Recognition: no theorem link
Diagnosing Training Inference Mismatch in LLM Reinforcement Learning
Pith reviewed 2026-05-15 02:01 UTC · model grok-4.3
The pith
Small token-level numerical disagreements can independently cause training collapse in LLM reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a controlled diagnostic setting that enforces exact matching between rollout and optimization, small token-level numerical disagreements arising from implementation differences in LLM RL systems are shown to independently cause training collapse. TIM is isolated from off-policy drift and stabilization effects, revealing that it modifies the effective optimization problem being solved. Remedies are identified that can mitigate these effects, leading to the conclusion that TIM represents a first-order perturbation in analyzing training stability.
What carries the argument
The VeXact diagnostic setting, which creates a zero-mismatch environment to separate Training-Inference Mismatch from other confounding factors in LLM RL training.
Load-bearing premise
The VeXact diagnostic setting successfully isolates TIM from off-policy drift and stabilization mechanisms without introducing new artifacts.
What would settle it
Observing whether training collapse occurs in VeXact when numerical matching is enforced versus when small disagreements are allowed to persist.
Figures
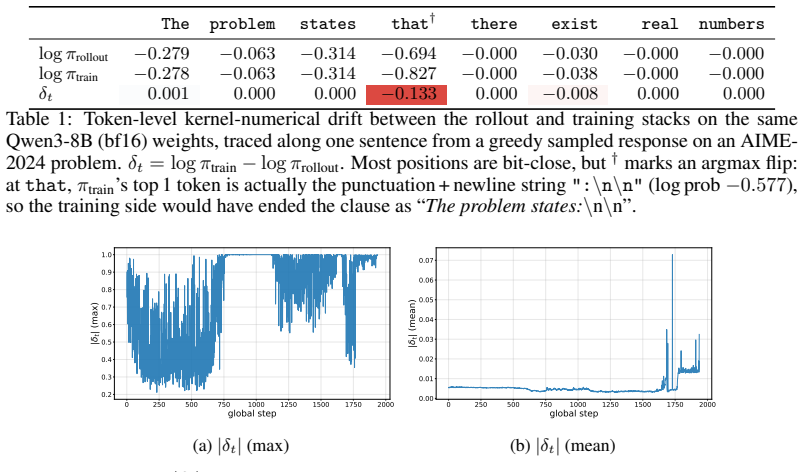







read the original abstract
Modern LLM RL systems separate rollout generation from policy optimization. These two stages are expected to produce token probabilities that match exactly. However, implementation differences can make them assign different values to the same sequence under the same model weights, inducing Training-Inference Mismatch (TIM). TIM is difficult to inspect because it is entangled with off-policy drift and common stabilization mechanisms. In this work, we isolate TIM in a zero-mismatch diagnostic setting (VeXact), and show that small token-level numerical disagreements can independently cause training collapse. We further show that TIM changes the effective optimization problem, and identify a set of remedies that could mitigate TIM. Our results suggest that TIM is not benign numerical noise, but a systems-level perturbation that should be treated as a first-order factor in analyzing LLM RL stability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies Training-Inference Mismatch (TIM) arising from implementation differences between rollout generation and policy optimization in LLM RL, which can produce differing token probabilities under identical weights. It introduces the VeXact zero-mismatch diagnostic to isolate TIM from off-policy drift and stabilization mechanisms, claims that small token-level numerical disagreements independently induce training collapse, shows that TIM alters the effective optimization problem, and proposes remedies.
Significance. If the central empirical claims hold with rigorous controls, the work would be significant for LLM RL stability analysis: it reframes TIM as a first-order systems perturbation rather than benign noise, supplies a diagnostic tool for isolating numerical mismatch, and identifies concrete mitigation strategies. The emphasis on reproducible isolation of a previously entangled factor could influence how future RL training pipelines are audited.
major comments (3)
- [Abstract] Abstract and VeXact section: the claim that VeXact successfully isolates TIM and that small numerical disagreements independently cause collapse is unsupported by any quantitative results, error analysis, ablation tables, or implementation details on how exact logit copying is enforced; without these, the causal attribution cannot be evaluated.
- [VeXact] VeXact diagnostic description: no explicit verification is provided that enforcing zero mismatch (e.g., forced exact logit copying) preserves the original optimization problem, gradient paths, or sampling dynamics; if the diagnostic itself modifies the effective loss landscape, observed collapse cannot be attributed solely to TIM.
