Recognition: no theorem link
Skill-Aligned Annotation for Reliable Evaluation in Text-to-Image Generation
Pith reviewed 2026-05-14 20:09 UTC · model grok-4.3
The pith
Annotation strategies tailored to each evaluation skill produce more consistent signals and higher agreement than uniform scales across all skills in text-to-image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
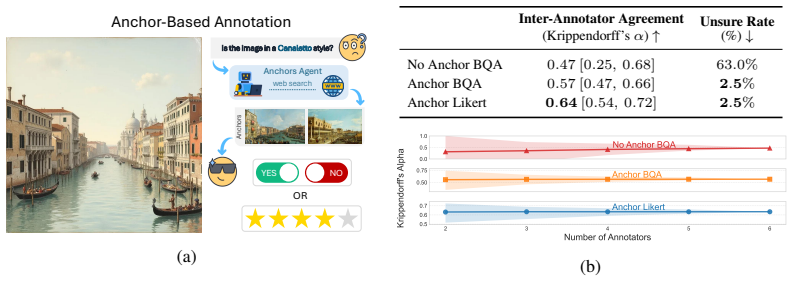
By shifting from uniform annotation mechanisms such as Likert scales or binary question answering applied indiscriminately to all skills, skill-aligned annotation that adapts strategies to each skill's characteristics generates more consistent evaluation signals, higher inter-annotator agreement, and improved stability across models while supporting an automated pipeline for scalable fine-grained evaluation.
What carries the argument
Skill-aligned annotation, which adapts the annotation format and question structure to match the underlying characteristics of each evaluation skill instead of using one method for all.
If this is right
- Higher inter-annotator agreement compared to uniform baselines.
- Greater stability of evaluation results across different models.
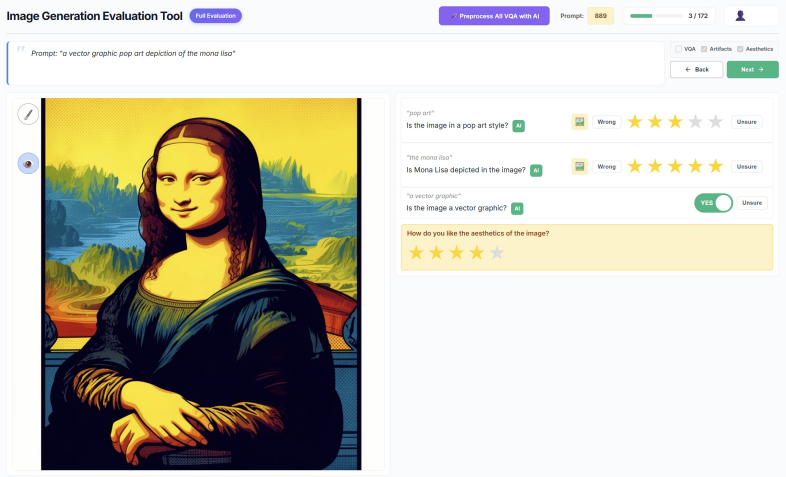
- An automated pipeline becomes feasible for large-scale, fine-grained assessment with spatially grounded feedback.
- Reliability of model comparisons increases without needing to scale total annotation volume.
Where Pith is reading between the lines
- The same tailoring principle could be tested in evaluation of text-to-video or 3D generation tasks.
- Benchmarks might incorporate dynamic selection of annotation types based on skill properties to reduce noise over time.
- Improved signal quality could allow smaller annotation budgets to distinguish incremental model advances.
Load-bearing premise
That the chosen skill-aligned strategies are fundamentally better suited to each skill's nature and that the uniform baselines provide a fair comparison without confounding factors in skill selection or annotation design.
What would settle it
An experiment that rebalances the skill set or redesigns uniform annotations to equivalent complexity levels and still finds equal or higher inter-annotator agreement and model stability under the uniform approach.
