Recognition: no theorem link
TurboVGGT: Fast Visual Geometry Reconstruction with Adaptive Alternating Attention
Pith reviewed 2026-05-15 02:15 UTC · model grok-4.3
The pith
TurboVGGT speeds multi-view 3D reconstruction by learning varying sparsity in attention across frames and layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TurboVGGT is an end-to-end trainable visual geometry transformer that uses adaptive sparse global attention guided by adaptive sparsity selection to model global relationships across frames together with frame attention to aggregate local details inside each frame. The adaptive component learns representative tokens at different sparsity levels because token importance changes across frames, attention layers, and structurally informative regions.
What carries the argument
Adaptive alternating attention that combines adaptive sparse global attention (selecting representative tokens at varying sparsity) with per-frame local attention.
If this is right
- Reconstruction runs in a single forward pass at lower computational cost than earlier visual geometry transformers.
- Quality remains competitive with state-of-the-art methods on standard multi-view benchmarks.
- Sparsity can adjust automatically to frame content and layer abstraction level instead of using a fixed ratio.
- The framework scales more readily to additional input views because global attention cost grows more slowly.
Where Pith is reading between the lines
- The same variable-sparsity idea could be tested in other transformer vision tasks where global context matters but token budgets are tight.
- If the learned sparsity patterns prove consistent, they might guide manual sparsity schedules for related models.
- Extending the approach to video sequences with temporal consistency constraints is a direct next experiment.
Load-bearing premise
That tokens selected adaptively at different sparsity levels will still capture all critical global geometric relationships without dropping essential details in real scenes.
What would settle it
Run the method on a benchmark set containing scenes with high geometric complexity or unusual lighting; if reconstruction error rises sharply compared with non-adaptive baselines while speed gains remain, the central claim fails.
Figures
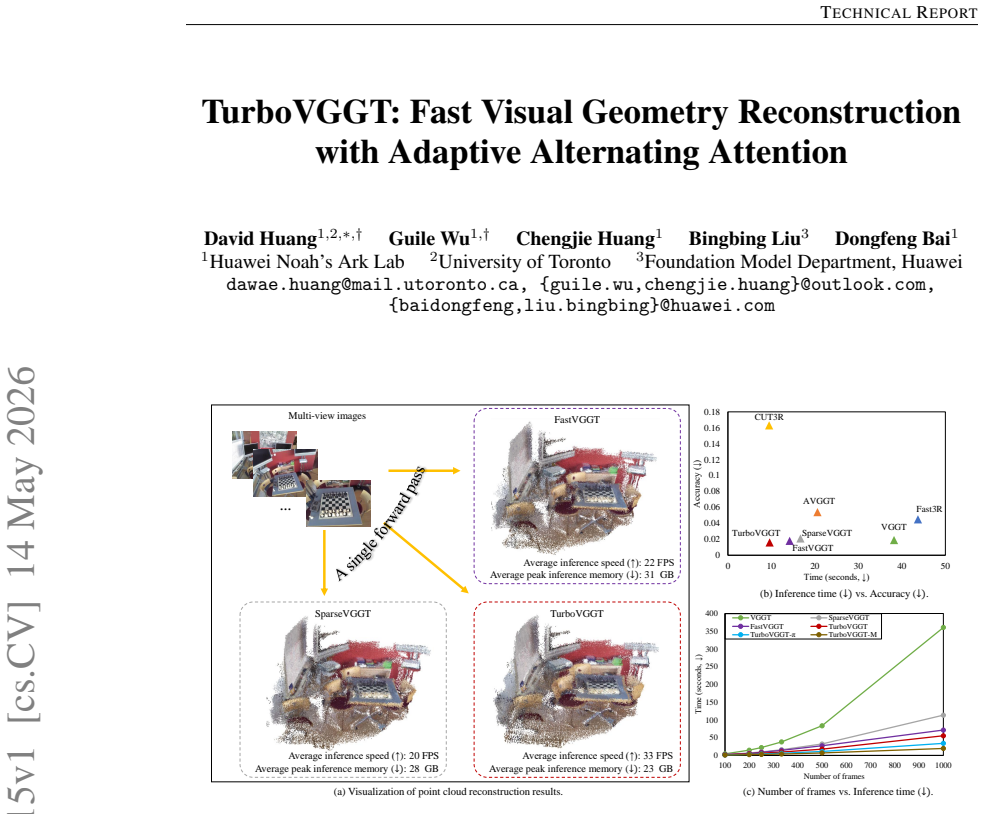


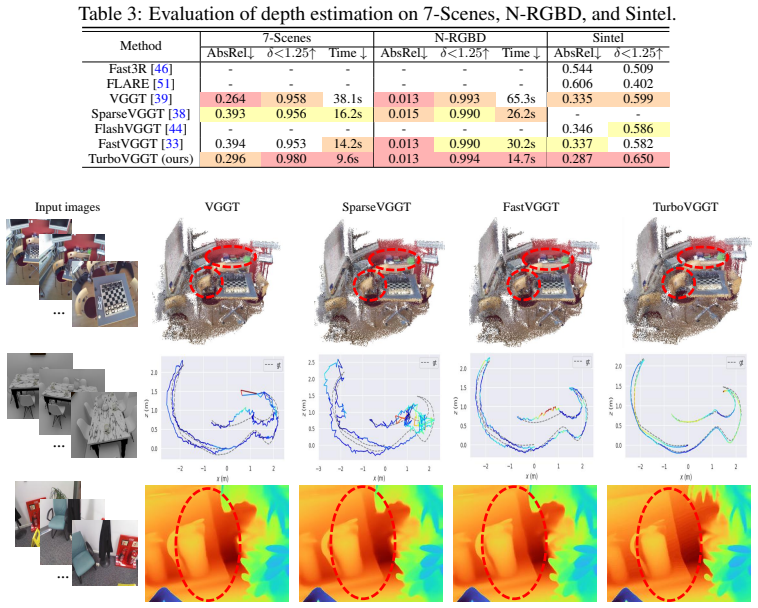



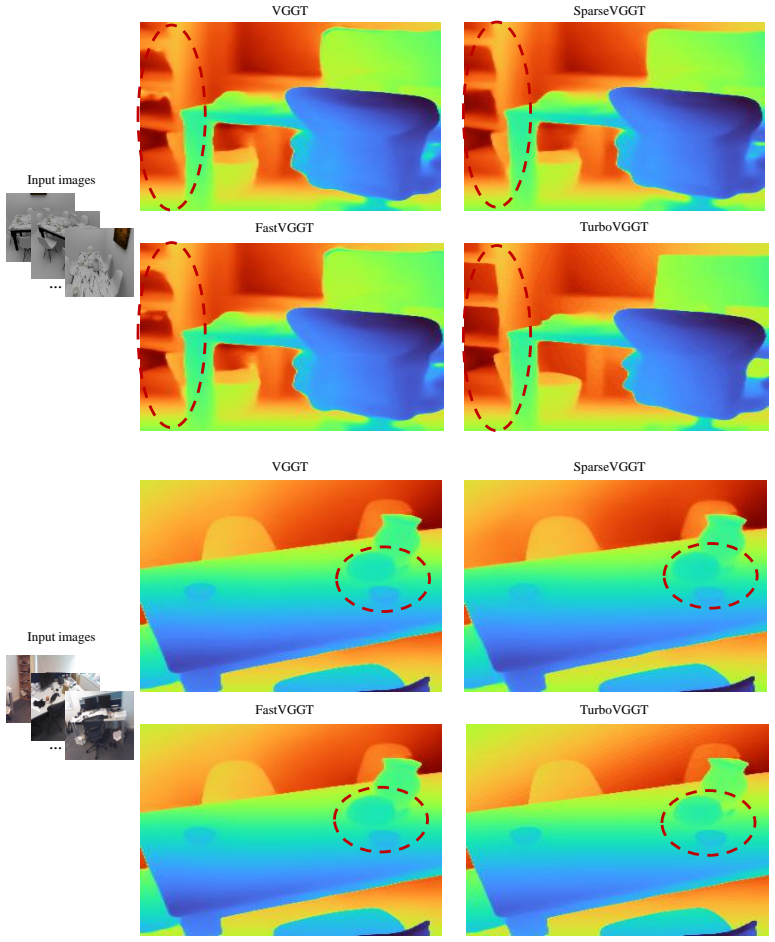
read the original abstract
