Recognition: 2 theorem links
· Lean TheoremDistributionally Robust Multi-Task Reinforcement Learning via Adaptive Task Sampling
Pith reviewed 2026-05-15 03:01 UTC · model grok-4.3
The pith
Adaptive sampling of hard tasks via a minimax objective improves worst-case performance in multi-task reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
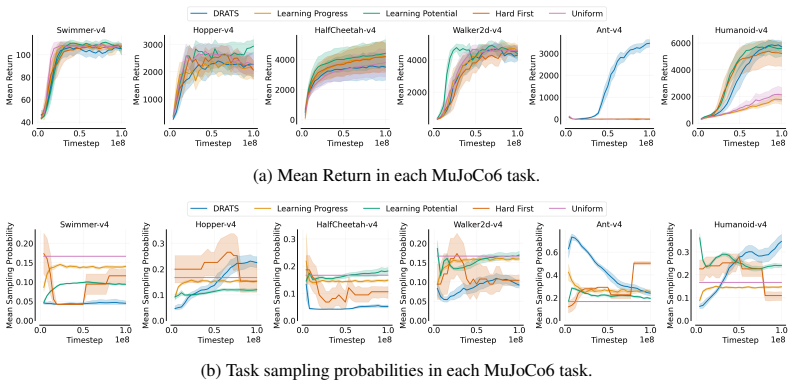
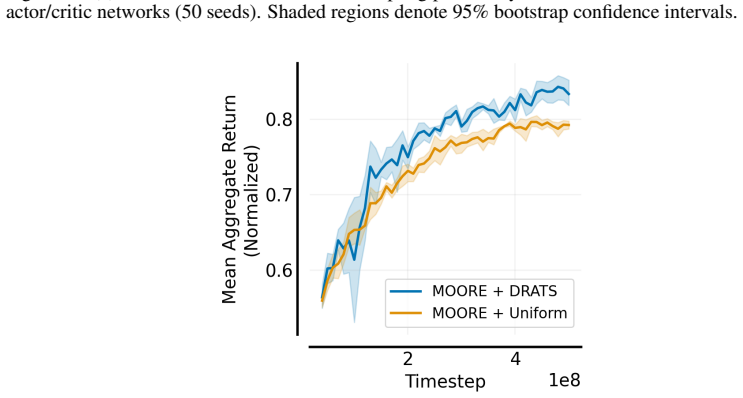
Formalizing multi-task reinforcement learning as the search for a single policy that meets target returns on every task yields a minimax objective over sampling distributions. The objective minimizes the worst-case return gap, and its solution is a sampling distribution that places higher probability on tasks whose current return is farthest from the target. DRATS implements this distribution by estimating gaps from recent rollouts and sampling accordingly, producing more balanced learning curves than uniform allocation.
What carries the argument
The minimax objective over task-sampling distributions that minimizes the maximum return gap across tasks, whose solution supplies the adaptive sampling weights used by DRATS.
If this is right
- DRATS improves data efficiency relative to uniform and other fixed sampling schedules on MetaWorld-MT10 and MT50.
- Worst-task performance rises because hard tasks receive proportionally more interactions.
- The same sampling rule can be applied on top of any base multi-task algorithm without altering gradients or architecture.
- Balanced allocation reduces the total environment interactions needed to bring every task above a performance threshold.
Where Pith is reading between the lines
- The same minimax construction could be applied to non-RL multi-task problems where data budget must be allocated across subtasks of unequal difficulty.
- Online estimation of return gaps might be replaced by learned predictors of task difficulty to reduce variance in the sampling weights.
- Combining DRATS with existing gradient-conflict methods could address both data imbalance and optimization conflicts simultaneously.
Load-bearing premise
That adaptively sampling tasks furthest from their target returns will steadily close those gaps without introducing instability or requiring extra assumptions about how task difficulty evolves.
What would settle it
An experiment on MetaWorld-MT50 in which DRATS produces lower worst-task return or requires more total steps than uniform sampling to reach the same worst-task return.
