Recognition: no theorem link
UniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
Pith reviewed 2026-05-14 21:57 UTC · model grok-4.3
The pith
Fusing ViT and VAE features early before VLM encoding unifies conditioning for multi-reference image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniCustom introduces a unified visual conditioning framework that fuses ViT semantic features and VAE appearance features prior to VLM encoding, allowing hidden states to jointly encode the referred subject and its visual appearance. This is achieved with a lightweight linear fusion layer, followed by reconstruction-oriented pretraining that preserves reference-specific details, supervised finetuning on single- and multi-reference tasks, and slot-wise binding regularization to reduce cross-reference entanglement.
What carries the argument
early fusion of ViT and VAE features before VLM encoding using a lightweight linear layer
If this is right
- Subject consistency rises across multiple references in the generated images.
- Textual instructions are followed more accurately in scenes with several subjects.
- Compositional fidelity improves and attribute leakage decreases compared with decoupled baselines.
- Cross-reference confusion drops when prompts involve more than one reference image.
Where Pith is reading between the lines
- The separation of semantic and appearance streams appears to be the main source of binding failures in current multi-reference systems.
- The same early-fusion pattern could be tested on single-reference or video generation tasks to check whether it generalizes.
- Slot-wise regularization may prove useful in other multimodal models that must keep multiple visual inputs distinct.
Load-bearing premise
That fusing ViT and VAE features early will let the VLM hidden states jointly encode subject semantics and appearance details without losing information or adding complexity that hurts performance.
What would settle it
If controlled tests on the same benchmarks show no measurable gain in subject consistency scores or no reduction in attribute leakage when early fusion is removed, the central claim would be falsified.
Figures












read the original abstract
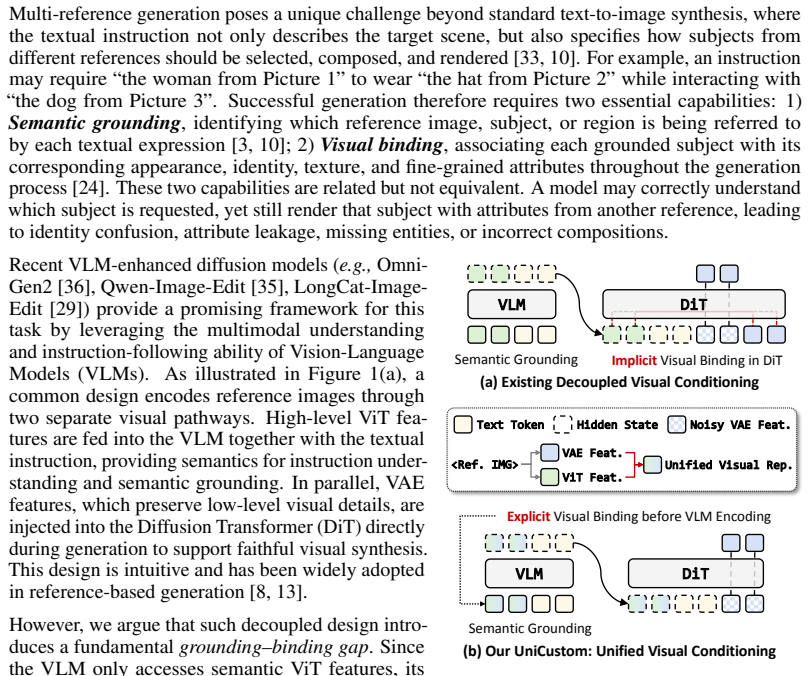
Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image. As a result, the model may recognize which subject is being referred to, but fail to preserve its identity and fine-grained appearance, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. To learn such unified representations, we adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce a slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference, thereby reducing cross-reference entanglement. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniCustom, a unified visual conditioning framework for multi-reference image generation. It fuses ViT semantic features and VAE appearance features early via a lightweight linear layer before VLM encoding, employs two-stage training (reconstruction pretraining followed by supervised finetuning on single- and multi-reference tasks), and adds slot-wise binding regularization to reduce cross-reference entanglement. The central claim is that this addresses attribute leakage and confusion in decoupled conditioning setups, yielding consistent gains in subject consistency, instruction following, and compositional fidelity on two benchmarks over strong baselines.
