Recognition: unknown
Bayesian Model Merging
Pith reviewed 2026-05-14 20:38 UTC · model grok-4.3
The pith
Bayesian Model Merging fuses task-specific models into one via inner Bayesian regression under anchor priors and outer Bayesian optimization of per-module hyperparameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bayesian Model Merging formulates model merging as a bi-level optimization in which the inner level performs activation-based Bayesian regression under a prior induced by an anchor model to obtain a closed-form merged weight solution, the outer level applies Bayesian optimization to search module-specific hyperparameters on a modest validation set, and an observed alignment between activation statistics and task vectors permits a data-free Gram-matrix estimator that removes the need for auxiliary data.
What carries the argument
Bi-level optimization with inner activation-based Bayesian regression under an anchor-model prior that yields a closed-form merged-weight solution.
Load-bearing premise
The statistical alignment between activation patterns and task vectors is tight enough to produce an accurate data-free Gram matrix, and the anchor prior yields a merged solution that generalizes without further post-hoc tuning.
What would settle it
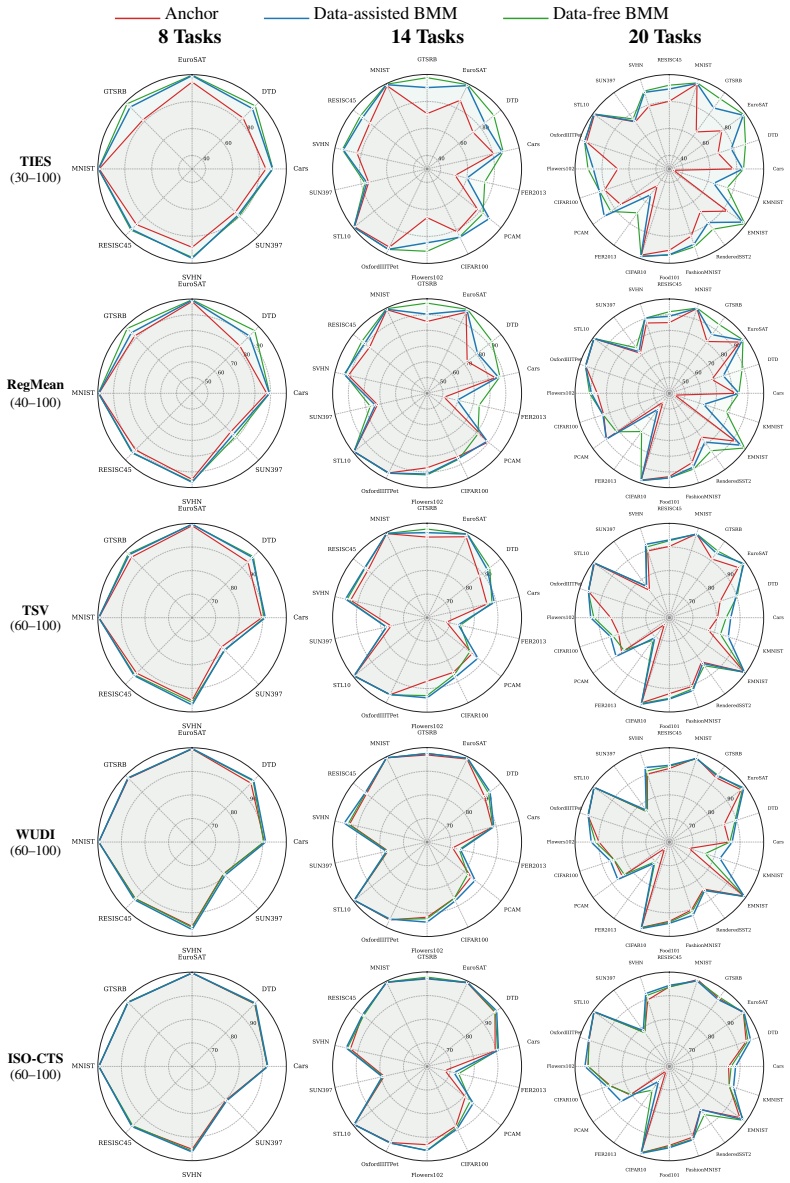
On the ViT-L/14 eight-task benchmark the data-free BMM variant falls more than two points below the expert average of 95.8 while the data-dependent version also underperforms the strongest baseline.
