Recognition: 2 theorem links
· Lean TheoremReducing Bias and Variance: Generative Semantic Guidance and Bi-Layer Ensemble for Image Clustering
Pith reviewed 2026-05-14 19:29 UTC · model grok-4.3
The pith
GSEC generates adaptive semantic descriptions with multimodal LLMs and applies a bi-layer ensemble to reduce both bias and variance in image clustering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
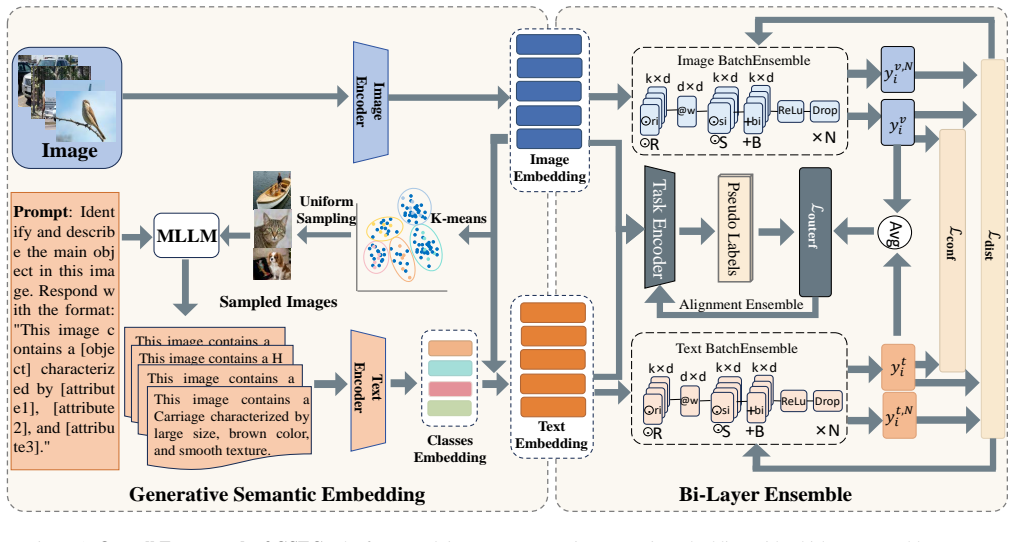
Generative semantic guidance from multimodal LLMs produces task-adaptive descriptions whose weighted-average embeddings reduce bias relative to vocabulary-matching baselines, while the bi-layer ensemble integrates cross-modal signals internally via BatchEnsemble and aligns outputs externally to reduce variance, yielding higher clustering accuracy on standard image datasets.
What carries the argument
Generative semantic guidance that converts LLM-produced descriptions into weighted-average embeddings, paired with a bi-layer ensemble that applies BatchEnsemble internally and output alignment externally.
If this is right
- Clustering performance improves on diverse unlabeled image collections without reliance on fixed vocabularies.
- Bias arising from limited matching spaces is lowered by replacing retrieval with generative priors.
- Variance is controlled separately through internal cross-modal fusion and external output alignment.
- The same accuracy gains appear consistently across six standard benchmarks against eighteen prior techniques.
Where Pith is reading between the lines
- The separation of bias reduction via generative priors and variance reduction via layered ensembles could be tested on other unsupervised tasks such as anomaly detection or representation learning.
- Replacing the current multimodal LLMs with stronger future models would be expected to further improve the quality of the generated priors and the resulting embeddings.
- The bi-layer structure offers a template for designing ensembles that target bias and variance independently in other clustering pipelines.
- In practice the method could support large-scale image organization where manual labels are unavailable and semantic adaptability matters.
Load-bearing premise
Semantic descriptions produced by current multimodal LLMs supply unbiased, task-adaptive prior knowledge that improves clustering more reliably than matching against predefined vocabularies, and the bi-layer ensemble reduces variance without introducing new systematic errors.
What would settle it
On any of the six benchmarks, removing either the generative description step or one of the two ensemble layers and re-running the comparison should cause accuracy to drop to or below the level of the eighteen baseline methods.
