Recognition: no theorem link
Learning Action Manifold with Multi-view Latent Priors for Robotic Manipulation
Pith reviewed 2026-05-13 05:20 UTC · model grok-4.3
The pith
Synthesizing multi-view latent images and learning actions on their valid manifold lets vision-language-action models overcome monocular depth ambiguity for better robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that combining synthesized multi-view latent priors with geometric alignment in a gated transformer and direct prediction on the action manifold allows VLA models to achieve superior success rates and robustness in manipulation tasks by resolving depth ambiguity and avoiding inefficient action regression.
What carries the argument
Action Manifold Learning (AML) that directly predicts on the valid action manifold, supported by Geometry-Guided Gated Transformer (G3T) using multi-view latent features from a diffusion model.
If this is right
- Manipulation tasks become more robust to occlusions and viewpoint changes.
- Action generation is more efficient by avoiding regression to unstructured noise or velocities.
- Performance improves on benchmarks like LIBERO and real-robot setups over state-of-the-art baselines.
- VLA models can better handle spatial perception challenges without additional hardware.
Where Pith is reading between the lines
- Replacing real multi-view cameras with synthesized latents could lower training costs for robotic systems.
- The method might apply to other domains like navigation where depth ambiguity arises from single views.
- Further work could test if the manifold approach generalizes to higher-dimensional action spaces.
Load-bearing premise
A pre-trained multi-view diffusion model can synthesize latent novel views that are accurate enough to resolve monocular depth ambiguity for the manipulation actions.
What would settle it
Running the experiments without the novel view synthesis component and observing no improvement or degradation in success rates would falsify the contribution of the multi-view priors.
Figures








read the original abstract
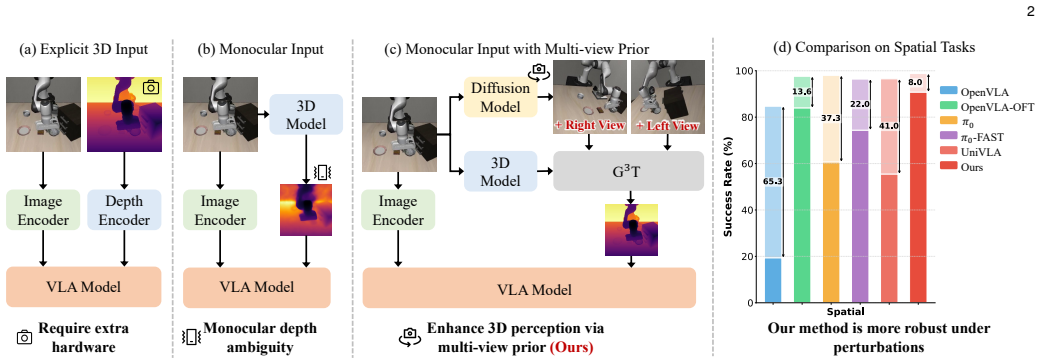
This paper tackles spatial perception and manipulation challenges in Vision-Language-Action (VLA) models. To address depth ambiguity from monocular input, we leverage a pre-trained multi-view diffusion model to synthesize latent novel views and propose a Geometry-Guided Gated Transformer (G3T) that aligns multi-view features under 3D geometric guidance while adaptively filtering occlusion noise. To improve action learning efficiency, we introduce Action Manifold Learning (AML), which directly predicts actions on the valid action manifold, bypassing inefficient regression of unstructured targets like noise or velocity. Experiments on LIBERO, RoboTwin 2.0, and real-robot tasks show our method achieves superior success rate and robustness over SOTA baselines. Project page: https://junjxiao.github.io/Multi-view-VLA.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes enhancements to Vision-Language-Action (VLA) models for robotic manipulation to address monocular depth ambiguity and inefficient action regression. It uses a pre-trained multi-view diffusion model to synthesize latent novel views, introduces a Geometry-Guided Gated Transformer (G3T) that aligns multi-view features under 3D geometric guidance while filtering occlusion noise, and presents Action Manifold Learning (AML) to predict actions directly on the valid manifold. Experiments on LIBERO, RoboTwin 2.0, and real-robot tasks report superior success rates and robustness over SOTA baselines.
