Recognition: 2 theorem links
· Lean TheoremRethinking Molecular OOD Generalization via Target-Aware Source Selection
Pith reviewed 2026-05-15 05:04 UTC · model grok-4.3
The pith
A reinforcement learning policy selects source subsets to reduce extreme out-of-distribution errors in molecular property prediction by up to 11 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
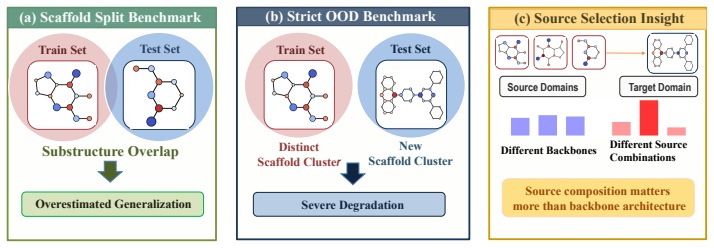
Scaffold-splitting protocols permit microscopic semantic overlap that encourages shortcut learning, while conventional domain adaptation injects noise and causes negative transfer under large structural differences. SCOPE-BENCH creates stricter OOD tests through cluster-level partitioning in physicochemical descriptor space and shows mean error increases of 5.9 times. POMA implements a retrieve-compose-adapt pipeline that first retrieves proxy targets, then uses an RL policy to choose an optimal source subset from a large pool, and finally performs dual-scale adaptation to improve accuracy.
What carries the argument
The POMA retrieve-compose-adapt pipeline, in which a reinforcement learning policy adaptively selects an optimal source subset from candidates identified as structurally close to the target, followed by dual-scale domain adaptation at macroscopic topological and microscopic pharmacophore scales.
If this is right
- Prediction errors on extreme OOD molecular tasks drop by up to 11.2 percent in mean absolute error when source selection is performed target-aware rather than blindly.
- The same selection-plus-adaptation procedure yields an average 6.2 percent relative improvement across multiple 3D molecular backbone architectures.
- Negative transfer is reduced because the policy avoids aligning topologically dissimilar source libraries with the target.
- Prior evaluations that rely on scaffold splits systematically overestimate true extrapolation capability by a factor of roughly six on average.
Where Pith is reading between the lines
- The same RL-driven source selection could be tested on protein-ligand or materials property tasks where distribution shifts are also extreme.
- Dual-scale adaptation implies that molecular models benefit from explicit alignment at both global graph structure and local functional-group levels.
- Benchmarks for scientific machine learning should routinely adopt cluster partitioning to guarantee separation at the semantic level rather than relying on scaffold rules alone.
Load-bearing premise
The reinforcement learning policy can reliably pick source subsets that avoid negative transfer, and cluster partitioning in physicochemical descriptor space fully removes any microscopic semantic overlap between source and target.
What would settle it
Apply the trained RL policy to a fresh collection of target molecules and measure whether the selected sources produce lower mean absolute error than either the full source library or randomly chosen subsets on the same SCOPE-BENCH splits.
Figures




read the original abstract
Robust prediction of molecular properties under extreme out-of-distribution (OOD) scenarios is a pivotal bottleneck in AI-driven drug discovery. Current scaffold-splitting protocols fail to obstruct microscopic semantic overlap, predisposing models to shortcut learning and overestimating their true extrapolation capability; meanwhile, conventional domain adaptation paradigms suffer under extreme structural shifts, as blindly aligning heterogeneous source libraries injects topological noise and triggers negative transfer. To address these two challenges, scaffold-cluster out-of-distribution performance evaluation benchmark (SCOPE-BENCH), a benchmark built on cluster-level partitioning in an explicit physicochemical descriptor space, is proposed alongside policy optimization for multi-source adaptation (POMA), a framework that formulates knowledge transfer as a retrieve-compose-adapt pipeline: labeled source scaffolds structurally close to the unlabeled target are first identified as proxy targets; a reinforcement learning policy then adaptively selects the optimal source subset from an exponentially large candidate pool; and dual-scale domain adaptation is finally performed at macroscopic topological and microscopic pharmacophore scales. Evaluations show that prediction errors of state-of-the-art 3D molecular models surge by up to 8.0x on SCOPE-BENCH with a mean of 5.9x, while POMA achieves up to an 11.2% reduction in mean absolute error with an average relative improvement of 6.2% across diverse backbone architectures. Code is available at https://anonymous.4open.science/r/Molecular-OOD-Code-73F6.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SCOPE-BENCH, a benchmark for molecular OOD generalization constructed via cluster-level partitioning in physicochemical descriptor space to block microscopic semantic overlap and shortcut learning, together with POMA, a retrieve-compose-adapt framework that uses reinforcement learning to select optimal source subsets from an exponentially large pool before performing dual-scale domain adaptation at topological and pharmacophore levels. It reports that state-of-the-art 3D molecular models exhibit prediction-error increases of up to 8.0x (mean 5.9x) on SCOPE-BENCH while POMA delivers up to 11.2% MAE reduction with 6.2% average relative improvement across backbones.
