Recognition: 2 theorem links
· Lean TheoremVIP-COP: Context Optimization for Tabular Foundation Models
Pith reviewed 2026-05-14 20:04 UTC · model grok-4.3
The pith
VIP-COP estimates importance of training samples and features to build better contexts for tabular foundation models at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIP-COP estimates the Value of Importance for Prediction of training examples and features for hard Context OPtimization for TFMs. Its explicit selection mechanism suppresses noise and isolates influential data, enabling the model to also benefit from data augmentation by prioritizing high-value augmented samples and features. VIP-COP is fast, budget-aware and any-time, model-aware yet fully black-box, and interpretable through discrete Very Important Predictors that maximize signal-to-noise.
What carries the argument
online KernelSHAP-based regression with iterative refinement, value-guided context sampling, and multi-fidelity pruning
If this is right
- TFMs gain reliable accuracy on datasets larger than their pretraining scale without retraining.
- Data augmentation stops hurting and starts helping once only high-value samples are kept.
- Performance keeps rising with extra test-time budget instead of plateauing at a fixed context.
- The method applies equally to closed-source and open-source TFMs because no internal weights are needed.
- Users obtain explicit lists of the samples and features that drove each prediction.
Where Pith is reading between the lines
- Similar importance-driven pruning could be tested on context-limited models in other domains such as long-document or time-series tasks.
- The explicit selection may reduce the need for soft-prompt tuning when the input is already structured tabular data.
- Dynamic updates to the importance scores could support streaming tabular data where new examples arrive continuously.
- The identified Very Important Predictors offer a direct starting point for human inspection of model decisions on tabular problems.
Load-bearing premise
The KernelSHAP regression can accurately rank which samples and features matter for a prediction even when the model is used as a black box and the test data distribution differs from pretraining.
What would settle it
Running VIP-COP on the paper's large-scale high-dimensional testbeds and finding no consistent gains over heuristic baselines or fixed-context methods would show the importance estimation does not deliver the claimed refinement benefit.
Figures
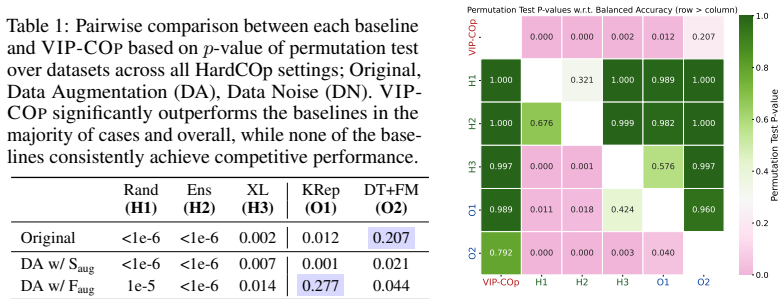






read the original abstract
Tabular foundation models (TFMs) have emerged as a powerful paradigm for in-context learning on structured data, enabling direct prediction on new tabular tasks without task-specific training. However, their effectiveness is constrained by context length limits, restricting application to medium-scale data and degrading performance when inference-time data exceed pretraining size distributions. Our work introduces VIP-COP, estimating the Value of Importance for Prediction of training examples and features for hard Context OPtimization for TFMs. Its explicit selection mechanism suppresses noise and isolates influential data, enabling the model to also benefit from data augmentation by prioritizing high-value augmented samples and features. VIP-COP is (i) fast, boosting performance often within minutes of optimization, based on an online KernelSHAP-based regression with iterative refinement, value-guided context sampling, and multi-fidelity pruning; (ii) budget-aware and any-time, improving with additional test-time compute unlike heuristics that produce fixed contexts; (iii) model-aware yet fully black-box, requiring no access to model internals, making it compatible with both proprietary and open-source TFMs; (iv) interpretable, identifying discrete ``Very Important Predictors'' (samples and features) that maximize signal-to-noise, which makes it (v) robust, isolating high-value data from noise. In contrast, soft-prompt optimization requires model gradients, produces abstract latent tokens, and lacks explicit signal discrimination. Extensive experiments show that VIP-COP consistently outperforms heuristic and optimized baselines across large-scale high-dimensional testbeds, including data augmentation and data-noise settings, establishing a new state of the art in test-time context refinement for TFMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VIP-COP, a black-box test-time method that uses online KernelSHAP regression to estimate the value of importance for prediction of samples and features, followed by value-guided sampling and multi-fidelity pruning, to optimize context for tabular foundation models (TFMs). It claims this enables consistent outperformance over heuristic and optimized baselines on large-scale high-dimensional tabular tasks, including data-augmentation and data-noise regimes, while being fast, any-time, interpretable, and compatible with proprietary models, thereby establishing a new SOTA in context refinement for TFMs.