Significance. If the results hold, the work offers a meaningful advance in VLA-based manipulation by improving spatial reasoning from monocular inputs and action efficiency via manifold constraints. The use of pre-trained diffusion priors for latent view synthesis and the AML formulation are strengths that could support better generalization; the coherent technical account in the methods section and internally consistent benchmark results provide a solid foundation for the headline claims.
minor comments (3)
- The description of how the pre-trained multi-view diffusion model is adapted for latent novel view synthesis (in the methods) would benefit from an explicit statement of any fine-tuning or conditioning steps used, to clarify reproducibility.
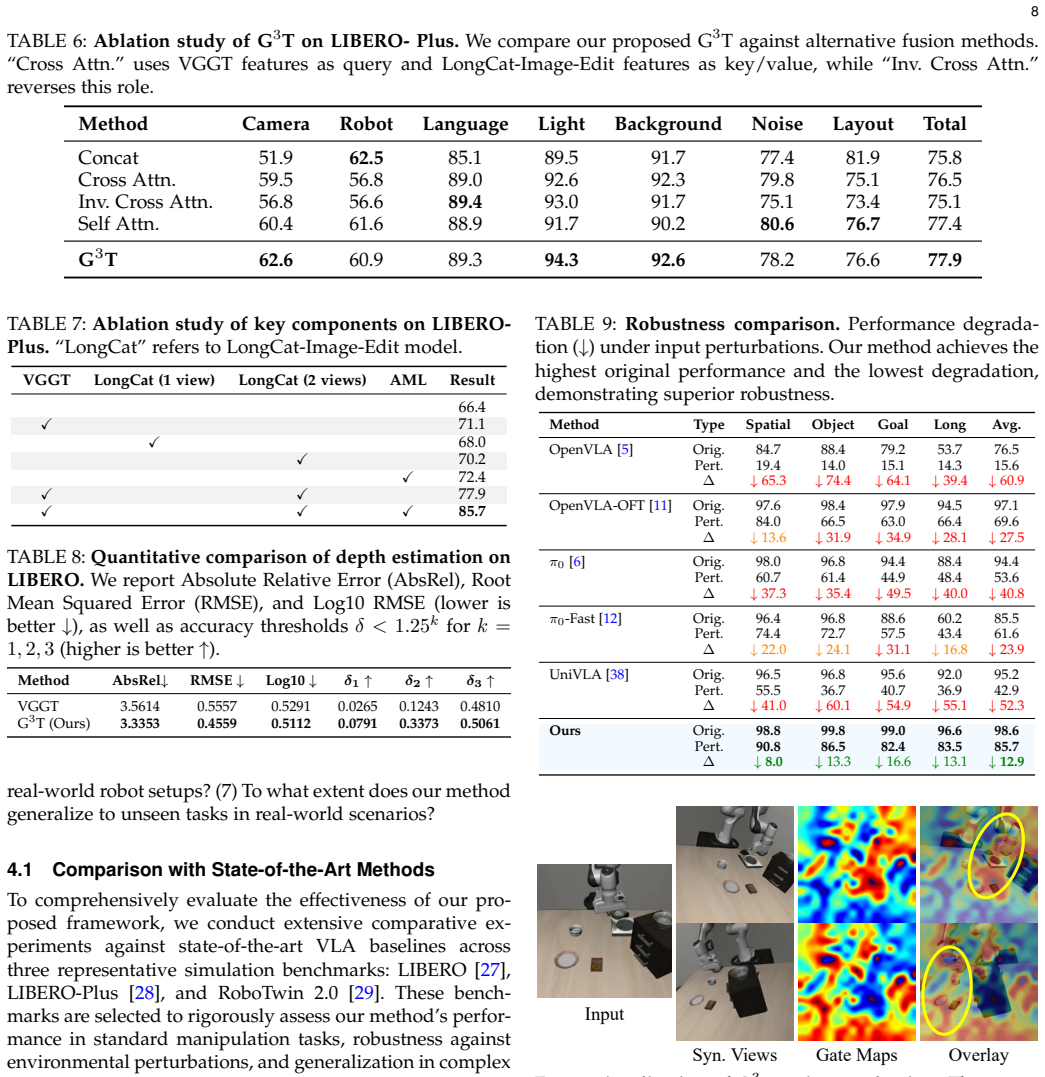
- Ablation results on the contribution of G3T versus AML would be clearer if presented with consistent metrics (e.g., success rate deltas with standard deviations) across all tables.
