Agentifying Patient Dynamics within LLMs through Interacting with Clinical World Model
Pith reviewed 2026-06-30 20:55 UTC · model grok-4.3
The pith
An LLM agent trained to simulate patient responses in a Clinical World Model outperforms RL and LLM baselines on sepsis treatment value and safety.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
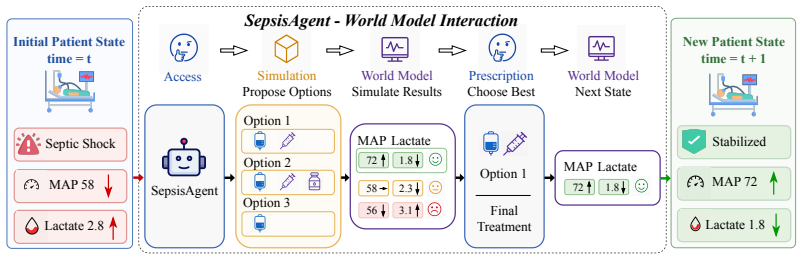
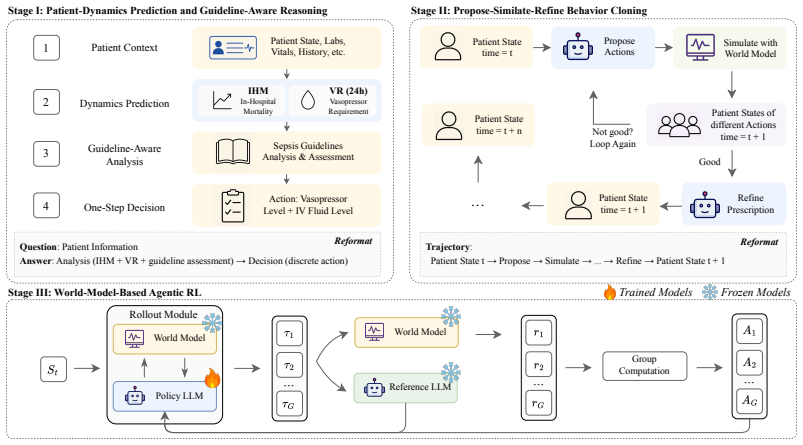
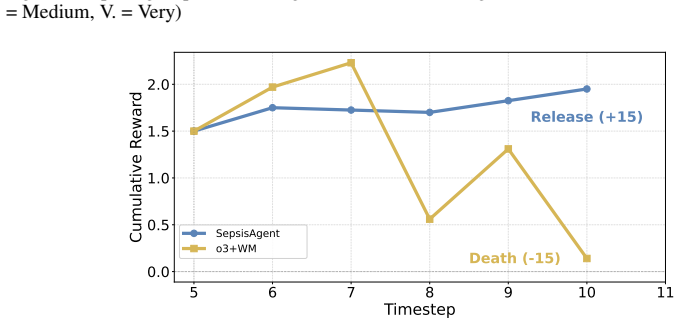
SepsisAgent, built by augmenting an LLM with a Clinical World Model and training it in three stages to follow a propose-simulate-refine loop, achieves the highest off-policy value and the strongest safety profile (guideline adherence plus lowest unsafe-action rate) among tested RL and LLM baselines on MIMIC-IV sepsis trajectories. Repeated interaction with the simulator allows the agent to internalize patient-response regularities that transfer to settings without simulator access.
What carries the argument
The Clinical World Model, a learned simulator of patient physiological responses to candidate fluid-vasopressor interventions that powers the propose-simulate-refine decision loop.
If this is right
- The propose-simulate-refine workflow yields measurably higher treatment value than direct LLM prompting or standard RL on the same data.
- Safety metrics (guideline adherence and unsafe-action count) improve when the agent can test candidate actions inside the world model before committing.
- Regularities learned through simulator interaction remain useful for decision making even after the simulator is removed at inference time.
- Curriculum training that combines dynamics supervision, behavior cloning, and world-model RL is required to stabilize performance.
