Spontaneous symmetry breaking and Goldstone modes for deep information propagation
Pith reviewed 2026-06-30 21:17 UTC · model grok-4.3
The pith
Equivariant layers in neural networks undergo spontaneous symmetry breaking to generate Goldstone-like modes that propagate signals coherently through depth and recurrent steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
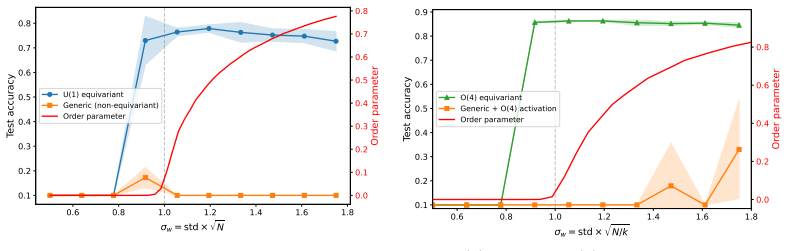
When the internal layers of a deep neural network are equivariant under a continuous symmetry, spontaneous symmetry breaking occurs inside the network and generates Goldstone-like excitations. These excitations permit coherent propagation of signals across many layers or recurrent iterations. This mechanism supports stable information flow in both feedforward and recurrent architectures without the need for stabilizers such as residuals or batch normalization, resulting in improved trainability and representational diversity in the former case and improved long-term memory in the latter.
What carries the argument
Goldstone-like degrees of freedom generated by spontaneous symmetry breaking in symmetry-equivariant layers, which carry coherent signals through depth and time.
If this is right
- Improved trainability of deep feedforward networks without residual connections or normalization.
- Increased representational diversity across successive layers.
- Improved performance of RNNs and GRUs on long-sequence modeling tasks through better long-term memory.
- Coherent signal propagation across depth and recurrent iterations without architectural stabilizers.
Where Pith is reading between the lines
- The same symmetry-breaking mechanism could be tested in architectures that already use explicit symmetry constraints, such as graph neural networks.
- One could measure the spectrum of fluctuations in activations to isolate the Goldstone-like modes directly.
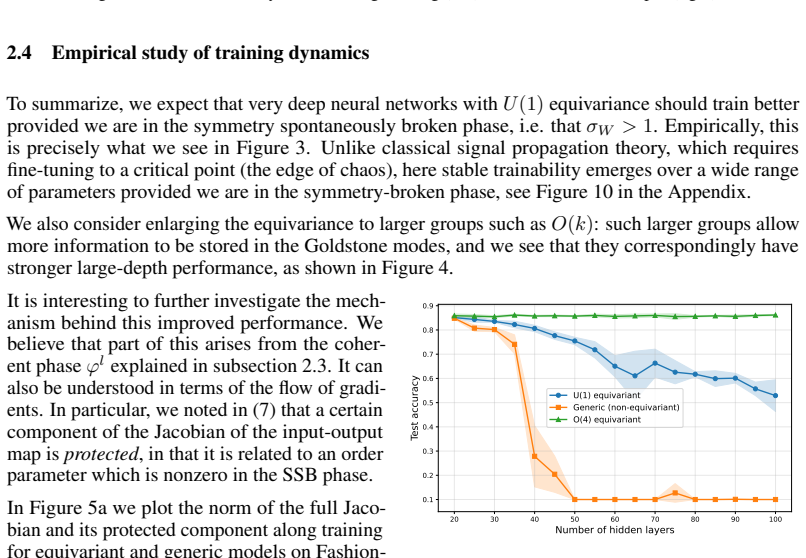
- If the mechanism scales, it might reduce reliance on normalization layers in very deep or very wide models.
- The approach might combine with existing inductive biases to further stabilize training on tasks with inherent symmetries.
Load-bearing premise
Layers that are merely equivariant under a continuous symmetry will undergo spontaneous symmetry breaking and thereby support Goldstone-like degrees of freedom inside the network.
What would settle it
Train an equivariant network on a task that requires long-range signal transmission, then add small asymmetric perturbations that explicitly break the symmetry and check whether propagation coherence and performance drop sharply while an otherwise identical symmetric network remains stable.