Significance. If the benchmark truly isolates extreme OOD without residual overlap and the RL policy reliably avoids negative transfer, the work would meaningfully advance reliable property prediction in AI-driven drug discovery by supplying both a stricter evaluation protocol and a practical adaptation method. Code availability is a positive factor for reproducibility.
major comments (3)
- [SCOPE-BENCH] SCOPE-BENCH construction: the load-bearing claim that cluster-level partitioning in explicit physicochemical descriptor space fully eliminates microscopic semantic overlap is insufficiently supported. Global descriptors (MW, logP, TPSA) do not encode local 3D substructure or pharmacophore similarity exploited by the evaluated 3D models; any residual overlap would invalidate attribution of the reported 5.9x mean error surge solely to OOD.
- [POMA] POMA framework: the reinforcement-learning policy is asserted to identify source subsets that avoid negative transfer, yet the reward design and any explicit penalization mechanism (e.g., held-out proxy-target validation) are not detailed. Without such safeguards the adaptive selection may still include harmful sources, directly affecting the claimed 6.2% average improvement.
- [Evaluations] Experimental evaluation: the quantitative claims (8.0x surge, 11.2% MAE reduction, 6.2% relative gain) are presented without protocol details, baseline definitions, statistical significance tests, or ablation studies, preventing verification that the gains are not due to post-hoc choices.
minor comments (1)
- [Abstract] The abstract would benefit from explicit definitions of 'microscopic semantic overlap' and 'dual-scale domain adaptation' to improve immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and will revise the paper to address the concerns by providing additional clarifications, analyses, and experimental details. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [SCOPE-BENCH] SCOPE-BENCH construction: the load-bearing claim that cluster-level partitioning in explicit physicochemical descriptor space fully eliminates microscopic semantic overlap is insufficiently supported. Global descriptors (MW, logP, TPSA) do not encode local 3D substructure or pharmacophore similarity exploited by the evaluated 3D models; any residual overlap would invalidate attribution of the reported 5.9x mean error surge solely to OOD.
Authors: We thank the referee for this important observation. While our cluster-level partitioning in physicochemical descriptor space is designed to enforce a stricter separation than standard scaffold splits by operating at a higher semantic granularity, we acknowledge that global descriptors alone may leave some residual local 3D or pharmacophore similarities unaddressed. In the revised manuscript we will add a quantitative analysis of residual overlap using 3D similarity metrics (e.g., pharmacophore fingerprint Tanimoto scores and 3D shape overlap) computed across cluster boundaries, together with a discussion of the remaining limitations. This will strengthen the attribution of the observed error increases to genuine OOD effects. revision: yes
-
Referee: [POMA] POMA framework: the reinforcement-learning policy is asserted to identify source subsets that avoid negative transfer, yet the reward design and any explicit penalization mechanism (e.g., held-out proxy-target validation) are not detailed. Without such safeguards the adaptive selection may still include harmful sources, directly affecting the claimed 6.2% average improvement.
