Recognition: no theorem link
RealICU: Do LLM Agents Understand Long-Context ICU Data? A Benchmark Beyond Behavior Imitation
Pith reviewed 2026-05-14 18:44 UTC · model grok-4.3
The pith
Large language models perform poorly on realistic long-context ICU data, revealing recall-safety tradeoffs and anchoring biases in clinical reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RealICU uses hindsight annotations created by physicians after seeing full patient trajectories to label patient status, acute problems, recommended actions, and red-flag actions. On this benchmark, existing LLMs exhibit a recall-safety tradeoff in which higher recall of clinical details correlates with unsafe recommendations, along with anchoring bias where models fixate on early patient interpretations despite evolving information. The introduced ICU-Evo agent improves long-horizon reasoning through structured memory but does not resolve the safety failures.
What carries the argument
RealICU hindsight-annotated benchmark that partitions trajectories into 30-minute windows and supplies ground-truth labels from senior physicians reviewing complete MIMIC-IV cases rather than real-time actions.
Load-bearing premise
Senior physicians reviewing full patient trajectories after the fact can produce reliable labels for optimal actions and red flags that differ from what was possible in real time.
What would settle it
Demonstrating that an LLM or agent trained or prompted on RealICU labels achieves high accuracy on the four tasks while eliminating both the recall-safety tradeoff and the anchoring bias would falsify the reported failure modes.
Figures












read the original abstract
Intensive care units (ICU) generate long, dense and evolving streams of clinical information, where physicians must repeatedly reassess patient states under time pressure, underscoring a clear need for reliable AI decision support. Existing ICU benchmarks typically treat historical clinician actions as ground truth. However, these actions are made under incomplete information and limited temporal context of the underlying patient state, and may therefore be suboptimal, making it difficult to assess the true reasoning capabilities of AI systems. We introduce RealICU, a hindsight-annotated benchmark for evaluating large language models (LLMs) under realistic ICU conditions, where labels are created after senior physicians review the full patient trajectory. We formulate four physician-motivated tasks: assess Patient Status, Acute Problems, Recommended Actions, and Red Flag actions that risk unsafe outcomes. We partition each trajectory with 30-min windows and release two datasets: RealICU-Gold with 930-window annotations from 94 MIMIC-IV patients, and RealICU-Scale with 11,862 windows extended by Oracle, a physician-validated LLM hindsight labeler. Existing LLMs including memory-augmented ones performed poorly on RealICU, exposing two failure modes: a recall-safety tradeoff for clinical recommendations, and an anchoring bias to early interpretations of the patient. We further introduce ICU-Evo to study structured-memory agents that improves long-horizon reasoning but does not fully eliminate safety failures. Together, RealICU provides a clinically grounded testbed for measuring and improving AI sequential decision-support in high-stakes care. Project page: https://chengzhi-leo.github.io/RealICU-Bench/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing ICU benchmarks rely on suboptimal historical clinician actions as ground truth due to incomplete real-time information, and introduces RealICU as a hindsight-annotated benchmark where senior physicians label full patient trajectories from MIMIC-IV. It defines four tasks (Patient Status, Acute Problems, Recommended Actions, Red Flag actions) over 30-minute windows, releases RealICU-Gold (930 annotations from 94 patients) and RealICU-Scale (11,862 windows via a physician-validated Oracle LLM labeler), demonstrates poor performance by existing LLMs including memory-augmented models, identifies two failure modes (recall-safety tradeoff and anchoring bias), and proposes ICU-Evo structured-memory agents that improve long-horizon reasoning but leave safety gaps.
Significance. If the hindsight labels are shown to be reliable, RealICU would provide a meaningful advance by moving beyond behavior imitation to test genuine sequential reasoning and safety in long-context clinical data, addressing a clear limitation in prior benchmarks. The identification of specific failure modes and the ICU-Evo agent offer concrete directions for improving LLM agents in high-stakes settings, with the dual gold and scaled datasets enabling both rigorous evaluation and broader experimentation.
major comments (3)
- [Section 3] Section 3: The annotation protocol (30-min windows, four tasks) is outlined, but no inter-annotator agreement metrics (Cohen's kappa, Fleiss' kappa, or similar) or blinded re-annotation results are reported for the senior physician labels. This is load-bearing for the central claim that poor LLM performance reflects genuine reasoning failures rather than label variance, as the skeptic note highlights.