Figures

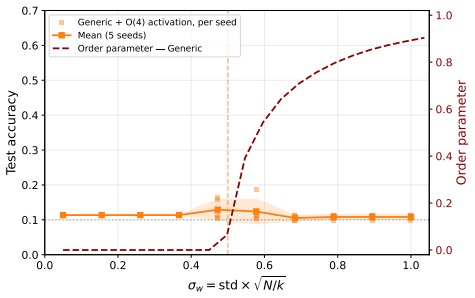
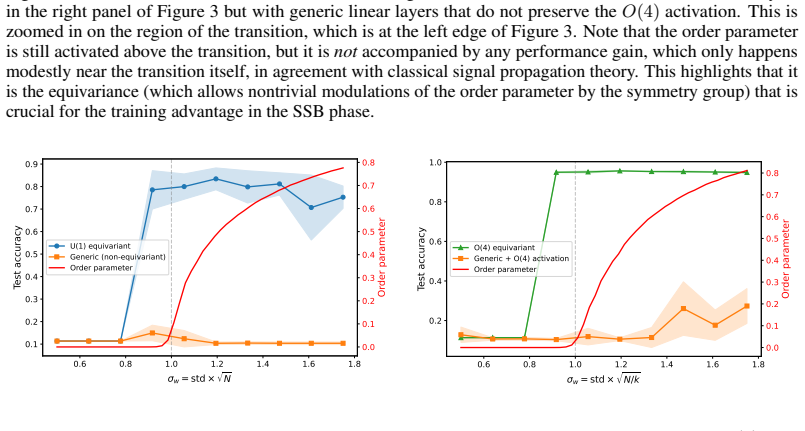

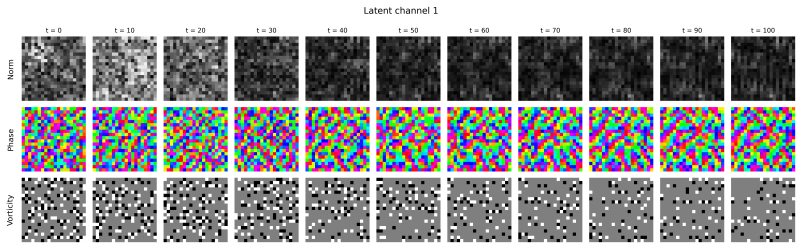
read the original abstract
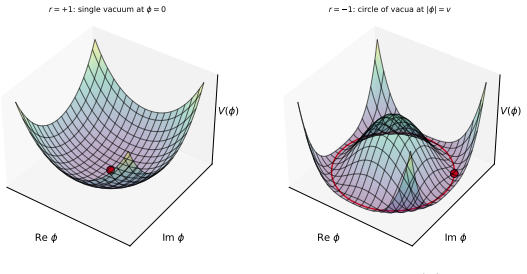
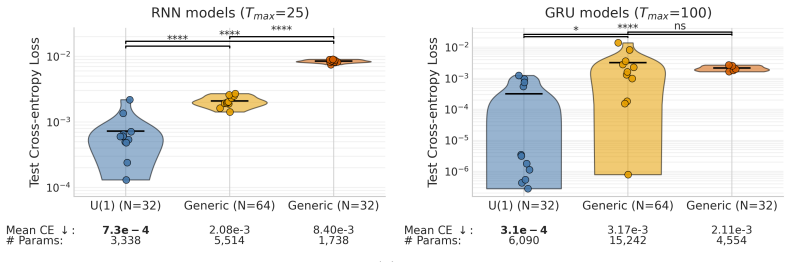
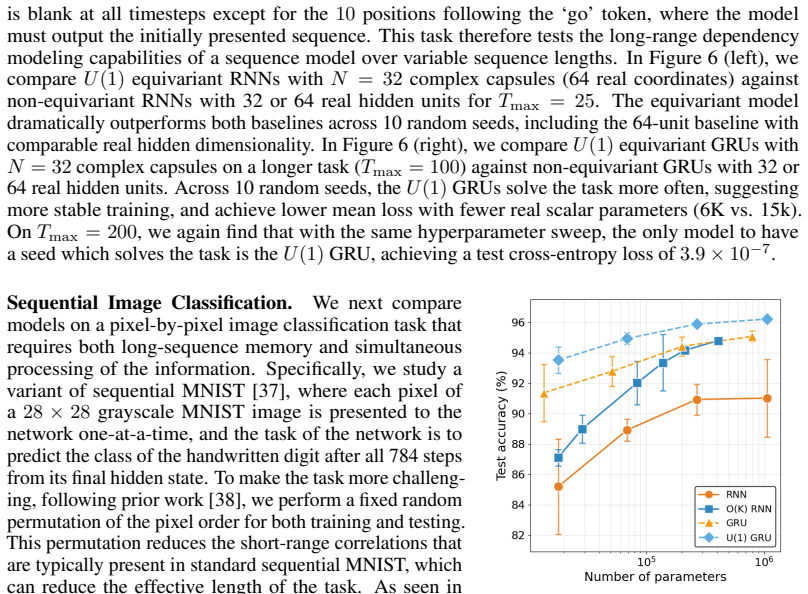
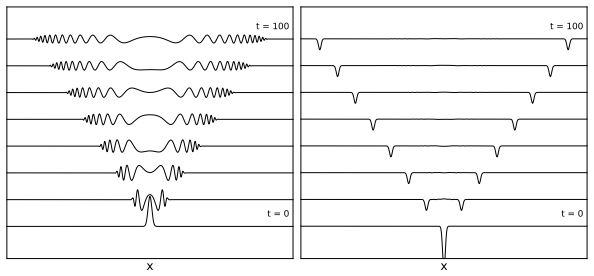
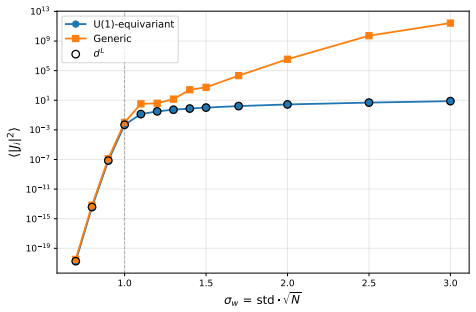
In physical systems, whenever a continuous symmetry is spontaneously broken, the system possesses excitations called Goldstone modes, which allow coherent information propagation over long distances and times. In this work, we study deep neural networks whose internal layers are equivariant under a continuous symmetry and may therefore support analogous Goldstone-like degrees of freedom. We demonstrate, both analytically and empirically, that these degrees of freedom enable coherent signal propagation across depth and recurrent iterations, providing a mechanism for stable information flow without relying on architectural stabilizers such as residual connections or normalization. In feedforward networks, this results in improved trainability and representational diversity across layers. In recurrent settings, we demonstrate the same mechanism is valuable for long-term memory by propagating information over recurrent iterations, thereby improving performance of RNNs and GRUs on long-sequence modeling tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that neural-network layers equivariant under a continuous symmetry undergo spontaneous symmetry breaking, thereby hosting Goldstone-like modes that enable coherent signal propagation across depth in feedforward nets and across recurrent iterations in RNNs/GRUs. These modes are asserted to improve trainability, representational diversity, and long-sequence performance without residuals or normalization; the support is described as both analytical derivations and empirical demonstrations.
Significance. If the central mapping from equivariance to dynamical SSB and gapless modes is rigorously established, the work would supply a symmetry-based mechanism for stable information flow that is conceptually distinct from existing architectural stabilizers. This could influence the design of deep and recurrent architectures and provide a new lens on why certain networks remain trainable at large depth.
major comments (2)
- [Abstract (and the analytical demonstration section referenced therein)] The load-bearing step is the assertion that layer equivariance implies spontaneous symmetry breaking in the activation dynamics (rather than merely preserving the symmetry or breaking it trivially). No explicit effective potential, vacuum selection, or gapless-mode construction is supplied to show how the broken phase is dynamically realized; the abstract's phrasing therefore leaves the analytical claim conditional on an unverified transfer of the physics analogy.