Authors: We appreciate the referee's request for greater transparency on the RL component. The reward function in POMA is a weighted sum of (i) negative MAE on a small held-out proxy-target validation set drawn from the target domain and (ii) a diversity penalty that discourages selection of sources whose topological or pharmacophore distributions deviate strongly from the target. In the revision we will provide the exact mathematical formulation of the reward, the policy gradient objective, training hyperparameters, and pseudocode for the selection procedure, thereby clarifying the safeguards against negative transfer. revision: yes
-
Referee: [Evaluations] Experimental evaluation: the quantitative claims (8.0x surge, 11.2% MAE reduction, 6.2% relative gain) are presented without protocol details, baseline definitions, statistical significance tests, or ablation studies, preventing verification that the gains are not due to post-hoc choices.
Authors: We agree that the current experimental section lacks sufficient detail for full reproducibility and verification. In the revised manuscript we will expand the evaluation section to include: complete data-preprocessing and splitting protocols, precise definitions and implementations of all baselines, results of statistical significance tests (paired t-tests and Wilcoxon signed-rank tests with reported p-values), and comprehensive ablation studies isolating the contributions of the RL source selection and the dual-scale adaptation modules. These additions will substantiate the reported performance numbers. revision: yes
Circularity Check
No significant circularity; framework uses external standard components
full rationale
The paper introduces SCOPE-BENCH via explicit cluster-level partitioning in physicochemical descriptor space and POMA as a retrieve-compose-adapt pipeline using a reinforcement learning policy for source subset selection followed by dual-scale domain adaptation. No equations, derivations, or first-principles predictions are presented that reduce to fitted parameters or inputs by construction. The central claims consist of empirical evaluations showing error surges and MAE reductions, which rely on standard RL and domain-adaptation techniques whose grounding is external. No self-citation chains, uniqueness theorems, or smuggled ansatzes serve as load-bearing steps. The derivation chain remains self-contained through explicit methodological definitions and benchmark construction rather than circular reductions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Scaffold-splitting protocols fail to obstruct microscopic semantic overlap
- domain assumption Blind alignment of heterogeneous source libraries injects topological noise and triggers negative transfer
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SCOPE-BENCH constructs domains via scaffold extraction, four-dimensional physicochemical feature vectors fk = Vmacro ⊕ Velement ⊕ Vconn ⊕ Vflex, hierarchical clustering with K-Means++ yielding 12 globally disjoint clusters, and asymmetric partitioning.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
POMA formulates knowledge transfer as retrieve–compose–adapt with GRPO policy optimization over candidate pool C, dual-scale alignment LDA using squared Frobenius norms of covariance matrices at mol and sub scales.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization.arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
k-means++: The advantages of careful seeding
David Arthur, Sergei Vassilvitskii, et al. k-means++: The advantages of careful seeding. InSoda, volume 7, pages 1027–1035, 2007
work page 2007
-
[3]
Gotennet: Rethinking efficient 3d equivariant graph neural networks
Sarp Aykent and Tian Xia. Gotennet: Rethinking efficient 3d equivariant graph neural networks. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[4]
Dávid Bajusz, Anita Rácz, and Károly Héberger. Why is tanimoto index an appropriate choice for fingerprint-based similarity calculations?Journal of cheminformatics, 7(1):20, 2015
work page 2015
-
[5]
E (n) equivariant topological neural networks.arXiv preprint arXiv:2405.15429, 2024
Claudio Battiloro, Mauricio Tec, George Dasoulas, Michelle Audirac, Francesca Dominici, et al. E (n) equivariant topological neural networks.arXiv preprint arXiv:2405.15429, 2024
-
[6]
Neural Combinatorial Optimization with Reinforcement Learning
