Recognition: 2 theorem links
· Lean TheoremScaling Retrieval-Augmented Reasoning with Parallel Search and Explicit Merging
Pith reviewed 2026-05-14 18:49 UTC · model grok-4.3
The pith
MultiSearch retrieves external knowledge from multiple query perspectives in parallel and merges the results to raise signal-to-noise ratio before reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces MultiSearch, an RL-based agent framework that, at each reasoning step, generates multiple retrieval queries from distinct perspectives, executes them in parallel to collect external information, and then applies an explicit merging process to consolidate and refine the retrieved content before feeding it into the language model. This multi-query-plus-merge pattern raises the signal-to-noise ratio of the knowledge supplied to the model and produces higher accuracy on downstream question-answering tasks.
What carries the argument
MultiSearch framework that performs parallel multi-query retrieval followed by an explicit information-merging step, trained end-to-end with reinforcement learning that supplies separate rewards for retrieval coverage and consolidation quality.
If this is right
- Agents cover a wider set of relevant facts at each step without depending on any single retrieval result.
- The merging step filters noise before reasoning begins, producing shorter and more accurate reasoning traces.
- Reinforcement learning with separate rewards for retrieval breadth and consolidation quality trains agents to balance coverage against clarity.
- Performance gains appear across seven diverse question-answering benchmarks that test multi-step reasoning.
- The approach improves retrieval quality without increasing the number of reasoning iterations required.
Where Pith is reading between the lines
- The same parallel-plus-merge pattern could be applied to other agent loops that currently call tools sequentially, such as code-generation or tool-use agents.
- If the merging operation remains lightweight, the method may extend to latency-sensitive applications where current retrieval overhead already limits deployment.
- The SNR improvement observed here suggests that multi-perspective retrieval may benefit ensemble-style prompting or multi-agent debate even without external knowledge bases.
Load-bearing premise
Generating queries from multiple perspectives and merging the results will consistently raise the signal-to-noise ratio without introducing new noise sources or prohibitive compute cost in the merging step.
What would settle it
A controlled comparison in which the explicit merging step is replaced by simple concatenation of all retrieved passages and accuracy falls below the single-query baseline would show that the SNR gain depends on the merge operation itself.
Figures






read the original abstract
Deep search agents have proven effective in enhancing LLMs by retrieving external knowledge during multi-step reasoning. However, existing methods often generate a single query for retrieval at each reasoning step, limiting information coverage and introducing high noise. This may result in low signal-to-noise ratios (SNR) during search, degrading reasoning accuracy and leading to unnecessary reasoning steps. In this paper, we introduce MultiSearch, an RL-based framework that addresses these limitations through multi-query retrieval and explicit merging of retrieved information. At each reasoning step, MultiSearch generates queries from multiple perspectives and retrieves external information in parallel, expanding the scope of relevant information and mitigating the reliance on any single retrieval result. Then, the agent consolidates and refines retrieved information at the merging process, improving the SNR and ensuring more accurate reasoning. Additionally, we propose a reinforcement learning framework with a multi-process reward design to optimize agents for both multi-query retrieval and information consolidation. Extensive experiments on seven benchmarks demonstrate that MultiSearch outperforms baseline methods, enhancing the SNR of retrieval and improving reasoning performance in question-answering tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiSearch, an RL-based framework for retrieval-augmented reasoning in LLMs. At each reasoning step it generates multiple queries from different perspectives, retrieves information in parallel, and performs explicit merging to consolidate results. The central claim is that this raises the signal-to-noise ratio of retrieved context, reduces unnecessary reasoning steps, and yields higher accuracy than prior single-query methods on seven QA benchmarks.
Significance. If the performance gains are robust and attributable to the merging step rather than retrieval volume alone, the work would offer a practical, scalable improvement to retrieval-augmented generation pipelines. The multi-process reward design for joint optimization of query generation and consolidation is a potentially reusable idea, provided it is shown to be stable and not merely benchmark-tuned.
major comments (3)
- [Abstract and §4 (Experiments)] The abstract and experimental section assert SNR improvement and outperformance on seven benchmarks, yet supply no quantitative definition of SNR, no direct measurement (e.g., retrieval precision/recall before vs. after merging), and no ablation that isolates merging from simply retrieving more documents. End-task accuracy alone cannot distinguish the claimed mechanism from increased context length.
- [§4 (Experiments)] Baseline implementations, hyper-parameter choices, statistical significance tests, and error bars are not reported. Without these, the reported gains cannot be assessed for reproducibility or for whether they exceed the variance of the underlying LLM and retriever.
