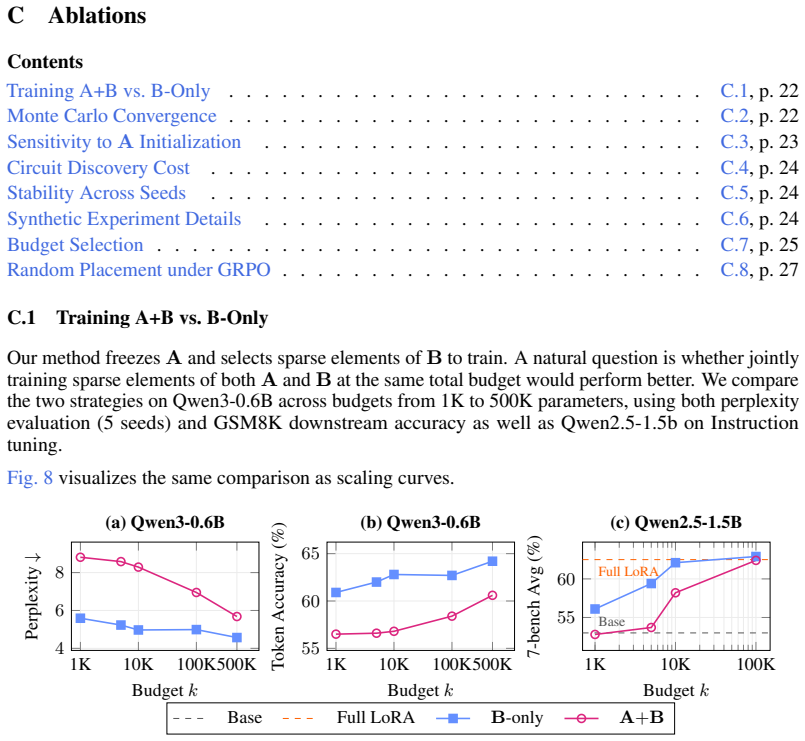
Recognition: no theorem link
Not How Many, But Which: Parameter Placement in Low-Rank Adaptation
Pith reviewed 2026-05-13 06:06 UTC · model grok-4.3
The pith
The choice of which parameters to update in LoRA adapters matters far more than the number updated, especially under GRPO training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under GRPO, only gradient-informed placement of the k trainable parameters in LoRA's B matrix recovers the accuracy of standard LoRA, while random placement fails to beat the base model; this occurs because GRPO gradients are high-rank and near-orthogonal across steps, so only consistently signed entries retain the update signal, unlike the low-rank stable gradients in SFT.
What carries the argument
The gradient-informed scoring procedure that ranks parameters by consistency of gradient signs or magnitudes to select the critical subset for training.
If this is right
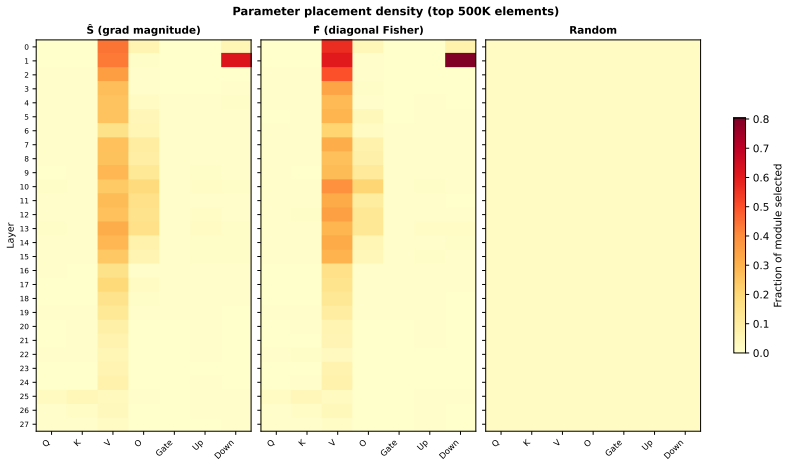
- Selected parameters concentrate on residual-stream-writing projections V, O, and Down across different model families and scales from 1.5B to 8B.