Where Pith is reading between the lines
- The same simulator-augmented training pattern could be tested on other sequential ICU tasks such as ventilator weaning or antibiotic escalation.
- If the world model can be kept lightweight, the approach may allow on-the-fly refinement of recommendations without full retraining.
- Removing simulator access only at deployment time suggests a path to cheaper inference while retaining some of the learned dynamics knowledge.
Load-bearing premise
The Clinical World Model must produce sufficiently accurate simulations of how real patients respond to fluid and vasopressor changes.
What would settle it
If predictions from the Clinical World Model diverge substantially from actual next-state outcomes on held-out MIMIC-IV trajectories, the reported gains in off-policy value and safety metrics disappear.
Figures





read the original abstract
Sepsis management in the ICU requires sequential treatment decisions under rapidly evolving patient physiology. Although large language models (LLMs) encode broad clinical knowledge and can reason over guidelines, they are not inherently grounded in action-conditioned patient dynamics. We introduce SepsisAgent, a world model-augmented LLM agent for sepsis treatment recommendation. SepsisAgent uses a learned Clinical World Model to simulate patient responses under candidate fluid--vasopressor interventions, and follows a propose--simulate--refine workflow before committing to a prescription. We first show that world-model access alone yields inconsistent LLM decision performance, motivating agent-specific training. We then train SepsisAgent through a three-stage curriculum: patient-dynamics supervised fine-tuning, propose--simulate--refine behavior cloning, and world-model-based agentic reinforcement learning. On MIMIC-IV sepsis trajectories, SepsisAgent outperforms all traditional RL and LLM-based baselines in off-policy value while achieving the best safety profile under guideline adherence and unsafe-action metrics. Further analysis shows that repeated interaction with the Clinical World Model enables the agent to learn regularities in patient evolution, which remain useful even when simulator access is removed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SepsisAgent, a world-model-augmented LLM agent for sepsis treatment. It learns a Clinical World Model to simulate patient responses to fluid-vasopressor interventions and follows a propose-simulate-refine workflow. Training proceeds via a three-stage curriculum (patient-dynamics supervised fine-tuning, propose-simulate-refine behavior cloning, and world-model-based agentic RL). On MIMIC-IV sepsis trajectories the method is reported to outperform traditional RL and LLM baselines in off-policy value while achieving the best safety profile on guideline adherence and unsafe-action metrics; interaction with the world model is claimed to produce persistent regularities even after simulator removal.
Significance. If the Clinical World Model is shown to be sufficiently accurate and the reported gains are not artifacts of post-hoc choices or circular value estimation, the work would demonstrate a concrete route for grounding LLMs in action-conditioned patient dynamics. The three-stage curriculum and the persistence result after simulator removal are potentially valuable contributions to agentic clinical AI.
major comments (2)
- [Abstract] Abstract: the central performance claim (outperformance on off-policy value and safety metrics) is stated without any description of model architecture, data splits, number of trajectories, statistical significance testing, or world-model validation procedure. These omissions are load-bearing for the claim that the propose-simulate-refine loop improves decisions over baselines.
- [Abstract] Abstract: the description of world-model-based RL does not indicate whether the reported off-policy value is computed from quantities already fitted inside the Clinical World Model itself; this leaves the circularity concern unaddressed and directly affects the weakest assumption that the simulator produces better decisions than baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional context is needed to support the central claims and will revise the abstract accordingly. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim (outperformance on off-policy value and safety metrics) is stated without any description of model architecture, data splits, number of trajectories, statistical significance testing, or world-model validation procedure. These omissions are load-bearing for the claim that the propose-simulate-refine loop improves decisions over baselines.