Figures






read the original abstract
Image clustering aims to partition unlabeled image datasets into distinct groups. A core aspect of this task is constructing and leveraging prior knowledge to guide the clustering process. Recent approaches introduce semantic descriptions as prior information, most of which typically relying on matching-based techniques with predefined vocabularies. However, the limited matching space restricts their adaptability to downstream clustering tasks. Moreover, these methods primarily focus on reducing bias to improve performance, frequently overlooking the importance of variance reduction. To address these limitations, we propose GSEC (Image Clustering based on Generative Semantic Guidance and Bi-Layer Ensemble), a framework designed to reduce bias through generative semantic guidance and mitigate variance via ensemble learning. Our method employs Multimodal Large Language Models to generate semantic descriptions and derive image embeddings via weighted averaging. Additionally, a bi-layer ensemble strategy integrates cross-modal information through BatchEnsemble in the inner layer and aligns outputs via an alignment mechanism in the outer layer. Comparative experiments demonstrate that GSEC outperforms 18 state-of-the-art methods across six benchmark datasets, while further analysis confirms its effectiveness in simultaneously reducing both bias and variance. The code is available at https://github.com/2017LI/GSEC.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GSEC, a framework for unsupervised image clustering that generates semantic descriptions via Multimodal Large Language Models (MLLMs), derives image embeddings through weighted averaging, and applies a bi-layer ensemble (BatchEnsemble in the inner layer for cross-modal integration and an alignment mechanism in the outer layer) to simultaneously reduce bias and variance. It reports outperformance over 18 state-of-the-art methods on six benchmark datasets, with additional analysis claimed to confirm the bias-variance reductions; code is released at a public GitHub repository.
Significance. If the bias and variance reductions are shown via clearly defined, label-independent proxies with statistical rigor and the performance gains are reproducible, the integration of generative MLLM priors with bi-layer ensembles could meaningfully advance image clustering methods that currently rely on fixed vocabularies. The public code release is a clear strength for reproducibility and follow-up work.
major comments (2)
- [Abstract] Abstract: the central claim that 'further analysis confirms its effectiveness in simultaneously reducing both bias and variance' is load-bearing yet unsupported by any description of the quantification procedure. In an unsupervised clustering setting, standard supervised bias-variance decomposition does not apply; the manuscript must specify the exact proxy (e.g., deviation from ground-truth partitions, intra-cluster dispersion, or ensemble disagreement) and demonstrate that the proxy itself is not introduced by the bi-layer alignment or MLLM semantics.
- [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the claim of outperformance across six benchmarks and 18 SOTA methods provides no details on data splits, error bars, number of runs, or statistical significance tests. Without these, the empirical superiority cannot be assessed as robust rather than an artifact of a single split or evaluation protocol.
minor comments (2)
- [Abstract] Abstract: the description of the bi-layer ensemble is too terse; explicitly define the BatchEnsemble inner-layer operation and the outer-layer alignment mechanism, including any hyperparameters or loss terms.
- The assumption that MLLM-generated semantics supply lower-bias priors than vocabulary matching should be supported by a quantitative ablation (e.g., hallucination rate or direct comparison to fixed-vocabulary baselines) rather than left as a qualitative motivation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'further analysis confirms its effectiveness in simultaneously reducing both bias and variance' is load-bearing yet unsupported by any description of the quantification procedure. In an unsupervised clustering setting, standard supervised bias-variance decomposition does not apply; the manuscript must specify the exact proxy (e.g., deviation from ground-truth partitions, intra-cluster dispersion, or ensemble disagreement) and demonstrate that the proxy itself is not introduced by the bi-layer alignment or MLLM semantics.