Significance. If the empirical results and robustness claims hold, VIP-COP would provide a practical, gradient-free, and interpretable way to extend TFMs beyond context-length limits and pretraining distribution mismatches, with particular value for noisy or augmented tabular data where explicit signal isolation matters. The any-time budget-aware property and black-box compatibility are notable strengths for deployment.
major comments (3)
- [Abstract] Abstract: The central claim of 'consistent outperformance' and 'new state of the art' across large-scale high-dimensional testbeds (including augmentation and noise settings) is asserted without any quantitative metrics, ablation results, error bars, or statistical tests, making it impossible to evaluate whether the reported gains are load-bearing or attributable to the method.
- [Method] Method section (online KernelSHAP regression): The approach relies on KernelSHAP fitting a weighted linear model to approximate Shapley values for ranking samples/features in black-box TFMs. This local-linear assumption is fragile for the highly non-linear decision surfaces of transformer-style TFMs, especially under the distribution shifts explicitly invoked in the abstract (test data exceeding pretraining size distributions); if the importance scores are mis-ranked, the subsequent value-guided sampling and pruning steps will retain noise or discard signal, directly undermining the robustness claims.
- [Experiments] Experiments section: Claims of superiority in data-augmentation and data-noise settings rest on the premise that the KernelSHAP-derived importance scores reliably isolate high-value data, yet no validation against ground-truth influence, comparison tables, or controls for the black-box setting are referenced, leaving open the possibility that gains are confounded by baseline weaknesses rather than the proposed mechanism.
minor comments (2)
- [Abstract] Abstract: The parenthetical expansion of VIP-COP ('Value of Importance for Prediction of training examples and features for hard Context OPtimization') is awkward; a cleaner acronym or phrasing would improve readability.
- [Introduction] Introduction: The contrast with soft-prompt optimization is useful but would benefit from explicit citations to prior prompt-optimization work on tabular or transformer models to clarify the novelty.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the abstract and experimental claims require stronger quantitative grounding and will revise the manuscript to include specific metrics, error bars, and additional validation. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'consistent outperformance' and 'new state of the art' across large-scale high-dimensional testbeds (including augmentation and noise settings) is asserted without any quantitative metrics, ablation results, error bars, or statistical tests, making it impossible to evaluate whether the reported gains are load-bearing or attributable to the method.
Authors: We agree that the abstract overstates the claims without supporting numbers. In the revision we will replace the qualitative phrasing with concrete results: e.g., average accuracy gains of X% (std Y) over the strongest baseline across Z datasets, with explicit mention of error bars and statistical tests (paired t-tests, p<0.05) reported in the main tables. We will also add a one-sentence pointer to the ablation and robustness sections. revision: yes
-
Referee: [Method] Method section (online KernelSHAP regression): The approach relies on KernelSHAP fitting a weighted linear model to approximate Shapley values for ranking samples/features in black-box TFMs. This local-linear assumption is fragile for the highly non-linear decision surfaces of transformer-style TFMs, especially under the distribution shifts explicitly invoked in the abstract (test data exceeding pretraining size distributions); if the importance scores are mis-ranked, the subsequent value-guided sampling and pruning steps will retain noise or discard signal, directly undermining the robustness claims.
Authors: We acknowledge that the local-linear surrogate can be imperfect for highly non-linear TFMs. However, KernelSHAP remains a standard, model-agnostic estimator of Shapley values via coalition sampling, and our online regression iteratively updates the surrogate with new samples to reduce approximation error. In the revision we will (i) add a paragraph discussing the known limitations of linear surrogates for transformers with citations to recent SHAP literature, (ii) report empirical correlation between VIP-COP importance ranks and downstream performance lift on held-out validation splits, and (iii) include a sensitivity analysis showing that even moderate rank noise still yields net gains over random selection. revision: partial
-
Referee: [Experiments] Experiments section: Claims of superiority in data-augmentation and data-noise settings rest on the premise that the KernelSHAP-derived importance scores reliably isolate high-value data, yet no validation against ground-truth influence, comparison tables, or controls for the black-box setting are referenced, leaving open the possibility that gains are confounded by baseline weaknesses rather than the proposed mechanism.