Authors: We agree that the abstract should include more supporting details. In the revised version we will expand it to briefly note: the base LLM architecture and fine-tuning approach; the MIMIC-IV sepsis cohort with explicit train/validation/test splits and trajectory counts; the statistical testing procedure (e.g., bootstrap confidence intervals or paired tests); and world-model validation metrics (prediction error on held-out transitions). These elements are already reported in Sections 4 and 5; the revision will summarize them concisely in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the description of world-model-based RL does not indicate whether the reported off-policy value is computed from quantities already fitted inside the Clinical World Model itself; this leaves the circularity concern unaddressed and directly affects the weakest assumption that the simulator produces better decisions than baselines.
Authors: The off-policy value is estimated on real MIMIC-IV trajectories using standard off-policy evaluation (weighted importance sampling with behavior policy derived from the data), independent of the Clinical World Model. The world model is used only for the propose-simulate-refine loop at inference time and during agentic RL training; it does not participate in the final value estimation. We will add an explicit clarifying sentence in the revised abstract to remove any ambiguity about circularity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core claims rest on a three-stage curriculum (patient-dynamics SFT, propose-simulate-refine BC, world-model RL) evaluated via off-policy value and safety metrics on held-out MIMIC-IV sepsis trajectories against external RL/LLM baselines. The abstract explicitly states that learned regularities remain useful after simulator removal, and no equations, fitted parameters, or self-citations are shown that would make reported performance reduce to quantities already present in the world-model fit by construction. The derivation is therefore self-contained against independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The third international consensus definitions for sepsis and septic shock (sepsis-3).Jama, 315(8):801–810, 2016
Mervyn Singer, Clifford S Deutschman, Christopher Warren Seymour, Manu Shankar-Hari, Djillali Annane, Michael Bauer, Rinaldo Bellomo, Gordon R Bernard, Jean-Daniel Chiche, Craig M Coopersmith, et al. The third international consensus definitions for sepsis and septic shock (sepsis-3).Jama, 315(8):801–810, 2016
2016
-
[2]
Global, regional, and national sepsis incidence and mortality, 1990–2017: analysis for the global burden of disease study.The Lancet, 395(10219):200–211, 2020
Kristina E Rudd, Sarah Charlotte Johnson, Kareha M Agesa, Katya Anne Shackelford, Derrick Tsoi, Daniel Rhodes Kievlan, Danny V Colombara, Kevin S Ikuta, Niranjan Kissoon, Simon Finfer, et al. Global, regional, and national sepsis incidence and mortality, 1990–2017: analysis for the global burden of disease study.The Lancet, 395(10219):200–211, 2020
1990
-
[3]
Incidence and trends of sepsis in us hospitals using clinical vs claims data, 2009-2014
Chanu Rhee, Raymund Dantes, Lauren Epstein, David J Murphy, Christopher W Seymour, Theodore J Iwashyna, Sameer S Kadri, Derek C Angus, Robert L Danner, Anthony E Fiore, et al. Incidence and trends of sepsis in us hospitals using clinical vs claims data, 2009-2014. Jama, 318(13):1241–1249, 2017
2009
-
[4]
Revolution in sepsis: a symptoms- based to a systems-based approach?Journal of Biomedical Science, 31(1):57, 2024
Geoffrey P Dobson, Hayley L Letson, and Jodie L Morris. Revolution in sepsis: a symptoms- based to a systems-based approach?Journal of Biomedical Science, 31(1):57, 2024
2024
-
[5]
Restriction of intravenous fluid in icu patients with septic shock.New England Journal of Medicine, 386(26):2459–2470, 2022
