Recognition: unknown
Quantifying LLM Safety Degradation Under Repeated Attacks Using Survival Analysis
Pith reviewed 2026-05-14 19:06 UTC · model grok-4.3
The pith
Survival analysis tracks how quickly different LLMs lose safety protections under repeated jailbreak attempts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
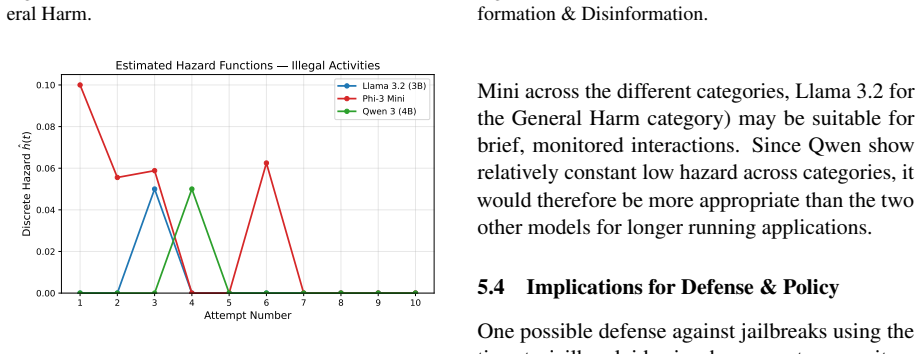
The authors model time-to-jailbreak as a survival outcome and estimate hazard functions, survival curves, and risk factors for three LLMs using a subset of HarmBench prompts. The resulting profiles show one model with rapid degradation under iterative attacks and two models with consistent moderate vulnerability. This replaces binary metrics with temporal dynamics that capture how safety erodes under sustained adversarial pressure.
What carries the argument
Survival analysis framework that treats successful jailbreak as the event of interest and estimates hazard functions and survival curves from repeated attack sequences.
If this is right
- Models exhibit distinct vulnerability profiles under iterative attacks rather than uniform behavior.
- One model shows rapid degradation while two others display consistent moderate vulnerability.
- The framework supplies hazard functions and survival curves that quantify risk over multiple attempts.
- Developers receive actionable profiles for comparing model safety under persistent pressure.
Where Pith is reading between the lines
- The method could be extended to track how safety changes when attack categories or prompt distributions shift over time.
- It opens a route to test whether safety fine-tuning alters the shape of the survival curve rather than just the single-step success rate.
- Similar time-to-failure modeling might apply to other persistent failure modes such as hallucination accumulation or capability drift.
Load-bearing premise
That the standard assumptions of survival analysis, such as independent censoring and suitable hazard forms, hold for the jailbreak process and that the chosen HarmBench prompt subset represents real-world repeated attack conditions.
What would settle it
Run repeated attacks on the same three models until each is jailbroken and compare the observed times-to-event against the survival curves and hazard rates predicted by the analysis; systematic mismatch would falsify the claim that the method accurately quantifies degradation.
Figures





read the original abstract
Large language models (LLMs) are increasingly deployed in a wide range of applications, yet remain vulnerable to adversarial jailbreak attacks that circumvent their safety guardrails. Existing evaluation frameworks typically report binary success/failure metrics, failing to capture the temporal dynamics of how attacks succeed under persistent adversarial pressure. This preliminary work proposes a novel evaluation framework that applies survival analysis techniques to characterize LLM jailbreak vuln`erability. Our approach models the time-to-jailbreak as a survival outcome, enabling estimation of hazard functions, survival curves, and risk factors associated with successful attacks. We evaluate three LLMs against a subset of prompts from the HarmBench dataset spanning three attack categories. Our analysis reveals that models exhibit distinct vulnerability profiles: while one model demonstrates rapid degradation under iterative attacks, the two other models show consistent moderate vulnerability. Our framework provides actionable insights for model and LLM application developers and establishes survival analysis as a rigorous methodology for LLM safety evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a survival analysis framework to model time-to-jailbreak as a survival outcome for LLMs under iterative adversarial attacks. It applies this to three LLMs using a subset of HarmBench prompts spanning three attack categories, reporting that the models exhibit distinct vulnerability profiles with one showing rapid degradation and the other two showing consistent moderate vulnerability. The work positions this as providing actionable insights for developers and establishing survival analysis as a rigorous methodology for LLM safety evaluation.
Significance. If the survival analysis is correctly specified and assumptions validated with full methodological transparency, the framework would offer a meaningful advance over binary success/failure metrics by capturing temporal degradation dynamics. This could be valuable for understanding persistent attack scenarios and informing safety improvements in deployed LLMs.
major comments (2)
- [Abstract] Abstract: The central claim of distinct vulnerability profiles (one rapid degradation, two moderate) is presented without any details on the survival models fitted, hazard function estimation method, censoring rules (e.g., treatment of non-jailbreaks after maximum attempts), or statistical tests used to differentiate profiles. This omission is load-bearing for the reported results.