- Under supervised fine-tuning, any random subset of k parameters achieves comparable performance to informed selection.
- The scoring procedure runs in under 10 seconds and costs less than 0.5% of full training.
- Gradient structure determines whether placement choice matters: low-rank stable gradients in SFT vs high-rank orthogonal in GRPO.
Where Pith is reading between the lines
- Similar placement sensitivity may appear in other parameter-efficient fine-tuning methods beyond LoRA when using reinforcement learning objectives like GRPO.
- Practitioners could integrate this quick scoring step into standard LoRA workflows to reduce trainable parameters without loss of performance under policy optimization.
- Testing the method on larger models or different tasks could reveal whether the concentration on V, O, Down projections holds more broadly.
- Future work might explore whether modifying the optimizer or gradient accumulation could make random placement viable under GRPO.
Load-bearing premise
The performance difference between random and informed placement under GRPO stems directly from the described differences in gradient rank and directional stability rather than from unexamined factors like optimizer settings or data order.
What would settle it
Running the same GRPO experiments but measuring if random placement succeeds when gradients are forced to be more stable or low-rank would falsify the claim if it then matches informed performance.
Figures



















read the original abstract
We study the \textit{parameter placement problem}: given a fixed budget of $k$ trainable entries within the B matrix of a LoRA adapter (A frozen), does the choice of which $k$ matter? Under supervised fine-tuning, random and informed subsets achieve comparable performance. Under GRPO on base models, random placement fails to improve over the base model, while gradient-informed placement recovers standard LoRA accuracy. This regime dependence traces to gradient structure: SFT gradients are low-rank and directionally stable, so any subset accumulates coherent updates; GRPO gradients are high-rank and near-orthogonal across steps, so only elements with consistently signed gradients retain the learning signal. Our scoring procedure identifies these critical parameters in under 10 seconds at less than 0.5% of training cost. Selected parameters concentrate on residual-stream-writing projections (V, O, Down), stable across model families and scales (1.5B - 8B).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the parameter placement problem in LoRA: with a fixed budget of k trainable entries in the B matrix (A frozen), does the specific choice of which entries matter? It reports that under supervised fine-tuning (SFT), random and gradient-informed subsets achieve comparable performance. Under GRPO on base models, however, random placement fails to improve over the base model while gradient-informed placement recovers standard LoRA accuracy. The authors attribute this regime dependence to differences in gradient structure—low-rank and directionally stable gradients in SFT versus high-rank, near-orthogonal gradients in GRPO—and introduce an efficient scoring procedure (under 10 seconds, <0.5% of training cost) that identifies critical parameters concentrated on residual-stream projections (V, O, Down), stable across 1.5B–8B models.
Significance. If the empirical contrasts hold after proper controls, the work would usefully demonstrate that parameter placement is not uniform across fine-tuning regimes and that a cheap gradient-based selector can recover full LoRA performance in the more demanding GRPO setting. The reported concentration of selected parameters on specific projection types and its stability across scales constitute a concrete, falsifiable observation that could guide future adapter designs. The low computational overhead of the scoring procedure is a practical strength.
major comments (2)
- [Abstract / GRPO experimental regime] The central regime-dependence claim (random placement fails under GRPO while informed succeeds) is load-bearing for the paper’s contribution, yet the abstract and experimental description do not indicate control experiments that hold optimizer momentum, per-step learning-rate scaling, and batch ordering fixed while varying only the selection rule. Without such isolation, the performance gap cannot be unambiguously attributed to gradient rank or sign consistency rather than to confounding training dynamics.