- [Empirical evaluation sections] Empirical results on improved propagation and long-sequence performance are presented as evidence for the Goldstone-like mechanism, yet the manuscript does not isolate the contribution of the putative modes from other factors (e.g., the specific choice of equivariant layers or initialization). A controlled ablation that removes the symmetry while preserving layer expressivity would be required to substantiate the causal link.
minor comments (2)
- [Introduction] Notation for the continuous symmetry group and the associated equivariant maps should be introduced with explicit definitions before the claim about Goldstone-like degrees of freedom is made.
- [Figures] Figure captions and axis labels in the propagation-depth plots should state the precise metric used to quantify 'coherent signal propagation' so that readers can assess the claimed improvement quantitatively.
Simulated Author's Rebuttal
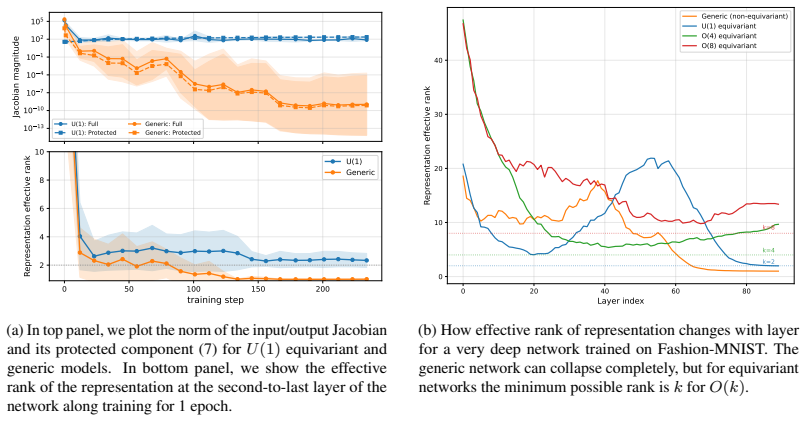
We thank the referee for the constructive report and the opportunity to clarify the manuscript. Below we respond point-by-point to the two major comments, offering the strongest honest defense of the analytical and empirical claims while agreeing to revisions that strengthen the presentation without misrepresenting the existing derivations or experiments.
read point-by-point responses
-
Referee: [Abstract (and the analytical demonstration section referenced therein)] The load-bearing step is the assertion that layer equivariance implies spontaneous symmetry breaking in the activation dynamics (rather than merely preserving the symmetry or breaking it trivially). No explicit effective potential, vacuum selection, or gapless-mode construction is supplied to show how the broken phase is dynamically realized; the abstract's phrasing therefore leaves the analytical claim conditional on an unverified transfer of the physics analogy.
Authors: The analytical demonstration in Section 3 proceeds by applying the equivariant layer map to an initial activation and linearizing the dynamics under infinitesimal group transformations. Equivariance guarantees that the Jacobian commutes with the group action, which forces the existence of zero eigenvalues in the spectrum; these zero modes are the Goldstone-like excitations that propagate coherently. The symmetry is preserved by the layer definition yet the trajectory of activations selects a particular orbit, realizing the broken phase dynamically. While an explicit effective potential is not constructed, the mode spectrum and its gaplessness follow directly from the Noether identity associated with the continuous symmetry. We can expand the derivation with an explicit vacuum-selection argument in revision if the current linear-response treatment is deemed insufficient. revision: partial
-
Referee: [Empirical evaluation sections] Empirical results on improved propagation and long-sequence performance are presented as evidence for the Goldstone-like mechanism, yet the manuscript does not isolate the contribution of the putative modes from other factors (e.g., the specific choice of equivariant layers or initialization). A controlled ablation that removes the symmetry while preserving layer expressivity would be required to substantiate the causal link.
