Beyond What to Select: A Plug-and-play Oscillatory Data-Volume Scheduling for Efficient Model Training
Pith reviewed 2026-06-30 21:46 UTC · model grok-4.3
The pith
Oscillating data selection ratios exploits implicit regularization to improve the efficiency-generalization trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Selected-data training induces an implicit regularization effect modulated by the instantaneous selection ratio. This reveals a key trade-off: lower ratios amplify selection-induced regularization, whereas higher ratios preserve data coverage and optimization fidelity. Motivated by this insight, PODS alternates between low-ratio regularization phases and high-ratio recovery phases under the target selection ratio, without introducing new sample-scoring metrics.
What carries the argument
The oscillatory data-volume scheduler that alternates low-ratio and high-ratio phases while respecting an overall target average ratio.
If this is right
- Reduces ImageNet-1k training cost by 50% with improved accuracy when used with data selection.
- Accelerates LLM instruction tuning by over 2x without performance degradation.
- Remains compatible with both static and dynamic existing sample selection methods.
- Applies across varied datasets, model architectures, and training paradigms.
Where Pith is reading between the lines
- The same volume-oscillation principle might be tested on modalities or scales not covered in the reported experiments.
- Optimal phase durations or oscillation frequencies could be studied as a function of model size or dataset difficulty.
- The method suggests that fixed-ratio assumptions in other data-efficient training pipelines warrant re-examination.
Load-bearing premise
The implicit regularization induced by lower selection ratios can be safely alternated with higher ratios without harming optimization stability or introducing new failure modes.
What would settle it
A controlled experiment showing lower final accuracy or training divergence with the oscillatory schedule versus a constant ratio at the same average volume would falsify the central claim.
Figures
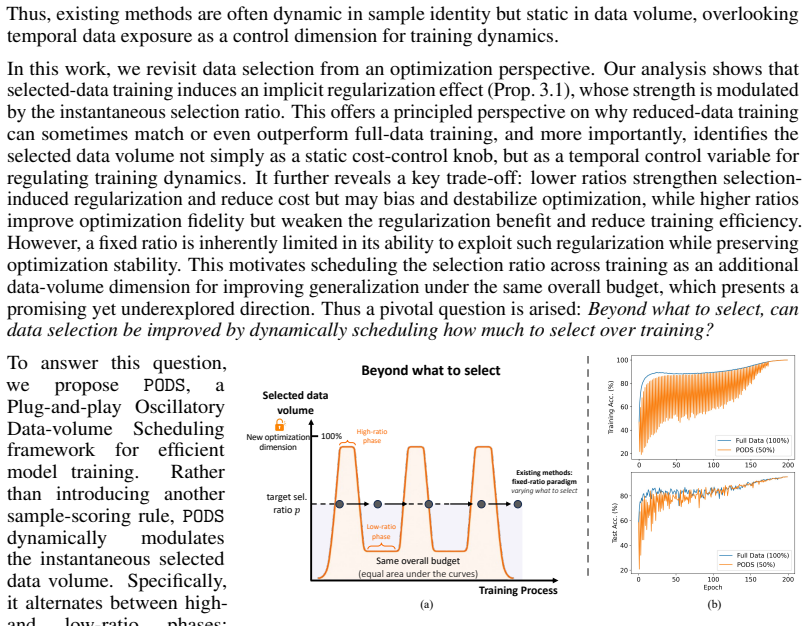
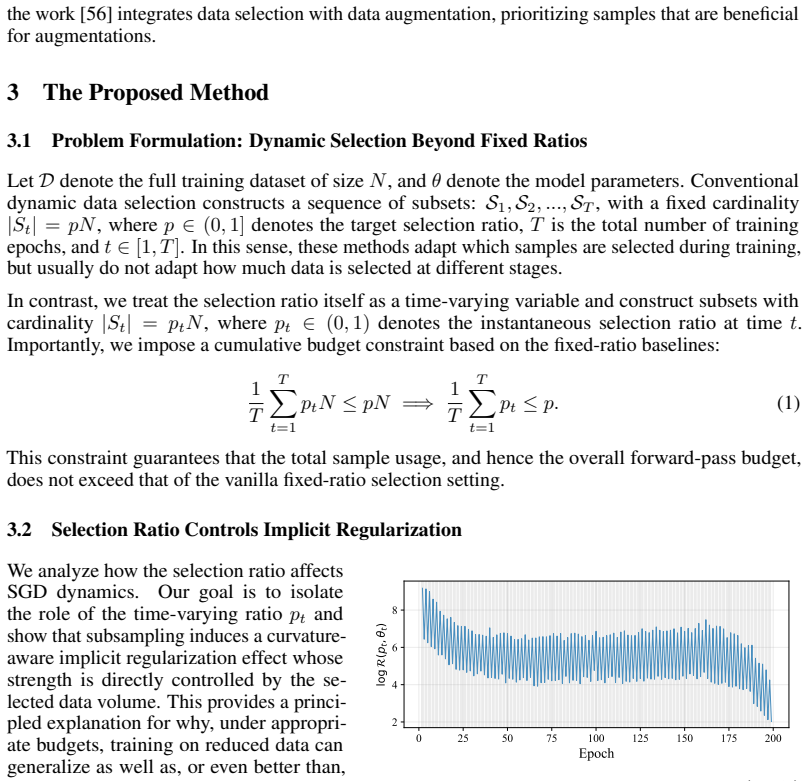
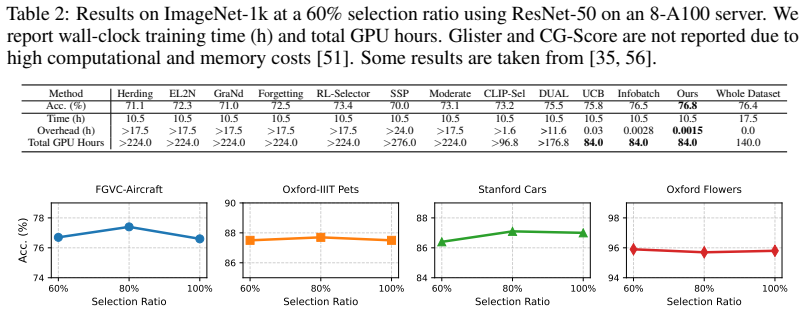
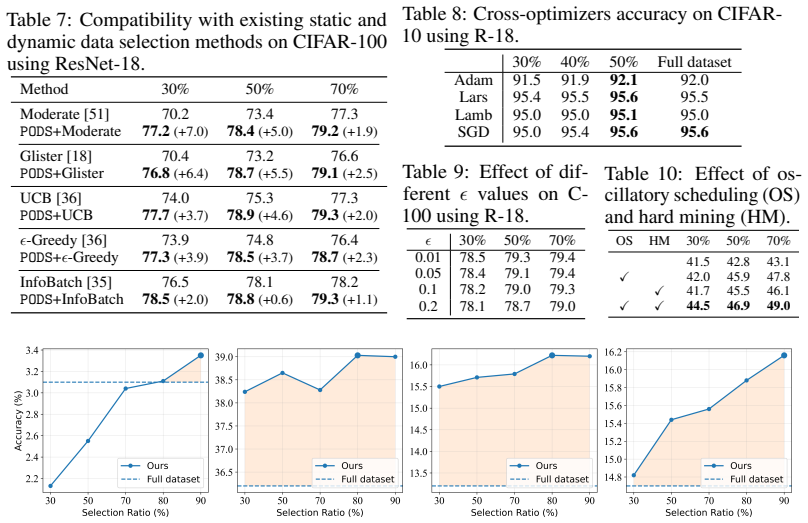
read the original abstract