Figures














read the original abstract
Multi-task reinforcement learning (MTRL) aims to train a single agent to efficiently optimize performance across multiple tasks simultaneously. However, jointly optimizing all tasks often yields imbalanced learning: agents quickly solve easy tasks but learn slowly on harder ones. While prior work primarily attributes this imbalance to conflicting task gradients and proposes gradient manipulation or specialized architectures to address it, we instead focus on a distinct and under-explored challenge: imbalanced data allocation. Standard MTRL allocates an equal number of environment interactions to each task, which over-allocates data to easy tasks that require relatively few interactions to solve and under-allocates data to hard tasks that require substantially more experience to solve. To address this challenge, we introduce Distributionally Robust Adaptive Task Sampling (DRATS), an algorithm that adaptively prioritizes sampling tasks furthest from being solved. We derive DRATS by formalizing MTRL as a feasibility problem from which we derive a minimax objective for minimizing the worst-case return gap, the difference between a desired target return and the agent's return on a task. In benchmarks like MetaWorld-MT10 and MT50, DRATS improves data efficiency and increases worst-task performance compared to existing task sampling algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Distributionally Robust Adaptive Task Sampling (DRATS) for multi-task reinforcement learning (MTRL). It formalizes MTRL as a feasibility problem from which a minimax objective is derived to minimize the worst-case return gap (target return minus achieved return) across tasks. DRATS uses this to adaptively sample tasks furthest from being solved, addressing imbalanced data allocation where easy tasks receive excess interactions and hard tasks receive too few. Experiments on MetaWorld-MT10 and MT50 show gains in data efficiency and worst-task performance over prior task-sampling baselines.
Significance. If the results hold, the work supplies a principled, distributionally robust alternative to gradient-manipulation methods for MTRL imbalance. The feasibility-to-minimax derivation supplies independent theoretical grounding, and the reported benchmark improvements in data efficiency and worst-task performance are practically relevant for heterogeneous task suites. The contribution is strengthened by the absence of free parameters or ad-hoc axioms.
major comments (2)
- [§3] §3 (feasibility-to-minimax derivation): The transition from the MTRL feasibility problem to the explicit minimax objective over return gaps must be expanded with all intermediate steps and any regularity conditions; without them the central claim that the sampler is distributionally robust cannot be fully verified.
- [§5.2] §5.2 (MetaWorld-MT50 results): The reported improvement in worst-task performance lacks confidence intervals, statistical significance tests, or ablation on the effect of the adaptive threshold; this weakens the data-efficiency claim.
minor comments (2)
- [Abstract] Abstract and §2: Define 'return gap' explicitly on first use and state the precise target-return value used in the minimax objective.
- [§4] §4 (algorithm): Clarify the practical approximation used for the worst-case expectation (e.g., number of samples or dual formulation) so that the sampler can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. The comments highlight opportunities to strengthen the theoretical exposition and empirical rigor, and we will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§3] §3 (feasibility-to-minimax derivation): The transition from the MTRL feasibility problem to the explicit minimax objective over return gaps must be expanded with all intermediate steps and any regularity conditions; without them the central claim that the sampler is distributionally robust cannot be fully verified.
Authors: We agree that the derivation requires additional detail for full verifiability. In the revised manuscript we will insert a complete step-by-step expansion of the transition from the feasibility formulation (Eq. 3) through the Lagrangian and dualization steps to the final minimax objective (Eq. 7), explicitly stating the regularity conditions used (bounded returns in [0, R_max], Lipschitz continuity of the value functions, and compactness of the task distribution simplex). These additions will make the distributional-robustness argument self-contained. revision: yes
-
Referee: [§5.2] §5.2 (MetaWorld-MT50 results): The reported improvement in worst-task performance lacks confidence intervals, statistical significance tests, or ablation on the effect of the adaptive threshold; this weakens the data-efficiency claim.
Authors: We accept the critique. The revised version will report 95% confidence intervals over 5 independent seeds for all MT50 metrics, include paired statistical significance tests (Wilcoxon signed-rank) against the strongest baselines, and add an ablation table varying the adaptive threshold parameter to quantify its contribution to data efficiency and worst-task performance. revision: yes
Circularity Check
Derivation from feasibility formalization is independent
full rationale
The paper derives the DRATS minimax objective by formalizing multi-task RL as a feasibility problem over worst-case return gaps. This is a direct mathematical construction from the stated problem definition rather than a reduction to fitted parameters, self-citations, or prior ansatzes. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The approach remains self-contained against external benchmarks, yielding a normal non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-task RL can be cast as a feasibility problem whose solution minimizes worst-case return gaps
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive DRATS by formalizing MTRL as a feasibility problem from which we derive a minimax objective for minimizing the worst-case return gap
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