Significance. If the empirical gains hold under rigorous controls, the early-fusion design offers a practical alternative to decoupled ViT/VAE conditioning in VLM-augmented diffusion models, potentially reducing identity leakage in complex multi-subject scenes. The two-stage training and slot-wise regularization are straightforward to implement and could transfer to related tasks such as personalized generation or compositional editing.
major comments (2)
- [Abstract, §4] Abstract and §4: the claim of 'consistent improvements' over baselines is stated without any quantitative metrics, ablation tables, or statistical significance tests in the provided text; this makes it impossible to assess effect sizes or baseline fairness and is load-bearing for the performance contribution.
- [§3.2] §3.2: the early-fusion hypothesis (ViT+VAE features jointly encoded in VLM hidden states without information loss) is motivated but lacks an explicit derivation or information-theoretic argument showing why the linear fusion preserves low-level details better than late injection; an ablation isolating the fusion timing would be needed to support the architectural choice.
minor comments (2)
- [§3.1] Notation for the number of reference slots and the exact dimensionality of the fused feature vector should be defined explicitly in §3.1 to avoid ambiguity when scaling to variable numbers of references.
- [§3.3] The description of the reconstruction pretraining objective would benefit from the precise loss formulation (e.g., whether it is pixel-space MSE, perceptual loss, or a combination) to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and architectural motivations.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4: the claim of 'consistent improvements' over baselines is stated without any quantitative metrics, ablation tables, or statistical significance tests in the provided text; this makes it impossible to assess effect sizes or baseline fairness and is load-bearing for the performance contribution.
Authors: We agree that the abstract and §4 would benefit from explicit quantitative support. The full manuscript contains tables reporting subject consistency, instruction following, and compositional fidelity metrics on both benchmarks, along with ablations, but these were not summarized numerically in the abstract. In the revised version we will add specific delta values, standard deviations, and significance indicators to the abstract and expand §4 with a consolidated results table plus statistical tests. revision: yes
-
Referee: [§3.2] §3.2: the early-fusion hypothesis (ViT+VAE features jointly encoded in VLM hidden states without information loss) is motivated but lacks an explicit derivation or information-theoretic argument showing why the linear fusion preserves low-level details better than late injection; an ablation isolating the fusion timing would be needed to support the architectural choice.
Authors: The motivation in §3.2 is primarily empirical, showing that early fusion enables the VLM to bind appearance details to semantic slots before diffusion. We acknowledge the absence of a formal information-theoretic derivation or a dedicated timing ablation. In revision we will add a short paragraph deriving the benefit from reduced cross-attention entropy and include an ablation comparing early vs. late fusion on a controlled single-reference subset, reporting both quantitative metrics and qualitative leakage examples. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an architectural proposal (early ViT+VAE fusion before VLM encoding, two-stage training, slot-wise regularization) and asserts empirical gains on two benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on experimental comparison rather than any self-referential reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
XVerse: Consistent multi-subject control of identity and semantic attributes via dit modulation
