Recognition: 2 theorem links
· Lean TheoremDetecting overfitting in Neural Networks during long-horizon grokking using Random Matrix Theory
Pith reviewed 2026-05-15 05:28 UTC · model grok-4.3
The pith
Neural networks form correlation traps in weight spectra that signal the start of overfitting during extended grokking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
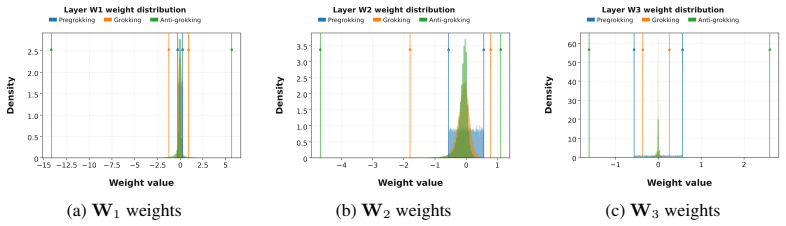
The central claim is that correlation traps, identified as large outliers violating the Marchenko-Pastur law in the empirical spectral distribution of element-wise randomized weight matrices, form and grow in number and scale during the anti-grokking phase of long-horizon grokking, coinciding with decreasing test accuracy while train accuracy remains high.
What carries the argument
Correlation traps: spectral outliers from Marchenko-Pastur fitting after element-wise weight randomization that mark overfitting onset.
Load-bearing premise
Randomizing weights element-wise and fitting to Marchenko-Pastur reliably isolates signals of overfitting, with outliers corresponding directly to generalization failure.
What would settle it
A counterexample would be a training run where correlation traps form and grow but test accuracy does not decrease, or where test accuracy decreases without corresponding trap growth.
Figures









read the original abstract
Training Neural Networks (NNs) without overfitting is difficult; detecting that overfitting is difficult as well. We present a novel Random Matrix Theory method that detects the onset of overfitting in deep learning models without access to train or test data. For each model layer, we randomize each weight matrix element-wise, $\mathbf{W} \to \mathbf{W}^{\mathrm{rand}}$, fit the randomized empirical spectral distribution with a Marchenko-Pastur distribution, and identify large outliers that violate self-averaging. We call these outliers Correlation Traps. During the onset of overfitting, which we call the "anti-grokking" phase in long-horizon grokking, Correlation Traps form and grow in number and scale as test accuracy decreases while train accuracy remains high. Traps may be benign or may harm generalization; we provide an empirical approach to distinguish between them by passing random data through the trained model and evaluating the JS divergence of output logits. Our findings show that anti-grokking is an additional grokking phase with high train accuracy and decreasing test accuracy, structurally distinct from pre-grokking through its Correlation Traps. More broadly, we find that some foundation-scale LLMs exhibit the same Correlation Traps, indicating potentially harmful overfitting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Random Matrix Theory method for detecting overfitting in neural networks during long-horizon grokking without access to data. The approach involves element-wise randomization of each layer's weight matrix, fitting the resulting empirical spectral distribution to the Marchenko-Pastur law, and flagging large outliers as 'Correlation Traps'. These traps are claimed to emerge and increase during the 'anti-grokking' phase, marked by sustained high training accuracy and declining test accuracy. An empirical procedure using Jensen-Shannon divergence on random inputs is proposed to differentiate benign from harmful traps, with observations extended to large language models.
Significance. If substantiated, this work could offer a practical, data-independent diagnostic for overfitting, which is particularly relevant for foundation models where test sets are limited or unavailable. It introduces the notion of anti-grokking as a distinct phase and links spectral properties to generalization failure. The use of RMT provides a theoretical grounding that could be extended, though the current lack of quantitative benchmarks limits immediate impact.
major comments (3)
- [Method (abstract and procedure description)] The core procedure (randomization followed by Marchenko-Pastur fitting) assumes that spectral outliers specifically isolate overfitting signals, but no derivation or controlled experiment demonstrates why these outliers arise from overfitting rather than weight scale, optimization trajectory, or layer geometry (see skeptic note on weakest assumption and abstract description of the method).
- [Empirical results and validation sections] The manuscript provides no quantitative validation, error analysis, baseline comparisons, or statistical details on how traps are distinguished from benign outliers; claims rest on unspecified empirical observations (reader's soundness assessment).
- [Anti-grokking phase analysis] The claim that Correlation Traps form and grow specifically during anti-grokking (high train acc, decreasing test acc) lacks ablation studies or falsifiable tests showing the method's specificity to generalization failure versus other training artifacts.
minor comments (2)
- [Notation and preliminaries] Notation for the randomized weight matrix (W to W^rand) should be explicitly defined once in the main text for consistency.