Data selection accelerates training by identifying representative training data while preserving model performance. However, existing methods mainly focus on designing sample-importance criteria, i.e., deciding what to select, while typically fixing the selected data volume as the target ratio throughout training. Thus, they are often dynamic in sample identity but static in data volume. In this work, we revisit data selection from an optimization perspective and show that selected-data training induces an implicit regularization effect modulated by the instantaneous selection ratio. This reveals a key trade-off: lower ratios amplify selection-induced regularization, whereas higher ratios preserve data coverage and optimization fidelity. Motivated by this insight, we propose PODS, a Plug-and-play Oscillatory Data-volume Scheduling framework. Rather than introducing another sample-scoring metric, PODS serves as a lightweight module that dynamically schedules how much data to select over training. Under the target selection ratio, PODS alternates between low-ratio regularization phases and high-ratio recovery phases to exploit selection-induced regularization without sacrificing optimization stability. With its lightweight, ratio-level, and task-agnostic design, PODS is compatible with existing static and dynamic selection methods and broadly applicable across training paradigms. Experiments across various datasets, architectures, and tasks show that PODS consistently improves the efficiency-generalization trade-off, e.g., reducing ImageNet-1k training cost by 50% with improved accuracy and accelerating LLM instruction tuning by over 2x without performance degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training on selected data induces an implicit regularization effect modulated by the instantaneous selection ratio, creating a trade-off between regularization strength (favored by low ratios) and optimization fidelity (favored by high ratios). It introduces PODS, a lightweight plug-and-play oscillatory scheduler that alternates low-ratio and high-ratio phases under a fixed target ratio to exploit this effect, and reports that the approach is compatible with existing selectors, task-agnostic, and yields substantial gains such as 50% reduction in ImageNet-1k training cost with accuracy improvement and >2x speedup on LLM instruction tuning without degradation.