Tine S Meyhoff, Peter B Hjortrup, Jørn Wetterslev, Praleene Sivapalan, Jon H Laake, Maria Cronhjort, Stephan M Jakob, Maurizio Cecconi, Marek Nalos, Marlies Ostermann, et al. Restriction of intravenous fluid in icu patients with septic shock.New England Journal of Medicine, 386(26):2459–2470, 2022
2022
-
[6]
Fluid response evaluation in sepsis hypotension and shock: a randomized clinical trial.Chest, 158(4):1431–1445, 2020
Ivor S Douglas, Philip M Alapat, Keith A Corl, Matthew C Exline, Lui G Forni, Andre L Holder, David A Kaufman, Akram Khan, Mitchell M Levy, Gregory S Martin, et al. Fluid response evaluation in sepsis hypotension and shock: a randomized clinical trial.Chest, 158(4):1431–1445, 2020
2020
-
[7]
Stephanie Helman, Martha Ann Terry, Tiffany Pellathy, Andrew Williams, Artur Dubrawski, Gilles Clermont, Michael R Pinsky, Salah Al-Zaiti, and Marilyn Hravnak. Engaging clinicians early during the development of a graphical user display of an intelligent alerting system at the bedside.International journal of medical informatics, 159:104643, 2022
2022
-
[8]
The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care
Matthieu Komorowski, Leo A Celi, Omar Badawi, Anthony C Gordon, and A Aldo Faisal. The artificial intelligence clinician learns optimal treatment strategies for sepsis in intensive care. Nature medicine, 24(11):1716–1720, 2018
2018
-
[9]
Derivation, validation, and potential treatment implications of novel clinical phenotypes for sepsis.Jama, 321(20):2003–2017, 2019
Christopher W Seymour, Jason N Kennedy, Shu Wang, Chung-Chou H Chang, Corrine F Elliott, Zhongying Xu, Scott Berry, Gilles Clermont, Gregory Cooper, Hernando Gomez, et al. Derivation, validation, and potential treatment implications of novel clinical phenotypes for sepsis.Jama, 321(20):2003–2017, 2019
2003
-
[10]
Impact of a deep learning sepsis prediction model on quality of care and survival
Aaron Boussina, Supreeth P Shashikumar, Atul Malhotra, Robert L Owens, Robert El-Kareh, Christopher A Longhurst, Kimberly Quintero, Allison Donahue, Theodore C Chan, Shamim Nemati, et al. Impact of a deep learning sepsis prediction model on quality of care and survival. NPJ digital medicine, 7(1):14, 2024. 10
2024
-
[11]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Ehrshot: An ehr benchmark for few-shot evaluation of foundation models.Advances in Neural Information Processing Systems, 36:67125–67137, 2023
Michael Wornow, Rahul Thapa, Ethan Steinberg, Jason Fries, and Nigam Shah. Ehrshot: An ehr benchmark for few-shot evaluation of foundation models.Advances in Neural Information Processing Systems, 36:67125–67137, 2023
2023
-
[15]
Deep Reinforcement Learning for Sepsis Treatment
Aniruddh Raghu, Matthieu Komorowski, Imran Ahmed, Leo Celi, Peter Szolovits, and Marzyeh Ghassemi. Deep reinforcement learning for sepsis treatment.arXiv preprint arXiv:1711.09602, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis.NPJ Digital Medicine, 6(1):15, 2023
XiaoDan Wu, RuiChang Li, Zhen He, TianZhi Yu, and ChangQing Cheng. A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis.NPJ Digital Medicine, 6(1):15, 2023
2023
-
[17]
Optimal vasopressin initiation in septic shock: the oviss reinforcement learning study.Jama, 333(19):1688–1698, 2025
Alexandre Kalimouttou, Jason N Kennedy, Jean Feng, Harvineet Singh, Suchi Saria, Derek C Angus, Christopher W Seymour, and Romain Pirracchio. Optimal vasopressin initiation in septic shock: the oviss reinforcement learning study.Jama, 333(19):1688–1698, 2025
2025
-
[18]
Reinforcement learning for clinical decision support in critical care: comprehensive review.Journal of medical Internet research, 22(7):e18477, 2020
Siqi Liu, Kay Choong See, Kee Yuan Ngiam, Leo Anthony Celi, Xingzhi Sun, and Mengling Feng. Reinforcement learning for clinical decision support in critical care: comprehensive review.Journal of medical Internet research, 22(7):e18477, 2020