- [Introduction and related work] Additional citations to prior RMT applications in deep learning and existing grokking literature would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript requires additional validation, clarifications, and experiments to substantiate the claims. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Method (abstract and procedure description)] The core procedure (randomization followed by Marchenko-Pastur fitting) assumes that spectral outliers specifically isolate overfitting signals, but no derivation or controlled experiment demonstrates why these outliers arise from overfitting rather than weight scale, optimization trajectory, or layer geometry (see skeptic note on weakest assumption and abstract description of the method).
Authors: We acknowledge that the current version lacks a formal derivation showing why outliers isolate overfitting signals rather than other factors such as scale or geometry. The randomization is intended to eliminate learned correlations while preserving the empirical spectral distribution's scale, with outliers indicating deviations from random-matrix behavior induced by training. In revision we will add controlled experiments on small MLPs trained on synthetic data, varying training-set size to induce controlled overfitting, and demonstrate that trap count and magnitude increase specifically with the generalization gap. We will also revise the abstract and method section to explicitly state the assumptions and limitations of the randomization step. revision: partial
-
Referee: [Empirical results and validation sections] The manuscript provides no quantitative validation, error analysis, baseline comparisons, or statistical details on how traps are distinguished from benign outliers; claims rest on unspecified empirical observations (reader's soundness assessment).
Authors: This criticism is correct. The revised manuscript will include quantitative validation: error bars from five independent random seeds, a table reporting trap count, maximum outlier deviation, and Jensen-Shannon divergence values across phases, baseline comparisons against randomly initialized networks and networks trained with weight decay or early stopping, and statistical tests (t-tests and p-values) on the increase in traps during anti-grokking. We will also provide the exact procedure and sensitivity analysis for the JS-divergence threshold used to label traps as benign or harmful. revision: yes
-
Referee: [Anti-grokking phase analysis] The claim that Correlation Traps form and grow specifically during anti-grokking (high train acc, decreasing test acc) lacks ablation studies or falsifiable tests showing the method's specificity to generalization failure versus other training artifacts.
Authors: We agree that specificity has not been demonstrated. In the revision we will add ablation studies: (i) training runs on the same architecture and data that avoid the anti-grokking phase via stronger regularization or different learning-rate schedules, showing that traps remain stable; (ii) application of the method to standard CIFAR-10 training without grokking dynamics, confirming that traps appear whenever test accuracy declines. These experiments will provide falsifiable evidence that trap growth is tied to generalization failure rather than other training artifacts. revision: partial
Circularity Check
No significant circularity: detection method uses standard MP fitting on randomized weights with empirical observation of traps during overfitting phases
full rationale
The paper defines Correlation Traps explicitly as spectral outliers in the empirical spectral distribution of element-wise randomized weight matrices after Marchenko-Pastur fitting. This definition is independent of any overfitting signal or train/test accuracy. The association between trap formation/growth and the anti-grokking phase (high train accuracy with falling test accuracy) is presented as an empirical finding from training trajectories, not derived by construction from the inputs or via a self-citation chain that assumes the result. The randomization step and MP fitting are standard RMT tools applied without data access, and no load-bearing step reduces the central claim to a fitted parameter renamed as a prediction or to an ansatz imported from prior self-work. The procedure remains self-contained against external benchmarks such as the Marchenko-Pastur law.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Marchenko-Pastur distribution describes the eigenvalue spectrum of randomized neural network weight matrices
invented entities (1)
-
Correlation Traps
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
For each model layer, we randomize each weight matrix element-wise, W→W^rand, fit the randomized empirical spectral distribution with a Marchenko-Pastur distribution, and identify large outliers that violate self-averaging. We call these outliers Correlation Traps.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