- The real-robot experiments section could include more detail on the exact hardware setup, camera calibration, and how latent views are rendered in the physical loop to aid replication.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. The referee correctly highlights the value of multi-view diffusion priors for resolving depth ambiguity and the AML formulation for more efficient action prediction in VLA models.
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain introduces a pre-trained multi-view diffusion model for latent novel views, a Geometry-Guided Gated Transformer (G3T) for feature alignment, and Action Manifold Learning (AML) for direct action prediction on the valid manifold. These components are presented as technical proposals whose validity is assessed via external benchmarks (LIBERO, RoboTwin 2.0, real-robot tasks) against SOTA baselines. No self-definitional equations, fitted inputs renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the described pipeline; the performance claims rest on independent experimental comparisons rather than internal reduction to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P . Luc, A. Miech, I. Barr, Y. Hasson, K. Lenc, A. Mensch, K. Millican, M. Reynoldset al., “Flamingo: a visual language model for few-shot learning,” inAdv. Neural Inform. Process. Syst., 2022. 1, 2
work page 2022
-
[2]
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” in Adv. Neural Inform. Process. Syst., 2023. 1, 2 13
work page 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P . Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond,” arXiv:2308.12966, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P . Xu, T. Xiao, F. Xia, J. Wu, P . Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConf. Rob. Learn., 2023, pp. 2165–2183. 1, 2
work page 2023
-
[5]
OpenVLA: An Open-Source Vision-Language-Action Model
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P . Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P . Liang, and C. Finn, “Openvla: An open-source vision-language-action model,”arXiv:2406.09246, 2024. 1, 2, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fu- sai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,” arXiv:2410.24164, 2024...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
World-Env: Leveraging World Model as a Virtual Environment for VLA Post-Training
J. Xiao, Y. Yang, X. Chang, R. Chen, F. Xiong, M. Xu, W.-S. Zheng, and Q. Zhang, “World-env: Leveraging world model as a virtual environment for vla post-training,”arxiv:2509.24948, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
S. Zeng, D. Qi, X. Chang, F. Xiong, S. Xie, X. Wu, S. Liang, M. Xu, and X. Wei, “Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation,” inInt. Conf. Learn. Represent., 2026. 1
work page 2026
-
[9]
M. Wei, C. Wan, X. Yu, T. Wang, Y. Yang, X. Mao, C. Zhu, W. Cai, H. Wang, Y. Chenet al., “Streamvln: Streaming vision-and-language navigation via slowfast context modeling,” arXiv:2507.05240, 2025. 1
-
[10]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y. Tan, L. Y. Chen, P . Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” in Proceedings of Robotics: Science and Systems, 2024. 1, 2, 3
work page 2024
-
[11]
Fine-Tuning Vision-Language- Action Models: Optimizing Speed and Success,
M. J. Kim, C. Finn, and P . Liang, “Fine-Tuning Vision-Language- Action Models: Optimizing Speed and Success,” inProceedings of Robotics: Science and Systems, 2025. 1, 2, 6, 8, 9, 12
work page 2025
-
[12]
FAST: Efficient Action Tok- enization for Vision-Language-Action Models,
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “FAST: Efficient Action Tok- enization for Vision-Language-Action Models,” inProceedings of Robotics: Science and Systems, 2025. 1, 6, 8
work page 2025
-
[13]
Pointvla: Injecting the 3d world into vision-language-action models,
