Recognition: 2 theorem links
· Lean TheoremDense vs Sparse Pretraining at Tiny Scale: Active-Parameter vs Total-Parameter Matching
Pith reviewed 2026-05-14 19:14 UTC · model grok-4.3
The pith
Mixture-of-experts models beat dense baselines when matching active parameters but fall short when total stored capacity is equalized in sub-25M pretraining.
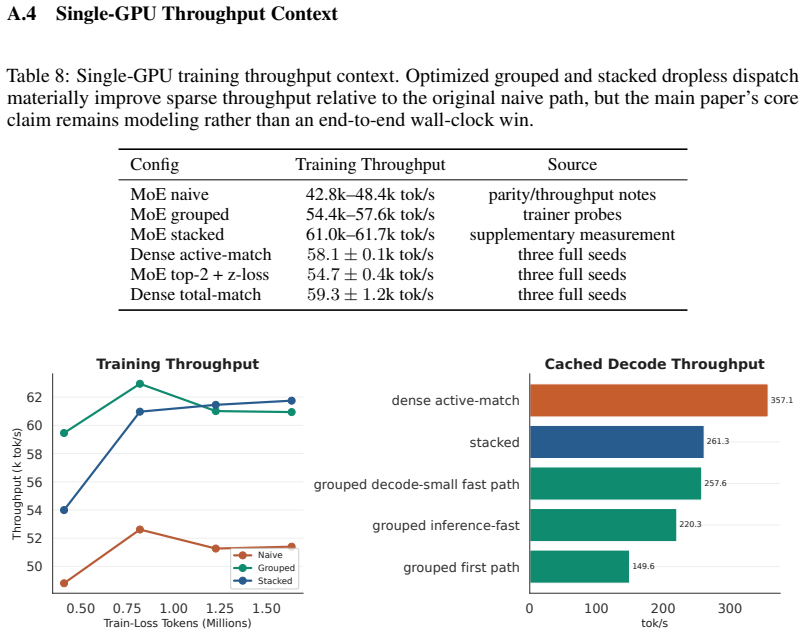
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In this sub-25M-parameter regime, the MoE model improves validation loss under active-parameter matching but does not surpass dense training at equal total stored capacity. Across three seeds the matched-active gap favors MoE by 0.0758 while the matched-total gap favors dense by 0.0180, with the active advantage widening and the total advantage shrinking over the course of training.
What carries the argument
Active-parameter versus total-parameter matching, which counts only the weights used in a forward pass for the active budget and all stored expert weights for the total budget.
If this is right
- The MoE advantage over active-matched dense models grows steadily across training steps.
- The dense advantage over MoE when total parameters are matched narrows sharply but remains positive at the end of training.
- The reported gaps hold with the given error bars across three independent seeds.
- MoE therefore provides a computational benefit only when capacity is measured by active weights rather than total stored weights.
Where Pith is reading between the lines
- If the same ordering appears at larger scales, it would imply that MoE gains are mainly computational savings rather than raw parameter efficiency.
- Varying the number of experts or the routing function while keeping total capacity fixed could test whether the observed total-match deficit is tied to this particular four-expert configuration.
- The narrowing total-match gap during training suggests that extended schedules or larger data volumes might eventually close or reverse the ordering.
Load-bearing premise
That the specific choice of four experts with top-2 routing and Switch-style balancing captures the essential difference between sparse and dense models rather than depending on untested details of the tiny-scale setup.
What would settle it
Repeating the exact experiment with eight experts instead of four and checking whether the MoE still underperforms the total-matched dense model would show whether the result depends on the chosen sparsity level.