- [Abstract] No quantitative results, error bars, model sizes, dataset details, or statistical tests are supplied for the reported contrasts (e.g., “recovers standard LoRA accuracy”). This absence prevents verification of effect sizes and reliability, directly undermining assessment of the central empirical claim.
minor comments (1)
- The scoring procedure is described only at a high level; a brief equation or pseudocode in the main text would clarify how per-parameter scores are computed from gradients.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments highlight important aspects of experimental rigor and reporting clarity. We address each below, providing clarifications on our controls and committing to revisions where they strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / GRPO experimental regime] The central regime-dependence claim (random placement fails under GRPO while informed succeeds) is load-bearing for the paper’s contribution, yet the abstract and experimental description do not indicate control experiments that hold optimizer momentum, per-step learning-rate scaling, and batch ordering fixed while varying only the selection rule. Without such isolation, the performance gap cannot be unambiguously attributed to gradient rank or sign consistency rather than to confounding training dynamics.
Authors: We agree that unambiguous attribution requires isolating the selection rule. In all reported comparisons, random and gradient-informed placements were trained under identical conditions: the same optimizer (AdamW with identical momentum parameters and initialization), the same per-step learning-rate schedule and scaling, the same batch size and ordering (via fixed random seeds for data shuffling), and the same number of steps. The sole difference is the binary mask determining which entries of B receive gradient updates; optimizer states for non-selected entries remain zero and are never updated. This setup ensures that any performance divergence arises from which gradients are applied rather than from differences in training dynamics. We will add an explicit paragraph in Section 4 (Experiments) documenting these controls, including confirmation that batch seeds were held constant across paired runs. No new experiments are required for this clarification. revision: partial
-
Referee: [Abstract] No quantitative results, error bars, model sizes, dataset details, or statistical tests are supplied for the reported contrasts (e.g., “recovers standard LoRA accuracy”). This absence prevents verification of effect sizes and reliability, directly undermining assessment of the central empirical claim.
Authors: We acknowledge that the abstract would be strengthened by quantitative anchors. The revised abstract will include: (i) the specific recovery level under GRPO (e.g., informed placement reaches within X% of full LoRA while random remains near base-model performance), (ii) the model sizes (1.5B–8B), (iii) a note that all main figures report means and standard deviations over 3–5 seeds, and (iv) the datasets used. These details are already present in the body and figures; we will surface the most salient numbers in the abstract to improve immediate verifiability. revision: yes
Circularity Check
No circularity: empirical comparisons stand on direct measurements without reduction to fitted inputs or self-citations
full rationale
The paper reports direct empirical results comparing random versus gradient-informed parameter subsets under SFT and GRPO, with performance gaps attributed to observed differences in gradient rank and sign consistency. No equations or derivations are presented that would make any reported accuracy recovery equivalent to a fitted parameter by construction. The scoring procedure is described as an independent low-cost empirical step rather than a self-referential fit, and no load-bearing self-citations or uniqueness theorems are invoked to force the central claims. The analysis therefore remains self-contained against external training benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA adapter consists of a frozen A matrix and a trainable B matrix whose entries can be selectively activated.
Reference graph
Works this paper leans on
-
[1]
Adilova and Samariddin Kushmuratov
F.T. Adilova and Samariddin Kushmuratov. OLoRA+: A hybrid approach to parameter-efficient fine-tuning of large language models. In Conference of Mathematics of AI, 2026. URL https://openreview.net/forum?id=c75JefyklT
work page 2026
-
[2]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language ...
-
[3]
Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad
Paul Albert, Frederic Z. Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad. RandloRA: Full rank parameter-efficient fine-tuning of large models. In The Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=Hn5eoTunHN
work page 2025
-
[4]
LoRA-XS: Low-rank adaptation with extremely small number of parameters, 2024
Klaudia Bałazy, Mohammadreza Banaei, Karl Aberer, and Jacek Tabor. LoRA-XS: Low-rank adaptation with extremely small number of parameters, 2024. URL https://openreview. net/forum?id=l80AgHoRaN
work page 2024
-
[5]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
BitFit: Simple parameter-efficient fine- tuning for transformer-based masked language-models
Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. BitFit: Simple parameter-efficient fine- tuning for transformer-based masked language-models. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume2: Short Papers), pages 1–9, Dublin, Ireland, May
-
[7]
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-short.1. URL https://aclanthology.org/2022.acl-short.1/
-
[8]
LoRA learns less and forgets less
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John Patrick Cunningham. LoRA learns less and forgets less. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id= aloEru2qCG....