Figures











read the original abstract
Text-to-image (T2I) generation has advanced rapidly, making reliable evaluation critical as performance differences between models narrow. Existing evaluation practices typically apply uniform annotation mechanisms, such as Likert-scale or binary question answering (BQA), across heterogeneous evaluation skills, despite fundamental differences in their nature. In this work, we revisit T2I evaluation through the lens of skill-aligned annotation, where annotation strategies reflect the underlying characteristics of each evaluation skill. We systematically compare skill-aligned annotation against uniform baselines and show that it produces more consistent evaluation signals, with higher inter-annotator agreement and improved stability across models. Finally, we present an automated pipeline that instantiates the proposed evaluation protocol, enabling scalable and fine-grained evaluation with spatially grounded feedback. Our work highlights that improving the foundations of image evaluation can increase reliability and efficiency without simply scaling annotation effort. We hope this motivates further research on refining evaluation protocols as a central component of reliable model assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that applying annotation strategies aligned to the specific characteristics of each evaluation skill in text-to-image generation produces more consistent signals than uniform baselines (e.g., Likert or binary QA), evidenced by higher inter-annotator agreement and greater stability across models; it further presents an automated pipeline for scalable, spatially grounded evaluation.
Significance. If the reported gains in consistency hold under properly controlled conditions, the work would strengthen the foundations of T2I evaluation by reducing format-skill mismatches, enabling more reliable model comparisons at comparable annotation cost and motivating protocol refinements as a core research direction.
major comments (2)
- [§4.2] §4.2 (Experimental Setup): The description of uniform baselines does not confirm that question wording, interface layout, and annotator instructions were held identical to the skill-aligned conditions, differing only on the alignment dimension. Without this isolation, reported gains in inter-annotator agreement could be confounded by post-hoc tailoring of skills or interfaces.
- [§5] §5 (Results): Higher agreement and cross-model stability are asserted, yet no statistical significance tests, annotator sample sizes, or bias controls (e.g., randomization or calibration) are reported, leaving the robustness of the central empirical claim unverifiable from the presented data.
minor comments (2)
- [Abstract] Abstract: The claim of 'systematic comparison' would be strengthened by briefly naming the evaluated skills and number of models in the abstract itself.
- [§6] §6 (Automated Pipeline): The pipeline description references 'spatially grounded feedback' without an accompanying figure or example output showing how spatial grounding is visualized or validated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve clarity and verifiability of the results.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Experimental Setup): The description of uniform baselines does not confirm that question wording, interface layout, and annotator instructions were held identical to the skill-aligned conditions, differing only on the alignment dimension. Without this isolation, reported gains in inter-annotator agreement could be confounded by post-hoc tailoring of skills or interfaces.
Authors: We agree that the experimental controls should be stated explicitly. In the original experiments, question wording, interface layout, and annotator instructions were held identical across conditions, with the only difference being the skill-alignment dimension. We have revised §4.2 to add a clear statement confirming these controls were constant, thereby isolating the alignment factor. revision: yes
-
Referee: [§5] §5 (Results): Higher agreement and cross-model stability are asserted, yet no statistical significance tests, annotator sample sizes, or bias controls (e.g., randomization or calibration) are reported, leaving the robustness of the central empirical claim unverifiable from the presented data.
Authors: We acknowledge the need for these details to support the claims. We have revised §5 to report annotator sample sizes, include statistical significance tests on the agreement and stability metrics, and describe bias controls such as randomized ordering and calibration procedures. These additions make the empirical results verifiable. revision: yes
Circularity Check
No circularity: empirical comparisons rest on direct measurements
full rationale
The paper is an empirical study that compares skill-aligned annotation protocols against uniform baselines on metrics such as inter-annotator agreement and cross-model stability. No derivation chain, equations, or first-principles predictions exist that could reduce to fitted inputs or self-citations. Claims are supported by experimental results rather than any self-definitional or load-bearing self-referential step. The work is therefore self-contained with respect to the circularity criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Evaluation skills in T2I have fundamentally different natures that uniform annotation mechanisms fail to capture.