Authors: We agree the abstract claim requires explicit support. In Section 4 we quantify bias via intra-cluster dispersion (mean embedding distance to assigned centroid) and variance via disagreement in cluster assignments across the bi-layer ensemble members; both proxies are label-independent. We will revise the abstract to name these proxies and add ablation experiments in the revised Section 4 that isolate each component (MLLM guidance and bi-layer alignment) to show the observed reductions are not artifacts of the method itself. revision: yes
-
Referee: [Abstract and §4 (Experiments)] Abstract and §4 (Experiments): the claim of outperformance across six benchmarks and 18 SOTA methods provides no details on data splits, error bars, number of runs, or statistical significance tests. Without these, the empirical superiority cannot be assessed as robust rather than an artifact of a single split or evaluation protocol.
Authors: We agree these details must be stated explicitly. Experiments were averaged over five independent runs with distinct random seeds; standard benchmark partitions were used for all datasets; results include mean and standard deviation; paired t-tests (p < 0.05) were performed against baselines. We will update the abstract to mention multi-run averaging and add a dedicated experimental-protocol subsection in §4 that reports splits, run count, error bars, and significance tests. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks and standard components
full rationale
The paper's core method combines publicly available MLLMs for semantic generation with a bi-layer ensemble using BatchEnsemble and alignment. Performance is evaluated via comparative experiments on six external benchmark datasets against 18 prior methods. No derivation step reduces by construction to fitted parameters from the same data, no self-citation chain is load-bearing for the central claim, and bias/variance reduction is asserted via further analysis without redefining quantities in terms of the method's own outputs. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- weights for semantic embedding averaging
axioms (1)
- domain assumption Multimodal large language models can generate semantic descriptions that serve as effective prior knowledge for downstream image clustering tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GSEC ... reduce bias through generative semantic guidance and mitigate variance via ensemble learning. ... bi-layer ensemble strategy integrates cross-modal information through BatchEnsemble ... alignment mechanism
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bias is defined as the average deviation ... variance quantifies the dispersion across predictions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Food-101–mining discriminative com- ponents with random forests
[Bossardet al., 2014 ] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative com- ponents with random forests. InEuropean conference on computer vision, pages 446–461. Springer,
2014
-
[2]
Bagging predictors.Machine learning, 24(2):123–140,
[Breiman, 1996] Leo Breiman. Bagging predictors.Machine learning, 24(2):123–140,
1996
-
[3]
Random forests.Machine learning, 45(1):5–32,
[Breiman, 2001] Leo Breiman. Random forests.Machine learning, 45(1):5–32,
2001
-
[4]
Semantic-enhanced im- age clustering
[Caiet al., 2023 ] Shaotian Cai, Liping Qiu, Xiaojun Chen, Qin Zhang, and Longteng Chen. Semantic-enhanced im- age clustering. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 6869–6878,
2023
-
[5]
Deep clustering for unsupervised learning of visual features
[Caronet al., 2018 ] Mathilde Caron, Piotr Bojanowski, Ar- mand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. InProceedings of the European conference on computer vision (ECCV), pages 132–149,
2018
-
[6]
Deep adaptive image clustering
[Changet al., 2017 ] Jianlong Chang, Lingfeng Wang, Gaofeng Meng, Shiming Xiang, and Chunhong Pan. Deep adaptive image clustering. InProceedings of the IEEE international conference on computer vision, pages 5879–5887,
2017
-
[7]
An analysis of single-layer networks in unsupervised feature learning
[Coateset al., 2011 ] Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. InProceedings of the fourteenth international conference on artificial intelli- gence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings,