C. Li, J. Wen, Y. Peng, Y. Peng, and Y. Zhu, “Pointvla: Injecting the 3d world into vision-language-action models,”IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2506–2513, 2026. 1, 3
work page 2026
-
[14]
RVT- 2: Learning Precise Manipulation from Few Demonstrations,
A. Goyal, V . Blukis, J. Xu, Y. Guo, Y.-W. Chao, and D. Fox, “RVT- 2: Learning Precise Manipulation from Few Demonstrations,” in Proceedings of Robotics: Science and Systems, 2024. 1, 3
work page 2024
-
[15]
T. Lin, G. Li, Y. Zhong, Y. Zou, Y. Du, J. Liu, E. Gu, and B. Zhao, “Evo-0: Vision-language-action model with implicit spatial under- standing,”arXiv:2507.00416, 2025. 1, 3
-
[16]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model,
F. Li, W. Song, H. Zhao, J. Wang, P . Ding, D. Wang, L. Zeng, and H. Li, “Spatial forcing: Implicit spatial representation alignment for vision-language-action model,” inInt. Conf. Learn. Represent.,
-
[17]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” in IEEE Conf. Comput. Vis. Pattern Recog., 2025. 1, 3, 4
work page 2025
-
[18]
Depth anything 3: Recovering the visual space from any views,
H. Lin, S. Chen, J. H. Liew, D. Y. Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,” inInt. Conf. Learn. Represent., 2026. 1
work page 2026
-
[19]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y. Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”Int. J. Rob. Res., vol. 44, no. 10-11, pp. 1684–1704, 2025. 1, 3, 6
work page 2025
-
[20]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y. Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foun- dation model for generalist humanoid robots,”arXiv:2503.14734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Q. Li, Y. Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y. Deng, S. Xu, Y. Zhanget al., “Cogact: A foundational vision- language-action model for synergizing cognition and action in robotic manipulation,”arXiv:2411.19650, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,” inAdv. Neural Inform. Process. Syst., 2020. 1, 3
work page 2020
-
[23]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInt. Conf. Learn. Represent., 2021. 1, 3
work page 2021
-
[24]
Flow matching for generative modeling,
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inInt. Conf. Learn. Represent.,
-
[25]
Flow straight and fast: Learning to generate and transfer data with rectified flow,
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,” inInt. Conf. Learn. Represent., 2023. 1, 3
work page 2023
-
[26]
Mean flows for one-step generative modeling,
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He, “Mean flows for one-step generative modeling,” inAdv. Neural Inform. Process. Syst., 2025. 1
work page 2025
-
[27]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y. Zhu, C. Gao, Y. Feng, Q. Liu, Y. Zhu, and P . Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” inAdv. Neural Inform. Process. Syst., 2023. 2, 8
work page 2023
-
[28]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P . Qian, L. Ji, X. He, S. Zhang, Z. Feiet al., “Libero-plus: In-depth robustness analysis of vision- language-action models,”arXiv:2510.13626, 2025. 2, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y. Liu, Z. Li, Q. Liang, X. Lin, Y. Ge, Z. Guet al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv:2506.18088, 2025. 2, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation,” inProc. Int. Conf. Mach. Learn., 2022. 2
work page 2022
-
[31]
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” inProc. Int. Conf. Mach. Learn., 2023. 2
work page 2023
-
[32]
Instructblip: Towards general-purpose vision- language models with instruction tuning,
W. Dai, J. Li, D. Li, A. Tiong, J. Zhao, W. Wang, B. Li, P . N. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision- language models with instruction tuning,” inAdv. Neural Inform. Process. Syst., 2023. 2
work page 2023
-
[33]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024. 2