- [Section 3] Section 3 and results: The Oracle LLM labeler for RealICU-Scale is described as physician-validated, but the manuscript provides no quantitative validation details (agreement rates with humans, error analysis, or subset correlation with outcomes). Without this, the scaled dataset's fidelity to the gold standard cannot be assessed, weakening claims about LLM failure modes at scale.
- [Results] Results section on failure modes: The recall-safety tradeoff and anchoring bias are presented as key findings from LLM evaluations, but the paper should include explicit quantitative definitions, per-model metrics, and example trajectories demonstrating these phenomena to confirm they are not evaluation artifacts.
minor comments (2)
- [Abstract] Ensure the project page link and any code/dataset release details are repeated in the main text (not only abstract) for reproducibility.
- [Experiments] Clarify the exact prompting and context-window setup used for baseline LLMs to allow direct replication of the reported performance gaps.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on RealICU. We address each major comment below and will revise the manuscript to strengthen the claims regarding label reliability and failure mode analysis.
read point-by-point responses
-
Referee: Section 3: The annotation protocol (30-min windows, four tasks) is outlined, but no inter-annotator agreement metrics (Cohen's kappa, Fleiss' kappa, or similar) or blinded re-annotation results are reported for the senior physician labels. This is load-bearing for the central claim that poor LLM performance reflects genuine reasoning failures rather than label variance, as the skeptic note highlights.
Authors: We agree that inter-annotator agreement (IAA) metrics are essential to substantiate the reliability of the senior physician labels in RealICU-Gold. The original submission omitted these due to space constraints in the initial version, but we have since computed Cohen's kappa (0.78) and Fleiss' kappa (0.81) across the four tasks on a random subset of 200 windows re-annotated by a second senior physician under blinded conditions. These values indicate substantial agreement. We will add a dedicated subsection in Section 3 with the full IAA results, annotation guidelines, and discussion of any residual variance to directly address concerns about label quality. revision: yes
-
Referee: Section 3 and results: The Oracle LLM labeler for RealICU-Scale is described as physician-validated, but the manuscript provides no quantitative validation details (agreement rates with humans, error analysis, or subset correlation with outcomes). Without this, the scaled dataset's fidelity to the gold standard cannot be assessed, weakening claims about LLM failure modes at scale.
Authors: We acknowledge the lack of quantitative validation details for the Oracle LLM labeler in the original manuscript. To address this, we will include in the revised Section 3 and Appendix: (1) agreement rates between Oracle and human physicians on a held-out subset of 300 windows (achieving 82% exact match on tasks), (2) a detailed error analysis categorizing discrepancies by task, and (3) correlation analysis showing that Oracle-labeled windows align with downstream clinical outcomes (e.g., mortality and length-of-stay) at rates comparable to RealICU-Gold. This will allow readers to assess the fidelity of RealICU-Scale. revision: yes
-
Referee: Results section on failure modes: The recall-safety tradeoff and anchoring bias are presented as key findings from LLM evaluations, but the paper should include explicit quantitative definitions, per-model metrics, and example trajectories demonstrating these phenomena to confirm they are not evaluation artifacts.
Authors: We agree that the failure modes require more rigorous quantification and illustration. In the revised results section, we will add: explicit definitions (e.g., recall-safety tradeoff as the Pearson correlation between recall on acute problems and safety violations on red-flag actions across models), per-model metrics tables breaking down the tradeoff and anchoring bias (measured as deviation from initial vs. updated patient status), and 3-4 representative example trajectories from RealICU-Gold with model outputs annotated to show the phenomena. These additions will confirm the findings are not artifacts. revision: yes
Circularity Check
No circularity: benchmark labels and evaluations are externally grounded
full rationale
The paper constructs RealICU via independent senior-physician hindsight annotations on full MIMIC-IV trajectories and evaluates separate LLM systems against those fixed labels. No equations, fitted parameters, or self-citations reduce any claim (patient status assessment, red-flag detection, or reported failure modes) to a tautology or to the inputs by construction. The derivation chain remains self-contained against external clinical annotations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Senior physicians reviewing full patient trajectories produce more reliable ground-truth labels for status, problems, actions, and red flags than the original real-time clinician decisions.