- [§3.2 (RL Framework)] The RL training procedure uses a multi-process reward whose weights are listed as free parameters. No sensitivity analysis or ablation on these weights is provided, leaving open whether the claimed improvements are robust or the result of post-hoc tuning against the evaluation benchmarks.
minor comments (2)
- [§3.1] Notation for the merging operator and the multi-query generation process should be formalized with explicit equations rather than prose descriptions.
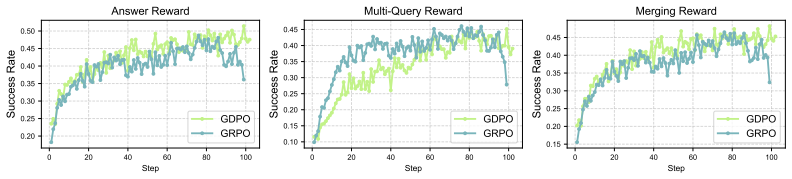
- [§4] Figure captions and axis labels in the experimental plots would benefit from explicit mention of the exact metrics and number of runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of results and analyses.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The abstract and experimental section assert SNR improvement and outperformance on seven benchmarks, yet supply no quantitative definition of SNR, no direct measurement (e.g., retrieval precision/recall before vs. after merging), and no ablation that isolates merging from simply retrieving more documents. End-task accuracy alone cannot distinguish the claimed mechanism from increased context length.
Authors: We agree that the current manuscript lacks an explicit quantitative definition of SNR and direct measurements isolating the merging step. In the revision we will define SNR as the ratio of relevant to total tokens in the consolidated context, add pre/post-merging retrieval precision and recall metrics on a held-out subset, and include an ablation that matches total retrieved documents between single-query and multi-query+merging variants to separate the effect of merging from context length. revision: yes
-
Referee: [§4 (Experiments)] Baseline implementations, hyper-parameter choices, statistical significance tests, and error bars are not reported. Without these, the reported gains cannot be assessed for reproducibility or for whether they exceed the variance of the underlying LLM and retriever.
Authors: We acknowledge these omissions limit reproducibility assessment. The revised version will document exact baseline implementations (with repository links), list all hyper-parameters, report mean and standard deviation over three independent runs, and include paired t-tests to establish statistical significance of the observed gains. revision: yes
-
Referee: [§3.2 (RL Framework)] The RL training procedure uses a multi-process reward whose weights are listed as free parameters. No sensitivity analysis or ablation on these weights is provided, leaving open whether the claimed improvements are robust or the result of post-hoc tuning against the evaluation benchmarks.
Authors: The weights were selected via preliminary grid search on a development split. To address robustness concerns we will add an appendix sensitivity study in the revision that sweeps the reward weights over a range of values and shows that performance remains stable and superior to baselines within that range. revision: partial
Circularity Check
No significant circularity; framework evaluated on external benchmarks
full rationale
The paper introduces an RL-trained MultiSearch agent for parallel multi-query retrieval followed by explicit merging. All performance claims rest on end-task accuracy/F1 metrics measured against independent QA benchmarks rather than any internal equation or fitted parameter that is renamed as a prediction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled via prior work, and SNR is used only as an informal descriptive term without a closed-form derivation that loops back to the method's own outputs. The derivation chain is therefore self-contained against external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-process reward weights
axioms (1)
- domain assumption Generating queries from multiple perspectives expands the scope of relevant information and mitigates reliance on any single retrieval result
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MultiSearch generates queries from multiple perspectives... consolidates and refines retrieved information at the merging process, improving the SNR
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reinforcement learning framework with a multi-process reward design
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey on evaluation of large language models.ACM transactions on intelligent systems and technology, 15(3):1–45, 2024
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology, 15(3):1–45, 2024
2024
-
[2]
Siren’s song in the ai ocean: A survey on hallucination in large language models.Computational Linguistics, 51(4):1373–1418, 2025
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models.Computational Linguistics, 51(4):1373–1418, 2025
2025
-
[3]
A study of generative large language model for medical research and healthcare.NPJ digital medicine, 6(1):210, 2023
Cheng Peng, Xi Yang, Aokun Chen, Kaleb E Smith, Nima PourNejatian, Anthony B Costa, Cheryl Martin, Mona G Flores, Ying Zhang, Tanja Magoc, et al. A study of generative large language model for medical research and healthcare.NPJ digital medicine, 6(1):210, 2023
2023
-
[4]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.CoRR, abs/2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[6]
Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096, 2025