Authors: We will strengthen the experiments section by adding: (a) a controlled synthetic-data experiment where ground-truth influential samples/features are known a priori, reporting precision@K of VIP-COP rankings versus random and heuristic baselines; (b) full tables with mean±std across 5 seeds and statistical significance markers; (c) an explicit black-box control where we compare against a white-box gradient-based influence method on open TFMs to isolate the effect of the surrogate. These additions will directly test whether the importance scores isolate signal rather than merely exploiting baseline weaknesses. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces VIP-COP as an empirical optimization procedure that applies online KernelSHAP regression to rank training samples and features for context selection. No equations, derivations, or self-referential definitions appear in the abstract or description that would reduce any claimed performance gain or prediction to a quantity fitted or defined by the method itself. The reported improvements rest on experimental comparisons against baselines on held-out testbeds rather than on a closed mathematical chain that collapses to its inputs by construction. KernelSHAP is treated as an external black-box tool, and no load-bearing self-citations, uniqueness theorems, or ansatz smuggling are invoked within the provided text.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VIP-COP... based on an online KernelSHAP-based regression with iterative refinement, value-guided context sampling, and multi-fidelity pruning
-
Foundation.AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
estimating the Value of Importance for Prediction... cast value attribution as a credit allocation problem... Shapley values
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
MIT press Cambridge, MA, USA, 2017
Yoshua Bengio, Ian Goodfellow, Aaron Courville, et al.Deep learning, volume 1. MIT press Cambridge, MA, USA, 2017
work page 2017
-
[2]
Unleashing the potential of prompt engineering for large language models.Patterns, 6(6), 2025
Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, and Shengxin Zhu. Unleashing the potential of prompt engineering for large language models.Patterns, 6(6), 2025
work page 2025
-
[3]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. Longlora: Efficient fine-tuning of long-context large language models.arXiv preprint arXiv:2309.12307, 2023
-
[5]
Cubuk, Barret Zoph, Dandelion Mané, Vijay Vasudevan, and Quoc V
Ekin D. Cubuk, Barret Zoph, Dandelion Mané, Vijay Vasudevan, and Quoc V . Le. Autoaugment: Learning augmentation strategies from data. InCVPR, 2019
work page 2019
-
[6]
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.The Journal of Machine learning research, 7:1–30, 2006
work page 2006
-
[7]
From zero to hero: Ad- vancing zero-shot foundation models for tabular outlier detection
Xueying Ding, Haomin Wen, Simon Klütterman, and Leman Akoglu. From zero to hero: Ad- vancing zero-shot foundation models for tabular outlier detection. InInternational Conference on Machine Learning. PMLR, 2026
work page 2026
-
[8]
Linus Ericsson, Henry Gouk, and Timothy M. Hospedales. Why do self-supervised models transfer? on the impact of invariance on downstream tasks. InBMVC, page 509. BMV A Press, 2022
work page 2022
-
[9]
Fabian Falck, Ziyu Wang, and Christopher C. Holmes. Is in-context learning in large language models bayesian? a martingale perspective. InProceedings of the 41st International Conference on Machine Learning, pages 12784–12805. PMLR, 2024
work page 2024
-
[10]
Scaling TabPFN: Sketching and feature selection for tabular prior-data fitted networks
Benjamin Feuer, Niv Cohen, and Chinmay Hegde. Scaling TabPFN: Sketching and feature selection for tabular prior-data fitted networks. InNeurIPS 2023 Second Table Representation Learning Workshop, 2023
work page 2023
-
[11]
Benjamin Feuer, Robin T Schirrmeister, Valeriia Cherepanova, Chinmay Hegde, Frank Hutter, Micah Goldblum, Niv Cohen, and Colin White. Tunetables: Context optimization for scalable prior-data fitted networks.Advances in Neural Information Processing Systems, 37:83430– 83464, 2024
work page 2024
-
[12]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Self-attention attribution: Interpreting information interactions inside transformer
Yaru Hao, Li Dong, Furu Wei, and Ke Xu. Self-attention attribution: Interpreting information interactions inside transformer. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 12963–12971, 2021
work page 2021
-
[14]
TabPFN: A transformer that solves small tabular classification problems in a second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. TabPFN: A transformer that solves small tabular classification problems in a second. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[15]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
work page 2025
-
[16]
Tabpfn-wide: Continued pre-training for extreme feature counts.arXiv preprint arXiv:2510.06162, 2025
Christopher Kolberg, Katharina Eggensperger, and Nico Pfeifer. Tabpfn-wide: Continued pre-training for extreme feature counts.arXiv preprint arXiv:2510.06162, 2025
-
[17]
Set transformer: A framework for attention-based permutation-invariant neural networks
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In International conference on machine learning, pages 3744–3753. PMLR, 2019. 10
