Recognition: no theorem link
The Great Pretender: A Stochasticity Problem in LLM Jailbreak
Pith reviewed 2026-05-15 02:05 UTC · model grok-4.3
The pith
LLM jailbreak success rates drop up to 30 points when prompts must succeed on multiple consecutive attempts due to model stochasticity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
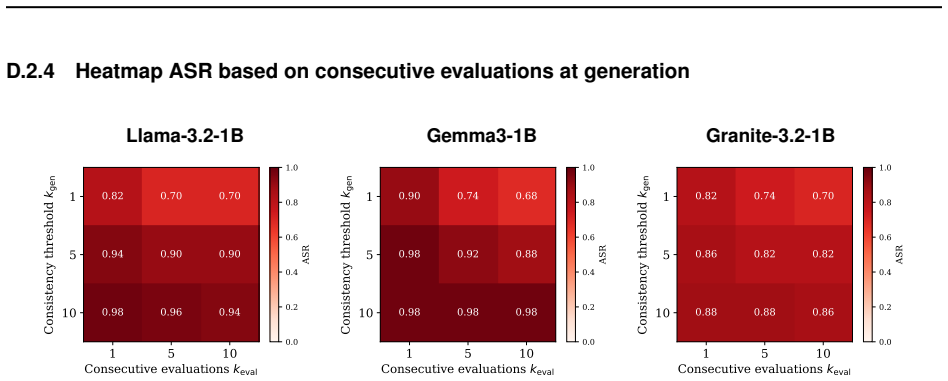
Stochasticity during both attack generation and evaluation makes jailbreak prompt performance inconsistent. Prompts optimized on one set of trials frequently deliver 30 percentage points lower ASR when they must succeed on more than one attempt. The CAS-eval framework quantifies this effect across models, attacks, and judges, while CAS-gen improves prior generation methods to close the gap and restore the original ASR levels.
What carries the argument
CAS-eval and CAS-gen frameworks that enforce multi-attempt success requirements to capture and reduce the effects of model stochasticity on jailbreak ASR.
If this is right
- ASR must be measured over multiple consecutive successful attempts to give a reliable figure.
- Previous jailbreak methods lose up to 30 percentage points when consistency across attempts is required.
- CAS-gen recovers the lost ASR by incorporating stochasticity considerations during prompt generation.
- Published ASR numbers from different papers cannot be compared directly without standardized handling of randomness.
Where Pith is reading between the lines
- Real deployments of jailbreaks face even lower effective success rates because repeated interactions amplify stochastic failures.
- Guardrail testing should prioritize prompts that remain reliable across multiple tries rather than single-shot wins.
- Security benchmarks for LLMs need multi-attempt protocols to avoid overestimating attack effectiveness.
Load-bearing premise
The observed inconsistency in jailbreak success is driven primarily by the target model's stochastic responses rather than by judge variability, prompt formatting, or other unmeasured factors.
What would settle it
Re-evaluate the same set of jailbreak prompts with temperature fixed at zero and check whether the up to 30 percentage point ASR drop disappears.
Figures
























read the original abstract
"Oh-Oh, yes, I'm the great pretender. Pretending that I'm doing well. My need is such, I pretend too much..." summarizes the state in the area of jailbreak creation and evaluation. You find this method to generate adversarial attacks proposed by a reputable institution (e.g., BoN from Anthropic or Crescendo from Microsoft Research). However, this method does not deliver on the promise claimed in the paper despite having top ASR scores against industry-grade LLMs. You successfully generate the jailbreak prompts against your target (open) model. However, the generated jailbreak prompt works against the target model with a 50% consecutive success rate (5 out of 10 attempts) despite having an 80% ASR (on paper) on the latest closed-source model (with a guardrail system)! This observation leads us to think. First, Attack Success Rate (ASR), the primary metric for LLM jailbreak benchmarking, is not a stable quantity. Second, published ASR numbers are therefore systematically inflated and incomparable across papers. Therefore, we wonder "Why a successful jailbreak prompt does not perform consistently well against a target model on which the prompts have been optimized?". To answer this question, we study the impact of stochasticity not only during attack evaluation but also during attack generation. Our evaluation includes several jailbreak attacks, models (different sizes and providers), and judges. In addition, we propose a new metric and two new frameworks (CAS-eval and CAS-gen). Our evaluation framework, CAS-eval, shows that an attack can have an ASR drop of up to 30 percentage points when a jailbreak prompt needs to succeed on more than one attempt. Thankfully, our attack generation framework (CAS-gen) improves previous jailbreak methods and helps them recover this loss of 30 percentage points!