Irwan Bello, Hieu Pham, Quoc V Le, Mohammad Norouzi, and Samy Bengio. Neural combinatorial optimization with reinforcement learning.arXiv preprint arXiv:1611.09940, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Guy W Bemis and Mark A Murcko. The properties of known drugs. 1. molecular frameworks.Journal of medicinal chemistry, 39(15):2887–2893, 1996
work page 1996
-
[8]
A theory of learning from different domains.Machine learning, 79(1):151–175, 2010
Shai Ben-David, John Blitzer, Koby Crammer, Alex Kulesza, Fernando Pereira, and Jennifer Wortman Vaughan. A theory of learning from different domains.Machine learning, 79(1):151–175, 2010
work page 2010
-
[9]
Xiangsen Chen, Ruilong Wu, Yanyan Lan, Ting Ma, and Yang Liu. Molevolve: Llm-guided evolutionary search for interpretable molecular optimization.arXiv preprint arXiv:2603.24382, 2026
-
[10]
On the art of compiling and using’drug-like’chemical fragment spaces.ChemMedChem, 3(10):1503, 2008
Jorg Degen, Christof Wegscheid-Gerlach, Andrea Zaliani, and Matthias Rarey. On the art of compiling and using’drug-like’chemical fragment spaces.ChemMedChem, 3(10):1503, 2008
work page 2008
-
[11]
Hung-Chieh Fang, Po-Yi Lu, and Hsuan-Tien Lin. Tackling dimensional collapse toward comprehensive universal domain adaptation.arXiv preprint arXiv:2410.11271, 2024
-
[12]
Anna Gaulton, Louisa J Bellis, A Patricia Bento, Jon Chambers, Mark Davies, Anne Hersey, Yvonne Light, Shaun McGlinchey, David Michalovich, Bissan Al-Lazikani, et al. Chembl: a large-scale bioactivity database for drug discovery.Nucleic acids research, 40(D1):D1100–D1107, 2012
work page 2012
-
[13]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
work page 2020
-
[14]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. InInternational conference on machine learning, pages 1263–1272. Pmlr, 2017
work page 2017
-
[15]
Good: A graph out-of-distribution benchmark
Shurui Gui, Xiner Li, Limei Wang, and Shuiwang Ji. Good: A graph out-of-distribution benchmark. Advances in Neural Information Processing Systems, 35:2059–2073, 2022
work page 2059
-
[16]
Inhomogeneous electron gas.Physical review, 136(3B):B864, 1964
Pierre Hohenberg and Walter Kohn. Inhomogeneous electron gas.Physical review, 136(3B):B864, 1964. 10
work page 1964
-
[17]
Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
-
[18]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
RDKit: Open-source chemoinformatics, 2024
Greg Landrum et al. RDKit: Open-source chemoinformatics, 2024. URL https://doi.org/10.5281/ zenodo.12782092
work page 2024
-
[20]
Haoyang Li, Xin Wang, Ziwei Zhang, and Wenwu Zhu. Out-of-distribution generalization on graphs: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[21]
Kun Li, Zhennan Wu, Shoupeng Wang, Jia Wu, Shirui Pan, and Wenbin Hu. Drugpilot: Llm-based parameterized reasoning agent for drug discovery.arXiv preprint arXiv:2505.13940, 2025
-
[22]
Kun Li, Zhennan Wu, Yida Xiong, Hongzhi Zhang, Longtao Hu, Zhonglie Liu, Junqi Zeng, Wenjie Wu, Mukun Chen, Jiameng Chen, et al. Bsl: A unified and generalizable multitask learning platform for virtual drug discovery from design to synthesis.arXiv preprint arXiv:2508.01195, 2025
-
[23]
Kun Li, Yida Xiong, Hongzhi Zhang, Xiantao Cai, Jia Wu, Bo Du, and Wenbin Hu. Graph-structured small molecule drug discovery through deep learning: Progress, challenges, and opportunities. In2025 IEEE International Conference on Web Services (ICWS), pages 1033–1042, 2025. doi: 10.1109/ICWS67624. 2025.00135
-
[24]
Kun Li, Yue Zeng, Yi-da Xiong, Hao-chen Wu, Sui Fang, Zhi-yan Qu, Yan Zhu, Bo Du, Zhao-bing Gao, and Wen-bin Hu. Contrastive learning-based drug screening model for glun1/glun3a inhibitors.Acta Pharmacologica Sinica, pages 1–13, 2025
work page 2025
-
[25]
Kun Li, Longtao Hu, Jiameng Chen, Hongzhi Zhang, Yida Xiong, Xiantao Cai, Wenbin Hu, and Jia Wu. Can molecular evolution mechanism enhance molecular representation? InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 15108–15116, 2026
work page 2026
-
[26]
Pcevo: Path-consistent molecular representation via virtual evolutionary
Kun Li, Longtao Hu, Yida Xiong, Jiajun Yu, Hongzhi Zhang, Jiameng Chen, Xiantao Cai, Jia Wu, and Wenbin Hu. Pcevo: Path-consistent molecular representation via virtual evolutionary. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-26. International Joint Conferences on Artificial Intelligence Organization...