- [Experiments] Results on training collapse: the assertion that TIM changes the effective optimization problem requires controlled re-introduction of mismatch at varying scales with metrics showing that collapse scales with the mismatch magnitude and not with side-effects of the diagnostic setup.
minor comments (2)
- [Preliminaries] Notation for token probabilities and mismatch metrics should be defined once with explicit formulas rather than introduced piecemeal.
- [Figures] Figure captions for any VeXact diagrams should include the precise conditions under which mismatch is controlled or eliminated.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our paper 'Diagnosing Training Inference Mismatch in LLM Reinforcement Learning'. We value the referee's assessment of its potential significance and address the major comments below, outlining revisions to enhance clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and VeXact section: the claim that VeXact successfully isolates TIM and that small numerical disagreements independently cause collapse is unsupported by any quantitative results, error analysis, ablation tables, or implementation details on how exact logit copying is enforced; without these, the causal attribution cannot be evaluated.
Authors: The full paper includes quantitative experiments in the results section demonstrating TIM isolation via VeXact, with training curves showing collapse under mismatch. We will revise the abstract and VeXact section to include more implementation details on logit copying enforcement, error bounds, and ablation tables quantifying the effect of small disagreements. This will strengthen the causal attribution. revision: yes
-
Referee: [VeXact] VeXact diagnostic description: no explicit verification is provided that enforcing zero mismatch (e.g., forced exact logit copying) preserves the original optimization problem, gradient paths, or sampling dynamics; if the diagnostic itself modifies the effective loss landscape, observed collapse cannot be attributed solely to TIM.
Authors: We will add a new subsection in the VeXact description providing explicit verification through both theoretical analysis and empirical checks that zero mismatch preserves gradients and sampling. This includes showing identical loss landscapes when TIM is absent, ensuring attribution to TIM alone. revision: yes
-
Referee: [Experiments] Results on training collapse: the assertion that TIM changes the effective optimization problem requires controlled re-introduction of mismatch at varying scales with metrics showing that collapse scales with the mismatch magnitude and not with side-effects of the diagnostic setup.
Authors: The manuscript already presents experiments re-introducing mismatch at different levels, with collapse observed scaling accordingly. We will expand this with additional metrics and controls to rule out diagnostic side-effects, including plots of collapse vs. mismatch magnitude and ablations on the diagnostic setup. revision: partial
Circularity Check
No circularity: empirical diagnostic isolates TIM via controlled experiments
full rationale
The paper frames its contribution as an empirical diagnostic (VeXact) that isolates token-level numerical mismatch from off-policy drift and stabilization mechanisms, then demonstrates collapse under controlled re-introduction of mismatch. No derivation chain, equations, or predictions reduce by construction to fitted inputs, self-citations, or ansatzes; the central claim rests on experimental outcomes rather than a mathematical reduction. The work is self-contained against external benchmarks in the form of reproducible training runs, with no load-bearing self-citation or uniqueness theorem invoked to force the result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model , author=. 2025 , eprint=
work page 2025
-
[2]
arXiv preprint arXiv:2602.19362 , year=
LLMs Can Learn to Reason Via Off-Policy RL , author=. arXiv preprint arXiv:2602.19362 , year=
-
[3]
Thinking Machines Lab: Connectionism , year =
Horace He , title =. Thinking Machines Lab: Connectionism , year =
- [4]
-
[5]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
work page 2024
-
[6]
and Ermon, Stefano and Rudra, Atri and R\'
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R\'. FLASHATTENTION: fast and memory-efficient exact attention with IO-awareness , year =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
-
[7]
FlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling , author=. 2026 , eprint=
work page 2026
-
[8]
Defeating the trainer-generator precision mismatch in TRL , author=
-
[9]
VeOmni: Scaling Any Modality Model Training with Model-Centric Distributed Recipe Zoo , author=. 2025 , eprint=
work page 2025
- [10]
-
[11]
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , eprint=
work page 2023
-
[12]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills , author=. 2023 , eprint=
work page 2023
-
[13]
2025 , howpublished =
work page 2025