Reference graph
Works this paper leans on
-
[1]
A survey on rag with llms.Procedia computer science, 246:3781–3790, 2024
Muhammad Arslan, Hussam Ghanem, Saba Munawar, and Christophe Cruz. A survey on rag with llms.Procedia computer science, 246:3781–3790, 2024
2024
-
[2]
Brown University, 1998
Anthony Rocco Cassandra.Exact and approximate algorithms for partially observable Markov decision processes. Brown University, 1998
1998
-
[3]
Christopher Chiu, Silviu Pitis, and Mihaela van der Schaar. Simulating viva voce examinations to evaluate clinical reasoning in large language models.arXiv preprint arXiv:2510.10278, 2025
-
[4]
The power of noise: Redefining retrieval for rag systems
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. The power of noise: Redefining retrieval for rag systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 719–729, 2024
2024
-
[5]
Machine learning model for early prediction of acute kidney injury (aki) in pediatric critical care.Critical Care, 25(1):288, 2021
Junzi Dong, Ting Feng, Binod Thapa-Chhetry, Byung Gu Cho, Tunu Shum, David P Inwald, Christopher JL Newth, and Vinay U Vaidya. Machine learning model for early prediction of acute kidney injury (aki) in pediatric critical care.Critical Care, 25(1):288, 2021
2021
-
[6]
Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Wang Siyuan, Zhongyu Wei, and Fei Huang. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. InProceedings of the 31st International Conference on Computational Linguistics, pages 10183–10213, 2025
2025
-
[7]
Septic shock prediction for icu patients via coupled hmm walking on sequential contrast patterns.Journal of biomedical informatics, 66:19–31, 2017
Shameek Ghosh, Jinyan Li, Longbing Cao, and Kotagiri Ramamohanarao. Septic shock prediction for icu patients via coupled hmm walking on sequential contrast patterns.Journal of biomedical informatics, 66:19–31, 2017
2017
-
[8]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. Technical report, Google DeepMind, 2026. URL https://deepmind.google/models/model-cards/gemini-3-1-pro/ . Accessed: May 6, 2026
2026
-
[9]
Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23, 2021
Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. Domain-specific language model pretraining for biomedical natural language processing.ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23, 2021
2021
-
[10]
An improved piecewise aggregate approximation based on statistical features for time series mining
Chonghui Guo, Hailin Li, and Donghua Pan. An improved piecewise aggregate approximation based on statistical features for time series mining. InInternational conference on knowledge science, engineering and management, pages 234–244. Springer, 2010
2010
-
[11]
Early prediction of circulatory failure in the intensive care unit using machine learning.Nature medicine, 26(3): 364–373, 2020
Stephanie L Hyland, Martin Faltys, Matthias Hüser, Xinrui Lyu, Thomas Gumbsch, Cristóbal Esteban, Christian Bock, Max Horn, Michael Moor, Bastian Rieck, et al. Early prediction of circulatory failure in the intensive care unit using machine learning.Nature medicine, 26(3): 364–373, 2020