Reference graph
Works this paper leans on
-
[1]
H. Cai, S. Cao, R. Du, P . Gao, S. Hoi, Z. Hou, S. Huang, D. Jiang, X. Jin, L. Li, et al. Z- image: An efficient image generation foundation model with single-stream diffusion trans- former. arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
J. Chen, J. YU, C. GE, L. Y ao, E. Xie, Z. Wang, J. Kwok, P . Luo, H. Lu, and Z. Li. Pixart- $\alpha$: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In The Twelfth International Conference on Learning Representations , 2024
2024
-
[3]
J. Cho, Y . Hu, J. M. Baldridge, R. Garg, P . Anderson, R. Krishna, M. Bansal, J. Pont-Tuset, and S. Wang. Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. In ICLR, 2024
2024
-
[4]
C. Clark, J. Zhang, Z. Ma, J. S. Park, M. Salehi, R. Tripathi, S. Lee, Z. Ren, C. D. Kim, Y . Y ang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding. arXiv preprint arXiv:2601.10611, 2026
-
[5]
DeepMind
G. DeepMind. Nano-banana. https://deepmind.google/models/gemini-image/ flash/, 2025
2025
-
[6]
Eldesokey, A
A. Eldesokey, A. Cvejic, B. Ghanem, and P . Wonka. Mind-the-glitch: Visual correspondence for detecting inconsistencies in subject-driven generation. In Advances in Neural Information Processing Systems, 2025
2025
-
[7]
Esser, S
P . Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In F orty-first international conference on machine learning, 2024
2024
-
[8]
Y . Fan, O. Watkins, Y . Du, H. Liu, M. Ryu, C. Boutilier, P . Abbeel, M. Ghavamzadeh, K. Lee, and K. Lee. Reinforcement learning for fine-tuning text-to-image diffusion models. In Thirty- seventh Conference on Neural Information Processing Systems , 2023
2023
-
[9]
Ghosh, H
D. Ghosh, H. Hajishirzi, and L. Schmidt. Geneval: An object-focused framework for evaluat- ing text-to-image alignment. Advances in Neural Information Processing Systems , 36:52132– 52152, 2023
2023
-
[10]
K. D. Hayes, M. Goldblum, V . Sehwag, G. Somepalli, A. Panda, and T. Goldstein. Fine- GRAIN: Evaluating failure modes of text-to-image models with vision language model judges. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. 10
2025
-
[11]
J. Ho, A. Jain, and P . Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[12]
Y . Hu, B. Liu, J. Kasai, Y . Wang, M. Ostendorf, R. Krishna, and N. A. Smith. Tifa: Accu- rate and interpretable text-to-image faithfulness evaluation with question answering. In Pro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
- [13]
-
[14]
Huang, C
K. Huang, C. Duan, K. Sun, E. Xie, Z. Li, and X. Liu. T2i-compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[15]
H. Kang, S. Wen, Z. Wen, J. Y e, W. Li, P . Feng, B. Zhou, B. Wang, D. Lin, L. Zhang, et al. Legion: Learning to ground and explain for synthetic image detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 18937–18947, 2025
2025
-
[16]
Kirstain, A
Y . Kirstain, A. Polyak, U. Singer, S. Matiana, J. Penna, and O. Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation. Advances in neural information pro- cessing systems, 36:36652–36663, 2023
2023
-
[17]
M. Ku, D. Jiang, C. Wei, X. Y ue, and W. Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long Papers), pages 12268–12290, 2024
2024
-
[18]
B. F. Labs. Flux. https://github.com/black-forest-labs/flux , 2024
2024
-
[19]
B. F. Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[20]
T. Lee, M. Y asunaga, C. Meng, Y . Mai, J. S. Park, A. Gupta, Y . Zhang, D. Narayanan, H. Teufel, M. Bellagente, et al. Holistic evaluation of text-to-image models. Advances in Neural Infor- mation Processing Systems, 36:69981–70011, 2023
2023
-
[21]
B. Li, Z. Lin, D. Pathak, J. Li, Y . Fei, K. Wu, T. Ling, X. Xia, P . Zhang, G. Neubig, and D. Ra- manan. GenAI-Bench: Evaluating and Improving Compositional Text-to-Visual Generation, Nov. 2024
2024
-
[22]
Z. Lin, D. Pathak, B. Li, J. Li, X. Xia, G. Neubig, P . Zhang, and D. Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[23]