work page 2024
-
[9]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[10]
Olora: Orthonormal low-rank adaptation of large language models
Kerim Büyükakyüz. Olora: Orthonormal low-rank adaptation of large language models. arXiv preprint arXiv:2406.01775, 2024
-
[11]
Nick Cammarata, Gabriel Goh, Shan Carter, Chelsea V oss, Ludwig Schubert, and Chris Olah. Curve circuits. Distill, 2021. doi: 10.23915/distill.00024.006. https://distill.pub/2020/circuits/curve-circuits
-
[12]
The lottery ticket hypothesis for pre-trained bert networks
Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Zhangyang Wang, and Michael Carbin. The lottery ticket hypothesis for pre-trained bert networks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 15834–15846. Curran Associates, Inc., 2020. URL...
work page 2020
-
[13]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019. 10
work page 2019
-
[14]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Michael Han Daniel Han and Unsloth team. Unsloth, 2023. URL https://github.com/ unslothai/unsloth
work page 2023
-
[17]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36:10088– 10115, 2023
work page 2023
-
[18]
Sparse low-rank adaptation of pre-trained language models
Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. Sparse low-rank adaptation of pre-trained language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4133–4145, Singapore, December 2023. Association for Compu...
-
[19]
Quantifying elicitation of latent capabilities in language models
Elizabeth Donoway, Hailey Joren, Arushi Somani, Henry Sleight, Julian Michael, Michael R DeWeese, John Schulman, Ethan Perez, Fabien Roger, and Jan Leike. Quantifying elicitation of latent capabilities in language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[20]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[21]
https://transformer-circuits.pub/2021/framework/index.html
work page 2021
-
[22]
The lottery ticket hypothesis: Finding sparse, trainable neural networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In International Conference on Learning Representations, 2019. URL https: //openreview.net/forum?id=rJl-b3RcF7
work page 2019
-
[23]
Sparsegpt: Massive language models can be accurately pruned in one-shot
Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. In International conference on machine learning, pages 10323–10337. PMLR, 2023
work page 2023
-
[24]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[25]
Parameter-efficient fine-tuning with discrete fourier transform
Ziqi Gao, Qichao Wang, Aochuan Chen, Zijing Liu, Bingzhe Wu, Liang Chen, and Jia Li. Parameter-efficient fine-tuning with discrete fourier transform. In International Conference on Machine Learning, pages 14884–14901. PMLR, 2024
work page 2024
-
[26]
Au- tomatically identifying local and global circuits with linear computation graphs, 2024
Xuyang Ge, Fukang Zhu, Wentao Shu, Junxuan Wang, Zhengfu He, and Xipeng Qiu. Au- tomatically identifying local and global circuits with linear computation graphs, 2024. URL https://arxiv.org/abs/2405.13868
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645(8081):633–638, 2025
work page 2025
-
[29]
Parameter-efficient transfer learning with diff pruning
Demi Guo, Alexander Rush, and Yoon Kim. Parameter-efficient transfer learning with diff pruning. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th 11 International Joint Conference on Natural Language Processing (V olume1: Long Papers), ...
