Recognition: 2 theorem links
· Lean TheoremQwen-Scope: Turning Sparse Features into Development Tools for Large Language Models
Pith reviewed 2026-05-13 05:31 UTC · model grok-4.3
The pith
Sparse autoencoders on Qwen models function as reusable interfaces for steering outputs, analyzing benchmarks, synthesizing data, and guiding fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAEs serve not only as post-hoc analysis tools but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models, demonstrated by inference-time steering via feature directions, evaluation analysis through activated features, data-centric tasks including toxicity classification and safety synthesis, and incorporation of SAE signals into supervised fine-tuning and reinforcement learning to address code-switching and repetition.
What carries the argument
The Qwen-Scope collection of 14 groups of sparse autoencoders across seven Qwen3 and Qwen3.5 variants that decompose activations into sparse features usable for development operations.
If this is right
- Feature directions enable direct control over language, concepts, and preferences during inference without any weight updates.
- Activated features supply a representation-level proxy for measuring benchmark redundancy and capability coverage.
- The same features support practical data tasks such as multilingual toxicity detection and safety-oriented data synthesis.
- SAE-derived signals can be added to supervised fine-tuning and reinforcement learning objectives to reduce repetition and code-switching.
Where Pith is reading between the lines
- If feature stability holds across releases, developers could maintain persistent control interfaces rather than re-deriving them for each model update.
- The approach opens the possibility of automated auditing pipelines that flag capability gaps directly from feature activation patterns.
- Wider adoption might shift emphasis from full retraining toward targeted edits at the representation level when undesirable behaviors appear.
Load-bearing premise
The learned SAE features remain stable, interpretable, and causally effective enough to support reliable steering and training signals across uses without introducing new unintended behaviors.
What would settle it
A controlled test in which activating an SAE feature direction intended to reduce repetition instead increases repetition rate or produces new inconsistencies on held-out prompts.
Figures



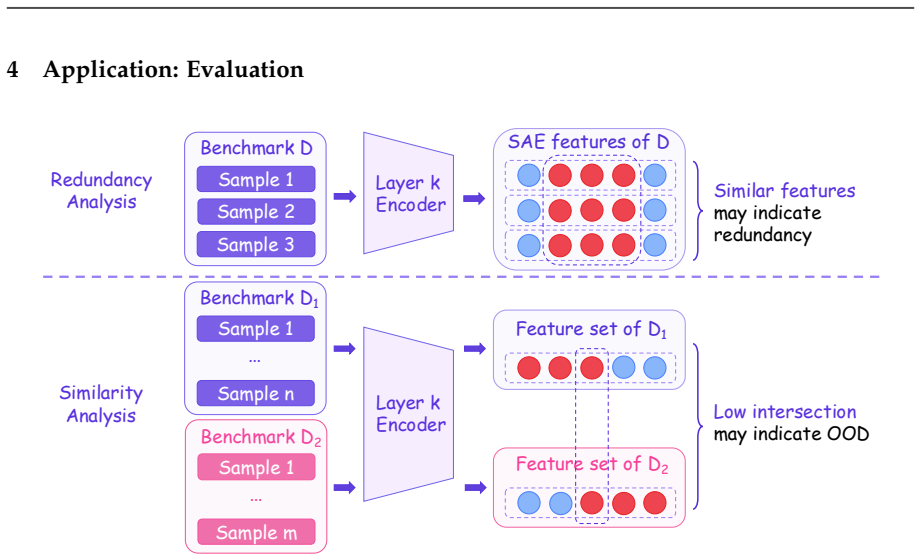



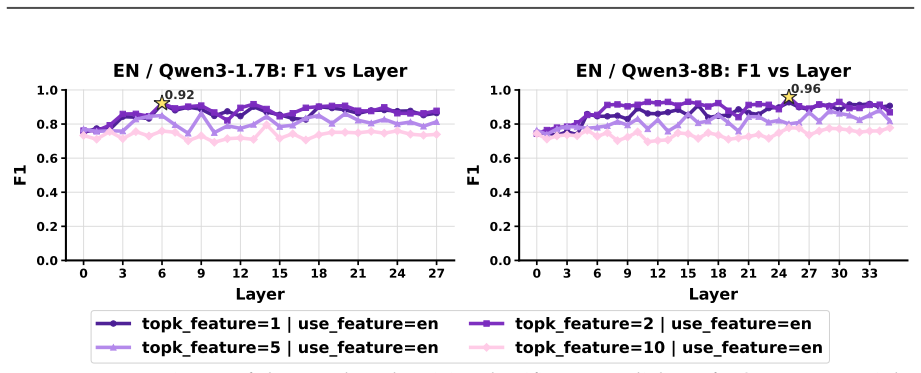













read the original abstract
Large language models have achieved remarkable capabilities across diverse tasks, yet their internal decision-making processes remain largely opaque, limiting our ability to inspect, control, and systematically improve them. This opacity motivates a growing body of research in mechanistic interpretability, with sparse autoencoders (SAEs) emerging as one of the most promising tools for decomposing model activations into sparse, interpretable feature representations. We introduce Qwen-Scope, an open-source suite of SAEs built on the Qwen model family, comprising 14 groups of SAEs across 7 model variants from the Qwen3 and Qwen3.5 series, covering both dense and mixture-of-expert architectures. Built on top of these SAEs, we show that SAEs can go beyond post-hoc analysis to serve as practical interfaces for model development along four directions: (i) inference-time steering, where SAE feature directions control language, concepts, and preferences without modifying model weights; (ii) evaluation analysis, where