work page 2024
-
[34]
Prismatic VLMs: Investigating the design space of visually-conditioned language models,
S. Karamcheti, S. Nair, A. Balakrishna, P . Liang, T. Kollar, and D. Sadigh, “Prismatic VLMs: Investigating the design space of visually-conditioned language models,” inProc. Int. Conf. Mach. Learn., 2024. 2
work page 2024
-
[35]
X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y. Feng, Y. Zheng, J. Zou, Y. Chen, J. Zenget al., “X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,” inInt. Conf. Learn. Represent., 2026. 2, 6
work page 2026
-
[36]
St4vla: Spatially guided training for vision-language-action models,
J. Ye, F. Wang, N. Gao, J. Yu, Y. Zhu, B. Wang, J. Zhang, W. Jin, Y. Fu, F. Zheng, Y. Chen, and J. Pang, “St4vla: Spatially guided training for vision-language-action models,” inInt. Conf. Learn. Represent., 2026. 2
work page 2026
-
[37]
Cot-vla: Visual chain-of-thought reasoning for vision- language-action models,
Q. Zhao, Y. Lu, M. J. Kim, Z. Fu, Z. Zhang, Y. Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, T.-Y. Lin, G. Wetzstein, M.-Y. Liu, and D. Xiang, “Cot-vla: Visual chain-of-thought reasoning for vision- language-action models,” inIEEE Conf. Comput. Vis. Pattern Recog.,
-
[38]
Univla: Learning to act anywhere with task-centric latent actions,
Q. Bu, Y. Yang, J. Cai, S. Gao, G. Ren, M. Yao, P . Luo, and H. Li, “Univla: Learning to act anywhere with task-centric latent actions,” inProceedings of Robotics: Science and Systems, 2025. 2, 6, 8
work page 2025
-
[39]
WorldVLA: Towards Autoregressive Action World Model
J. Cen, C. Yu, H. Yuan, Y. Jiang, S. Huang, J. Guo, X. Li, Y. Song, H. Luo, F. Wanget al., “Worldvla: Towards autoregressive action world model,”arXiv:2506.21539, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Reconvla: Reconstructive vision- language-action model as effective robot perceiver,
W. Song, Z. Zhou, H. Zhao, J. Chen, P . Ding, H. Yan, Y. Huang, F. Tang, D. Wang, and H. Li, “Reconvla: Reconstructive vision- language-action model as effective robot perceiver,” inAAAI, 2026. 2
work page 2026
-
[41]
Interactive post-training for vision-language- action models, 2025
S. Tan, K. Dou, Y. Zhao, and P . Kr ¨ahenb ¨uhl, “Interactive post- training for vision-language-action models,”arxiv:2505.17016,
-
[42]
Scalable deep reinforcement learning for vision-based robotic manipulation,
D. Kalashnikov, A. Irpan, P . Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V . Vanhoucke, and S. Levine, “Scalable deep reinforcement learning for vision-based robotic manipulation,” inConf. Rob. Learn., 2018. 2
work page 2018
-
[43]
Pre-Training for Robots: Offline RL Enables Learn- ing New Tasks in a Handful of Trials,
A. Kumar, A. Singh, F. D. Ebert, M. Nakamoto, Y. Yang, C. Finn, and S. Levine, “Pre-Training for Robots: Offline RL Enables Learn- ing New Tasks in a Handful of Trials,” inProceedings of Robotics: Science and Systems, 2023. 2
work page 2023
-
[44]
Robotic Offline RL from Internet Videos via Value-Function Pre-Training
C. Bhateja, D. Guo, D. Ghosh, A. Singh, M. Tomar, Q. Vuong, Y. Chebotar, S. Levine, and A. Kumar, “Robotic offline rl from internet videos via value-function pre-training,”arxiv:2309.13041,
-
[45]
Steering your generalists: Improving robotic foundation models via value guidance,
M. Nakamoto, O. Mees, A. Kumar, and S. Levine, “Steering your generalists: Improving robotic foundation models via value guidance,” inConf. Rob. Learn., 2024. 2 14
work page 2024
-
[46]
RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning,
C. Xu, Q. Li, J. Luo, and S. Levine, “RLDG: Robotic Generalist Policy Distillation via Reinforcement Learning,” inProceedings of Robotics: Science and Systems, 2025. 2
work page 2025
-
[47]
Residual reinforcement learning for robot control,
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learning for robot control,” inIEEE Int. Conf. Rob. Auto., 2019. 2