Bowen Chen, Brynn zhao, Haomiao Sun, Li Chen, Xu Wang, Daniel Kang Du, and Xinglong Wu. XVerse: Consistent multi-subject control of identity and semantic attributes via dit modulation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[4]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yufeng Cheng, Wenxu Wu, Shaojin Wu, Mengqi Huang, Fei Ding, and Qian He. Umo: Scaling multi-identity consistency for image customization via matching reward.arXiv preprint arXiv:2509.06818, 2025
-
[6]
Yusuf Dalva, Guocheng Gordon Qian, Maya Goldenberg, Tsai-Shien Chen, Kfir Aberman, Sergey Tulyakov, Pinar Yanardag, and Kuan-Chieh Jackson Wang. Canvas-to-image: Composi- tional image generation with multimodal controls.arXiv preprint arXiv:2511.21691, 2025
-
[7]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Yufan Deng, Xun Guo, Yizhi Wang, Jacob Zhiyuan Fang, Angtian Wang, Shenghai Yuan, Yiding Yang, Bo Liu, Haibin Huang, and Chongyang Ma. Cinema: Coherent multi-subject video generation via mllm-based guidance.arXiv preprint arXiv:2503.10391, 2025
-
[9]
Guid- ing instruction-based image editing via multimodal large language models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guid- ing instruction-based image editing via multimodal large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[10]
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions On Graphics (TOG), 44(4):1–11, 2025
work page 2025
-
[11]
Nano banana 2: Combining pro capabilities with lightning-fast speed
Google. Nano banana 2: Combining pro capabilities with lightning-fast speed. https: //blog.google/innovation-and-ai/technology/ai/nano-banana-2/, 2026
work page 2026
-
[12]
Image quality metrics: Psnr vs
Alain Hore and Djemel Ziou. Image quality metrics: Psnr vs. ssim. In2010 20th international conference on pattern recognition, pages 2366–2369. IEEE, 2010
work page 2010
-
[13]
Teng Hu, Zhentao Yu, Zhengguang Zhou, Sen Liang, Yuan Zhou, Qin Lin, and Qinglin Lu. Hunyuancustom: A multimodal-driven architecture for customized video generation.arXiv preprint arXiv:2505.04512, 2025
-
[14]
Human-art: A versatile human-centric dataset bridging natural and artificial scenes
Xuan Ju, Ailing Zeng, Jianan Wang, Qiang Xu, and Lei Zhang. Human-art: A versatile human-centric dataset bridging natural and artificial scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 618–629, 2023
work page 2023
-
[15]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 10
work page 2019
-
[16]
Nohumansrequired: Autonomous high-quality image editing triplet mining
Maksim Kuprashevich, Grigorii Alekseenko, Irina Tolstykh, Georgii Fedorov, Bulat Suleimanov, Vladimir Dokholyan, and Aleksandr Gordeev. Nohumansrequired: Autonomous high-quality image editing triplet mining. InProceedings of the IEEE/CVF Winter Conference on Applica- tions of Computer Vision, pages 6059–6068, 2026
work page 2026
-
[17]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Dongxu Li, Junnan Li, and Steven Hoi. BLIP-diffusion: Pre-trained subject representation for controllable text-to-image generation and editing. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[19]
Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131,
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024
-
[20]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld-v1: High-resolution semantic encoders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[22]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Wan-Image: Pushing the Boundaries of Generative Visual Intelligence
Chaojie Mao, Chen-Wei Xie, Chongyang Zhong, Haoyou Deng, Jiaxing Zhao, Jie Xiao, Jinbo Xing, Jingfeng Zhang, Jingren Zhou, Jingyi Zhang, et al. Wan-image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Dreamo: A unified framework for image customization
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al. Dreamo: A unified framework for image customization. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–12, 2025
work page 2025
-
[25]
Introducing chatgpt images 2.0
OpenAI. Introducing chatgpt images 2.0. https://openai.com/index/ introducing-chatgpt-images-2-0/, 2026
work page 2026
-
[26]
Kosmos- g: Generating images in context with multimodal large language models
Xichen Pan, Li Dong, Shaohan Huang, Zhiliang Peng, Wenhu Chen, and Furu Wei. Kosmos- g: Generating images in context with multimodal large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[27]