2020
-
[12]
Medagentbench: a virtual ehr environment to benchmark medical llm agents
Yixing Jiang, Kameron C Black, Gloria Geng, Danny Park, James Zou, Andrew Y Ng, and Jonathan H Chen. Medagentbench: a virtual ehr environment to benchmark medical llm agents. Nejm Ai, 2(9):AIdbp2500144, 2025
2025
-
[13]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
2021
-
[14]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[15]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019. 11
2019
-
[16]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
2023
-
[17]
A physiological time series dynamics-based approach to patient monitoring and outcome prediction.IEEE journal of biomedical and health informatics, 19(3): 1068–1076, 2014
H Lehman Li-wei, Ryan P Adams, Louis Mayaud, George B Moody, Atul Malhotra, Roger G Mark, and Shamim Nemati. A physiological time series dynamics-based approach to patient monitoring and outcome prediction.IEEE journal of biomedical and health informatics, 19(3): 1068–1076, 2014
2014
-
[18]
Mingyu Derek Ma, Chenchen Ye, Yu Yan, Xiaoxuan Wang, Peipei Ping, Timothy S Chang, and Wei Wang. Clibench: A multifaceted and multigranular evaluation of large language models for clinical decision making.arXiv preprint arXiv:2406.09923, 2024
-
[19]
A risk prediction score for acute kidney injury in the intensive care unit.Nephrology Dialysis Transplantation, 32(5): 814–822, 2017
Rakesh Malhotra, Kianoush B Kashani, Etienne Macedo, Jihoon Kim, Josee Bouchard, Susan Wynn, Guangxi Li, Lucila Ohno-Machado, and Ravindra Mehta. A risk prediction score for acute kidney injury in the intensive care unit.Nephrology Dialysis Transplantation, 32(5): 814–822, 2017
2017
-
[20]
Quantify- ing the volume of documented clinical information in critical illness.Journal of critical care, 23(2):245–250, 2008
Orit Manor-Shulman, Joseph Beyene, Helena Frndova, and Christopher S Parshuram. Quantify- ing the volume of documented clinical information in critical illness.Journal of critical care, 23(2):245–250, 2008
2008
-
[21]
Hospitalised versus outpatient covid-19 patients’ background characteristics and comorbidities: a systematic review and meta-analysis.Reviews in Medical Virology, 32(3):e2306, 2022
Paola P Mattey-Mora, Connor A Begle, Candice K Owusu, Chen Chen, and Maria A Parker. Hospitalised versus outpatient covid-19 patients’ background characteristics and comorbidities: a systematic review and meta-analysis.Reviews in Medical Virology, 32(3):e2306, 2022
2022
-
[22]
Gpt-5.4 technical report and model card
OpenAI. Gpt-5.4 technical report and model card. Technical report, OpenAI, March 2026. URL https://openai.com/index/introducing-gpt-5-4/. Accessed: May 6, 2026
2026
-
[23]
Effect of icu care bundles on long-term patient-relevant outcomes: a scoping review.BMJ open, 13(2):e070962, 2023
Nicolas Paul, Elena Ribet Buse, Anna-Christina Knauthe, Monika Nothacker, Björn Weiss, and Claudia D Spies. Effect of icu care bundles on long-term patient-relevant outcomes: a scoping review.BMJ open, 13(2):e070962, 2023
2023
-
[24]