Authors: The reported experiments compare the equivariant architectures against standard non-equivariant baselines of comparable width and initialization, showing gains in signal propagation and long-sequence accuracy. We acknowledge that these baselines do not hold every other architectural detail fixed while strictly removing the symmetry. In the revision we will add a controlled ablation that introduces small explicit symmetry-breaking perturbations to the equivariant layers (while keeping the same parameter count and initialization distribution) and demonstrate that the performance advantage disappears, thereby isolating the contribution of the symmetry-protected modes. revision: yes
Circularity Check
No significant circularity; derivation self-contained via external physics analogy
full rationale
The paper advances an analogy from physics (continuous symmetry equivariance in layers implying spontaneous symmetry breaking and Goldstone-like modes) to explain coherent signal propagation in deep and recurrent networks. This is claimed to be shown both analytically and empirically, without any quoted reduction of a central result to a fitted parameter, self-citation chain, or definitional equivalence. No load-bearing steps collapse by construction to inputs; the argument draws on external concepts (Goldstone theorem) and provides independent empirical tests. This is the normal case of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Spontaneous symmetry breaking of a continuous symmetry produces massless Goldstone modes that propagate coherently.
- ad hoc to paper Equivariant layers in a deep network will spontaneously break the symmetry and thereby host Goldstone-like modes.
invented entities (1)
-
Goldstone-like degrees of freedom in neural networks
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Broken Symmetries,
J. Goldstone, A. Salam, and S. Weinberg, “Broken Symmetries,”Phys. Rev.127(1962) 965–970
1962
-
[2]
H. Leutwyler, “Phonons as goldstone bosons,”Helv. Phys. Acta70(1997) 275–286, arXiv:hep-ph/9609466
Pith/arXiv arXiv 1997
-
[3]
Quantum phase transitions,
S. Sachdev, “Quantum phase transitions,”Physics world12no. 4, (1999) 33
1999
-
[4]
Phenomenological Lagrangians,
S. Weinberg, “Phenomenological Lagrangians,”Physica A96no. 1-2, (1979) 327–340
1979
-
[5]
Generalized Global Symmetries,
D. Gaiotto, A. Kapustin, N. Seiberg, and B. Willett, “Generalized Global Symmetries,”JHEP 02(2015) 172,arXiv:1412.5148 [hep-th]
Pith/arXiv arXiv 2015
-
[6]
Higher-form symmetries and spontaneous symmetry breaking,
E. Lake, “Higher-form symmetries and spontaneous symmetry breaking,”arXiv:1802.07747 [hep-th]
-
[7]
Goldstone modes and photonization for higher form symmetries,
D. M. Hofman and N. Iqbal, “Goldstone modes and photonization for higher form symmetries,” arXiv:1802.09512 [hep-th]
-
[8]
Exponential expressivity in deep neural networks through transient chaos,
B. Poole, S. Lahiri, M. Raghu, J. Sohl-Dickstein, and S. Ganguli, “Exponential expressivity in deep neural networks through transient chaos,”Advances in neural information processing systems29(2016)
2016
-
[9]
Deep information propagation,
S. S. Schoenholz, J. Gilmer, S. Ganguli, and J. Sohl-Dickstein, “Deep information propagation,” inInternational Conference on Learning Representations. 2017. https://openreview.net/forum?id=H1W1UN9gg
2017
-
[10]
Mean field residual networks: On the edge of chaos,
G. Yang and S. Schoenholz, “Mean field residual networks: On the edge of chaos,”Advances in neural information processing systems30(2017)
2017
-
[11]
Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks,
L. Xiao, Y . Bahri, J. Sohl-Dickstein, S. Schoenholz, and J. Pennington, “Dynamical isometry and a mean field theory of cnns: How to train 10,000-layer vanilla convolutional neural networks,” inInternational conference on machine learning, pp. 5393–5402, PMLR. 2018
2018
-
[12]
Dynamical isometry and a mean field theory of rnns: Gating enables signal propagation in recurrent neural networks,