Recent feed-forward 3D reconstruction methods, such as visual geometry transformers, have substantially advanced the traditional per-scene optimization paradigm by enabling effective multi-view reconstruction in a single forward pass. However, most existing methods struggle to achieve a balance between reconstruction quality and computational efficiency, which limits their scalability and efficiency. Although some efficient visual geometry transformers have recently emerged, they typically use the same sparsity ratio across layers and frames and lack mechanisms to adaptively learn representative tokens to capture global relationships, leading to suboptimal performance. In this work, we propose TurboVGGT, a novel approach that employs an efficient visual geometry transformer with adaptive alternating attention for fast multi-view 3D reconstruction. Specifically, TurboVGGT employs an end-to-end trainable framework with adaptive sparse global attention guided by adaptive sparsity selection to capture global relationships across frames and frame attention to aggregate local details within each frame. In the adaptive sparse global attention, TurboVGGT adaptively learns representative tokens with varying sparsity levels for global geometry modeling, considering that token importance varies across frames, attention layers operate tokens at different levels of abstraction, and global dependencies rely on structurally informative regions. Extensive experiments on multiple 3D reconstruction benchmarks demonstrate that TurboVGGT achieves fast multi-view reconstruction while maintaining competitive reconstruction quality compared with state-of-the-art methods. Project page: https://turbovggt.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TurboVGGT, an efficient visual geometry transformer for fast multi-view 3D reconstruction. It introduces an end-to-end trainable framework with adaptive alternating attention, consisting of adaptive sparse global attention that learns representative tokens with varying sparsity levels across frames, layers, and structurally informative regions to capture global relationships, combined with frame attention to aggregate local details within each frame. Experiments on multiple 3D reconstruction benchmarks are reported to demonstrate that the method achieves fast reconstruction while maintaining competitive quality relative to state-of-the-art approaches.