2020
-
[19]
Qianyi Xu, Gousia Habib, Dilruk Perera, and Mengling Feng. Meddreamer: Model-based reinforcement learning with latent imagination on complex ehrs for clinical decision support. arXiv preprint arXiv:2505.19785, 2025
-
[20]
Model-Based Reinforcement Learning for Sepsis Treatment
Aniruddh Raghu, Matthieu Komorowski, and Sumeetpal Singh. Model-based reinforcement learning for sepsis treatment.arXiv preprint arXiv:1811.09602, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
2022
-
[23]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[24]
Toward expert-level medical question answering with large language models.Nature Medicine, 31(3):943–950, 2025
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al. Toward expert-level medical question answering with large language models.Nature Medicine, 31(3):943–950, 2025
2025
-
[25]
Towards conversational diagnostic artificial intelligence.Nature, 642(8067):442–450, 2025
Tao Tu, Mike Schaekermann, Anil Palepu, Khaled Saab, Jan Freyberg, Ryutaro Tanno, Amy Wang, Brenna Li, Mohamed Amin, Yong Cheng, et al. Towards conversational diagnostic artificial intelligence.Nature, 642(8067):442–450, 2025
2025
-
[26]
Motor: A time-to-event foundation model for structured medical records
Ethan Steinberg, Jason Alan Fries, Yizhe Xu, and Nigam Shah. Motor: A time-to-event foundation model for structured medical records. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[27]
Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, Ethan Steinberg, Jason Alan Fries, Christopher Ré, Sanmi Koyejo, and Nigam H Shah. Context clues: Evaluating long context models for clinical prediction tasks on ehrs.arXiv preprint arXiv:2412.16178, 2024. 11
-
[28]
Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al. Mimic-iv, a freely accessible electronic health record dataset.Scientific data, 10(1):1, 2023
2023
-
[29]
Surviving sepsis campaign: international guidelines for management of sepsis and septic shock 2021.Critical care medicine, 49(11):e1063–e1143, 2021
Laura Evans, Andrew Rhodes, Waleed Alhazzani, Massimo Antonelli, Craig M Coopersmith, Craig French, Flávia R Machado, Lauralyn Mcintyre, Marlies Ostermann, Hallie C Prescott, et al. Surviving sepsis campaign: international guidelines for management of sepsis and septic shock 2021.Critical care medicine, 49(11):e1063–e1143, 2021
2021
-
[30]
Mimic-sepsis: A curated benchmark for modeling and learning from sepsis trajectories in the icu
Yong Huang, Zhongqi Yang, and Amir Rahmani. Mimic-sepsis: A curated benchmark for modeling and learning from sepsis trajectories in the icu. In2025 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), pages 1–7. IEEE, 2025
2025
-
[31]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Reasonmed: A 370k multi-agent generated dataset for advancing medical reasoning
Yu Sun, Xingyu Qian, Weiwen Xu, Hao Zhang, Chenghao Xiao, Long Li, Deli Zhao, Wenbing Huang, Tingyang Xu, Qifeng Bai, et al. Reasonmed: A 370k multi-agent generated dataset for advancing medical reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26457–26478, 2025
2025
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Doubly robust off-policy value evaluation for reinforcement learning
Nan Jiang and Lihong Li. Doubly robust off-policy value evaluation for reinforcement learning. InInternational conference on machine learning, pages 652–661. PMLR, 2016
2016
-
[36]
Eligibility traces for off-policy policy evaluation
Doina Precup, Richard S Sutton, and Satinder Singh. Eligibility traces for off-policy policy evaluation. 2000
2000
-
[37]
Assuring the safety of ai-based clinical decision support systems: a case study of the ai clinician for sepsis treatment.BMJ health & care informatics, 29(1):e100549, 2022
Paul Festor, Yan Jia, Anthony C Gordon, A Aldo Faisal, Ibrahim Habli, and Matthieu Ko- morowski. Assuring the safety of ai-based clinical decision support systems: a case study of the ai clinician for sepsis treatment.BMJ health & care informatics, 29(1):e100549, 2022