activated SAE features provide a representation-level proxy for benchmark redundancy and capability coverage; (iii) data-centric workflows, where SAE features support multilingual toxicity classification and safety-oriented data synthesis; and (iv) post-training optimization, where SAE-derived signals are incorporated into supervised fine-tuning and reinforcement learning objectives to mitigate undesirable behaviors such as code-switching and repetition. Together, these results demonstrate that SAEs can serve not only as post-hoc analysis tools, but also as reusable representation-level interfaces for diagnosing, controlling, evaluating, and improving large language models. By open-sourcing Qwen-Scope, we aim to support mechanistic research and accelerate practical workflows that connect model internals to downstream behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen-Scope, an open-source suite of 14 groups of sparse autoencoders (SAEs) trained on 7 variants from the Qwen3 and Qwen3.5 model families (dense and MoE). It claims that these SAEs can function as reusable representation-level interfaces for four practical model development tasks: (i) inference-time steering of language, concepts, and preferences (§4.1), (ii) representation-level analysis of benchmark redundancy and capability coverage (§4.2), (iii) multilingual toxicity classification and safety-oriented data synthesis (§4.3), and (iv) incorporation of SAE-derived signals into SFT and RL objectives to reduce code-switching and repetition (§4.4). The central thesis is that SAEs extend beyond post-hoc interpretability to support diagnosing, controlling, evaluating, and improving LLMs.
Significance. If the empirical demonstrations hold under systematic validation, the work would be significant for mechanistic interpretability and LLM engineering. It provides the first large-scale open SAE release for the Qwen family and illustrates concrete workflows that connect sparse features directly to downstream behaviors such as steering and post-training. The open-sourcing of the SAE suite itself is a clear strength that lowers barriers for reproducible research on representation-level interfaces.
major comments (3)
- [§4.1] §4.1 (steering): The demonstrations of feature-based control do not report quantitative metrics for cross-prompt stability of activated SAE features or side-effect rates (e.g., capability degradation on held-out tasks or perplexity increase) relative to non-SAE baselines. Without these, it remains unclear whether the steering effects are robust enough to support the claim of reusable interfaces.
- [§4.4] §4.4 (post-training): The incorporation of SAE-derived signals into SFT and RL objectives lacks ablation studies that isolate the contribution of the SAE features from generic regularization or data-filtering effects. This is load-bearing for the claim that SAE signals specifically mitigate undesirable behaviors such as code-switching.
- [§4.2–4.3] §4.2–4.3: The evaluation and data-workflow sections provide no systematic sensitivity analysis on feature selection (e.g., top-k vs. thresholded activation) or cross-model stability of the same SAE features, which is required to substantiate that the SAEs function as reliable, reusable interfaces rather than case-by-case tools.
minor comments (2)
- [Abstract / §3] The abstract states that Qwen-Scope comprises 14 groups of SAEs but does not specify the exact layer indices, dictionary sizes, or training hyperparameters; these details should be added to the main text or a dedicated appendix for reproducibility.