Significance. If the empirical results hold, the work is significant because it directly targets the quality-efficiency trade-off in feed-forward 3D reconstruction by replacing fixed sparsity ratios with learned, context-dependent token selection. This could improve scalability for real-world multi-view pipelines without sacrificing geometric fidelity, building on prior visual geometry transformers while adding adaptive mechanisms that align with varying token importance.
minor comments (3)
- [Abstract] Abstract: The claim of 'competitive reconstruction quality' and 'fast multi-view reconstruction' is stated without any numerical metrics, error bars, or specific benchmark scores; adding at least the key numbers (e.g., Chamfer distance, PSNR, runtime) from the main results table would make the central claim immediately verifiable.
- [§3] §3 (Method): The description of the adaptive sparsity selection module lacks concrete implementation details such as the architecture of the sparsity predictor, the loss terms used to train it, and the exact range of allowed sparsity ratios; these are load-bearing for reproducing the claimed adaptivity.
- [Experiments] Experiments section: While multiple benchmarks are mentioned, the manuscript should include an explicit ablation isolating the contribution of per-frame/layer adaptive sparsity versus a fixed-ratio baseline to substantiate the weakest assumption about reliable capture of global geometry.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the work's significance in targeting the quality-efficiency trade-off via learned adaptive token selection, and recommendation for minor revision. We appreciate the constructive feedback on our adaptive alternating attention framework.
Circularity Check
No significant circularity detected
full rationale
The paper introduces an end-to-end trainable neural architecture (TurboVGGT) with adaptive sparse global attention and frame attention for multi-view 3D reconstruction. No mathematical derivations, equations, or first-principles predictions are described that reduce to fitted parameters or self-referential definitions by construction. Performance claims rest on external benchmark comparisons rather than internal reductions. The method is presented as a coherent, trainable framework without load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms in transformers can model global and local relationships in multi-view image data for 3D geometry reconstruction.