2022
-
[38]
A new era of intelligence with gemini 3.Google
Sundar Pichai, Demis Hassabis, and Koray Kavukcuoglu. A new era of intelligence with gemini 3.Google. URL: https://blog. google/products-and-platforms/products/gemini/gemini-3, 2025
2025
-
[39]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025
2025
-
[40]
Gpt-4.1.https://openai.com/index/gpt-4-1/, 2024
OpenAI. Gpt-4.1.https://openai.com/index/gpt-4-1/, 2024. Accessed: 2024-11-30
2024
-
[41]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
2025
-
[42]
P. Langley. Crafting papers on machine learning. In Pat Langley, editor,Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pages 1207–1216, Stanford, CA, 2000. Morgan Kaufmann
2000
-
[43]
Challenges with reinforcement learning model transportability for sepsis treatment in emergency care.npj Digital Medicine, 8(1):1–5, 2025
Peter C Nauka, Jason N Kennedy, Emily B Brant, Matthieu Komorowski, Romain Pirracchio, Derek C Angus, and Christopher W Seymour. Challenges with reinforcement learning model transportability for sepsis treatment in emergency care.npj Digital Medicine, 8(1):1–5, 2025
2025
-
[44]
Smart imitator: Learning from imperfect clinical decisions.Journal of the American Medical Informatics Association, 33(1):49–66, 2026
Dilruk Perera, Siqi Liu, Kay Choong See, and Mengling Feng. Smart imitator: Learning from imperfect clinical decisions.Journal of the American Medical Informatics Association, 33(1):49–66, 2026
2026
-
[45]
Reinforcement learning to optimize ventilator settings for patients on invasive mechanical ventilation: retrospective study.Journal of Medical Internet Research, 26:e44494, 2024
Siqi Liu, Qianyi Xu, Zhuoyang Xu, Zhuo Liu, Xingzhi Sun, Guotong Xie, Mengling Feng, and Kay Choong See. Reinforcement learning to optimize ventilator settings for patients on invasive mechanical ventilation: retrospective study.Journal of Medical Internet Research, 26:e44494, 2024
2024
-
[46]
Elham Estiri and Hossein Mirinejad. Model-free reinforcement learning for automated fluid administration in critical care.arXiv preprint arXiv:2401.06299, 2024
-
[47]
Zhiyao Luo, Yangchen Pan, Peter Watkinson, and Tingting Zhu. Reinforcement learning in dynamic treatment regimes needs critical reexamination.arXiv preprint arXiv:2405.18556, 2024
-
[48]
Robust and efficient transfer learning with hidden parameter markov decision processes.Advances in neural information processing systems, 30, 2017
Taylor W Killian, Samuel Daulton, George Konidaris, and Finale Doshi-Velez. Robust and efficient transfer learning with hidden parameter markov decision processes.Advances in neural information processing systems, 30, 2017
2017
-
[49]
Survival after shock requiring high-dose vasopressor therapy.Chest, 143(3):664–671, 2013
Samuel M Brown, Michael J Lanspa, Jason P Jones, Kathryn G Kuttler, Yao Li, Rick Carlson, Russell R Miller III, Eliotte L Hirshberg, Colin K Grissom, and Alan H Morris. Survival after shock requiring high-dose vasopressor therapy.Chest, 143(3):664–671, 2013
2013
-
[50]
Interaction between fluids and vasoactive agents on mortality in septic shock: a multicenter, observational study.Critical care medicine, 42(10):2158–2168, 2014
Jason Waechter, Anand Kumar, Stephen E Lapinsky, John Marshall, Peter Dodek, Yaseen Arabi, Joseph E Parrillo, R Phillip Dellinger, Allan Garland, Cooperative Antimicrobial Therapy of Septic Shock Database Research Group, et al. Interaction between fluids and vasoactive agents on mortality in septic shock: a multicenter, observational study.Critical care m...
2014
-
[51]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 14 A Related Work A.1 LLM Agent Using a World Model Sepsis treatment involves complex and patient-specific hemodynamic dynamics, and current practices in h...