- [Throughout] Figure captions and section headings occasionally use inconsistent terminology (e.g., “SAE feature directions” vs. “activated features”); standardizing this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback, which helps strengthen the empirical grounding of Qwen-Scope as reusable representation-level interfaces. We address each major comment below and will incorporate the suggested analyses into the revised manuscript.
read point-by-point responses
-
Referee: [§4.1] §4.1 (steering): The demonstrations of feature-based control do not report quantitative metrics for cross-prompt stability of activated SAE features or side-effect rates (e.g., capability degradation on held-out tasks or perplexity increase) relative to non-SAE baselines. Without these, it remains unclear whether the steering effects are robust enough to support the claim of reusable interfaces.
Authors: We agree that quantitative metrics for robustness are necessary to support the reusable-interface claim. In the revised manuscript we will add cross-prompt stability measurements (feature activation consistency across prompt paraphrases and domains) and side-effect evaluations, including perplexity shifts on held-out corpora and performance changes on standard benchmarks (e.g., subsets of MMLU and GSM8K) relative to non-SAE baselines such as direct activation steering and prompt-based interventions. revision: yes
-
Referee: [§4.4] §4.4 (post-training): The incorporation of SAE-derived signals into SFT and RL objectives lacks ablation studies that isolate the contribution of the SAE features from generic regularization or data-filtering effects. This is load-bearing for the claim that SAE signals specifically mitigate undesirable behaviors such as code-switching.
Authors: We concur that isolating the SAE-specific contribution is essential. The revised version will include ablation experiments that compare the full SAE-signal objective against (i) generic regularization baselines (KL penalty, entropy regularization) and (ii) data-filtering approaches without SAE features. These ablations will quantify the incremental benefit of the SAE-derived signals on code-switching and repetition metrics. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3: The evaluation and data-workflow sections provide no systematic sensitivity analysis on feature selection (e.g., top-k vs. thresholded activation) or cross-model stability of the same SAE features, which is required to substantiate that the SAEs function as reliable, reusable interfaces rather than case-by-case tools.
Authors: We will add systematic sensitivity analyses in the revised sections 4.2 and 4.3, comparing top-k, thresholded, and hybrid feature-selection methods on benchmark redundancy and toxicity-classification tasks. For cross-model stability we will report quantitative overlap and transfer metrics across the Qwen3/Qwen3.5 variants; because SAEs are trained per model, full feature identity transfer is limited, but we will document the degree of stability that exists within the model family to support the reusability argument. revision: yes
Circularity Check
No circularity: empirical applications of standard SAEs with no self-referential derivations
full rationale
The paper introduces an open-source collection of SAEs trained on Qwen models and demonstrates four empirical use cases (steering, evaluation, data workflows, post-training) via experiments. No equations, derivations, or first-principles results are presented that reduce to fitted parameters or inputs defined by the same data. The central claim that SAEs can function as reusable interfaces rests on new empirical demonstrations rather than any self-definition, fitted-input prediction, or load-bearing self-citation chain. Standard SAE training procedures are invoked without redefinition or circular justification, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders trained on model activations yield interpretable and controllable features
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SAEs decompose model activations into sparse, interpretable feature representations... inference-time steering... SAE feature directions control language, concepts, and preferences
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
feature coverage as a proxy for benchmark redundancy... overlap(D1,D2) = |F(D1) ∩ F(D2)| / |F(D1)|
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Llama Scope: Extracting Millions of Features from Llama-3.1-8B with Sparse Autoencoders , author=. 2024 , eprint=
work page 2024
-
[2]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kramar, Janos and Dragan, Anca and Shah, Rohin and Nanda, Neel. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP....
-
[3]
Gemma Scope 2: helping the AI safety community deepen understanding of complex language model behavior , author=
-
[4]
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
work page 2023
-
[5]
Working Notes of CLEF 2024 - Conference and Labs of the Evaluation Forum , editor=
Overview of the Multilingual Text Detoxification Task at PAN 2024 , author=. Working Notes of CLEF 2024 - Conference and Labs of the Evaluation Forum , editor=. 2024 , organization=
work page 2024
-
[6]
Advances in Neural Information Processing Systems , volume=
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Anthropic , institution=. The
-
[8]
Introducing Claude 4 , author=
-
[9]
Introducing Claude Sonnet 4.6 , author=
-
[10]
Aixin Liu and Bei Feng and Bin Wang and Bingxuan Wang and Bo Liu and Chenggang Zhao and Chengqi Deng and Chong Ruan and Damai Dai and Daya Guo and Dejian Yang and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and Hao Zhang and Hanwei Xu and Hao Yang and Haowei Zhang and Honghui Ding and...