q*_i = exp(η g_i(θ)) / sum exp(η g_j(θ))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AutoMixAlign: Adaptive Data Mixing for Multi-Task Preference Optimization in LLMs , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
arXiv preprint arXiv:2408.14037 , year=
Re-mix: Optimizing data mixtures for large scale imitation learning , author=. arXiv preprint arXiv:2408.14037 , year=
-
[4]
Distributionally robust losses against mixture covariate shifts , author=. Under review , volume=
-
[5]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. arXiv preprint arXiv:1911.08731 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
Advances in Neural Information Processing Systems , volume=
Offline reinforcement learning with reverse model-based imagination , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Selective Data Augmentation for Improving the Performance of Offline Reinforcement Learning , year=
Han, Jungwoo and Kim, Jinwhan , booktitle=. Selective Data Augmentation for Improving the Performance of Offline Reinforcement Learning , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Counterfactual data augmentation using locally factored dynamics , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Proceedings of the 5th Conference on Robot Learning , pages =
S4RL: Surprisingly Simple Self-Supervision for Offline Reinforcement Learning in Robotics , author =. Proceedings of the 5th Conference on Robot Learning , pages =. 2022 , editor =
work page 2022
-
[10]
A Swapping Target Q-Value Technique for Data Augmentation in Offline Reinforcement Learning , year=
Joo, Ho-Taek and Baek, In-Chang and Kim, Kyung-Joong , journal=. A Swapping Target Q-Value Technique for Data Augmentation in Offline Reinforcement Learning , year=
-
[11]
Advances in Neural Information Processing Systems , year=
S2P: State-conditioned Image Synthesis for Data Augmentation in Offline Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Advances in Neural Information Processing Systems , year=
Bootstrapped transformer for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[13]
arXiv preprint arXiv:2211.11603 , year=
Model-based Trajectory Stitching for Improved Offline Reinforcement Learning , author=. arXiv preprint arXiv:2211.11603 , year=
-
[14]
Offline Learning from Demonstrations and Unlabeled Experience , author=. ArXiv , year=
-
[15]
Sample-Efficient Reinforcement Learning via Counterfactual-Based Data Augmentation , author =. Offline Reinforcement Learning - Workshop at the 34th Conference on Neural Information Processing Systems (NeurIPS) , year =
-
[16]
Dota 2 with Large Scale Deep Reinforcement Learning , author=. 2019 , eprint=
work page 2019
-
[18]
Grandmaster level in StarCraft II using multi-agent reinforcement learning , author=. Nature , volume=. 2019 , publisher=
work page 2019
-
[19]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Way Off-Policy Batch Deep Reinforcement Learning of Implicit Human Preferences in Dialog
Way off-policy batch deep reinforcement learning of implicit human preferences in dialog , author=. arXiv preprint arXiv:1907.00456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[21]
Conference on Robot Learning , pages=
Scalable deep reinforcement learning for vision-based robotic manipulation , author=. Conference on Robot Learning , pages=. 2018 , organization=
work page 2018
-
[22]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[23]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[24]
Magnetic control of tokamak plasmas through deep reinforcement learning , author=. Nature , volume=. 2022 , publisher=
work page 2022
-
[25]
Outracing champion Gran Turismo drivers with deep reinforcement learning , author=. Nature , volume=. 2022 , publisher=
work page 2022
-
[26]
Advances in Neural Information Processing Systems , volume=
Robust On-Policy Sampling for Data-Efficient Policy Evaluation in Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Advances in neural information processing systems , volume=
Interpolated policy gradient: Merging on-policy and off-policy gradient estimation for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[28]
Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic
Q-prop: Sample-efficient policy gradient with an off-policy critic , author=. arXiv preprint arXiv:1611.02247 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Uncertainty in Artificial Intelligence , pages=
P3o: Policy-on policy-off policy optimization , author=. Uncertainty in Artificial Intelligence , pages=. 2020 , organization=
work page 2020
-
[30]
Deep Reinforcement Learning with Python: With PyTorch, TensorFlow and OpenAI Gym , pages=
Combining Policy Gradient and Q-Learning , author=. Deep Reinforcement Learning with Python: With PyTorch, TensorFlow and OpenAI Gym , pages=. 2021 , publisher=
work page 2021
-
[31]
Sample Efficient Actor-Critic with Experience Replay
Sample efficient actor-critic with experience replay , author=. arXiv preprint arXiv:1611.01224 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
2019 IEEE conference on games (CoG) , pages=
Combining experience replay with exploration by random network distillation , author=. 2019 IEEE conference on games (CoG) , pages=. 2019 , organization=
work page 2019
-
[34]
arXiv preprint arXiv:2001.05270 , year=
Continuous-action reinforcement learning for playing racing games: Comparing SPG to PPO , author=. arXiv preprint arXiv:2001.05270 , year=
- [35]
- [36]
- [37]
-
[38]
Advances in Neural Information Processing Systems , volume=
The difficulty of passive learning in deep reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Joonho Lee and Jemin Hwangbo and Lorenz Wellhausen and Vladlen Koltun and Marco Hutter , title =. Science Robotics , volume =
-
[40]
arXiv preprint arXiv:1910.07113 , year=
Solving rubik's cube with a robot hand , author=. arXiv preprint arXiv:1910.07113 , year=
-
[41]
AAAI Spring Symposium Series , year=
Run, skeleton, run: skeletal model in a physics-based simulation , author =. AAAI Spring Symposium Series , year=
-
[42]
Motion, Interaction and Games , pages=