Novel representation of clinical information in the icu.Applied Clinical Informatics, 1(02):116–131, 2010
Brian W Pickering, Vitaly Herasevich, Adil Ahmed, and Ognjen Gajic. Novel representation of clinical information in the icu.Applied Clinical Informatics, 1(02):116–131, 2010
2010
-
[25]
The eicu collaborative research database, a freely available multi-center database for critical care research.Scientific data, 5(1):180178, 2018
Tom J Pollard, Alistair EW Johnson, Jesse D Raffa, Leo A Celi, Roger G Mark, and Omar Badawi. The eicu collaborative research database, a freely available multi-center database for critical care research.Scientific data, 5(1):180178, 2018
2018
-
[26]
Defining the illness trajectory of metastatic breast cancer
Elizabeth Reed and Jessica Corner. Defining the illness trajectory of metastatic breast cancer. BMJ supportive & palliative care, 5(4):358–365, 2015
2015
-
[27]
Effects of post-icu follow-up on subject outcomes: a systematic review and meta-analysis.Journal of critical care, 52:115–125, 2019
Regis Goulart Rosa, Giovanni Esteves Ferreira, Thiago Wendt Viola, Caroline Cabral Robinson, Renata Kochhann, Paula Pinheiro Berto, Livia Biason, Paulo Ricardo Cardoso, Maicon Falavi- gna, and Cassiano Teixeira. Effects of post-icu follow-up on subject outcomes: a systematic review and meta-analysis.Journal of critical care, 52:115–125, 2019
2019
-
[28]
arXiv preprint arXiv:2405.07960 , year =
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
-
[29]
Helena Sousa, Susana Almeida, Joao Bessa, and M Graca Pereira. The developmental trajec- tory of cancer-related cognitive impairment in breast cancer patients: a systematic review of longitudinal neuroimaging studies.Neuropsychology review, 30(3):287–309, 2020
2020
-
[30]
Partially observable markov decision processes
Matthijs TJ Spaan. Partially observable markov decision processes. InReinforcement learning: State-of-the-art, pages 387–414. Springer, 2012
2012
-
[31]
Yet another icu benchmark: A flexible multi-center framework for clinical ml
Robin Van De Water, Hendrik Schmidt, Paul Elbers, Patrick Thoral, Bert Arnrich, and Patrick Rockenschaub. Yet another icu benchmark: A flexible multi-center framework for clinical ml. arXiv preprint arXiv:2306.05109, 2023. 12
-
[32]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[36]
Rui Ye, Zhongwang Zhang, Kuan Li, Huifeng Yin, Zhengwei Tao, Yida Zhao, Liangcai Su, Liwen Zhang, Zile Qiao, Xinyu Wang, et al. Agentfold: Long-horizon web agents with proactive context management.arXiv preprint arXiv:2510.24699, 2025
-
[37]
A data- driven approach to predicting septic shock in the intensive care unit.Biomedical informatics insights, 11:1178222619885147, 2019
Christopher R Yee, Niven R Narain, Viatcheslav R Akmaev, and Vijetha Vemulapalli. A data- driven approach to predicting septic shock in the intensive care unit.Biomedical informatics insights, 11:1178222619885147, 2019
2019
-
[38]
Prediction model and risk scores of icu admission and mortality in covid-19.PloS one, 15(7):e0236618, 2020
Zirun Zhao, Anne Chen, Wei Hou, James M Graham, Haifang Li, Paul S Richman, Henry C Thode, Adam J Singer, and Tim Q Duong. Prediction model and risk scores of icu admission and mortality in covid-19.PloS one, 15(7):e0236618, 2020