Significance. If the reported efficiency-generalization improvements hold under rigorous controls and the oscillatory mechanism proves stable, PODS would constitute a simple, ratio-level enhancement that can be layered on top of existing data-selection methods, potentially reducing compute costs in large-scale vision and language training without requiring new sample-scoring criteria.
major comments (2)
- [Abstract] Abstract: the central motivation rests on an 'optimization-derived insight' that selected-data training induces an implicit regularization effect modulated by the selection ratio, yet the abstract supplies no equations, derivation steps, or experimental controls supporting this claim; because this insight directly motivates the design of PODS, its absence is load-bearing for the paper's contribution.
- [Abstract] Abstract: the strongest empirical claims (50% cost reduction on ImageNet-1k with accuracy gain; >2x acceleration on LLM tuning) are stated without reference to specific baselines, ablation on oscillation parameters, or controls isolating the regularization effect from other factors; this makes it impossible to verify that gains arise from the proposed scheduling rather than from the underlying selector or hyper-parameter choices.
minor comments (1)
- The abstract refers to experiments 'across various datasets, architectures, and tasks' without naming them; the introduction or experimental section should list the concrete settings (e.g., ImageNet-1k, specific LLM, architectures) to allow readers to assess scope.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract can be improved to better convey the supporting evidence for the central insight and the empirical claims. We respond to each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central motivation rests on an 'optimization-derived insight' that selected-data training induces an implicit regularization effect modulated by the selection ratio, yet the abstract supplies no equations, derivation steps, or experimental controls supporting this claim; because this insight directly motivates the design of PODS, its absence is load-bearing for the paper's contribution.
Authors: The abstract is intentionally concise and does not include equations or derivation steps, which are provided in the main text (Section 3). However, we recognize that referencing the insight more explicitly could strengthen the abstract. We will revise the abstract to include a short phrase indicating that the insight is supported by optimization analysis and experimental validation in the paper. revision: yes
-
Referee: [Abstract] Abstract: the strongest empirical claims (50% cost reduction on ImageNet-1k with accuracy gain; >2x acceleration on LLM tuning) are stated without reference to specific baselines, ablation on oscillation parameters, or controls isolating the regularization effect from other factors; this makes it impossible to verify that gains arise from the proposed scheduling rather than from the underlying selector or hyper-parameter choices.
Authors: We agree that the abstract presents high-level results without detailing the baselines or controls. The full paper includes these in the experiments section, with comparisons to standard selectors and ablations. To address the concern, we will update the abstract to specify the key baselines (e.g., static selection at target ratio) and note that ablations confirm the contribution of the oscillatory scheduling. revision: yes
Circularity Check
No circularity: empirical scheduling validated externally
full rationale
The paper motivates PODS from an observed trade-off between selection ratio and implicit regularization, then validates the oscillatory schedule through direct experiments on ImageNet-1k, LLMs, and other benchmarks. No equations or claims reduce a prediction to a fitted parameter by construction, no self-citation chain carries the central result, and the module is presented as task-agnostic without deriving its gains from the same runs it evaluates. The derivation chain is therefore self-contained against external performance metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- oscillation schedule parameters (low/high ratios, phase durations, target ratio)
axioms (1)
- domain assumption Selected-data training induces an implicit regularization effect modulated by the instantaneous selection ratio.