Reference graph
Works this paper leans on
-
[1]
Mapillary planet-scale depth dataset
Manuel López Antequera, Pau Gargallo, Markus Hofinger, Samuel Rota Bulo, Yubin Kuang, and Peter Kontschieder. Mapillary planet-scale depth dataset. InEuropean Conference on Computer Vision, pages 589–604. Springer, 2020
work page 2020
-
[2]
Scene- script: Reconstructing scenes with an autoregressive structured language model
Armen Avetisyan, Christopher Xie, Henry Howard-Jenkins, Tsun-Yi Yang, Samir Aroudj, Suvam Patra, Fuyang Zhang, Duncan Frost, Luke Holland, Campbell Orme, et al. Scene- script: Reconstructing scenes with an autoregressive structured language model. InEuropean Conference on Computer Vision, pages 247–263. Springer, 2024
work page 2024
-
[3]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6290–6301, 2022
work page 2022
-
[4]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[5]
A naturalistic open source movie for optical flow evaluation
Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A naturalistic open source movie for optical flow evaluation. InEuropean conference on computer vision, pages 611–625. Springer, 2012
work page 2012
-
[6]
TTT3r: 3d re- construction as test-time training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. TTT3r: 3d re- construction as test-time training. InThe F ourteenth International Conference on Learning Representations, 2026
work page 2026
-
[7]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
work page 2017
-
[8]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
work page 2022
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[11]
Vgg-t 3: Offline feed-forward 3d reconstruction at scale.arXiv preprint arXiv:2602.23361, 2026
Sven Elflein, Ruilong Li, Sérgio Agostinho, Zan Gojcic, Laura Leal-Taixé, Qunjie Zhou, and Aljosa Osep. Vgg-t 3: Offline feed-forward 3d reconstruction at scale.arXiv preprint arXiv:2602.23361, 2026
-
[12]
Yasutaka Furukawa and Carlos Hernández. Multi-view stereo: A tutorial.F oundations and Trends in Computer Graphics and Vision, 9(1-2):1–148, 2015
work page 2015
-
[13]
Agent attention: On the integration of softmax and linear attention
Dongchen Han, Tianzhu Ye, Yizeng Han, Zhuofan Xia, Siyuan Pan, Pengfei Wan, Shiji Song, and Gao Huang. Agent attention: On the integration of softmax and linear attention. In European conference on computer vision, pages 124–140. Springer, 2024
work page 2024
-
[14]
Enhancing 3d recon- struction for dynamic scenes
Jisang Han, Honggyu An, Jaewoo Jung, Takuya Narihira, Junyoung Seo, Kazumi Fukuda, Chaehyun Kim, Sunghwan Hong, Yuki Mitsufuji, and Seungryong Kim. Enhancing 3d recon- struction for dynamic scenes. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[15]
Yuan-Ting Hu, Jiahong Wang, Raymond A Yeh, and Alexander G Schwing. Sail-vos 3d: A synthetic dataset and baselines for object detection and 3d mesh reconstruction from video data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1418–1428, 2021
work page 2021
-
[16]
Deepmvs: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. Deepmvs: Learning multi-view stereopsis. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2821–2830, 2018
work page 2018
-
[17]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–4664. PMLR, 2021. 10
work page 2021
-
[18]
ZipMap: Linear-Time Stateful 3D Reconstruction via Test-Time Training
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T Barron, Noah Snavely, and Aleksander Holynski. Zipmap: Linear-time stateful 3d reconstruction via test-time training. arXiv preprint arXiv:2603.04385, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Dynamicstereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Dynamicstereo: Consistent dynamic depth from stereo videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13229–13239, 2023
work page 2023
-
[20]
Mapanything: Universal feed-forward metric 3d reconstruction
Nikhil Varma Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. Mapanything: Universal feed-forward metric 3d reconstructio...