Figures





read the original abstract
We study dense and mixture-of-experts (MoE) transformers in a tiny-scale pretraining regime under a shared LLaMA-style decoder training recipe. The sparse model replaces dense feed-forward blocks with Mixtral-style routed experts. Dense baselines are modestly width-resized to tightly match either active or total parameter budgets, while tokenizer, data, optimizer, schedule, depth, context length, normalization style, and evaluation protocol are held fixed. Our best sparse recipe uses four experts, top-2 routing, Switch-style load balancing, and router z-loss. In a three-seed full-data comparison, the dense active-match model reaches 1.6545 +/- 0.0012 best validation loss, the MoE reaches 1.5788 +/- 0.0020, and the dense total-match model reaches 1.5608 +/- 0.0025. This yields a matched-active gap of 0.0758 +/- 0.0021 in the MoE's favor and a matched-total gap of 0.0180 +/- 0.0020 in the dense model's favor. Across training, the matched-active advantage grows while the matched-total dense advantage narrows sharply. In this sub-25M-parameter regime, MoE therefore improves validation loss under active-parameter matching but does not surpass dense training at equal total stored capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically investigates dense versus mixture-of-experts (MoE) pretraining at tiny scales below 25M parameters. Under a fixed LLaMA-style training setup, dense models are width-adjusted to match either the active or total parameter count of a four-expert top-2 MoE model. With three seeds, the MoE achieves a validation loss of 1.5788 ± 0.0020 compared to 1.6545 ± 0.0012 for active-matched dense and 1.5608 ± 0.0025 for total-matched dense, indicating an advantage for MoE in active matching but not in total matching.
Significance. If these findings hold, the work offers valuable insights into the benefits of sparsity in low-parameter regimes, demonstrating that MoE improves performance when computation is matched but not when total capacity is equalized. The controlled experimental design with reported variances enhances the credibility of the conclusions for understanding scaling behaviors in sparse architectures.
minor comments (2)
- [Methods] Explicitly state whether the router parameters are counted within the active-parameter budget for the MoE models, since they remain active during inference and could introduce a minor asymmetry in the active-matching comparison.
- [Abstract] Include the precise active and total parameter counts for the dense and MoE configurations to allow readers to verify the tightness of the matching.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. No specific major comments were raised in the report, so we have no individual points requiring rebuttal or revision at this stage. We are pleased that the controlled experimental design and reported variances were viewed as enhancing credibility.
Circularity Check
No circularity: direct empirical loss measurements
full rationale
The paper reports direct empirical measurements of validation loss from training runs under controlled active- and total-parameter matching. No equations, derivations, or predictive models are present that reduce reported gaps to fitted parameters, self-citations, or definitions by construction. All claims rest on observed losses (e.g., 1.5788 vs 1.6545) with three-seed statistics, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of experts =
4
- Routing top-k =
2
axioms (1)
- domain assumption LLaMA-style decoder training recipe and fixed tokenizer, data, optimizer, schedule, depth, context, and normalization are held constant across models
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In this sub-25M-parameter regime, MoE therefore improves validation loss under active-parameter matching but does not surpass dense training at equal total stored capacity.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dense baselines are modestly width-resized to tightly match either active or total parameter budgets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Journal of Machine Learning Research , volume=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. Journal of Machine Learning Research , volume=
-
[3]
Zoph, Barret and Fedus, William and Zhou, Denny and others , journal=
-
[4]
Mixtral of Experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Du, Nan and Huang, Yanping and Dai, Andrew and others , journal=
-
[6]
Proceedings of the 39th International Conference on Machine Learning , pages=
Unified Scaling Laws for Routed Language Models , author=. Proceedings of the 39th International Conference on Machine Learning , pages=
-
[7]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
Efficient Large Scale Language Modeling with Mixtures of Experts , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
work page 2022
-
[8]
arXiv preprint arXiv:2402.07871 , year=
Scaling Laws for Fine-Grained Mixture of Experts , author=. arXiv preprint arXiv:2402.07871 , year=
-
[9]
Abnar, Samira and Shah, Harshay and Busbridge, Dan and Mohamed Elnouby Ali, Alaaeldin and Susskind, Josh and Thilak, Vimal , journal=. Parameters vs
- [10]
-
[11]
Muennighoff, Niklas and Soldaini, Luca and Groeneveld, Dirk and Lo, Kyle and Morrison, Jacob and others , booktitle=
-
[12]
Mixture-of-Experts Can Surpass Dense
Li, Houyi and Lo, Ka Man and Xuyang, Shijie and Wang, Ziqi and Zheng, Wenzhen and others , booktitle=. Mixture-of-Experts Can Surpass Dense
-
[13]
Eldan, Ronen and Li, Yuanzhi , journal=
-
[14]
Proceedings of Machine Learning and Systems , year=
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts , author=. Proceedings of Machine Learning and Systems , year=
-
[15]
Training Compute-Optimal Large Language Models
Training Compute-Optimal Large Language Models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Dai, Damai and Li, Wenbin and Xu, Nuo and others , journal=
-
[17]
arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.