work page 2019
-
[48]
arXiv preprint arXiv:2412.06685 , year=
M. S. Mark, T. Gao, G. G. Sampaio, M. K. Srirama, A. Sharma, C. Finn, and A. Kumar, “Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone,”arxiv:2412.06685, 2024. 2
-
[49]
G. Lu, C. Zhang, H. Jiang, Y. Zhou, Z. Gao, Y. Tang, and Z. Wang, “Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,”arxiv:2505.18719, 2025. 2
-
[50]
ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy,
Y. Chen, S. Tian, S. Liu, Y. Zhou, H. Li, and D. Zhao, “ConRFT: A Reinforced Fine-tuning Method for VLA Models via Consistency Policy,” inProceedings of Robotics: Science and Systems, 2025. 2
work page 2025
-
[51]
Simplevla-rl: Scaling vla training via reinforcement learning,
H. Li, Y. Zuo, J. Yu, Y. Zhang, Z. Yang, K. Zhang, X. Zhu, Y. Zhang, T. Chen, G. Cuiet al., “Simplevla-rl: Scaling vla training via reinforcement learning,” inInt. Conf. Learn. Represent., 2026. 2
work page 2026
-
[52]
Dream to control: Learning behaviors by latent imagination,
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to control: Learning behaviors by latent imagination,” inInt. Conf. Learn. Represent., 2020. 2
work page 2020
-
[53]
Mastering atari with discrete world models,
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba, “Mastering atari with discrete world models,” inInt. Conf. Learn. Represent., 2021. 2
work page 2021
-
[54]
Mastering diverse control tasks through world models,
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap, “Mastering diverse control tasks through world models,”Nature, pp. 1–7, 2025. 2
work page 2025
-
[55]
Td-mpc2: Scalable, robust world models for continuous control,
N. Hansen, H. Su, and X. Wang, “Td-mpc2: Scalable, robust world models for continuous control,” inInt. Conf. Learn. Represent., 2024. 2
work page 2024
-
[56]
Wmpo: World model-based policy optimization for vision-language-action models,
Z. Fangqi, Y. Zhengyang, H. Zicong, S. Quanxin, M. Xiao, and G. Song, “Wmpo: World model-based policy optimization for vision-language-action models,” inInt. Conf. Learn. Represent.,
-
[57]
Srpo: Self-referential policy optimization for vision-language-action models,
S. Fei, S. Wang, L. Ji, A. Li, S. Zhang, L. Liu, J. Hou, J. Gong, X. Zhao, and X. Qiu, “Srpo: Self-referential policy optimization for vision-language-action models,”arXiv:2511.15605, 2025. 2
-
[58]
H. Li, P . Ding, R. Suo, Y. Wang, Z. Ge, D. Zang, K. Yu, M. Sun, H. Zhang, D. Wanget al., “Vla-rft: Vision-language-action rein- forcement fine-tuning with verified rewards in world simulators,” arXiv:2510.00406, 2025. 2
-
[59]
Z. Jiang, S. Zhou, Y. Jiang, Z. Huang, M. Wei, Y. Chen, T. Zhou, Z. Guo, H. Lin, Q. Zhang, Y. Wang, H. Li, C. Yu, and D. Zhao, “Wovr: World models as reliable simulators for post-training vla policies with rl,”arXiv:2602.13977, 2026. 2
-
[60]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y. Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inProceedings of Robotics: Science and Systems, 2024. 3
work page 2024
-
[61]
Vihe: Virtual in-hand eye transformer for 3d robotic manipulation,
W. Wang, Y. Lei, S. Jin, G. D. Hager, and L. Zhang, “Vihe: Virtual in-hand eye transformer for 3d robotic manipulation,” inIEEE/RSJ Int. Conf. Intell. Rob. Syst., 2024. 3
work page 2024
-
[62]
V . Bhat, Y.-H. Lan, P . Krishnamurthy, R. Karri, and F. Khorrami, “3d cavla: Leveraging depth and 3d context to generalize vision language action models for unseen tasks,”arXiv:2505.05800, 2025. 3, 6
-
[63]
T. Yuan, Y. Liu, C. Lu, Z. Chen, T. Jiang, and H. Zhao, “Depthvla: Enhancing vision-language-action models with depth-aware spa- tial reasoning,”arXiv:2510.13375, 2025. 3
-
[64]
Geovla: Em- powering 3d representations in vision-language-action models,
L. Sun, B. Xie, Y. Liu, H. Shi, T. Wang, and J. Cao, “Geovla: Em- powering 3d representations in vision-language-action models,” arXiv:2508.09071, 2025. 3, 6