work page 2021
-
[30]
When models manipulate manifolds: The geometry of a counting task
Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah, and Joshua Batson. When models manipulate manifolds: The geometry of a counting task. Transformer Circuits Thread, 2025. URL https://transformer-circuits.pub/2025/ linebreaks/index.html
work page 2025
-
[31]
Position-aware automatic circuit discovery, 2025
Tal Haklay, Hadas Orgad, David Bau, Aaron Mueller, and Yonatan Belinkov. Position-aware automatic circuit discovery, 2025. URLhttps://arxiv.org/abs/2502.04577
-
[32]
Flora: Low-rank adapters are secretly gradient compressors
Yongchang Hao, Yanshuai Cao, and Lili Mou. Flora: Low-rank adapters are secretly gradient compressors. In Forty-first International Conference on Machine Learning, 2024. URL https: //openreview.net/forum?id=uubBZKM99Y
work page 2024
-
[33]
Optimal brain surgeon and general network pruning
Babak Hassibi, David G Stork, and Gregory J Wolff. Optimal brain surgeon and general network pruning. In IEEE international conference on neural networks, pages 293–299. IEEE, 1993
work page 1993
-
[34]
Lora+: Efficient low rank adaptation of large models
Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models. arXiv preprint arXiv:2402.12354, 2024
-
[35]
Sensitivity-aware visual parameter-efficient fine-tuning
Haoyu He, Jianfei Cai, Jing Zhang, Dacheng Tao, and Bohan Zhuang. Sensitivity-aware visual parameter-efficient fine-tuning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11825–11835, 2023
work page 2023
-
[36]
SparseAdapter: An easy approach for improving the parameter-efficiency of adapters
Shwai He, Liang Ding, Daize Dong, Jeremy Zhang, and Dacheng Tao. SparseAdapter: An easy approach for improving the parameter-efficiency of adapters. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2184–2190, Abu Dhabi, United Arab Emirates, December 2022. As- sociatio...
-
[37]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[38]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[39]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022
work page 2022
-
[40]
Lora training in the ntk regime has no spurious local minima
Uijeong Jang, Jason D Lee, and Ernest K Ryu. Lora training in the ntk regime has no spurious local minima. In International Conference on Machine Learning, pages 21306–21328. PMLR, 2024
work page 2024
-
[41]
Maxwell Jia. Aime problem set 2024, 2024. URL https://huggingface.co/datasets/ Maxwell-Jia/AIME_2024
work page 2024
-
[42]
MoRA: High- rank updating for parameter-efficient fine-tuning, 2024
Ting Jiang, Shaohan Huang, Shengyue Luo, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, Qi Zhang, Songtao Wang, deqing wang, and Fuzhen Zhuang. MoRA: High- rank updating for parameter-efficient fine-tuning, 2024. URL https://openreview.net/ forum?id=SxOrhLuuVz
work page 2024
-
[43]
A rank stabilization scaling factor for fine-tuning with LoRA
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora. arXiv preprint arXiv:2312.03732, 2023
-
[44]
Scaling sparse feature circuit finding for in-context learning, 2025
Dmitrii Kharlapenko, Stepan Shabalin, Fazl Barez, Arthur Conmy, and Neel Nanda. Scaling sparse feature circuit finding for in-context learning, 2025. URL https://arxiv.org/abs/ 2504.13756
-
[45]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13): 3...
-
[46]
Vera: Vector-based random matrix adaptation
Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M Asano. Vera: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[47]
arXiv preprint arXiv:2403.00745 , year=
János Kramár, Tom Lieberum, Rohin Shah, and Neel Nanda. Atp*: An efficient and scalable method for localizing llm behaviour to components, 2024. URL https://arxiv.org/abs/ 2403.00745
-
[48]
Bespoke-stratos: The unreasonable effectiveness of reasoning distil- lation
Bespoke Labs. Bespoke-stratos: The unreasonable effectiveness of reasoning distil- lation. https://www.bespokelabs.ai/blog/bespoke-stratos-the-unreasonable-effectiveness-of- reasoning-distillation, 2025. Accessed: 2025-01-22
work page 2025
-
[49]
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage. Advances in neural information processing systems, 2, 1989
work page 1989
-
[50]
Namhoon Lee, Thalaiyasingam Ajanthan, and Philip H. S. Torr. SNIP: single-shot network pruning based on connection sensitivity. CoRR, abs/1810.02340, 2018. URLhttp://arxiv. org/abs/1810.02340
work page Pith review arXiv 2018
-
[51]
Measuring the intrinsic dimension of objective landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes. In International Conference on Learning Representations,
-
[52]
URLhttps://openreview.net/forum?id=ryup8-WCW
-
[53]
Vb-lora: Extreme parameter efficient fine-tuning with vector banks