Yusu Qian, Eli Bocek-Rivele, Liangchen Song, Jialing Tong, Yinfei Yang, Jiasen Lu, Wenze Hu, and Zhe Gan. Pico-banana-400k: A large-scale dataset for text-guided image editing.arXiv preprint arXiv:2510.19808, 2025
-
[28]
MOSAIC: Multi-subject personalized generation via correspondence-aware alignment and disentanglement
Dong She, Siming Fu, Mushui Liu, Qiaoqiao Jin, Hualiang Wang, Mu Liu, and Jidong Jiang. MOSAIC: Multi-subject personalized generation via correspondence-aware alignment and disentanglement. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[29]
Longcat-image technical report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report. arXiv preprint arXiv:2512.07584, 2025
-
[30]
The unsplash dataset.https://github.com/unsplash/datasets, 2025
Unsplash. The unsplash dataset.https://github.com/unsplash/datasets, 2025
work page 2025
-
[31]
PSR: Scaling Multi-Subject Personalized Image Generation with Pairwise Subject-Consistency Rewards
Shulei Wang, Longhui Wei, Xin He, Jianbo Ouyang, Hui Lu, Zhou Zhao, and Qi Tian. Psr: Scaling multi-subject personalized image generation with pairwise subject-consistency rewards. arXiv preprint arXiv:2512.01236, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
MS-diffusion: Multi- subject zero-shot image personalization with layout guidance
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. MS-diffusion: Multi- subject zero-shot image personalization with layout guidance. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[33]
Yuran Wang, Bohan Zeng, Chengzhuo Tong, Wenxuan Liu, Yang Shi, Xiaochen Ma, Hao Liang, Yuanxing Zhang, and Wentao Zhang. Scone: Bridging composition and distinction in subject-driven image generation via unified understanding-generation modeling.arXiv preprint arXiv:2512.12675, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
MICo-150K: A Comprehensive Dataset Advancing Multi-Image Composition
Xinyu Wei, Kangrui Cen, Hongyang Wei, Zhen Guo, Bairui Li, Zeqing Wang, Jinrui Zhang, and Lei Zhang. Mico-150k: A comprehensive dataset advancing multi-image composition.arXiv preprint arXiv:2512.07348, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Shaojin Wu, Mengqi Huang, Yufeng Cheng, Wenxu Wu, Jiahe Tian, Yiming Luo, Fei Ding, and Qian He. Uso: Unified style and subject-driven generation via disentangled and reward learning.arXiv preprint arXiv:2508.18966, 2025
-
[38]
Less-to-more generalization: Unlocking more controllability by in-context generation
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more generalization: Unlocking more controllability by in-context generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18682–18692, 2025
work page 2025
-
[39]
Omnicontrol: Control any joint at any time for human motion generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[40]
Withanyone: Toward controllable and ID consistent image generation
Hengyuan Xu, Wei Cheng, Peng Xing, Yixiao Fang, Shuhan Wu, Rui Wang, Xianfang Zeng, Daxin Jiang, Gang YU, Xingjun Ma, and Yu-Gang Jiang. Withanyone: Toward controllable and ID consistent image generation. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[41]
Hq-50k: A large-scale, high-quality dataset for image restoration
Qinhong Yang, Dongdong Chen, Zhentao Tan, Qiankun Liu, Qi Chu, Jianmin Bao, Lu Yuan, Gang Hua, and Nenghai Yu. Hq-50k: A large-scale, high-quality dataset for image restoration. arXiv preprint arXiv:2306.05390, 2023
-
[42]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zhenghao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation.arXiv preprint arXiv:2508.09987, 2025
-
[44]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Reconstruct Picture i with the highest possible fidelity
Yi Zhang, Bolin Ni, Xin-Sheng Chen, Heng-Rui Zhang, Yongming Rao, Houwen Peng, Qinglin Lu, Han Hu, Meng-Hao Guo, and Shi-Min Hu. Bee: A high-quality corpus and full-stack suite to unlock advanced fully open mllms.arXiv preprint arXiv:2510.13795, 2025. 12 A Implementation Details During pretraining of UniCustom, we jointly optimize the fusion layer and the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.