Figures








read the original abstract
Model merging aims to combine multiple task-specific expert models into a single model without joint retraining, offering a practical alternative to multi-task learning when data access or computational budget is limited. Existing methods, however, face two key limitations: (1) they overlook the valuable inductive bias of strong anchor models and estimate the merged weights from scratch, and (2) they rely on a shared hyperparameter setting across different modules of the network, lacking a global optimization strategy. This paper introduces Bayesian Model Merging (BMM), a plug-and-play bi-level optimization framework, where the inner level formulates the model merging as an activation-based Bayesian regression under a strong prior induced by an anchor model, yielding an efficient closed-form solution; and the outer level leverages a Bayesian optimization procedure to search module-specific hyperparameters globally based on a small validation set. Furthermore, we reveal a key alignment between activation statistics and task vectors, enabling us to derive a data-free variant of BMM that estimates the Gram matrix for regression without any auxiliary data. Across extensive benchmarks, including up to 20-task merging in vision and 5-task merging in language, BMM consistently outperforms all plug-and-play anchor baselines (e.g., TA, WUDI-Merging, and TSV). In particular, on the ViT-L/14 benchmark for 8-task merging, a single merged model reaches 95.1, closely matching the average performance of eight task-specific experts (95.8).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Bayesian Model Merging (BMM), a plug-and-play bi-level optimization framework for model merging. The inner level casts merging as activation-based Bayesian regression under an anchor-model prior, yielding a closed-form solution; the outer level performs Bayesian optimization over module-specific hyperparameters on a small validation set. A data-free variant is derived from a claimed alignment between activation statistics and task vectors that permits Gram-matrix estimation without auxiliary data. Experiments across vision (up to 20-task) and language (5-task) benchmarks report consistent outperformance over anchor baselines (TA, WUDI-Merging, TSV), with a highlighted result of 95.1 accuracy on 8-task ViT-L/14 merging versus 95.8 for the average of eight task-specific experts.
Significance. If the alignment assumption holds and the reported gains prove robust, BMM supplies a principled Bayesian treatment of model merging that exploits strong anchor priors and global hyperparameter search, addressing two stated limitations of prior plug-and-play methods. The closed-form inner solution and data-free option could be valuable in data-limited or privacy-sensitive regimes.
major comments (2)
- [Section 5 (Experiments)] The central empirical claim (e.g., 95.1 on ViT-L/14 8-task merging) is presented without error bars, exact train/validation splits, number of random seeds, or ablation studies isolating the contribution of the anchor prior versus the outer optimization; this absence directly weakens confidence in the outperformance numbers cited in the abstract and Section 5.
- [Section 3.3 (Data-free BMM)] The data-free variant rests on an unquantified alignment between activation statistics and task vectors that is asserted to enable accurate Gram-matrix recovery (Section 3.3); no correlation coefficients, layer-wise error bounds, or sensitivity analysis are supplied, leaving the approximation error of the closed-form regression solution uncharacterized.
minor comments (2)
- [Section 3.1] Notation for the Gram matrix and anchor prior could be introduced earlier with an explicit equation reference to improve readability of the inner-level derivation.
- [Abstract] The abstract states 'up to 20-task merging in vision' but does not list the precise task counts or model sizes used in each table; adding a summary table of benchmark configurations would aid comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the empirical and theoretical support in the manuscript. We address each major comment below and will incorporate the requested details and analyses in the revised version.
read point-by-point responses
-
Referee: [Section 5 (Experiments)] The central empirical claim (e.g., 95.1 on ViT-L/14 8-task merging) is presented without error bars, exact train/validation splits, number of random seeds, or ablation studies isolating the contribution of the anchor prior versus the outer optimization; this absence directly weakens confidence in the outperformance numbers cited in the abstract and Section 5.