work page 2026
-
[21]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
work page 2024
-
[22]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[23]
Megadepth: Learning single-view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018
work page 2041
-
[24]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
work page 2024
-
[25]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nalivayko, and Andrés Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4981–4991, 2023
work page 2023
-
[26]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
work page 2024
-
[27]
Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 7855–7862. IEEE, 2019
work page 2019
-
[28]
Global structure- from-motion revisited
Linfei Pan, Dániel Baráth, Marc Pollefeys, and Johannes L Schönberger. Global structure- from-motion revisited. InEuropean Conference on Computer Vision, pages 58–77. Springer, 2024
work page 2024
-
[29]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179– 12188, 2021
work page 2021
-
[30]
Speed3r: Sparse feed-forward 3d reconstruction models
Weining Ren, Xiao Tan, and Kai Han. Speed3r: Sparse feed-forward 3d reconstruction models. arXiv preprint arXiv:2603.08055, 2026
-
[31]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
work page 2016
-
[32]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean conference on computer vision, pages 501–518. Springer, 2016
work page 2016
-
[33]
FastVGGT: Fast visual geometry transformer
You Shen, Zhipeng Zhang, Yansong Qu, Xiawu Zheng, Jiayi Ji, Shengchuan Zhang, and Liujuan Cao. FastVGGT: Fast visual geometry transformer. InThe F ourteenth International Conference on Learning Representations, 2026. 11
work page 2026
-
[34]
Scene coordinate regression forests for camera relocalization in rgb-d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb-d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013
work page 2013
-
[35]
Avggt: Rethinking global attention for accelerating vggt.arXiv preprint arXiv:2512.02541, 2025
Xianbing Sun, Zhikai Zhu, Zhengyu Lou, Bo Yang, Jinyang Tang, Liqing Zhang, He Wang, and Jianfu Zhang. Avggt: Rethinking global attention for accelerating vggt.arXiv preprint arXiv:2512.02541, 2025
-
[36]
Smd-nets: Stereo mixture density networks
Fabio Tosi, Yiyi Liao, Carolin Schmitt, and Andreas Geiger. Smd-nets: Stereo mixture density networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8942–8952, 2021
work page 2021
-
[37]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. InEuropean Conference on Computer Vision, pages 313–331. Springer, 2024
work page 2024
-
[38]
Faster vggt with block-sparse global attention.arXiv preprint arXiv:2509.07120, 2025
Chung-Shien Brian Wang, Christian Schmidt, Jens Piekenbrinck, and Bastian Leibe. Faster vggt with block-sparse global attention.arXiv preprint arXiv:2509.07120, 2025
-
[39]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[40]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
work page 2025
-
[41]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
work page 2024
-
[42]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020
work page 2020
-
[43]
π3: Scalable permutation-equivariant visual geometry learning.arXiv e-prints, pages arXiv–2507, 2025
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry learning.arXiv e-prints, pages arXiv–2507, 2025
work page 2025
-
[44]
Zipeng Wang and Dan Xu. Flashvggt: Efficient and scalable visual geometry transformers with compressed descriptor attention.arXiv preprint arXiv:2512.01540, 2025
-
[45]
Sparsifiner: Learning sparse instance-dependent attention for efficient vision transformers
Cong Wei, Brendan Duke, Ruowei Jiang, Parham Aarabi, Graham W Taylor, and Florian Shkurti. Sparsifiner: Learning sparse instance-dependent attention for efficient vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22680–22689, 2023
work page 2023
-
[46]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
work page 2025
-
[47]
Blendedmvs: A large-scale dataset for generalized multi-view stereo networks
Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large-scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1790–1799, 2020
work page 2020
-
[48]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
work page 2023
-
[49]
Not all tokens are equal: Human-centric visual analysis via token clustering transformer
Wang Zeng, Sheng Jin, Wentao Liu, Chen Qian, Ping Luo, Wanli Ouyang, and Xiaogang Wang. Not all tokens are equal: Human-centric visual analysis via token clustering transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11101–11111, 2022. 12
work page 2022
-
[50]
Spargeattention: Accurate and training-free sparse attention accelerating any model inference
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattention: Accurate and training-free sparse attention accelerating any model inference. InInternational Conference on Machine Learning, pages 76397–76413. PMLR, 2025
work page 2025
-
[51]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gordon Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025
work page 2025
-
[52]
Yuchen Zhang, Nikhil Keetha, Chenwei Lyu, Bhuvan Jhamb, Yutian Chen, Yuheng Qiu, Jay Karhade, Shreyas Jha, Yaoyu Hu, Deva Ramanan, et al. Ufm: A simple path towards unified dense correspondence with flow.arXiv preprint arXiv:2506.09278, 2025
-
[53]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifica- tion: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
work page 2018
-
[54]
Streaming visual geometry transformer
Dong Zhuo, Wenzhao Zheng, Jiahe Guo, Yuqi Wu, Jie Zhou, and Jiwen Lu. Streaming visual geometry transformer. InThe F ourteenth International Conference on Learning Representations, 2026. A Technical appendices and supplementary material A.1 Limitation and Future Work While the proposed TurboVGGT achieves superior performance on fast multi-view 3D reconstr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.