-
[14]
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism , author=. 2019 , eprint=
work page 2019
- [15]
-
[16]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Fine-Tuning Language Models from Human Preferences
Fine-Tuning Language Models from Human Preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[18]
Advances in Neural Information Processing Systems , volume=
Learning to summarize with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2512.01374 , year=
Stabilizing Reinforcement Learning with LLMs: Formulation and Practices , author=. arXiv preprint arXiv:2512.01374 , year=
-
[20]
When Speed Kills Stability: Demystifying
Liu, Jiacai and Li, Yingru and Fu, Yuqian and Wang, Jiawei and Liu, Qian and Shen, Yu , year=. When Speed Kills Stability: Demystifying
-
[21]
arXiv preprint arXiv:2510.18855 , year=
Learning for Trillion-Scale Thinking Model , author=. arXiv preprint arXiv:2510.18855 , year=
-
[22]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=
-
[23]
Deterministic Inference across Tensor Parallel Sizes That Eliminates Training-Inference Mismatch , author=. 2025 , eprint=
work page 2025
-
[24]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
- [25]
-
[26]
Guo, Daya and Yang, Dejian and Zhang, Haowei and others , journal =. 2025 , url =
work page 2025
-
[27]
Yu, Qiying and Zhang, Zheng and Zhu, Ruofei and Yuan, Yufeng and Zuo, Xiaochen and Yue, Yu and Dai, Weinan and Fan, Tiantian and Liu, Gaohong and Liu, Lingjun and others , journal =. 2025 , url =
work page 2025
-
[28]
Group Sequence Policy Optimization
Group Sequence Policy Optimization , author =. arXiv preprint arXiv:2507.18071 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
On the Rollout-Training Mismatch in Modern
Feng Yao and Liyuan Liu and Dinghuai Zhang and Chengyu Dong and Jingbo Shang and Jianfeng Gao , booktitle=. On the Rollout-Training Mismatch in Modern. 2025 , url=
work page 2025
-
[30]
Defeating the Training-Inference Mismatch via
Qi, Penghui and Liu, Zichen and Zhou, Xinyu and Pang, Tianyu and Du, Chao and Lee, Wee Sun and Lin, Min , journal =. Defeating the Training-Inference Mismatch via. 2025 , url =
work page 2025
-
[31]
Ma, Wenxuan and Zhang, Hangyu and Zhao, Lei and Song, Yuhao and Wang, Yue and Sui, Zhifeng and Luo, Fuwen , journal =. Stabilizing. 2025 , url =
work page 2025
- [32]
-
[33]
Trust Region Masking for Long-Horizon LLM Reinforcement Learning , author=. 2026 , eprint=
work page 2026
-
[34]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization , author=. 2025 , eprint=
work page 2025
-
[35]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. 2025 , eprint=
work page 2025
-
[36]
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author =. Machine Learning , volume =. 1992 , doi =
work page 1992
- [37]
-
[38]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel , author=. 2023 , eprint=
work page 2023
-
[39]
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models , author=. 2020 , eprint=
work page 2020
-
[40]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism , author=. 2020 , eprint=
work page 2020
-
[41]
SGLang: Efficient Execution of Structured Language Model Programs , author=. 2024 , eprint=
work page 2024
-
[42]
Advances in Neural Information Processing Systems , volume =
Root Mean Square Layer Normalization , author =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
work page 2019
- [43]
-
[44]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Openrlhf: An easy-to-use, scalable and high-performance rlhf framework , author=. arXiv preprint arXiv:2405.11143 , volume=
work page internal anchor Pith review arXiv
-
[45]
HybridFlow: A Flexible and Efficient RLHF Framework , url=
Sheng, Guangming and Zhang, Chi and Ye, Zilingfeng and Wu, Xibin and Zhang, Wang and Zhang, Ru and Peng, Yanghua and Lin, Haibin and Wu, Chuan , year=. HybridFlow: A Flexible and Efficient RLHF Framework , url=. doi:10.1145/3689031.3696075 , booktitle=
-
[46]
Introducing Miles: RL Framework To Fire Up Large-Scale MoE Training , author=. 2025 , howpublished=
work page 2025
-
[47]
SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning , author =
-
[48]
Areal: A large-scale asynchronous reinforcement learning system for language reasoning , author=. arXiv preprint arXiv:2505.24298 , year=
-
[49]
arXiv preprint arXiv:2510.12633 , year=
Laminar: A scalable asynchronous rl post-training framework , author=. arXiv preprint arXiv:2510.12633 , year=
-
[50]
arXiv preprint arXiv:2410.18252 , year=
Asynchronous rlhf: Faster and more efficient off-policy rl for language models , author=. arXiv preprint arXiv:2410.18252 , year=
-
[51]
arXiv preprint arXiv:2502.18770 , year=
Reward shaping to mitigate reward hacking in rlhf , author=. arXiv preprint arXiv:2502.18770 , year=
-
[52]
arXiv preprint arXiv:2402.06627 , year=
Feedback loops with language models drive in-context reward hacking , author=. arXiv preprint arXiv:2402.06627 , year=
-
[53]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.