Authors: We agree that additional statistical rigor and ablations are needed to support the central claims. In the revision we will report error bars over at least five random seeds, specify the exact train/validation splits and data partitioning procedure, and add ablation studies that separately quantify the contribution of the anchor-model prior versus the outer-level Bayesian hyperparameter optimization. These changes will directly address the concern about confidence in the reported numbers. revision: yes
-
Referee: [Section 3.3 (Data-free BMM)] The data-free variant rests on an unquantified alignment between activation statistics and task vectors that is asserted to enable accurate Gram-matrix recovery (Section 3.3); no correlation coefficients, layer-wise error bounds, or sensitivity analysis are supplied, leaving the approximation error of the closed-form regression solution uncharacterized.
Authors: We acknowledge that the alignment assumption underlying the data-free variant is currently stated without quantitative support. We will add layer-wise Pearson correlation coefficients between activation statistics and task vectors, explicit error bounds on the recovered Gram matrices, and a sensitivity analysis showing how approximation error propagates to the closed-form regression solution. These additions will characterize the reliability of the data-free variant. revision: yes
Circularity Check
Standard Bayesian regression plus held-out hyperparameter search; no reduction to fitted benchmark quantities
full rationale
The inner-level closed-form solution is the standard posterior mean of Bayesian linear regression under an anchor-induced prior; the outer level performs Bayesian optimization over module-specific hyperparameters on a small held-out validation set. Neither step is shown by the paper's equations to be algebraically identical to the final reported test metrics. The data-free Gram-matrix construction rests on an observed alignment between activation statistics and task vectors, presented as an enabling derivation rather than a parameter fitted directly to the 8-task ViT-L/14 benchmark scores. No self-citation chain or self-definitional loop is load-bearing for the central claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- module-specific hyperparameters
axioms (2)
- domain assumption Activation statistics align with task vectors
- standard math Bayesian regression under anchor-model prior admits efficient closed-form solution
Reference graph
Works this paper leans on
-
[1]
An Overview of Multi-Task Learning in Deep Neural Networks
Sebastian Ruder. An overview of multi-task learning in deep neural networks.arXiv preprint arXiv:1706.05098, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Michael S. Matena and Colin A. Raffel. Merging models with fisher-weighted averaging. Advances in Neural Information Processing Systems, 35:17703–17716, 2022
work page 2022
-
[3]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[4]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A. Raffel, and Mohit Bansal. TIES- merging: Resolving interference when merging models. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[5]
Hugging Face. The hugging face hub. https://huggingface.co, 2026. Accessed: 2026-05- 04
work page 2026
-
[6]
Dataless knowledge fusion by merging weights of language models
Xisen Jin, Xiang Ren, Daniel Preotiuc-Pietro, and Pengxiang Cheng. Dataless knowledge fusion by merging weights of language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[7]
Whoever started the interference should end it: Guiding data-free model merging via task vectors
Runxi Cheng, Feng Xiong, Yongxian Wei, Wanyun Zhu, and Chun Yuan. Whoever started the interference should end it: Guiding data-free model merging via task vectors. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 10121–10143. PMLR, 2025
work page 2025
-
[8]
Task singular vectors: Reducing task interference in model merging
Antonio Andrea Gargiulo, Donato Crisostomi, Maria Sofia Bucarelli, Simone Scardapane, Fabrizio Silvestri, and Emanuele Rodolà. Task singular vectors: Reducing task interference in model merging. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18695–18705, 2025
work page 2025
-
[9]
Bagdanov, and Joost van de Weijer
Daniel Marczak, Simone Magistri, Sebastian Cygert, Bartłomiej Twardowski, Andrew D. Bagdanov, and Joost van de Weijer. No task left behind: Isotropic model merging with common and task-specific subspaces. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 43177–43199. PMLR, 2025
work page 2025
-
[10]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 57755–57775. PMLR, 2024
work page 2024
-
[11]
Guodong Du, Junlin Lee, Jing Li, Runhua Jiang, Yifei Guo, Shuyang Yu, Hanting Liu, Sim Kuan Goh, Ho-Kin Tang, Daojing He, and Min Zhang. Parameter competition balancing for model merging.Advances in Neural Information Processing Systems, 37, 2024
