. Medical event data standard (meds): Facilitating machine learning for health. InICLR 2024 Workshop on Learning from Time Series For Health, pp. 03–08,
work page 2024
-
[2]
Bolton, E., Venigalla, A., Yasunaga, M., Hall, D., Xiong, B., Lee, T., Daneshjou, R., Frankle, J., Liang, P., Carbin, M., et al. Biomedlm: A 2.7 b parameter lan- guage model trained on biomedical text.arXiv preprint arXiv:2403.18421,
-
[3]
Measuring the robustness of nlp models to domain shifts
Calderon, N., Porat, N., Ben-David, E., Chapanin, A., Gekhman, Z., Oved, N., Shalumov, V ., and Reichart, R. Measuring the robustness of nlp models to domain shifts. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 126–154,
work page 2024
-
[4]
Chen, C., Yu, J., Chen, S., Liu, C., Wan, Z., Bitterman, D., Wang, F., and Shu, K. Clinicalbench: Can llms beat traditional ml models in clinical prediction?arXiv preprint arXiv:2411.06469, 2024a. Chen, L., Davis, J. Q., Hanin, B., Bailis, P., Stoica, I., Za- haria, M. A., and Zou, J. Y . Are more llm calls all you need? towards the scaling properties of ...
-
[5]
Bpe gets picky: Efficient vocabulary refinement during tokenizer training
Chizhov, P., Arnett, C., Korotkova, E., and Yamshchikov, I. Bpe gets picky: Efficient vocabulary refinement during tokenizer training. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 16587–16604,
work page 2024
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cui, H., Shen, Z., Zhang, J., Shao, H., Qin, L., Ho, J. C., and Yang, C. Llms-based few-shot disease predictions using ehr: A novel approach combining predictive agent reasoning and critical agent instruction. InAMIA Annual Symposium Proceedings, volume 2024, pp. 319,
work page 2024
-
[8]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Lossless token sequence compression via meta-tokens.arXiv preprint arXiv:2506.00307,
Harvill, J., Fan, Z., Wang, H., Sun, Y ., Ding, H., Huan, L., and Deoras, A. Lossless token sequence compression via meta-tokens.arXiv preprint arXiv:2506.00307,
-
[10]
N., Andres, S., Guellil, I., Zhang, H., Casey, A., Alex, B., Guthrie, B., and Wu, H
Hasan, A., Wu, J., Nguyen, Q. N., Andres, S., Guellil, I., Zhang, H., Casey, A., Alex, B., Guthrie, B., and Wu, H. Infusing clinical knowledge into tokenisers for language models.arXiv preprint arXiv:2406.14312,
-
[11]
Llm- lingua: Compressing prompts for accelerated inference of large language models
Jiang, H., Wu, Q., Lin, C.-Y ., Yang, Y ., and Qiu, L. Llm- lingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 13358–13376,
work page 2023
-
[12]
Efficient knowledge infusion via kg-llm alignment
Jiang, Z., Zhong, L., Sun, M., Xu, J., Sun, R., Cai, H., Luo, S., and Zhang, Z. Efficient knowledge infusion via kg-llm alignment. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 2986–2999,
work page 2024
- [13]
-
[14]
Kudo, T. and Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 66–71,
work page 2018
-
[15]
10 From Token to Token Pair: Efficient Prompt Compression for Large Language Models in Clinical Prediction Mesinovic, M., Molaei, S., Watkinson, P., and Zhu, T. Dy- nagraph: Interpretable multi-label prediction from ehrs via dynamic graph learning and contrastive augmentation. arXiv preprint arXiv:2503.22257,
-
[16]
Ectsum: A new benchmark dataset for bullet point summarization of long earnings call tran- scripts
Mukherjee, R., Bohra, A., Banerjee, A., Sharma, S., Hegde, M., Shaikh, A., Shrivastava, S., Dasgupta, K., Ganguly, N., Ghosh, S., et al. Ectsum: A new benchmark dataset for bullet point summarization of long earnings call tran- scripts. InProceedings of the 2022 Conference on Em- pirical Methods in Natural Language Processing, pp. 10893–10906,
work page 2022
-
[17]
B., Hoffer, E., and Reichart, R
Nakash, I., Calderon, N., David, E. B., Hoffer, E., and Reichart, R. Adaptivocab: Enhancing llm efficiency in focused domains through lightweight vocabulary adapta- tion.arXiv preprint arXiv:2503.19693,