Yuxuan Huang, Yihang Chen, Haozheng Zhang, Kang Li, Huichi Zhou, Meng Fang, Linyi Yang, Xiaoguang Li, Lifeng Shang, Songcen Xu, et al. Deep research agents: A systematic examination and roadmap.arXiv preprint arXiv:2506.18096, 2025
-
[7]
Yunjia Xi, Jianghao Lin, Yongzhao Xiao, Zheli Zhou, Rong Shan, Te Gao, Jiachen Zhu, Weiwen Liu, Yong Yu, and Weinan Zhang. A survey of llm-based deep search agents: Paradigm, optimization, evaluation, and challenges.arXiv preprint arXiv:2508.05668, 2025
-
[8]
Webthinker: Empowering large reasoning models with deep research capability
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[9]
Tongyi DeepResearch Technical Report
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, et al. Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[11]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[12]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025
2025
-
[14]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588, 2025
-
[15]
Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen
Mingyang Chen, Linzhuang Sun, Tianpeng Li, sunhaoze, ZhouYijie, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. Research: Learning to reason with search for LLMs via reinforcement learning. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. 10
2025
-
[16]
Search and refine during think: Facilitating knowledge refinement for improved retrieval-augmented reasoning
Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, and Xiang Wang. Search and refine during think: Facilitating knowledge refinement for improved retrieval-augmented reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[17]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward- decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
work page internal anchor Pith review arXiv 2026
-
[18]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[19]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, 2023
2023
-
[20]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[21]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
2018
-
[22]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[23]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[24]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
2023
-
[25]
Query rewriting in retrieval- augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting in retrieval- augmented large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5303–5315, December 2023
2023
-
[26]
Query expansion using lexical-semantic relations
Ellen M V oorhees. Query expansion using lexical-semantic relations. InSIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University, pages 61–69. Springer
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun-Mei Song, Mingchuan Zhang, Y . K. Li, Yu Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.ArXiv, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems. Curran Associates Inc., 2022
2022
-
[29]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, Toronto, Canada, July 2023. Association for C...
-
[32]
Projective characterization of higher- order quantum transformations, 2022
Tzu-Han Lin, Wei-Lin Chen, Chen-An Li, Hung-yi Lee, Yun-Nung Chen, and Yu Meng. Adasearch: Balancing parametric knowledge and search in large language models via reinforce- ment learning.CoRR, abs/2512.16883, 2025. doi: 10.48550/ARXIV .2512.16883
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[33]
Yaocheng Zhang, Haohuan Huang, Zijun Song, Yuanheng Zhu, Qichao Zhang, Zijie Zhao, and Dongbin Zhao. Criticsearch: Fine-grained credit assignment for search agents via a retrospective critic.arXiv preprint arXiv:2511.12159, 2025
-
[34]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. ArXiv, abs/2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-...
-
[36]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36: 68539–68551, 2023
2023
-
[40]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[41]
Yuqin Dai, Guoqing Wang, Yuan Wang, Kairan Dou, Kaichen Zhou, Zhanwei Zhang, Shuo Yang, Fei Tang, Jun Yin, Pengyu Zeng, et al. Evinote-rag: Enhancing rag models via answer- supportive evidence notes.arXiv preprint arXiv:2509.00877, 2025
-
[42]
Peiran Xu, Zhuohao Li, Xiaoying Xing, Guannan Zhang, Debiao Li, and Kunyu Shi. Hy- brid reward normalization for process-supervised non-verifiable agentic tasks.arXiv preprint arXiv:2509.25598, 2025
-
[43]
Process vs
Wenlin Zhang, Xiangyang Li, Kuicai Dong, Yichao Wang, Pengyue Jia, Xiaopeng Li, Yingyi Zhang, Derong Xu, Zhaocheng Du, Huifeng Guo, Ruiming Tang, and Xiangyu Zhao. Process vs. outcome reward: Which is better for agentic RAG reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 12
2026
-
[44]
Bowei He, Minda Hu, Zenan Xu, Hongru Wang, Licheng Zong, Yankai Chen, Chen Ma, Xue Liu, Pluto Zhou, and Irwin King. Search-r2: Enhancing search-integrated reasoning via actor-refiner collaboration.arXiv preprint arXiv:2602.03647, 2026
-
[45]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
2022
-
[46]
Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
1996
-
[47]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Signal" represents information that is directly relevant to answering the question
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023. 13 A More Experimental Results A.1 Ablation of Evaluation Metrics To provide a more comprehensive eva...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.