-
[11]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multimodal Models , author =. arXiv preprint arXiv:2312.11805 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Thomas Mesnard and Cassidy Hardin and Robert Dadashi and Surya Bhupatiraju and Shreya Pathak and Laurent Sifre and Morgane Rivière and Mihir Sanjay Kale and Juliette Love and Pouya Tafti and Léonard Hussenot and Pier Giuseppe Sessa and Aakanksha Chowdhery and Adam Roberts and Aditya Barua and Alex Botev and Alex Castro-Ros and Ambrose Slone and Amélie Hél...
-
[13]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
- [15]
-
[16]
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[17]
Instruction-Following Evaluation for Large Language Models
Instruction-following evaluation for large language models , author=. arXiv preprint arXiv:2311.07911 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[19]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
work page 2023
-
[21]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2411.19799 , year=
Include: Evaluating multilingual language understanding with regional knowledge , author=. arXiv preprint arXiv:2411.19799 , year=
-
[23]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Supergpqa: Scaling llm evaluation across 285 graduate disciplines , author=. arXiv preprint arXiv:2502.14739 , year=
-
[25]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Icleval: evaluating in-context learning ability of large language models , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[27]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Are we done with mmlu? , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Theoremqa: A theorem-driven question answering dataset , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[30]
Kor-bench: Benchmarking language models on knowledge-orthogonal reasoning tasks , author=. arXiv preprint arXiv:2410.06526 , year=
-
[31]
Advances in Neural Information Processing Systems , year=
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models , author=. Advances in Neural Information Processing Systems , year=
-
[32]
CMMLU: Measuring massive multitask language understanding in Chinese , author=. 2023 , eprint=
work page 2023
-
[33]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
work page 2023
-
[34]
First Conference on Language Modeling , year =
Evaluating Language Models for Efficient Code Generation , author =. First Conference on Language Modeling , year =
-
[35]
Multipl-e: A scalable and extensible approach to benchmarking neural code generation , author=. arXiv preprint arXiv:2208.08227 , year=
-
[36]
Multilingual Massive Multitask Language Understanding , author=. 2024 , url=
work page 2024
-
[37]
Lindsey, Jack and Gurnee, Wes and Ameisen, Emmanuel and Chen, Brian and Pearce, Adam and Turner, Nicholas L. and Citro, Craig and Abrahams, David and Carter, Shan and Hosmer, Basil and Marcus, Jonathan and Sklar, Michael and Templeton, Adly and Bricken, Trenton and McDougall, Callum and Cunningham, Hoagy and Henighan, Thomas and Jermyn, Adam and Jones, An...
-
[38]
arXiv preprint arXiv:2601.03595 , year=
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering , author=. arXiv preprint arXiv:2601.03595 , year=
-
[39]
Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders
Deng, Boyi and Wan, Yu and Yang, Baosong and Zhang, Yidan and Feng, Fuli. Unveiling Language-Specific Features in Large Language Models via Sparse Autoencoders. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.229
-
[40]
Boyi Deng and Yu Wan and Baosong Yang and Fei Huang and Wenjie Wang and Fuli Feng , booktitle=. 2026 , url=
work page 2026
-
[41]
The 2025 Conference on Empirical Methods in Natural Language Processing , year=
Model Unlearning via Sparse Autoencoder Subspace Guided Projections , author=. The 2025 Conference on Empirical Methods in Natural Language Processing , year=
work page 2025
-
[42]
The Fourteenth International Conference on Learning Representations , year=
Does Higher Interpretability Imply Better Utility? A Pairwise Analysis on Sparse Autoencoders , author=. The Fourteenth International Conference on Learning Representations , year=
-
[43]
The 2025 Conference on Empirical Methods in Natural Language Processing , year=
Feature Extraction and Steering for Enhanced Chain-of-Thought Reasoning in Language Models , author=. The 2025 Conference on Empirical Methods in Natural Language Processing , year=
work page 2025
-
[44]
SAEs Are Good for Steering – If You Select the Right Features , url=
Arad, Dana and Mueller, Aaron and Belinkov, Yonatan , year=. SAEs Are Good for Steering – If You Select the Right Features , url=. doi:10.18653/v1/2025.emnlp-main.519 , booktitle=
-
[45]
Applying sparse autoencoders to unlearn knowledge in language models , author=. 2024 , eprint=
work page 2024
-
[46]
Falsifying Sparse Autoencoder Reasoning Features in Language Models , author=. 2026 , eprint=
work page 2026
-
[47]
arXiv preprint arXiv:2602.10388 , year=