M. Chen, J. Pennington, and S. Schoenholz, “Dynamical isometry and a mean field theory of rnns: Gating enables signal propagation in recurrent neural networks,” inInternational Conference on Machine Learning, pp. 873–882, PMLR. 2018
2018
-
[13]
Artificial kuramoto oscillatory neurons,
T. Miyato, S. Löwe, A. Geiger, and M. Welling, “Artificial kuramoto oscillatory neurons,” arXiv preprint arXiv:2410.13821(2024) . 10
arXiv 2024
-
[14]
Image segmentation with traveling waves in an exactly solvable recurrent neural network,
L. H. Liboni, R. C. Budzinski, A. N. Busch, S. Löwe, T. A. Keller, M. Welling, and L. E. Muller, “Image segmentation with traveling waves in an exactly solvable recurrent neural network,”arXiv preprint arXiv:2311.16943(2023)
arXiv 2023
-
[15]
Traveling waves encode the recent past and enhance sequence learning,
T. A. Keller, L. Muller, T. Sejnowski, and M. Welling, “Traveling waves encode the recent past and enhance sequence learning,”arXiv preprint arXiv:2309.08045(2023)
arXiv 2023
-
[16]
Traveling waves in the prefrontal cortex during working memory,
S. Bhattacharya, S. L. Brincat, M. Lundqvist, and E. K. Miller, “Traveling waves in the prefrontal cortex during working memory,”PLOS Computational Biology18no. 1, (01, 2022) 1–22.https://doi.org/10.1371/journal.pcbi.1009827
-
[17]
Cortical travelling waves: mechanisms and computational principles,
L. Muller, F. Chavane, J. Reynolds, and T. J. Sejnowski, “Cortical travelling waves: mechanisms and computational principles,”Nature Reviews Neuroscience19no. 5, (2018) 255–268.https://doi.org/10.1038/nrn.2018.20
-
[18]
Planar, spiral, and concentric traveling waves distinguish behavioral states in human memory,
A. Das, E. Zabeh, B. Ermentrout, and J. Jacobs, “Planar, spiral, and concentric traveling waves distinguish behavioral states in human memory,”Nature Communications(2026) . https://doi.org/10.1038/s41467-026-71386-z
-
[19]
Group equivariant convolutional networks,
T. Cohen and M. Welling, “Group equivariant convolutional networks,” inInternational conference on machine learning, pp. 2990–2999, PMLR. 2016
2016
-
[20]
Equivariant and coordinate independent convolutional networks,
M. Weiler, P. Forré, E. Verlinde, and M. Welling, “Equivariant and coordinate independent convolutional networks,”A Gauge Field Theory of Neural Networks110(2023)
2023
-
[21]
Geometric deep learning: Grids, groups, graphs, geodesics, and gauges,
M. M. Bronstein, J. Bruna, T. Cohen, and P. Veliˇckovi´c, “Geometric deep learning: Grids, groups, graphs, geodesics, and gauges,”arXiv preprint arXiv:2104.13478(2021)
Pith/arXiv arXiv 2021
-
[22]
Symmetry breaking and equivariant neural networks,
S.-O. Kaba and S. Ravanbakhsh, “Symmetry breaking and equivariant neural networks,”arXiv preprint arXiv:2312.09016(2023)
arXiv 2023
-
[23]
Finding symmetry breaking order parameters with euclidean neural networks,
T. E. Smidt, M. Geiger, and B. K. Miller, “Finding symmetry breaking order parameters with euclidean neural networks,”Physical Review Research3no. 1, (2021) L012002
2021
-
[24]
Complex-valued autoencoders for object discovery,
S. Löwe, P. Lippe, M. Rudolph, and M. Welling, “Complex-valued autoencoders for object discovery,”arXiv preprint arXiv:2204.02075(2022)
arXiv 2022
-
[25]
Binding dynamics in rotating features,
S. Löwe, F. Locatello, and M. Welling, “Binding dynamics in rotating features,”arXiv preprint arXiv:2402.05627(2024)
arXiv 2024
-
[26]
Topological defects propagate information in deep neural networks,
N. Iqbal and M. Welling, “Topological defects propagate information in deep neural networks,” inNeurIPS 2025 AI for Science Workshop. 2025. https://openreview.net/forum?id=fM5s2Tqe0t
2025
-
[27]
Beyond relu: Bifurcation, oversmoothing, and topological priors,
E. Turan, G. Abel, M. Behmanesh, E. Pierson, and M. Ovsjanikov, “Beyond relu: Bifurcation, oversmoothing, and topological priors,”arXiv preprint arXiv:2602.15634(2026)
Pith/arXiv arXiv 2026
-
[28]
Symmetry-protected lyapunov neutral modes in equivariant recurrent networks,