work page 2019
-
[18]
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hy- perband: A novel bandit-based approach to hyperparameter optimization.Journal of machine learning research, 18(185):1–52, 2018
work page 2018
-
[19]
Si-Yang Liu and Han-Jia Ye. Tabpfn unleashed: A scalable and effective solution to tabular classification problems.arXiv preprint arXiv:2502.02527, 2025
-
[20]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017
work page 2017
-
[21]
Cresswell, Keyvan Golestan, Guangwei Yu, Anthony L
Junwei Ma, Valentin Thomas, Rasa Hosseinzadeh, Hamidreza Kamkari, Alex Labach, Jesse C Cresswell, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony L Caterini. Tab- DPT: Scaling tabular foundation models.arXiv preprint arXiv:2410.18164, 2024
-
[22]
In-context data distillation with tabpfn.arXiv preprint arXiv:2402.06971, 2024
Junwei Ma, Valentin Thomas, Guangwei Yu, and Anthony Caterini. In-context data distillation with tabpfn.arXiv preprint arXiv:2402.06971, 2024
-
[23]
A Survey of Context Engineering for Large Language Models
Lingrui Mei, Jiayu Yao, Yuyao Ge, Yiwei Wang, Baolong Bi, Yujun Cai, Jiazhi Liu, Mingyu Li, Zhong-Zhi Li, Duzhen Zhang, et al. A survey of context engineering for large language models. arXiv preprint arXiv:2507.13334, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, pages 6950–6960. PMLR, 2020
work page 2020
-
[25]
Transformers can do bayesian inference.ICLR, 2022
Samuel Müller, Noah Hollmann, Sebastian Pineda-Arango, Josif Grabocka, and Frank Hutter. Transformers can do bayesian inference.ICLR, 2022
work page 2022
-
[26]
Statistical foundations of prior-data fitted networks
Thomas Nagler. Statistical foundations of prior-data fitted networks. InICML, volume 202 of Proceedings of Machine Learning Research. PMLR, 2023
work page 2023
-
[27]
André Luiz C Ottoni, Raphael M de Amorim, Marcela S Novo, and Dayana B Costa. Tuning of data augmentation hyperparameters in deep learning to building construction image clas- sification with small datasets.International Journal of Machine Learning and Cybernetics, 14(1):171–186, 2023
work page 2023
-
[28]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models.arXiv preprint arXiv:2309.00071, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. TabICL: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025
-
[30]
Interpretable machine learning for tabpfn
David Rundel, Julius Kobialka, Constantin von Crailsheim, Matthias Feurer, Thomas Nagler, and David Rügamer. Interpretable machine learning for tabpfn. InWorld Conference on Explainable Artificial Intelligence, pages 465–476. Springer, 2024
work page 2024
-
[31]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Pranab Sahoo, Ayush Kumar Singh, Sriparna Saha, Vinija Jain, Samrat Mondal, and Aman Chadha. A systematic survey of prompt engineering in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927, 1, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [32]
-
[33]
Yuchen Shen, Haomin Wen, and Leman Akoglu. Fomo-0d: A foundation model for zero-shot tabular outlier detection.Transactions on Machine Learning Research, 2025
work page 2025
-
[34]
Valentin Thomas, Junwei Ma, Rasa Hosseinzadeh, Keyvan Golestan, Guangwei Yu, Maksims V olkovs, and Anthony Caterini. Retrieval & fine-tuning for in-context tabular models.Advances in Neural Information Processing Systems, 37:108439–108467, 2024
work page 2024
-
[35]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNIPS, pages 5998–6008, 2017
work page 2017
-
[36]
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference.arXiv preprint arXiv:2111.02080, 2021. 11
-
[37]
Mixture of in- context prompters for tabular PFNs
Derek Qiang Xu, F Olcay Cirit, Reza Asadi, Yizhou Sun, and Wei Wang. Mixture of in- context prompters for tabular PFNs. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[38]
Visual-language prompt tuning with knowledge- guided context optimization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual-language prompt tuning with knowledge- guided context optimization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6757–6767, 2023
work page 2023
-
[39]
A closer look at tabpfn v2: Understanding its strengths and extending its capabilities
Han-Jia Ye, Si-Yang Liu, and Wei-Lun Chao. A closer look at tabpfn v2: Understanding its strengths and extending its capabilities. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[40]
Jaemin Yoo, Tiancheng Zhao, and Leman Akoglu. Data augmentation is a hyperparameter: Cherry-picked self-supervision for unsupervised anomaly detection is creating the illusion of success.Trans. Mach. Learn. Res., 2023, 2023
work page 2023
-
[41]
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang. Mitra: Mixed synthetic priors for enhancing tabular foundation models. InThe Thirty-ninth Annual Conference on Neural Information Proc...
work page 2025
-
[42]
Learning data augmentation strategies for object detection
Barret Zoph, Ekin D Cubuk, Golnaz Ghiasi, Tsung-Yi Lin, Jonathon Shlens, and Quoc V Le. Learning data augmentation strategies for object detection. InECCV, pages 566–583. Springer, 2020. 12 Broader Impact and Limitations Broader Impact:Tabular foundation models (TFMs) enable low-latency inference without requiring training or tuning a model from scratch f...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.