-
[65]
Spatialactor: Exploring disentangled spatial represen- tations for robust robotic manipulation,
H. Shi, B. Xie, Y. Liu, Y. Yue, T. Wang, H. Fan, X. Zhang, and G. Huang, “Spatialactor: Exploring disentangled spatial represen- tations for robust robotic manipulation,” inAAAI, 2026. 3
work page 2026
-
[66]
Voxact-b: Voxel- based acting and stabilizing policy for bimanual manipulation,
I.-C. A. Liu, S. He, D. Seita, and G. S. Sukhatme, “Voxact-b: Voxel- based acting and stabilizing policy for bimanual manipulation,” inConf. Rob. Learn., 2025. 3
work page 2025
-
[67]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
R. Q. Charles, H. Su, M. Kaichun, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” in IEEE Conf. Comput. Vis. Pattern Recog., 2017. 3
work page 2017
-
[68]
Geoaware- vla: Implicit geometry aware vision-language-action model,
A. Abouzeid, M. Mansour, Z. Sun, and D. Song, “Geoaware- vla: Implicit geometry aware vision-language-action model,” arXiv:2509.14117, 2025. 3
-
[69]
B. Yu, S. Lian, X. Lin, Z. Shen, Y. Wei, H. Liu, C. Wu, H. Yuan, B. Wang, C. Huang, and K. Chen, “3d-mix for vla: A plug-and-play module for integrating vggt-based 3d information into vision- language-action models,”arXiv:2603.24393, 2026. 3
-
[70]
P . Li, Y. Chen, H. Wu, X. Ma, X. Wu, Y. Huang, L. Wang, T. Kong, and T. Tan, “Bridgevla: Input-output alignment for efficient 3d ma- nipulation learning with vision-language models,” inAdv. Neural Inform. Process. Syst., 2025. 3
work page 2025
-
[71]
Learning to see and act: Task-aware virtual view exploration for robotic manipulation,
Y. Bai, Z. Wang, Y. Liu, K. Luo, Y. Wen, M. Dai, W. Chen, Z. Chen, L. Liu, G. Li, and L. Lin, “Learning to see and act: Task-aware virtual view exploration for robotic manipulation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2026. 3
work page 2026
-
[72]
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y. Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y. Sun, J. Tang, J. Tu, J. Wan, P . Wang, P . Wang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Longcat-image technical report
M. L. Team, H. Ma, H. Tan, J. Huang, J. Wu, J.-Y. He, L. Gao, S. Xiao, X. Wei, X. Ma, X. Cai, Y. Guan, and J. Hu, “Longcat-image technical report,”arXiv:2512.07584, 2025. 4
-
[74]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdv. Neural Inform. Process. Syst., 2017. 5
work page 2017
-
[75]
C.-Y. Hung, Q. Sun, P . Hong, A. Zadeh, C. Li, U. Tan, N. Majumder, S. Poriaet al., “Nora: A small open-sourced generalist vision language action model for embodied tasks,”arXiv:2504.19854,
-
[76]
Mergevla: Cross-skill model merging toward a generalist vision- language-action agent,
Y. Fu, Z. Zhang, Y. Zhang, Z. Wang, Z. Huang, and Y. Luo, “Mergevla: Cross-skill model merging toward a generalist vision- language-action agent,” inIEEE Conf. Comput. Vis. Pattern Recog.,
-
[77]
Unifolm-vla-0: A vision-language-action (vla) frame- work under unifolm family,
Unitree, “Unifolm-vla-0: A vision-language-action (vla) frame- work under unifolm family,” 2026. 6
work page 2026
-
[78]
Spatialvla: Exploring spatial representa- tions for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y. Yao, X. Ye, Y. Ding, Z. Wang, J. Gu, B. Zhao, D. Wanget al., “Spatialvla: Exploring spatial representa- tions for visual-language-action model,” inProceedings of Robotics: Science and Systems, 2025. 6
work page 2025
-
[79]
Q. Lv, W. Kong, H. Li, J. Zeng, Z. Qiu, D. Qu, H. Song, Q. Chen, X. Deng, and J. Pang, “F1: A vision-language-action model bridg- ing understanding and generation to actions,”arXiv:2509.06951,
-
[80]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
I.-M. Contributors, “Internvla-m1: A spatially guided vision- language-action framework for generalist robot policy,” arXiv:2510.13778, 2025. 6
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.