On learning symmetric locomotion , author=. Motion, Interaction and Games , pages=
-
[43]
Advances in neural information processing systems , volume=
Reinforcement learning with augmented data , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in Neural Information Processing Systems , volume=
Mocoda: Model-based counterfactual data augmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Advances in neural information processing systems , volume=
Hindsight experience replay , author=. Advances in neural information processing systems , volume=
-
[46]
International Conference on Learning Representations , year=
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels , author=. International Conference on Learning Representations , year=
-
[47]
Reinforcement learning: An introduction , author=. 2018 , publisher=
work page 2018
-
[48]
RL Course by David Silver, Lecture 5: Model-Free Control , author=
-
[49]
Achiam, Joshua , title =
-
[50]
International Conference on Learning Representations (ICLR) , year=
Understanding when Dynamics-Invariant Data Augmentations Benefit Model-Free Reinforcement Learning Updates , author=. International Conference on Learning Representations (ICLR) , year=
-
[51]
Guided Data Augmentation for Offline Reinforcement Learning and Imitation Learning , author=. 2024 , journal=
work page 2024
-
[52]
On-Policy Policy Gradient Reinforcement Learning Without On-Policy Sampling , author=. Under Review , year=
-
[53]
Reinforcement learning , pages=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Reinforcement learning , pages=. 1992 , publisher=
work page 1992
-
[54]
Advances in Neural Information Processing Systems , volume=
The surprising effectiveness of ppo in cooperative multi-agent games , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Advances in Neural Information Processing Systems , volume=
(More) efficient reinforcement learning via posterior sampling , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in neural information processing systems , volume=
\# exploration: A study of count-based exploration for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[57]
6th International Conference on Learning Representations,
Sainbayar Sukhbaatar and Zeming Lin and Ilya Kostrikov and Gabriel Synnaeve and Arthur Szlam and Rob Fergus , title =. 6th International Conference on Learning Representations,. 2018 , url =
work page 2018
-
[58]
International conference on machine learning , pages=
Count-based exploration with neural density models , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[59]
International conference on machine learning , pages=
Curiosity-driven exploration by self-supervised prediction , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[60]
Computer Science Department Faculty Publication Series , pages=
Eligibility traces for off-policy policy evaluation , author=. Computer Science Department Faculty Publication Series , pages=
-
[61]
advances in neural information processing systems , volume=
The self-normalized estimator for counterfactual learning , author=. advances in neural information processing systems , volume=
-
[62]
International Conference on Machine Learning , pages=
Data-efficient off-policy policy evaluation for reinforcement learning , author=. International Conference on Machine Learning , pages=. 2016 , organization=
work page 2016
-
[63]
Kingma and Jimmy Ba , editor =
Diederik P. Kingma and Jimmy Ba , editor =. Adam:. 3rd International Conference on Learning Representations,. 2015 , url =
work page 2015
-
[64]
Markov decision processes: discrete stochastic dynamic programming , author=. 2014 , publisher=
work page 2014
-
[65]
Importance sampling in reinforcement learning with an estimated behavior policy , author=. Machine Learning , volume=. 2021 , publisher=
work page 2021
-
[66]
International Conference on Machine Learning , year=
Reducing Sampling Error in Batch Temporal Difference Learning , author=. International Conference on Machine Learning , year=
-
[67]
Advances in Neural Information Processing Systems , volume=
Active offline policy selection , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
Advances in Neural Information Processing Systems , volume=
Conservative data sharing for multi-task offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
- [69]
-
[70]
International Conference on Machine Learning , pages=
Doubly robust off-policy value evaluation for reinforcement learning , author=. International Conference on Machine Learning , pages=. 2016 , organization=
work page 2016
-
[71]
arXiv preprint arXiv:2202.01721 , year=
Variance-optimal augmentation logging for counterfactual evaluation in contextual bandits , author=. arXiv preprint arXiv:2202.01721 , year=
-
[72]
International Conference on Machine Learning , pages=
Safe exploration for efficient policy evaluation and comparison , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Efficient counterfactual learning from bandit feedback , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[74]
Artificial Intelligence and Statistics , pages=
Toward minimax off-policy value estimation , author=. Artificial Intelligence and Statistics , pages=. 2015 , organization=
work page 2015
-
[75]
Uncertainty in Artificial Intelligence , pages=
ReVar: Strengthening policy evaluation via reduced variance sampling , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
work page 2022
-
[76]
Queeney, James and Paschalidis, Ioannis Ch. and Cassandras, Christos G. , title =. Advances in Neural Information Processing Systems , publisher =
- [77]
-
[78]
Shengyi Huang and Rousslan Fernand Julien Dossa and Chang Ye and Jeff Braga and Dipam Chakraborty and Kinal Mehta and João G.M. Araújo , title =. Journal of Machine Learning Research , year =
-
[79]
Advances in neural information processing systems , volume=
Diversity-driven exploration strategy for deep reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[80]
International conference on machine learning , pages=
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[81]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.