2011
-
[8]
Performance guaran- tees for hierarchical clustering
[Dasgupta, 2002] Sanjoy Dasgupta. Performance guaran- tees for hierarchical clustering. InInternational Confer- ence on Computational Learning Theory, pages 351–363. Springer,
2002
-
[9]
Imagenet: A large-scale hierarchical image database
[Denget al., 2009 ] Jia Deng, Wei Dong, Richard Socher, Li- Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee,
2009
-
[10]
Ensemble methods in machine learning
[Dietterich, 2000] Thomas G Dietterich. Ensemble methods in machine learning. InInternational workshop on multi- ple classifier systems, pages 1–15. Springer,
2000
-
[11]
Clustering by maximizing mutual information across views
[Doet al., 2021 ] Kien Do, Truyen Tran, and Svetha Venkatesh. Clustering by maximizing mutual information across views. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 9928–9938,
2021
-
[12]
Zero-shot out-of-distribution detection based on the pre-trained model clip
[Esmaeilpouret al., 2022 ] Sepideh Esmaeilpour, Bing Liu, Eric Robertson, and Lei Shu. Zero-shot out-of-distribution detection based on the pre-trained model clip. InProceed- ings of the AAAI conference on artificial intelligence, vol- ume 36, pages 6568–6576,
2022
-
[13]
A density-based algorithm for discovering clusters in large spatial databases with noise
[Esteret al., 1996 ] Martin Ester, Hans-Peter Kriegel, J ¨org Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, volume 96, pages 226–231,
1996
-
[14]
A decision-theoretic generalization of on-line learning and an application to boosting.Journal of com- puter and system sciences, 55(1):119–139,
[Freund and Schapire, 1997] Yoav Freund and Robert E Schapire. A decision-theoretic generalization of on-line learning and an application to boosting.Journal of com- puter and system sciences, 55(1):119–139,
1997
-
[15]
Deep semantic clustering by partition confidence maximisation
[Huanget al., 2020 ] Jiabo Huang, Shaogang Gong, and Xia- tian Zhu. Deep semantic clustering by partition confidence maximisation. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 8849–8858,
2020
-
[16]
Invariant information clustering for unsupervised image classification and segmentation
[Jiet al., 2019 ] Xu Ji, Joao F Henriques, and Andrea Vedaldi. Invariant information clustering for unsupervised image classification and segmentation. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 9865–9874,
2019
-
[17]
3d object representations for fine- grained categorization
[Krauseet al., 2013 ] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE inter- national conference on computer vision workshops, pages 554–561,
2013
-
[18]
Learning multiple layers of features from tiny im- ages
[Krizhevskyet al., 2009 ] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny im- ages
2009
-
[19]
Image clustering with external guidance.arXiv preprint arXiv:2310.11989,
[Liet al., 2023b ] Yunfan Li, Peng Hu, Dezhong Peng, Jiancheng Lv, Jianping Fan, and Xi Peng. Image clustering with external guidance.arXiv preprint arXiv:2310.11989,
-
[20]
Fine-Grained Visual Classification of Aircraft
[Majiet al., 2013 ] Subhransu Maji, Esa Rahtu, Juho Kan- nala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
Some methods of classification and analysis of multivariate observations
[McQueen, 1967] James B McQueen. Some methods of classification and analysis of multivariate observations. In Proc. of 5th Berkeley Symposium on Math. Stat. and Prob., pages 281–297,
1967
-
[22]
Divclust: Control- ling diversity in deep clustering
[Metaxaset al., 2023 ] Ioannis Maniadis Metaxas, Georgios Tzimiropoulos, and Ioannis Patras. Divclust: Control- ling diversity in deep clustering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3418–3428,
2023
-
[23]
Clustergan: La- tent space clustering in generative adversarial networks
[Mukherjeeet al., 2019 ] Sudipto Mukherjee, Himanshu As- nani, Eugene Lin, and Sreeram Kannan. Clustergan: La- tent space clustering in generative adversarial networks. InProceedings of the AAAI conference on artificial intel- ligence, volume 33, pages 4610–4617,
2019
-
[24]
Spice: Semantic pseudo-labeling for image clustering.IEEE Transactions on Image Processing, 31:7264–7278,