-
[18]
Ni, M., Yang, Z., Li, L., Lin, C.-C., Lin, K., Zuo, W., and Wang, L. Point-rft: Improving multimodal reasoning with visually grounded reinforcement finetuning.arXiv preprint arXiv:2505.19702,
-
[19]
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression
Pan, Z., Wu, Q., Jiang, H., Xia, M., Luo, X., Zhang, J., Lin, Q., R ¨uhle, V ., Yang, Y ., Lin, C.-Y ., et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. InFindings of the Association for Computational Linguistics ACL 2024, pp. 963–981,
work page 2024
-
[20]
Generalizing over long tail con- cepts for medical term normalization
Portelli, B., Scaboro, S., Santus, E., Sedghamiz, H., Cher- soni, E., and Serra, G. Generalizing over long tail con- cepts for medical term normalization. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 8580–8591,
work page 2022
-
[21]
Llama-3- meditron: An open-weight suite of medical llms based on llama-3.1
Sallinen, A., Solergibert, A.-J., Zhang, M., Boy ´e, G., Dupont-Roc, M., Theimer-Lienhard, X., Boisson, E., Bernath, B., Hadhri, H., Tran, A., et al. Llama-3- meditron: An open-weight suite of medical llms based on llama-3.1. InWorkshop on Large Language Models and Generative AI for Health at AAAI 2025,
work page 2025
-
[22]
Song, X., Salcianu, A., Song, Y ., Dopson, D., and Zhou, D. Fast wordpiece tokenization. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 2089–2103,
work page 2021
-
[23]
Gemma 2: Improving Open Language Models at a Practical Size
Team, G., Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahri- ari, B., Ram ´e, A., et al. Gemma 2: Improving open language models at a practical size.arXiv preprint arXiv:2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Team, Q. Qwen2 technical report.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Zhang, S., Zhang, X., Wang, H., Guo, L., and Liu, S
doi: 10.52783/jisem.v10i37s.6506. Zhang, S., Zhang, X., Wang, H., Guo, L., and Liu, S. Multi- scale attentive interaction networks for chinese medical question answer selection.IEEE access, 6:74061–74071,
-
[27]
Zhu, M., Liu, Y ., Luo, Z., and Zhu, T. The taxonomies, train- ing, and applications of event stream modelling for elec- tronic health records.arXiv preprint arXiv:2603.14003,
-
[28]
A. Algorithm of Dependency-aware Replacement Algorithm 1Dependency-aware Replacement Input:Original vocabulary V, TPE candidates VTPE, budgetM Output:Optimised vocabularyV ⋆ Step 1: Formulate Insertion Set (I) foreachd j ∈ VTPE do Calculatescore(d j)via Eq. (9) end for I ←Top-M(V TPE,score) Step 2: Identify Dependencies (D) InitializeD ← ∅ foreachd j ∈ Id...
work page 2024
-
[29]
The padding token was set to be identical to the EOS token
Only the em- beddings of new tokens were trainable during fine-tuning, with all other embeddings and LLM layers frozen. The padding token was set to be identical to the EOS token. We did not perform hyperparameter tuning since the selected settings were constrained by hardware limits (e.g., batch size and sequence length), and no baselines required traini...
work page 2025
-
[30]
From the Llama3 family (Grattafiori et al., 2024), we selected the 1B and 8B variants
into the evaluation. From the Llama3 family (Grattafiori et al., 2024), we selected the 1B and 8B variants. We also included Meditron3-8B (Salli- nen et al., 2025), an open clinical LLM suite developed through continued pre-training of Llama3 in medical cor- pora for enhanced clinical decision support. All these fam- ilies use Byte Pair Encoding (BPE) tok...
work page 2024
-
[31]
Failure Mode A indicates reason- ing hallucination: the model preserves the required output format, but the CoT rationale becomes misaligned with the final prediction. Failure Mode B indicates a loss of instruc- tion adherence: the model continues generating clinical explanations but fails to produce the required JSON output. These behaviours are consiste...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.