During the onset of overfitting, which we call the 'anti-grokking' phase in long-horizon grokking, Correlation Traps form and grow in number and scale as test accuracy decreases while train accuracy remains high.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Amit, Hanoch Gutfreund, and Haim Sompolinsky
Daniel J. Amit, Hanoch Gutfreund, and Haim Sompolinsky. Spin-glass models of neural networks.Physical Review A, 32(2):1007–1018, 1985. doi: 10.1103/PhysRevA.32.1007
-
[2]
Philip W. Anderson. Absence of diffusion in certain random lattices.Physical Review, 109(5): 1492–1505, 1958. doi: 10.1103/PhysRev.109.1492
-
[3]
Jinho Baik, Gérard Ben Arous, and Sandrine Péché. Phase transition of the largest eigenvalue for nonnull complex sample covariance matrices.The Annals of Probability, 33(5):1643–1697, 2005
work page 2005
-
[4]
Siegfried Bös. Statistical mechanics approach to early stopping and weight decay.Physical Review E, 58(1):833–847, 1998. doi: 10.1103/PhysRevE.58.833
-
[5]
Plancks Gesetz und Lichtquantenhypothese.Zeitschrift für Physik, 26(1): 178–181, 1924
Satyendra Nath Bose. Plancks Gesetz und Lichtquantenhypothese.Zeitschrift für Physik, 26(1): 178–181, 1924. doi: 10.1007/BF01327326
-
[6]
Albert Einstein. Quantentheorie des einatomigen idealen Gases.Sitzungsberichte der Preussis- chen Akademie der Wissenschaften, pages 3–14, 1925
work page 1925
-
[7]
E. Gardner. The space of interactions in neural network models.Journal of Physics A: Mathematical and General, 21(1):257–270, 1988. doi: 10.1088/0305-4470/21/1/030
-
[8]
John J. Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982. doi: 10.1073/pnas.79.8.2554
-
[9]
Grokfast: Accelerated grokking by amplifying slow gradients, 2024
Jaerin Lee, Bong Gyun Kang, Kihoon Kim, and Kyoung Mu Lee. Grokfast: Accelerated grokking by amplifying slow gradients, 2024. URL https://arxiv.org/abs/2405.20233
-
[10]
Jiping Li and Rishi Sonthalia. Risk phase transitions in spiked regression: Alignment driven benign and catastrophic overfitting.arXiv preprint arXiv:2510.01414, 2025
-
[11]
Ziming Liu, Ouail Kitouni, Niklas S. Nolte, Eric J. Michaud, Max Tegmark, and Mike Williams. Towards understanding grokking: An effective theory of representation learning. InAdvances in Neural Information Processing Systems, volume 35, pages 34651–34663. Curran Associates, Inc., 2022. URLhttps://arxiv.org/abs/2205.10343
-
[12]
Marchenko and Leonid Andreevich Pastur
Vladimir A. Marchenko and Leonid Andreevich Pastur. Distribution of eigenvalues for some sets of random matrices.Matematicheskii Sbornik, 72(114)(4):507–536, 1967
work page 1967
-
[13]
Charles H. Martin. WeightWatcher: Analyze Deep Learning Models without Training or Data. https://github.com/CalculatedContent/WeightWatcher, 2018-2024. Version 0.7.5.5 used in this study. Accessed May 12, 2025
work page 2018
-
[14]
Martin and Christopher Hinrichs
Charles H. Martin and Christopher Hinrichs. SETOL: A semi-empirical theory of (deep) learning.arXiv preprint arXiv:2507.17912, 2025. URL https://arxiv.org/abs/2507. 17912
-
[15]
Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(1):165, January 2021. URL http://jmlr.org/papers/ v22/20-410.html. 10
work page 2021
-
[16]
Martin, Tian Peng, and Michael W
Charles H. Martin, Tian Peng, and Michael W. Mahoney. Predicting trends in the quality of state- of-the-art neural networks without access to training or testing data.Nature Communications, 12:4122, jul 2021. doi: 10.1038/s41467-021-24025-8. URL https://doi.org/10.1038/ s41467-021-24025-8
-
[17]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability, 2023. URL https://arxiv.org/ abs/2301.05217
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
OpenAI. Introducing gpt-oss. https://openai.com/index/introducing-gpt-oss/, Au- gust 2025. Accessed: 2026-03-28
work page 2025
-
[19]
gpt-oss-120b & gpt-oss-20b model card
OpenAI. gpt-oss-120b & gpt-oss-20b model card. https://openai.com/index/ gpt-oss-model-card/, August 2025. Accessed: 2026-03-28
work page 2025
-
[20]
C. E. Porter and R. G. Thomas. Fluctuations of nuclear reaction widths.Physical Review, 104 (2):483–491, 1956
work page 1956
-
[21]
Cambridge University Press, 2021
Marc Potters and Jean-Philippe Bouchaud.A First Course in Random Matrix Theory: F or Physi- cists, Engineers and Data Scientists. Cambridge University Press, 2021. ISBN 9781108768900
work page 2021
-
[22]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URL https://arxiv. org/abs/2201.02177
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Sebastian Seung, Haim Sompolinsky, and Naftali Tishby
H. Sebastian Seung, Haim Sompolinsky, and Naftali Tishby. Statistical mechanics of learning from examples.Physical Review A, 45(8):6056–6091, 1992. doi: 10.1103/PhysRevA.45.6056
-
[24]
Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://arxiv.org/pdf/2405.15071
-
[25]
train” curve for inferred facts test_inferredID No Main “test
Pierre Weiss. L’hypothèse du champ moléculaire et la propriété ferromagnétique.Jour- nal de Physique Théorique et Appliquée, 6(1):661–690, 1907. doi: 10.1051/jphystap: 019070060066100. 11 A Experimental Setup and Additional Notes: MLP, MA, and GPT2 A.1 MLP Experimental Setup We train a Multi-Layer Perceptron (MLP) on a subset of the MNIST dataset using th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.