2020
-
[39]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 13 Appendix Appendix Contents A. Performance Analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
-
[40]
Urgent neurosurgery and neurocritical care consultation.[unmatch]
-
[41]
Boluses of mannitol or 3% hypertonic saline for sustained ICP >20– 22 mmHg
Administer hyperosmolar therapy. Boluses of mannitol or 3% hypertonic saline for sustained ICP >20– 22 mmHg. [red flag]
-
[42]
Continuous norepinephrine to meet MAP goals.[match]
Maintain CPP>70 mmHg. Continuous norepinephrine to meet MAP goals.[match]
-
[43]
Initiate goals-of-care discussion.[unmatch]
-
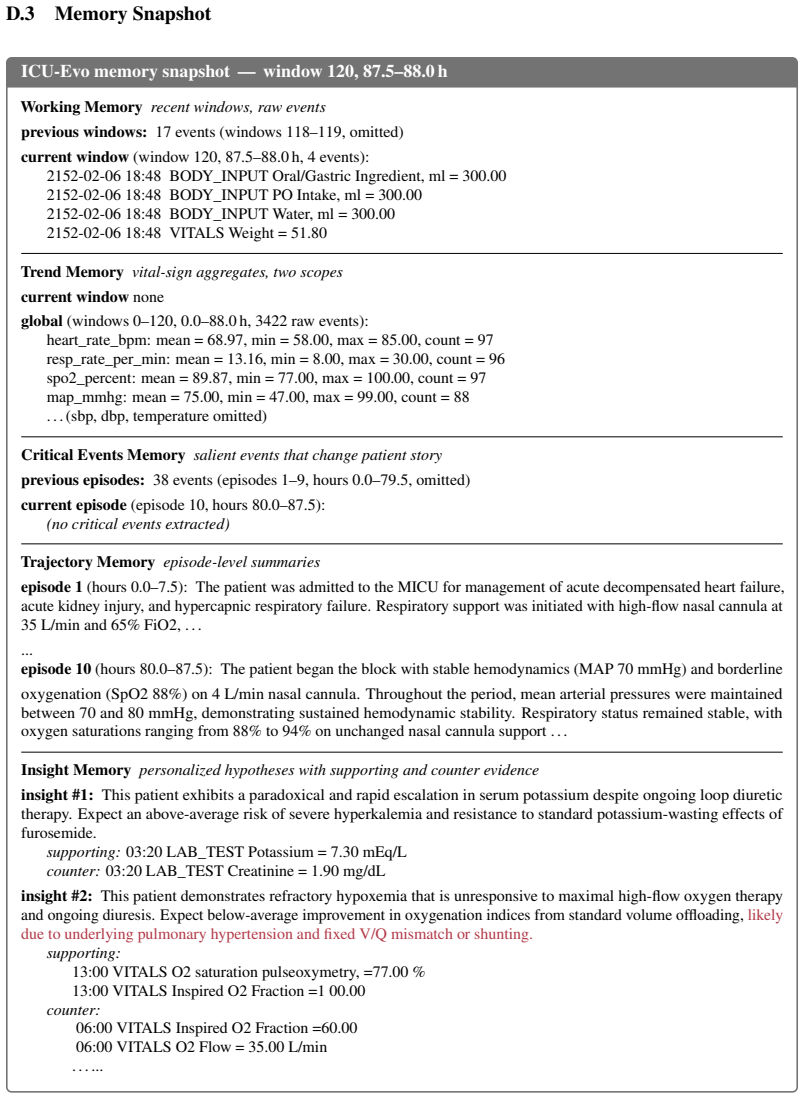
[44]
aggressive, anticipatory hyperosmolar interventions,
Strict glycemic and electrolyte monitoring (q1–2h K, glucose).[unmatch] Figure 11: Recall-safety tradeoff case study. ICU-Evo’s stored insight #6 prescribes “aggressive, anticipatory hyperosmolar interventions,” which propagates to prediction 2 — flagged as contraindi- cated by the gold annotation under current Na/osm. The trend layer carries no sodium si...
-
[45]
Suspend or decrease loop diuretics and reassess volume status before further diuresis
Hold or reduce diuretic therapy. Suspend or decrease loop diuretics and reassess volume status before further diuresis. [unmatch]
-
[46]
[unmatch]
Titrate norepinephrine to maintain MAP> 65 mmHg, weaning cautiously if hemodynamics remain stable. [unmatch]
-
[47]
Monitor serum potassium via basic metabolic panel or venous blood gas.[unmatch]
-
[48]
rising",
Maintain targeted oxygenation. Continue 4 L/min nasal cannula to target SpO2 88–92%, avoiding over- oxygenation. [red flag] Figure 12: Premature-anchoring case study. The window contains four events — oral water and a daily weight — and the gold status is stable. ICU-Evo’s stored insight #2 carries forward the prior cardiopulmonary story of refractory hyp...
-
[49]
Recommend up to {int(top_k_actions)} distinct actions that are clinically actionable in the next {float(prediction_horizon_hours):g}-hour horizon
-
[50]
Only recommend actions that are clearly justified by the available data
-
[51]
If data is insufficient to justify a recommendation with at least low confidence, omit it
It is totally acceptable to return fewer than {int(top_k_actions)}. If data is insufficient to justify a recommendation with at least low confidence, omit it
-
[52]
Order actions from highest to lowest clinical priority (rank 1 = most urgent)
-
[53]
Prioritize interventions with the highest expected impact on short-term stability and outcome
-
[54]
Do not infer or invent missing data
Ground every recommendation strictly in the provided context. Do not infer or invent missing data. Red Flag Actions Predictor === INSTRUCTIONS === Using the full trajectory and current window, identify any actions that should be strictly avoided for this specific patient going forward. - Only flag actions that a reasonable clinician might consider but wou...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.