work page 2024
-
[12]
Yifei He, Yuzheng Hu, Yong Lin, Tong Zhang, and Han Zhao. Localize-and-stitch: Efficient model merging via sparse task arithmetic.Transactions on Machine Learning Research, 2025. Accepted to TMLR
work page 2025
-
[13]
Modeling multi-task model merging as adaptive projective gradient descent
Yongxian Wei, Anke Tang, Li Shen, Zixuan Hu, Chun Yuan, and Xiaochun Cao. Modeling multi-task model merging as adaptive projective gradient descent. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 66178–66193. PMLR, 2025
work page 2025
-
[14]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
work page 2020
-
[15]
Adityanarayanan Radhakrishnan, Daniel Beaglehole, Parthe Pandit, and Mikhail Belkin. Mech- anism for feature learning in neural networks and kernel machines.Science, 383(6690):1461– 1467, 2024. 10
work page 2024
-
[16]
Average gradient outer product as a mechanism for deep neural collapse
Daniel Beaglehole, Peter Súkeník, Marco Mondelli, and Mikhail Belkin. Average gradient outer product as a mechanism for deep neural collapse. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[17]
Formation of representations in neural networks
Liu Ziyin, Isaac Chuang, Tomer Galanti, and Tomaso Poggio. Formation of representations in neural networks. InThe Thirteenth International Conference on Learning Representations (ICLR 2025), 2025. Spotlight
work page 2025
-
[18]
Xiao Li, Sheng Liu, Jinxin Zhou, Xinyu Lu, Carlos Fernandez-Granda, Zhihui Zhu, and Qing Qu. Understanding and improving transfer learning of deep models via neural collapse.arXiv preprint arXiv:2212.12206, 2022
-
[19]
Yuhe Ding, Bo Jiang, Lijun Sheng, Aihua Zheng, and Jian Liang. Unleashing the power of neural collapse for transferability estimation.arXiv preprint arXiv:2310.05754, 2023
-
[20]
The impact of geometric complexity on neural collapse in transfer learning
Michael Munn, Benoit Dherin, and Javier Gonzalvo. The impact of geometric complexity on neural collapse in transfer learning. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[21]
Peter I Frazier. Bayesian optimization. InRecent advances in optimization and modeling of contemporary problems, pages 255–278. Informs, 2018
work page 2018
-
[22]
Mergebench: A benchmark for merging domain-specialized llms.arXiv preprint arXiv:2505.10833, 2025
Yifei He, Siqi Zeng, Yuzheng Hu, Rui Yang, Tong Zhang, and Han Zhao. Mergebench: A benchmark for merging domain-specialized llms.arXiv preprint arXiv:2505.10833, 2025
-
[23]
Explicit inductive bias for transfer learning with convolutional networks
Xuhong Li, Yves Grandvalet, and Franck Davoine. Explicit inductive bias for transfer learning with convolutional networks. InProceedings of the 35th International Conference on Machine Learning, pages 2825–2834. PMLR, 2018
work page 2018
-
[24]
Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 7654–7663. PMLR, 2019
work page 2019
-
[25]
Jingfeng Wu, Difan Wang, and Weijie J. Su. The alignment property of SGD noise and how it helps select flat minima: A stability analysis. InAdvances in Neural Information Processing Systems, volume 35, pages 4680–4693, 2022
work page 2022
-
[26]
Optimizing neural networks with kronecker-factored approx- imate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approx- imate curvature. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 2408–2417. PMLR, 2015
work page 2015
-
[27]
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning, 2017
work page 2017
-
[28]
Being bayesian, even just a bit, fixes overconfidence in relu networks
Agustinus Kristiadi, Matthias Hein, and Philipp Hennig. Being bayesian, even just a bit, fixes overconfidence in relu networks. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5436–5446. PMLR, 2020
work page 2020
-
[29]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InICCV Workshops, 2013
work page 2013
-
[30]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InCVPR, 2014
work page 2014
-
[31]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019
work page 2019
-
[32]
The german traffic sign recognition benchmark: A multi-class classification competition
Johannes Stallkamp, Marc Schlipsing, Jan Salmen, and Christian Igel. The german traffic sign recognition benchmark: A multi-class classification competition. InIJCNN, 2011
work page 2011
-
[33]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 1998
Yann LeCun, Leon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 1998. 11
work page 1998
-
[34]
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 2017
work page 2017
-
[35]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Exploring a large collection of scene categories. InIJCV, 2016
work page 2016
-
[36]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNeurIPS Workshops, 2011