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Attack Success Rate (ASR) metrics for LLM jailbreaks are unstable due to model stochasticity during both evaluation and generation, leading to systematically inflated and incomparable published results. It introduces CAS-eval, which demonstrates ASR drops of up to 30 percentage points when success must hold across multiple independent attempts, and CAS-gen, which augments prior attack methods to recover this performance loss. The evaluation spans multiple jailbreak attacks, models of varying sizes/providers, and judges.
Significance. If the central empirical observations hold after addressing controls, the work would be significant for LLM safety research by exposing a key source of non-reproducibility in jailbreak benchmarking and offering practical frameworks (CAS-eval and CAS-gen) to produce more consistent attacks and evaluations. The explicit quantification of inconsistency across attempts and the recovery via generation improvements could shift community standards toward multi-trial metrics.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation methodology: The headline claim that an attack can exhibit an ASR drop of up to 30pp when requiring success on more than one attempt attributes the inconsistency primarily to target-model stochasticity, yet provides no ablations isolating this from judge-model variance, decoding temperature, or prompt formatting sensitivity. Without fixed-judge baselines or deterministic decoding controls, the 30pp figure risks being an artifact of unmeasured evaluation noise rather than the diagnosed stochasticity problem.
- [CAS-eval] CAS-eval framework description: The procedure for selecting and retaining prompts that achieve high single-attempt ASR before measuring multi-attempt consistency is not detailed enough to exclude post-hoc selection bias; this directly affects whether the reported drop is load-bearing evidence for inflated published ASRs.
- [CAS-gen] CAS-gen recovery claim: The assertion that CAS-gen recovers the full 30pp loss requires explicit comparison against simple baselines (e.g., increased sampling temperature or seed averaging in existing generators) to confirm the improvement stems from the new framework rather than generic variance reduction.
minor comments (2)
- [Evaluation] Provide the exact number of independent trials, models, and judge configurations used to compute the 30pp figure, along with confidence intervals or statistical tests for the drop.
- [CAS-eval] Clarify notation for the new consistency metric in CAS-eval (e.g., how consecutive success rate is formally defined versus single-attempt ASR).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation methodology: The headline claim that an attack can exhibit an ASR drop of up to 30pp when requiring success on more than one attempt attributes the inconsistency primarily to target-model stochasticity, yet provides no ablations isolating this from judge-model variance, decoding temperature, or prompt formatting sensitivity. Without fixed-judge baselines or deterministic decoding controls, the 30pp figure risks being an artifact of unmeasured evaluation noise rather than the diagnosed stochasticity problem.
Authors: We agree that stronger isolation of variance sources is needed. In the revision we will add ablations using a fixed judge model and deterministic decoding (temperature=0) on the target models, reporting separate results to confirm that the observed drops are driven primarily by target-model stochasticity. revision: yes
-
Referee: [CAS-eval] CAS-eval framework description: The procedure for selecting and retaining prompts that achieve high single-attempt ASR before measuring multi-attempt consistency is not detailed enough to exclude post-hoc selection bias; this directly affects whether the reported drop is load-bearing evidence for inflated published ASRs.
Authors: We will expand Section 3.2 with a precise step-by-step description of the selection thresholds, retention criteria, and number of prompts at each stage. We will also add an analysis of multi-attempt drops across the full unfiltered set to address selection-bias concerns. revision: yes
-
Referee: [CAS-gen] CAS-gen recovery claim: The assertion that CAS-gen recovers the full 30pp loss requires explicit comparison against simple baselines (e.g., increased sampling temperature or seed averaging in existing generators) to confirm the improvement stems from the new framework rather than generic variance reduction.