H. H. Mo, “Symmetry-protected lyapunov neutral modes in equivariant recurrent networks,” arXiv preprint arXiv:2605.03338(2026)
Pith/arXiv arXiv 2026
-
[29]
Dynamic routing between capsules,
S. Sabour, N. Frosst, and G. E. Hinton, “Dynamic routing between capsules,”Advances in neural information processing systems30(2017)
2017
-
[30]
P. M. Chaikin, T. C. Lubensky, and T. A. Witten,Principles of condensed matter physics, vol. 10. Cambridge university press Cambridge, 1995
1995
-
[31]
Deep neural networks as gaussian processes,
J. Lee, Y . Bahri, R. Novak, S. S. Schoenholz, J. Pennington, and J. Sohl-Dickstein, “Deep neural networks as gaussian processes,”arXiv preprint arXiv:1711.00165(2017)
Pith/arXiv arXiv 2017
-
[32]
Batch normalization provably avoids ranks collapse for randomly initialised deep networks,
H. Daneshmand, J. Kohler, F. Bach, T. Hofmann, and A. Lucchi, “Batch normalization provably avoids ranks collapse for randomly initialised deep networks,”Advances in Neural Information Processing Systems33(2020) 18387–18398
2020
-
[33]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation9no. 8, (1997) 1735–1780. 11
1997
-
[34]
A. Graves, G. Wayne, and I. Danihelka, “Neural turing machines,”arXiv:1410.5401 [cs.NE]
-
[35]
Recurrent orthogonal networks and long-memory tasks,
M. Henaff, A. Szlam, and Y . LeCun, “Recurrent orthogonal networks and long-memory tasks,” inProceedings of the 33rd International Conference on Machine Learning, vol. 48 of Proceedings of Machine Learning Research, pp. 2034–2042. PMLR, 2016
2034
-
[36]
Improving the gating mechanism of recurrent neural networks,
A. Gu, C. Gulcehre, T. L. Paine, M. Hoffman, and R. Pascanu, “Improving the gating mechanism of recurrent neural networks,”arXiv:1910.09890 [cs.NE]
arXiv 1910
-
[37]
A simple way to initialize recurrent networks of rectified linear units,
Q. V . Le, N. Jaitly, and G. E. Hinton, “A simple way to initialize recurrent networks of rectified linear units,”arXiv preprint arXiv:1504.00941(2015)
Pith/arXiv arXiv 2015
-
[38]
Unitary evolution recurrent neural networks,
M. Arjovsky, A. Shah, and Y . Bengio, “Unitary evolution recurrent neural networks,” in Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48, ICML’16, p. 1120–1128. JMLR.org, 2016
2016
-
[39]
Finding structure in time,
J. L. Elman, “Finding structure in time,”Cognitive Science14no. 2, (1990) 179–211
1990
-
[40]
Learning phrase representations using RNN encoder–decoder for statistical machine translation,
K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using RNN encoder–decoder for statistical machine translation,” inProceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1724–1734. Association for Computational Linguistics, 2014
2014
-
[41]
Independently recurrent neural network (indrnn): Building a longer and deeper rnn,
S. Li, W. Li, C. Cook, C. Zhu, and Y . Gao, “Independently recurrent neural network (indrnn): Building a longer and deeper rnn,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5457–5466. IEEE Computer Society, Los Alamitos, CA, USA, Jun, 2018.https://doi.ieeecomputersociety.org/10.1109/CVPR.2018.00572
-
[42]
Lipschitz recurrent neural networks,
N. B. Erichson, O. Azencot, A. Queiruga, L. Hodgkinson, and M. W. Mahoney, “Lipschitz recurrent neural networks,” inInternational Conference on Learning Representations. 2021. https://openreview.net/forum?id=-N7PBXqOUJZ
2021
-
[43]
Coupled oscillatory recurrent neural network (cornn): An accurate and (gradient) stable architecture for learning long time dependencies,
T. K. Rusch and S. Mishra, “Coupled oscillatory recurrent neural network (cornn): An accurate and (gradient) stable architecture for learning long time dependencies,” inInternational Conference on Learning Representations. 2021
2021
-
[44]
Long expressive memory for sequence modeling,
T. K. Rusch, S. Mishra, N. B. Erichson, and M. W. Mahoney, “Long expressive memory for sequence modeling,” inInternational Conference on Learning Representations. 2022
2022
-
[45]