2024
-
[52]
Note that Dopamine is excluded from our final action space due to its declining usage in modern sepsis protocols
Norepinephrine Equivalent (NE-Eq):[49] Aggregates multiple vasopressors into a stan- dard norepinephrine scale. Note that Dopamine is excluded from our final action space due to its declining usage in modern sepsis protocols
-
[53]
Dextrose 5% is excluded as it functions as free water rather than a volume expander
Total Effective Volume (TEV):[50] Aggregates crystalloids and colloids based on their volume expansion effect. Dextrose 5% is excluded as it functions as free water rather than a volume expander. Table 5: Cohort statistics stratified by 90-day mortality. Group % Female Mean Age Avg Steps Population Survivors 42.8 61.9 11.7 13,446 Non-survivors 43.0 68.0 1...
-
[54]
Vasopressors mcg/kg/min (NE-Eq) NE-Eq=Norepinephrine+Epinephrine+Phenylephrine/10 (Norepinephrine Equivalent)+Dopamine/100 +Vasopressin×2.5/60
-
[55]
We mapped over 20 distinct MIMIC-IV ItemIDs to their physiological expansion coefficients (wk), ranging from 0.25 (hypotonic) to 8.0 (hypertonic)
IV Fluids mL/4h (TEV) TEV=P kwkVk (See Appendix Table 8 for full ItemID cura- tion) (Total Effective V olume)+2×(V Albumin 5%+ 5×VAlbumin 25%) 2https://github.com/MIT-LCP/mimic-code 16 Table 8: Detailed curation of Total Effective V olume (TEV) coefficients. We mapped over 20 distinct MIMIC-IV ItemIDs to their physiological expansion coefficients (wk), ra...
2048
-
[56]
**Data Grounding**: Do not hallucinate symptoms not present in the data
-
[57]
Simulation confirms Action A hits the MAP target (65), whereas Action B fails (63)
**Internal Alignment**: Ensure your reasoning logically leads to the ’Target Action’ provided in the reference context (though do not mention you saw the reference). Please generate the answer directly based on all the provided information, without any additional explanation. Note that you should assume the physician’s decision is not given. Figure 5: Pro...
-
[58]
[vasopressor_level, iv_fluid_level]
**simulation**: Simulate patient outcomes for different treatment actions before making a final decision. - Parameter: actions (list of "[vasopressor_level, iv_fluid_level]" strings, max 3 actions)
-
[59]
- Parameters: vasopressor (int 0-4), iv_fluid (int 0-4) ## Clinical Protocols (Strict Adherence Required)
**prescription**: Execute the final treatment decision. - Parameters: vasopressor (int 0-4), iv_fluid (int 0-4) ## Clinical Protocols (Strict Adherence Required)
-
[60]
Hypoperfusion requires immediate resuscitation
**Emergency Priority**: Sepsis is a medical emergency. Hypoperfusion requires immediate resuscitation
-
[61]
**Early Resuscitation Rule (0-3h)**: Within the first 3 hours of admission (Hour 0), if there are signs of hypoperfusion, at least LOW-level IV fluid is MANDATORY
-
[62]
**Vasopressor Threshold**: If MAP remains < 65 mmHg after adequate fluid resuscitation, vasopressor support should be considered
-
[63]
**MAP Target**: For patients with septic shock on vasopressors, the initial target MAP is 65 mmHg rather than higher targets. 25
-
[64]
name": "simulation
**Definition of Septic Shock**: A patient is in ’Septic Shock’ ONLY if ALL three conditions are met: (a) Vasopressor level > 0 (Currently on vasopressors) (b) MAP (meanbp) < 65 mmHg (c) Lactate > 2 mmol/L # Hour 0 Since ICU Admission (timestep t=0) ## Vital Signs History - heart_rate(bpm): [63.9] - sysbp(mmHg): [107.8] - diabp(mmHg): [58.5] - meanbp(mmHg)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.