[Niuet al., 2022 ] Chuang Niu, Hongming Shan, and Ge Wang. Spice: Semantic pseudo-labeling for image clustering.IEEE Transactions on Image Processing, 31:7264–7278,
2022
-
[25]
Cats and dogs
[Parkhiet al., 2012 ] Omkar M Parkhi, Andrea Vedaldi, An- drew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recogni- tion, pages 3498–3505. IEEE,
2012
-
[26]
On the provable importance of gradients for autonomous language-assisted image clustering
[Penget al., 2025 ] Bo Peng, Jie Lu, Guangquan Zhang, and Zhen Fang. On the provable importance of gradients for autonomous language-assisted image clustering. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 19805–19815,
2025
-
[27]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
2021
-
[28]
Deep clustering: A comprehensive survey.IEEE transactions on neural networks and learning systems, 36(4):5858–5878,
[Renet al., 2024 ] Yazhou Ren, Jingyu Pu, Zhimeng Yang, Jie Xu, Guofeng Li, Xiaorong Pu, Philip S Yu, and Li- fang He. Deep clustering: A comprehensive survey.IEEE transactions on neural networks and learning systems, 36(4):5858–5878,
2024
-
[29]
You never cluster alone.Advances in Neural Information Processing Systems, 34:27734–27746,
[Shenet al., 2021 ] Yuming Shen, Ziyi Shen, Menghan Wang, Jie Qin, Philip Torr, and Ling Shao. You never cluster alone.Advances in Neural Information Processing Systems, 34:27734–27746,
2021
-
[30]
[Taoet al., 2021 ] Yaling Tao, Kentaro Takagi, and Kouta Nakata. Clustering-friendly representation learning via instance discrimination and feature decorrelation.arXiv preprint arXiv:2106.00131,
-
[31]
Scan: Learning to classify images without labels
[Van Gansbekeet al., 2020 ] Wouter Van Gansbeke, Simon Vandenhende, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. Scan: Learning to classify images without labels. InEuropean conference on computer vi- sion, pages 268–285. Springer,
2020
-
[32]
Generalization perfor- mance of pure accuracy and its application in selective en- semble learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1798–1816,
[Wanget al., 2022 ] Jieting Wang, Yuhua Qian, Feijiang Li, Jiye Liang, and Qingfu Zhang. Generalization perfor- mance of pure accuracy and its application in selective en- semble learning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1798–1816,
2022
-
[33]
Text-guided domain adaptation via deep manifold constraints and neighborhood propagation
[Wanget al., 2026 ] Jieting Wang, Yue Sun, Feijiang Li, and Huimei Shi. Text-guided domain adaptation via deep manifold constraints and neighborhood propagation. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2586–2590. IEEE,
2026
-
[34]
[Wenet al., 2020 ] Yeming Wen, Dustin Tran, and Jimmy Ba. Batchensemble: an alternative approach to effi- cient ensemble and lifelong learning.arXiv preprint arXiv:2002.06715,
-
[35]
Deep comprehensive correlation mining for image clustering
[Wuet al., 2019 ] Jianlong Wu, Keyu Long, Fei Wang, Chen Qian, Cheng Li, Zhouchen Lin, and Hongbin Zha. Deep comprehensive correlation mining for image clustering. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8150–8159,
2019
-
[36]
Unsupervised deep embedding for clustering analysis
[Xieet al., 2016 ] Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. InInternational conference on machine learn- ing, pages 478–487. PMLR,
2016
-
[37]
Joint unsupervised learning of deep representations and image clusters
[Yanget al., 2016 ] Jianwei Yang, Devi Parikh, and Dhruv Batra. Joint unsupervised learning of deep representations and image clusters. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5147– 5156,
2016
-
[38]
Graph contrastive clustering
[Zhonget al., 2021 ] Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, Minghua Deng, Liqiang Nie, Zhouchen Lin, and Xian-Sheng Hua. Graph contrastive clustering. InProceedings of the IEEE/CVF international conference on computer vision, pages 9224–9233,
2021
-
[39]
Hierarchical semantic alignment for image clustering
[Zhuet al., 2026 ] Xingyu Zhu, Beier Zhu, Yunfan Li, Jun- feng Fang, Shuo Wang, Kesen Zhao, and Hanwang Zhang. Hierarchical semantic alignment for image clustering. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 40, pages 29177–29185,
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.