work page 2026
-
[27]
Towards out-of-distribution generalization: A survey.arXiv preprint arXiv:2108.13624, 2021
Jiashuo Liu, Zheyan Shen, Yue He, Xingxuan Zhang, Renzhe Xu, Han Yu, and Peng Cui. Towards out-of-distribution generalization: A survey.arXiv preprint arXiv:2108.13624, 2021
-
[28]
Harry L Morgan. The generation of a unique machine description for chemical structures-a technique developed at chemical abstracts service.Journal of chemical documentation, 5(2):107–113, 1965
work page 1965
-
[29]
Yaniv Ovadia, Emily Fertig, Jie Ren, Zachary Nado, David Sculley, Sebastian Nowozin, Joshua Dillon, Balaji Lakshminarayanan, and Jasper Snoek. Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift.Advances in neural information processing systems, 32, 2019
work page 2019
-
[30]
Sinno Jialin Pan and Qiang Yang. A survey on transfer learning.IEEE Transactions on knowledge and data engineering, 22(10):1345–1359, 2009
work page 2009
-
[31]
Moment matching for multi-source domain adaptation
Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, and Bo Wang. Moment matching for multi-source domain adaptation. InProceedings of the IEEE/CVF international conference on computer vision, pages 1406–1415, 2019
work page 2019
-
[32]
Deep reinforcement learning for de novo drug design.Science advances, 4(7):eaap7885, 2018
Mariya Popova, Olexandr Isayev, and Alexander Tropsha. Deep reinforcement learning for de novo drug design.Science advances, 4(7):eaap7885, 2018
work page 2018
-
[33]
Xiaohan Qin, Chao Wang, Zhengyang Zhou, Linjiang Chen, Wenjie Du, and Yang Wang. Msanchor: De novo molecular generation from mass spectrometry data with anchor-extended molecular scaffolds. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 953–961, 2026
work page 2026
-
[34]
Quantum chemistry structures and properties of 134 kilo molecules.Scientific data, 1(1):1–7, 2014
Raghunathan Ramakrishnan, Pavlo O Dral, Matthias Rupp, and O Anatole V on Lilienfeld. Quantum chemistry structures and properties of 134 kilo molecules.Scientific data, 1(1):1–7, 2014
work page 2014
-
[35]
Extended-connectivity fingerprints.Journal of chemical information and modeling, 50(5):742–754, 2010
David Rogers and Mathew Hahn. Extended-connectivity fingerprints.Journal of chemical information and modeling, 50(5):742–754, 2010
work page 2010
-
[36]
Rosenstein, Zvika Marx, Leslie Pack Kaelbling, and Thomas G
Michael T. Rosenstein, Zvika Marx, Leslie Pack Kaelbling, and Thomas G. Dietterich. To transfer or not to transfer. InNIPS Workshop on Transfer Learning, 2005. 11
work page 2005
-
[37]
E (n) equivariant graph neural networks
Vıctor Garcia Satorras, Emiel Hoogeboom, and Max Welling. E (n) equivariant graph neural networks. In International conference on machine learning, pages 9323–9332. PMLR, 2021
work page 2021
-
[38]
Gabriele Scalia, Colin A Grambow, Barbara Pernici, Yi-Pei Li, and William H Green. Evaluating scalable uncertainty estimation methods for deep learning-based molecular property prediction.Journal of chemical information and modeling, 60(6):2697–2717, 2020
work page 2020
-
[39]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Kristof Schütt, Pieter-Jan Kindermans, Huziel Enoc Sauceda Felix, Stefan Chmiela, Alexandre Tkatchenko, and Klaus-Robert Müller. Schnet: A continuous-filter convolutional neural network for modeling quantum interactions.Advances in neural information processing systems, 30, 2017
work page 2017
-
[41]
Equivariant message passing for the prediction of tensorial properties and molecular spectra
Kristof Schütt, Oliver Unke, and Michael Gastegger. Equivariant message passing for the prediction of tensorial properties and molecular spectra. InInternational conference on machine learning, pages 9377–9388. PMLR, 2021
work page 2021
-
[42]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Weisfeiler-lehman graph kernels.Journal of Machine Learning Research, 12(9), 2011