work page 2011
-
[37]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[38]
An analysis of single-layer networks in unsuper- vised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsuper- vised feature learning. InAISTATS, 2011
work page 2011
-
[39]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InICVGIP, 2008
work page 2008
-
[40]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V . Jawahar. Cats and dogs. In CVPR, 2012
work page 2012
-
[41]
Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling
Bastiaan S. Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation equivariant cnns for digital pathology. InMICCAI, 2018
work page 2018
-
[42]
Challenges in Representation Learning: A report on three machine learning contests
Ian J. Goodfellow, Dumitru Erhan, Pierre Luc Carrier, Aaron Courville, Mehdi Mirza, Ben Ham- ner, Will Cukierski, Yichuan Tang, David Thaler, Dong-Hyun Lee, et al. Challenges in represen- tation learning: A report on three machine learning contests.arXiv preprint arXiv:1307.0414, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[43]
Emnist: Extending mnist to handwritten letters
Gregory Cohen, Saeed Afshar, Jonathan Tapson, and Andre van Schaik. Emnist: Extending mnist to handwritten letters. InIJCNN, 2017
work page 2017
-
[44]
Food-101: Mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101: Mining discriminative components with random forests. InECCV, 2014
work page 2014
-
[45]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Y . Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InEMNLP, 2013
work page 2013
-
[47]
Deep Learning for Classical Japanese Literature
Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, and David Ha. Deep learning for classical japanese literature.arXiv preprint arXiv:1812.01718, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tülu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. Dart-math: Difficulty- aware rejection tuning for mathematical problem-solving.Advances in Neural Information Processing Systems, 37:7821–7846, 2024
work page 2024
-
[51]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository, 2024. 12
work page 2024
-
[52]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[53]
Shivalika Singh, Freddie Vargus, Daniel Dsouza, Börje F Karlsson, Abinaya Mahendiran, Wei- Yin Ko, Herumb Shandilya, Jay Patel, Deividas Mataciunas, Laura OMahony, et al. Aya dataset: An open-access collection for multilingual instruction tuning.arXiv preprint arXiv:2402.06619, 2024
-
[54]
Viet Lai, Chien Nguyen, Nghia Ngo, Thuat Nguyen, Franck Dernoncourt, Ryan Rossi, and Thien Nguyen. Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 318–327, 2023
work page 2023
-
[55]
Magicoder: Empow- ering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empow- ering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
-
[56]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[57]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[58]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms.arXiv preprint arXiv:2406.18495, 2024
-
[59]
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, et al. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models.Advances in Neural Information Processing Systems, 37:47094–47165, 2024
work page 2024
-
[60]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
Paul Röttger, Hannah Rose Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models.arXiv preprint arXiv:2308.01263, 2023
work page internal anchor Pith review arXiv 2023
-
[62]
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4 edition, 2013
work page 2013
-
[63]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006. 13 A Proof of Theorem 1 Let x denote an input activation to moduleW(t) and y=U (t)x= (W (t) −W pre)x the correspond- ing residual output. Using standard Stochastic Gradient Descent (SGD) with the L2 regularization, we define gy =−∇ yℓ as the back...
work page 2006
-
[64]
The expected per-sample descent matrix is aligned with the task vector: E[D(t)] =ρU (t), or equivalently,E[δ(U (t))] =0
-
[65]
At convergence, the centered descent matrix fluctuations are assumed to retain a positive Frobenius overlap with the Gram matrix of the mean descent matrix signal. That is, let D (t) =E[D (t)],C t =E h (D(t) − D (t) )⊤(D(t) − D (t) ) i ,M t = (D (t) )⊤D (t) .(18) We have cosF (Ct,M t)> α t, 0< α t ≤1 , where cosF (A,B) = Tr(A ⊤B)/(∥A∥F ∥B∥F ) is the Frobe...
-
[66]
The gradient energy factorizes from the second-moment of input activation: E ∥gy∥2 2xx⊤ =E[∥g y∥2 2]E[xx ⊤].(19) All expectations are w.r.t. the stochasticity induced by mini-batch sampling while conditioning on the fine-tuned checkpoint. Assumption 1 reflects a local quasi-stationary basin in which the mean of update-drift becomes negligible and the weig...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.