Yang Li, Shaobo Han, and Shihao Ji. Vb-lora: Extreme parameter efficient fine-tuning with vector banks. In The 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[54]
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: a simple, effective, and efficient reinforcement learning method for aligning large language models. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
work page 2024
-
[55]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 3214–3252, Dublin, Ireland, May
-
[56]
Bradley Efron and Robert J Tibshirani.An introduction to the bootstrap, volume
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.229. URL https://aclanthology.org/2022.acl-long.229
-
[57]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[58]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. In Conference on Language Modeling (COLM), 2025
work page 2025
-
[59]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu et al. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. In ICLR, 2024
work page 2024
-
[60]
Merging models with fisher-weighted averaging
Michael S Matena and Colin A Raffel. Merging models with fisher-weighted averaging. Advances in Neural Information Processing Systems, 35:17703–17716, 2022
work page 2022
-
[61]
math ai. Aime problem set 2025, 2025. URL https://huggingface.co/datasets/ math-ai/aime25
work page 2025
-
[62]
Pissa: Principal singular values and singular vectors adaptation of large language models
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models. Advances in Neural Information Processing Systems, 37:121038–121072, 2024
work page 2024
-
[63]
Mass-Editing Memory in a Transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer. arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review arXiv 2022
-
[64]
Morris, Niloofar Mireshghallah, Mark Ibrahim, and Saeed Mahloujifar
John X Morris, Niloofar Mireshghallah, Mark Ibrahim, and Saeed Mahloujifar. Learning to reason in 13 parameters. arXiv preprint arXiv:2602.04118, 2026
-
[65]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. arXiv preprint arXiv:2301.05217, 2023
work page internal anchor Pith review arXiv 2023
-
[66]
Amc 2023: American mathematics competitions 2023 dataset
Mathematical Association of America (MAA). Amc 2023: American mathematics competitions 2023 dataset. https://huggingface.co/datasets/math-ai/amc23, 2023. Accessed: 2024-05-05. 13
work page 2023
-
[67]
Lisa: Layerwise importance sampling for memory-efficient large language model fine-tuning
Rui Pan, Xiang Liu, Shizhe Diao, Renjie Pi, Jipeng Zhang, Chi Han, and Tong Zhang. Lisa: Layerwise importance sampling for memory-efficient large language model fine-tuning. arXiv preprint arXiv:2403.17919, 2024
-
[68]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9
work page 2023
-
[69]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. In First Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
work page 2024
-
[70]
MELoRA: Mini-ensemble low-rank adapters for parameter- efficient fine-tuning
Pengjie Ren, Chengshun Shi, Shiguang Wu, Mengqi Zhang, Zhaochun Ren, Maarten de Rijke, Zhumin Chen, and Jiahuan Pei. MELoRA: Mini-ensemble low-rank adapters for parameter- efficient fine-tuning. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume1: Long ...
-
[71]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. arXiv preprint arXiv:1907.10641, 2019
work page internal anchor Pith review arXiv 1907
-
[72]
Movement pruning: Adaptive sparsity by fine-tuning
Victor Sanh, Thomas Wolf, and Alexander Rush. Movement pruning: Adaptive sparsity by fine-tuning. Advances in neural information processing systems, 33:20378–20389, 2020
work page 2020
-
[73]
Efficient rlhf: Reducing the memory usage of ppo
Michael Santacroce, Yadong Lu, Han Yu, Yuanzhi Li, and Yelong Shen. Efficient rlhf: Reducing the memory usage of ppo. arXiv preprint arXiv:2309.00754, 2023
-
[74]
John Schulman and Thinking Machines Lab. Lora without regret. Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20250929. https://thinkingmachines.ai/blog/lora/
-
[75]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[76]
Pratyusha Sharma, Jordan T. Ash, and Dipendra Misra. The truth is in there: Improving reasoning in language models with layer-selective rank reduction. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=ozX92bu8VA
work page 2024
-
[77]
Math-llava: Bootstrapping mathematical reasoning for multimodal large language models, 2024
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, and Roy Ka-Wei Lee. Math-llava: Bootstrapping mathematical reasoning for multimodal large language models, 2024
work page 2024
-
[78]
A simple and effective pruning approach for large language models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models. In The Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=PxoFut3dWW
work page 2024
- [80]
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.