Nino Shervashidze, Pascal Schweitzer, Erik Jan Van Leeuwen, Kurt Mehlhorn, and Karsten M Borgwardt. Weisfeiler-lehman graph kernels.Journal of Machine Learning Research, 12(9), 2011
work page 2011
-
[44]
Deep coral: Correlation alignment for deep domain adaptation
Baochen Sun and Kate Saenko. Deep coral: Correlation alignment for deep domain adaptation. In European conference on computer vision, pages 443–450. Springer, 2016
work page 2016
-
[45]
Matteo Togninalli, Elisabetta Ghisu, Felipe Llinares-López, Bastian Rieck, and Karsten Borgwardt. Wasserstein weisfeiler-lehman graph kernels.Advances in neural information processing systems, 32, 2019
work page 2019
-
[46]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
work page 2008
-
[47]
W Patrick Walters and Mark Murcko. Assessing the impact of generative ai on medicinal chemistry.Nature biotechnology, 38(2):143–145, 2020
work page 2020
-
[48]
Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, et al. Scientific discovery in the age of artificial intelligence.Nature, 620(7972):47–60, 2023
work page 2023
-
[49]
Yusong Wang, Tong Wang, Shaoning Li, Xinheng He, Mingyu Li, Zun Wang, Nanning Zheng, Bin Shao, and Tie-Yan Liu. Enhancing geometric representations for molecules with equivariant vector-scalar interactive message passing.Nature Communications, 15(1):313, 2024
work page 2024
-
[50]
Characterizing and avoiding negative transfer
Zirui Wang, Zihang Dai, Barnabás Póczos, and Jaime Carbonell. Characterizing and avoiding negative transfer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11293–11302, 2019
work page 2019
-
[51]
Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513–530, 2018
work page 2018
-
[52]
Electron density-enhanced molecular geometry learning
Hongxin Xiang, Jun Xia, Xin Jin, Wenjie Du, Li Zeng, and Xiangxiang Zeng. Electron density-enhanced molecular geometry learning. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 7840–7848, 2025
work page 2025
-
[53]
Nianzu Yang, Kaipeng Zeng, Qitian Wu, Xiaosong Jia, and Junchi Yan. Learning substructure invariance for out-of-distribution molecular representations.Advances in Neural Information Processing Systems, 35: 12964–12978, 2022
work page 2022
-
[54]
Kernel readout for graph neural networks
Jiajun Yu, Zhihao Wu, Jinyu Cai, Adele Lu Jia, and Jicong Fan. Kernel readout for graph neural networks. InIJCAI, pages 2505–2514, 2024
work page 2024
-
[55]
A centrality-based graph learning framework
Jiajun Yu, Zhihao Wu, Jielong Lu, Tianyue Wang, and Haishuai Wang. A centrality-based graph learning framework. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 3588–3596, 2025. 12
work page 2025
-
[56]
Han Zhao, Shanghang Zhang, Guanhang Wu, José MF Moura, Joao P Costeira, and Geoffrey J Gordon. Adversarial multiple source domain adaptation.Advances in neural information processing systems, 31, 2018
work page 2018
-
[57]
Optimization of molecules via deep reinforcement learning.Scientific reports, 9(1):10752, 2019
Zhenpeng Zhou, Steven Kearnes, Li Li, Richard N Zare, and Patrick Riley. Optimization of molecules via deep reinforcement learning.Scientific reports, 9(1):10752, 2019. 13 A Training Algorithm and Implementation Details All experiments are conducted on NVIDIA RTX A6000 (48 GB) GPUs. The computational overhead of POMA can be decoupled into two phases: (1) ...
work page 2019
-
[58]
In these cases, conventional fine-tuning often leads to catastrophic forgetting or negative transfer due to the injection of irrelevant source noise. By contrast, the target-aware selection mechanism in POMA isolates a sparse but highly relevant subset of source knowledge. Consequently, the model maintains high predictive accuracy without being compromise...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.