Less is Enough: Synthesizing Diverse Data in Feature Space of LLMs , author=. arXiv preprint arXiv:2602.10388 , year=
-
[48]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[49]
Forty-second International Conference on Machine Learning , year=
Automatically Interpreting Millions of Features in Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[50]
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models , author=. arXiv preprint arXiv:2601.14004 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Automatically Interpreting Millions of Features in Large Language Models , booktitle =
Gon. Automatically Interpreting Millions of Features in Large Language Models , booktitle =
-
[52]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander. Steering Llama 2 via Contrastive Activation Addition. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.828
-
[53]
arXiv preprint arXiv:2503.00177 , year=
Steering large language model activations in sparse spaces , author=. arXiv preprint arXiv:2503.00177 , year=
-
[54]
arXiv preprint arXiv:2502.11356 , year=
Saif: A sparse autoencoder framework for interpreting and steering instruction following of language models , author=. arXiv preprint arXiv:2502.11356 , year=
-
[55]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Refusal in Language Models Is Mediated by a Single Direction , booktitle =
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Panickssery and Wes Gurnee and Neel Nanda , editor =. Refusal in Language Models Is Mediated by a Single Direction , booktitle =. 2024 , url =
work page 2024
-
[57]
The Thirteenth International Conference on Learning Representations,
Javier Ferrando and Oscar Balcells Obeso and Senthooran Rajamanoharan and Neel Nanda , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[58]
Rethinking Interpretability in the Era of Large Language Models , author=. 2024 , eprint=
work page 2024
-
[59]
Transcoders find interpretable LLM feature circuits , url =
Dunefsky, Jacob and Chlenski, Philippe and Nanda, Neel , booktitle =. Transcoders find interpretable LLM feature circuits , url =. doi:10.52202/079017-0768 , editor =
-
[60]
On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLM s
Calderon, Nitay and Reichart, Roi. On Behalf of the Stakeholders: Trends in NLP Model Interpretability in the Era of LLM s. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.29
-
[61]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
work page 2025
- [62]
-
[63]
Open Problems in Mechanistic Interpretability
Open problems in mechanistic interpretability , author=. arXiv preprint arXiv:2501.16496 , year=
work page internal anchor Pith review arXiv
-
[64]
Mechanistic Interpretability for
Leonard Bereska and Stratis Gavves , journal=. Mechanistic Interpretability for. 2024 , url=
work page 2024
-
[65]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , author=. 2015 , eprint=
work page 2015
- [66]
-
[67]
Toy models of superposition , author=. arXiv preprint arXiv:2209.10652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Transactions on Machine Learning Research , issn=
Finding Neurons in a Haystack: Case Studies with Sparse Probing , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
work page 2023
-
[69]
Emergent Linear Representations in World Models of Self-Supervised Sequence Models
Nanda, Neel and Lee, Andrew and Wattenberg, Martin. Emergent Linear Representations in World Models of Self-Supervised Sequence Models. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2023. doi:10.18653/v1/2023.blackboxnlp-1.2
-
[70]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models , author=. arXiv preprint arXiv:2403.19647 , year=
work page internal anchor Pith review arXiv
- [72]
-
[73]
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2023 , eprint=
work page 2023
-
[74]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[75]
arXiv preprint arXiv:2602.11180 , year=
Mechanistic interpretability for large language model alignment: Progress, challenges, and future directions , author=. arXiv preprint arXiv:2602.11180 , year=
-
[76]
A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models
Shu, Dong and Wu, Xuansheng and Zhao, Haiyan and Rai, Daking and Yao, Ziyu and Liu, Ninghao and Du, Mengnan. A Survey on Sparse Autoencoders: Interpreting the Internal Mechanisms of Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.89
-
[77]
Route Sparse Autoencoder to Interpret Large Language Models
Shi, Wei and Li, Sihang and Liang, Tao and Wan, Mingyang and Ma, Guojun and Wang, Xiang and He, Xiangnan. Route Sparse Autoencoder to Interpret Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.346
-
[78]
Thought Branches: Interpreting LLM Reasoning Requires Resampling , author=. 2026 , eprint=
work page 2026
-
[79]
Thought Anchors: Which LLM Reasoning Steps Matter? , author=. 2025 , eprint=
work page 2025
-
[80]
Detecting Strategic Deception Using Linear Probes , author=. 2025 , eprint=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.