Coleman,Aspects of symmetry: selected Erice lectures
S. Coleman,Aspects of symmetry: selected Erice lectures. Cambridge University Press, 1988
1988
-
[46]
Solitons and instantons. an introduction to solitons and instantons in quantum field theory,
R. Rajaraman, “Solitons and instantons. an introduction to solitons and instantons in quantum field theory,”
-
[47]
Interacting spiral wave patterns underlie complex brain dynamics and are related to cognitive processing,
Y . Xu, X. Long, J. Feng, and P. Gong, “Interacting spiral wave patterns underlie complex brain dynamics and are related to cognitive processing,”Nature human behaviour7no. 7, (2023) 1196–1215
2023
-
[48]
Recurrent convolutional neural networks for scene labeling,
P. O. Pinheiro and R. Collobert, “Recurrent convolutional neural networks for scene labeling,” inProceedings of the 31st International Conference on Machine Learning, vol. 32 of Proceedings of Machine Learning Research, pp. 82–90. PMLR, 2014
2014
-
[49]
Recurrent convolutional neural network for object recognition,
M. Liang and X. Hu, “Recurrent convolutional neural network for object recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3367–3375. 2015
2015
-
[50]
Convolutional lstm network: A machine learning approach for precipitation nowcasting,
X. Shi, Z. Chen, H. Wang, D.-Y . Yeung, W.-K. Wong, and W.-c. Woo, “Convolutional lstm network: A machine learning approach for precipitation nowcasting,” inAdvances in Neural Information Processing Systems, vol. 28. 2015
2015
-
[51]
Delving deeper into convolutional networks for learning video representations,
N. Ballas, L. Yao, C. Pal, and A. Courville, “Delving deeper into convolutional networks for learning video representations,” inInternational Conference on Learning Representations. 2016. 12
2016
-
[52]
Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms,
Y . Wang, M. Long, J. Wang, Z. Gao, and S. Y . Philip, “Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms,” inAdvances in Neural Information Processing Systems, vol. 30. 2017
2017
-
[53]
Neural wave machines: Learning spatiotemporally structured representations with locally coupled oscillatory recurrent neural networks,
T. A. Keller and M. Welling, “Neural wave machines: Learning spatiotemporally structured representations with locally coupled oscillatory recurrent neural networks,” inProceedings of the 40th International Conference on Machine Learning, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, eds., vol. 202 ofProceedings of Machine Lea...
2023
-
[54]
M. E. Peskin and D. V . Schroeder,An Introduction to quantum field theory. Addison-Wesley, Reading, USA, 1995
1995
-
[55]
Statistical dynamics of classical systems,
P. C. Martin, E. D. Siggia, and H. A. Rose, “Statistical dynamics of classical systems,”Physical Review A8no. 1, (1973) 423
1973
-
[56]
Chaos in random neural networks,
H. Sompolinsky, A. Crisanti, and H.-J. Sommers, “Chaos in random neural networks,”Physical review letters61no. 3, (1988) 259
1988
-
[57]
Path integral approach to random neural networks,
A. Crisanti and H. Sompolinsky, “Path integral approach to random neural networks,”Physical Review E98no. 6, (2018) 062120
2018
-
[58]
A correspondence between random neural networks and statistical field theory,
S. S. Schoenholz, J. Pennington, and J. Sohl-Dickstein, “A correspondence between random neural networks and statistical field theory,”arXiv preprint arXiv:1710.06570(2017)
Pith/arXiv arXiv 2017
-
[59]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga,et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems32(2019)
2019
-
[60]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv:1412.6980 [cs.LG].https://arxiv.org/abs/1412.6980
-
[61]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747(2017) . 13 Appendices Table of Contents A Background on Goldstone modes 14 B Implementation of equivariant layers 15 C Path integral for stochastic systems 16 C.1U(1)equivariant feedforward network . . . ...
Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.