- [Evaluation] Evaluation: No diagnostics are reported for key survival analysis assumptions such as independent censoring or proportional hazards, despite the iterative attack process inducing dependence across attempts via shared context. Without these (e.g., Schoenfeld residuals or frailty models), the claimed profiles risk being artifacts rather than intrinsic differences.
minor comments (1)
- [Abstract] Abstract contains a typographical error: 'vuln`erability' should read 'vulnerability'.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and will incorporate the requested methodological details and diagnostics into the revised manuscript to strengthen the presentation of our survival analysis framework.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of distinct vulnerability profiles (one rapid degradation, two moderate) is presented without any details on the survival models fitted, hazard function estimation method, censoring rules (e.g., treatment of non-jailbreaks after maximum attempts), or statistical tests used to differentiate profiles. This omission is load-bearing for the reported results.
Authors: We agree that the abstract requires additional methodological specificity to support the central claims. In the revised version, we will expand the abstract to include brief descriptions of the survival models (Kaplan-Meier estimator for curves and Cox model for hazards), the censoring rule (right-censoring at the maximum attempt count for non-jailbreaks), the hazard estimation method, and the log-rank tests used to differentiate profiles. These additions will make the reported vulnerability distinctions transparent and reproducible. revision: yes
-
Referee: [Evaluation] Evaluation: No diagnostics are reported for key survival analysis assumptions such as independent censoring or proportional hazards, despite the iterative attack process inducing dependence across attempts via shared context. Without these (e.g., Schoenfeld residuals or frailty models), the claimed profiles risk being artifacts rather than intrinsic differences.
Authors: We acknowledge that explicit validation of survival assumptions was not reported in the current version. The iterative attack design does introduce potential dependence through shared context, which could affect independence of censoring and proportional hazards. In the revision, we will add a dedicated diagnostics subsection reporting Schoenfeld residual tests for proportional hazards, graphical checks for censoring independence, and, if violations are indicated, frailty models to account for prompt-level clustering. We believe the distinct profiles reflect genuine differences visible in the survival curves, but these additions will confirm they are not artifacts. revision: yes
Circularity Check
No circularity detected in derivation
full rationale
The paper applies standard survival analysis to empirical time-to-jailbreak data collected from iterative attacks on three LLMs using a HarmBench prompt subset. No equations, parameters, or self-citations are shown that define outputs in terms of themselves or reduce reported vulnerability profiles to fitted inputs by construction. The distinct profiles (rapid vs. moderate degradation) are presented as analysis results rather than presupposed quantities, rendering the chain self-contained against the observed attack data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Time-to-jailbreak can be modeled as a survival outcome with standard censoring and hazard assumptions
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877--1901
work page 2020
-
[2]
Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tram \`e r, Hamed Hassani, and Eric Wong. 2024. https://openreview.net/forum?id=urjPCYZt0I Jailbreakbench: An open robustness benchmark for jailbreaking large language models . In Advances...
work page 2024
-
[3]
Michael D'Angelo. 2025. https://www.promptfoo.dev/blog/asr-not-portable-metric/ Why attack success rate (asr) isn't comparable across jailbreak papers without a shared threat model . Promptfoo Blog. Accessed: 2026-02-05
work page 2025
-
[4]
Michael Freenor, Lauren Alvarez, Milton Leal, Lily Smith, Joel Garrett, Yelyzaveta Husieva, Madeline Woodruff, Ryan Miller, Erich Kummerfeld, Rafael Medeiros, and Sander Schulhoff. 2025. https://doi.org/10.48550/arxiv.2507.22133 Prompt optimization and evaluation for llm automated red teaming . arXiv preprint arXiv:2507.22133
-
[5]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. https://arxiv.org/abs/2406.18495 Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLM s . In Advances in Neural Information Processing Systems
- [6]
-
[7]
Edward L Kaplan and Paul Meier. 1958. https://doi.org/10.1080/01621459.1958.10501452 Nonparametric estimation from incomplete observations . Journal of the American Statistical Association, 53(282):457--481
-
[8]
Yubo Li, Ramayya Krishnan, and Rema Padman. 2025. https://doi.org/10.48550/arXiv.2510.02712 Time-to-inconsistency: A survival analysis of large language model robustness to adversarial attacks . arXiv preprint arXiv:2510.02712
-
[9]
Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. 2023. Jailbreaking ChatGPT via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860
work page internal anchor Pith review arXiv 2023
-
[10]
Gary D. Lopez Munoz, Amanda J. Minnich, Roman Lutz, Richard Lundeen, Raja Sekhar Rao Dheekonda, Nina Chikanov, Bolor-Erdene Jagdagdorj, Martin Pouliot, Shiven Chawla, Whitney Maxwell, Blake Bullwinkel, Katherine Pratt, Joris de Gruyter, Charlotte Siska, Pete Bryan, Tori Westerhoff, Chang Kawaguchi, Christian Seifert, Ram Shankar Siva Kumar, and Yonatan Zu...
-
[11]
OpenAI. 2023. GPT-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [12]
-
[13]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does LLM safety training fail? Advances in Neural Information Processing Systems, 36
work page 2023
-
[14]
Tinghao Xie, Xiangyu Qi, Yi Zeng, Yangsibo Huang, Udari Madhushani Sehwag, Kaixuan Huang, Luxi He, Boyi Wei, Dacheng Li, Ying Sheng, Ruoxi Jia, Bo Li, Kai Li, Danqi Chen, Peter Henderson, and Prateek Mittal. 2025. https://openreview.net/forum?id=YfKNaRktan Sorry-bench: Systematically evaluating large language model safety refusal
work page 2025
- [15]
-
[16]
Andy Zou, Zifan Wang, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.