Authors: We will add direct comparisons in the revised experiments against baselines that increase sampling temperature and perform seed averaging on the original generators, demonstrating that CAS-gen yields gains beyond these generic variance-reduction methods. revision: yes
Circularity Check
No significant circularity in empirical jailbreak evaluation
full rationale
The paper is an empirical comparison introducing CAS-eval and CAS-gen to quantify and mitigate ASR inconsistency across repeated attempts. Central claims rest on observed performance deltas across models, attacks, and judges rather than any derivation, fitted parameter renamed as prediction, or self-referential definition. No equations or uniqueness theorems appear; the 30pp drop and recovery are presented as measured outcomes, not constructed by construction from inputs. This is the expected non-finding for a benchmarking study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM responses to the same prompt are independent and stochastic across attempts
invented entities (2)
-
CAS-eval framework
no independent evidence
-
CAS-gen framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Subbarao Kambhampati, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking. Technical report, Anthropic, 2024. arXiv:2412.03556. (Cited on page 1, 2, 6)
-
[2]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm- based input-output safeguard for human-ai conversations. Technical report, Meta AI, 2023. arXiv:2312.06674. (Cited on page 2)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. InarXiv preprint arXiv:2310.08419, 2023. (Cited on page 2, 6)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Tree of attacks: Jailbreaking black-box LLMs automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Y aron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box LLMs automatically. InAdvances in Neural Information Processing Systems, volume 37, 2024. (Cited on page 2, 6)
work page 2024
-
[5]
Mark Russinovich, Ahmed Salem, and Ronen Eldan. Great, now write an article about that: The crescendo multi-turn llm jailbreak attack. InUSENIX Security, 2025. arXiv:2404.01833. (Cited on page 2, 6)
-
[6]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. InarXiv preprint arXiv:2404.01318, 2024. (Cited on page 6)
work page internal anchor Pith review arXiv 2024
-
[7]
Fraser, Hillary Dawkins, Isar Nejadgholi, and Svetlana Kiritchenko
Kathleen C. Fraser, Hillary Dawkins, Isar Nejadgholi, and Svetlana Kiritchenko. Fine-tuning lowers safety and disrupts evaluation consistency. InarXiv preprint arXiv:2506.17209, 2025. (Cited on page 11)
-
[8]
A coin flip for safety: Llm judges fail to reliably measure adversarial robustness
Leo Schwinn, Moritz Ladenburger, Tim Beyer, Mehrnaz Mofakhami, Gauthier Gidel, and Stephan G¨unnemann. A coin flip for safety: Llm judges fail to reliably measure adversarial robustness. In arXiv preprint arXiv:2603.06594, 2026. (Cited on page 11)
-
[9]
Statistical estimation of adversarial risk in large language models under best-of-n sampling
Mingqian Feng, Xiaodong Liu, Weiwei Y ang, Chenliang Xu, Christopher White, and Jianfeng Gao. Statistical estimation of adversarial risk in large language models under best-of-n sampling. InarXiv preprint arXiv:2601.22636, 2026. (Cited on page 11, 14)
-
[10]
Hugging face hub.https://huggingface.co, 2023
Hugging Face. Hugging face hub.https://huggingface.co, 2023. (Cited on page 13)
work page 2023
-
[11]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Y acine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art n...
work page 2020
-
[12]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.Journal of the American Statistical Association, 22(158):209–212, 1927. (Cited on page 14)
work page 1927
-
[13]
Stegun.Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical T ables
Milton Abramowitz and Irene A. Stegun.Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical T ables. National Bureau of Standards, Washington, D.C., 1964. (Cited on page 14) Qualcomm Technologies, Inc. 12 A Experiment A.1 Experimental Hardware For our experiments, we use a cluster of two Nvidia A100 GPUs (80GB RAM each). Most of our e...
work page 1964
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.