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P . Wan, D. Zhang, and W. Ouyang. Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Y . Lu, X. Y ang, X. Li, X. E. Wang, and W. Y . Wang. Llmscore: Unveiling the power of large language models in text-to-image synthesis evaluation. Advances in neural information processing systems, 36:23075–23093, 2023
2023
-
[25]
Y . Ma, X. Wu, K. Sun, and H. Li. Hpsv3: Towards wide-spectrum human preference score. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 15086– 15095, 2025
2025
-
[26]
Otani, R
M. Otani, R. Togashi, Y . Sawai, R. Ishigami, Y . Nakashima, E. Rahtu, J. Heikkilä, and S. Satoh. Toward verifiable and reproducible human evaluation for text-to-image generation. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 14277–14286, 2023
2023
-
[27]
Podell, Z
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rom- bach. SDXL: Improving latent diffusion models for high-resolution image synthesis. In The Twelfth International Conference on Learning Representations , 2024. 11
2024
-
[28]
Saharia, W
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gon- tijo Lopes, B. Karagol Ayan, T. Salimans, et al. Photorealistic text-to-image diffusion mod- els with deep language understanding. Advances in Neural Information Processing Systems , 35:36479–36494, 2022
2022
-
[29]
Saxon, F
M. Saxon, F. Jahara, M. Khoshnoodi, Y . Lu, A. Sharma, and W. Y . Wang. Who evaluates the evaluations? objectively scoring text-to-image prompt coherence metrics with t2IScorescore (TS2). In The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024
2024
-
[30]
Y . Song, C. Durkan, I. Murray, and S. Ermon. Maximum likelihood training of score-based diffusion models. Advances in neural information processing systems , 34:1415–1428, 2021
2021
-
[31]
Q. Team. Qwen-3.5. https://qwen.ai/blog?id=qwen3.5, 2026
2026
-
[32]
Tu, Z.-A
R.-C. Tu, Z.-A. Ma, T. Lan, Y . Zhao, H.-Y . Huang, and X.-L. Mao. Automatic evaluation for text-to-image generation: Task-decomposed framework, distilled training, and meta-evaluation benchmark. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 22340–22361, 2025
2025
-
[33]
Wallace, M
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[34]
W AN. Wan-2.5. https://wan.video/, 2025
2025
-
[35]
Wiles, C
O. Wiles, C. Zhang, I. Albuquerque, I. Kajic, S. Wang, E. Bugliarello, Y . Onoe, P . Papalam- pidi, I. Ktena, C. Knutsen, C. Rashtchian, A. Nawalgaria, J. Pont-Tuset, and A. Nematzadeh. Revisiting text-to-image evaluation with gecko: on metrics, prompts, and human rating. In The Thirteenth International Conference on Learning Representations , 2025
2025
-
[36]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
X. Wu, K. Sun, F. Zhu, R. Zhao, and H. Li. Human preference score: Better aligning text-to- image models with human preference. In Proceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 2096–2105, 2023
2096
- [38]
-
[39]
J. Xu, X. Liu, Y . Wu, Y . Tong, Q. Li, M. Ding, J. Tang, and Y . Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Informa- tion Processing Systems, 36:15903–15935, 2023
2023
-
[40]
Zhang, Z
L. Zhang, Z. Xu, C. Barnes, Y . Zhou, Q. Liu, H. Zhang, S. Amirghodsi, Z. Lin, E. Shechtman, and J. Shi. Perceptual artifacts localization for image synthesis tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 7579–7590, 2023
2023
-
[41]
Zhang, B
S. Zhang, B. Wang, J. Wu, Y . Li, T. Gao, D. Zhang, and Z. Wang. Learning multi-dimensional human preference for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8018–8027, 2024
2024
-
[42]
Hello" in cursive style Is the word
T. Zhang, X. Wang, L. Li, Z. Tai, J. Chi, J. Tian, H. He, and S. Wang. Strict: Stress-test of rendering image containing text. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21148–21161, 2025. 12 A Details on Skills Taxonomy We provide additional examples illustrating the proposed skillsubskill taxonomy in...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.