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-vl technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025
2025
-
[2]
Lightweight dataset prun- ing without full training via example difficulty and prediction uncertainty
Yeseul Cho, Baekrok Shin, Changmin Kang, and Chulhee Yun. Lightweight dataset prun- ing without full training via example difficulty and prediction uncertainty. InForty-second International Conference on Machine Learning, 2025
2025
-
[3]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
Patryk Chrabaszcz, Ilya Loshchilov, and Frank Hutter. A downsampled variant of imagenet as an alternative to the cifar datasets.arXiv preprint arXiv:1707.08819, Aug 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Free dolly: Introducing the world’s first truly open instructiontuned llm
Mike Conover, Matt Hayes, Ankit Mathur, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia, and Reynold Xin. Free dolly: Introducing the world’s first truly open instructiontuned llm. 2023
2023
-
[5]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[6]
What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems, 33:2881–2891, 2020
Vitaly Feldman and Chiyuan Zhang. What neural networks memorize and why: Discovering the long tail via influence estimation.Advances in Neural Information Processing Systems, 33:2881–2891, 2020
2020
-
[7]
Rcap: Robust, class-aware, probabilistic dynamic dataset pruning
Atif Hassan, Swanand Khare, and Jiaul H Paik. Rcap: Robust, class-aware, probabilistic dynamic dataset pruning. InThe 41st Conference on Uncertainty in Artificial Intelligence, 2025
2025
-
[8]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024
2024
-
[9]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), pages 770–778, 2016
2016
-
[10]
Large-scale dataset pruning with dynamic uncertainty
Muyang He, Shuo Yang, Tiejun Huang, and Bo Zhao. Large-scale dataset pruning with dynamic uncertainty. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7713–7722, 2024
2024
-
[11]
You only condense once: Two rules for pruning condensed datasets.Advances in Neural Information Processing Systems, 36, 2024
Yang He, Lingao Xiao, and Joey Tianyi Zhou. You only condense once: Two rules for pruning condensed datasets.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[12]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8340–8349, 2021
2021
-
[13]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[14]
Natural adversarial examples
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15262–15271, 2021. 10
2021
-
[15]
Submodular combina- torial information measures with applications in machine learning
Rishabh Iyer, Ninad Khargoankar, Jeff Bilmes, and Himanshu Asanani. Submodular combina- torial information measures with applications in machine learning. InAlgorithmic Learning Theory, pages 722–754. PMLR, 2021
2021
-
[16]
Kakade, and Michael I
Chi Jin, Rong Ge, Praneeth Netrapalli, Sham M. Kakade, and Michael I. Jordan. How to escape saddle points efficiently, 2017
2017
-
[17]
Data-efficient contrastive self-supervised learn- ing: Most beneficial examples for supervised learning contribute the least
Siddharth Joshi and Baharan Mirzasoleiman. Data-efficient contrastive self-supervised learn- ing: Most beneficial examples for supervised learning contribute the least. InInternational conference on machine learning, pages 15356–15370. PMLR, 2023
2023
-
[18]
Glister: Generalization based data subset selection for efficient and robust learning
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. Glister: Generalization based data subset selection for efficient and robust learning. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 8110–8118, 2021
2021
-
[19]
Openassistant conversations-democratizing large language model alignment.Advances in neural information processing systems, 36:47669–47681, 2023
Andreas Köpf, Yannic Kilcher, Dimitri V on Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations-democratizing large language model alignment.Advances in neural information processing systems, 36:47669–47681, 2023
2023
-
[20]
Collecting a large-scale dataset of fine-grained cars
Jonathan Krause, Jia Deng, Michael Stark, and Li Fei-Fei. Collecting a large-scale dataset of fine-grained cars. 2013
2013
-
[21]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[22]
Ssrgd: Simple stochastic recursive gradient descent for escaping saddle points
Zhize Li. Ssrgd: Simple stochastic recursive gradient descent for escaping saddle points. Advances in Neural Information Processing Systems, 32, 2019
2019
-
[23]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[24]
Large- scale long-tailed recognition in an open world
Ziwei Liu, Zhongqi Miao, Xiaohang Zhan, Jiayun Wang, Boqing Gong, and Stella X Yu. Large- scale long-tailed recognition in an open world. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2537–2546, 2019
2019
-
[25]
The flan collection: Designing data and methods for effective instruction tuning
Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. The flan collection: Designing data and methods for effective instruction tuning. InInternational conference on machine learning, pages 22631– 22648. PMLR, 2023
2023
-
[26]
Adyasha Maharana, Prateek Yadav, and Mohit Bansal. D2 pruning: Message passing for balancing diversity and difficulty in data pruning.arXiv preprint arXiv:2310.07931, 2023
-
[27]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal
Sören Mindermann, Jan Brauner, Muhammed Razzak, Mrinank Sharma, Andreas Kirsch, Winnie Xu, Benedikt Höltgen, Aidan N. Gomez, Adrien Morisot, Sebastian Farquhar, and Yarin Gal. Prioritized training on points that are learnable, worth learning, and not yet learnt, 2022
2022
-
[29]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, pages 6950–6960. PMLR, 2020
2020
-
[30]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
2008
-
[31]
Data valuation without training of a model
Ki Nohyun, Hoyong Choi, and Hye Won Chung. Data valuation without training of a model. In The Eleventh International Conference on Learning Representations, 2023. 11
2023
-
[32]
Nikolakakis, Amin Karbasi, Dionysis Kalogerias, Nezihe Merve Gürel, and Theodoros Rekatsinas
Patrik Okanovic, Roger Waleffe, Vasilis Mageirakos, Konstantinos E. Nikolakakis, Amin Karbasi, Dionysis Kalogerias, Nezihe Merve Gürel, and Theodoros Rekatsinas. Repeated random sampling for minimizing the time-to-accuracy of learning, 2023
2023
-
[33]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
2012
-
[34]
Deep learning on a data diet: Finding important examples early in training.Advances in Neural Information Processing Systems, 34:20596–20607, 2021
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training.Advances in Neural Information Processing Systems, 34:20596–20607, 2021
2021
-
[35]
Ziheng Qin, Kai Wang, Zangwei Zheng, Jianyang Gu, Xiangyu Peng, Zhaopan Xu, Daquan Zhou, Lei Shang, Baigui Sun, Xuansong Xie, et al. Infobatch: Lossless training speed up by unbiased dynamic data pruning.arXiv preprint arXiv:2303.04947, 2023
-
[36]
Accelerating deep learning with dynamic data pruning.arXiv preprint arXiv:2111.12621, 2021
Ravi S Raju, Kyle Daruwalla, and Mikko Lipasti. Accelerating deep learning with dynamic data pruning.arXiv preprint arXiv:2111.12621, 2021
-
[37]
A weighted k-center algorithm for data subset selection.arXiv preprint arXiv:2312.10602, 2023
Srikumar Ramalingam, Pranjal Awasthi, and Sanjiv Kumar. A weighted k-center algorithm for data subset selection.arXiv preprint arXiv:2312.10602, 2023
-
[38]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[39]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Active learning for convolutional neural networks: A core-set approach, 2018
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach, 2018
2018
-
[41]
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Morcos. Beyond neural scaling laws: beating power law scaling via data pruning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[42]
Le, Ed H
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V . Le, Ed H. Chi, Denny Zhou, and Jason Wei. Challeng- ing big-bench tasks and whether chain-of-thought can solve them, 2022
2022
-
[43]
Imagenet-hard: The hardest images remaining from a study of the power of zoom and spatial biases in image classification.Advances in Neural Information Processing Systems, 36, 2024
Mohammad Reza Taesiri, Giang Nguyen, Sarra Habchi, Cor-Paul Bezemer, and Anh Nguyen. Imagenet-hard: The hardest images remaining from a study of the power of zoom and spatial biases in image classification.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[44]
Data pruning via moving-one-sample-out.Advances in Neural Information Processing Systems, 36, 2024
Haoru Tan, Sitong Wu, Fei Du, Yukang Chen, Zhibin Wang, Fan Wang, and Xiaojuan Qi. Data pruning via moving-one-sample-out.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[45]
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geoffrey J Gordon. An empirical study of example forgetting during deep neural network learning.arXiv preprint arXiv:1812.05159, 2018
-
[46]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia
Jiachen T. Wang, Tong Wu, Dawn Song, Prateek Mittal, and Ruoxi Jia. GREATS: Online selection of high-quality data for LLM training in every iteration. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[48]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark, 2024. 12
2024
-
[49]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[50]
Herding dynamical weights to learn
Max Welling. Herding dynamical weights to learn. InProceedings of the 26th Annual Interna- tional Conference on Machine Learning, pages 1121–1128, 2009
2009
-
[51]
Moderate coreset: A universal method of data selection for real-world data-efficient deep learning
Xiaobo Xia, Jiale Liu, Jun Yu, Xu Shen, Bo Han, and Tongliang Liu. Moderate coreset: A universal method of data selection for real-world data-efficient deep learning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[52]
Dataset pruning: Reducing training data by examining generalization influence
Shuo Yang, Zeke Xie, Hanyu Peng, Min Xu, Mingming Sun, and Ping Li. Dataset pruning: Reducing training data by examining generalization influence. InInternational Conference on Learning Representations, 2023
2023
-
[53]
Suorong Yang, Peijia Li, Furao Shen, and Jian Zhao. Rl-selector: Reinforcement learning- guided data selection via redundancy assessment.arXiv preprint arXiv:2506.21037, 2025
-
[54]
Data agent: Learning to select data via end-to-end dynamic optimization, 2026
Suorong Yang, Fangjian Su, Hai Gan, Ziqi Ye, Jie Li, Baile Xu, Furao Shen, and Soujanya Poria. Data agent: Learning to select data via end-to-end dynamic optimization, 2026
2026
-
[55]
Suorong Yang, Peng Ye, Wanli Ouyang, Dongzhan Zhou, and Furao Shen. A clip-powered framework for robust and generalizable data selection.arXiv preprint arXiv:2410.11215, 2024
-
[56]
Suorong Yang, Peng Ye, Furao Shen, and Dongzhan Zhou. When dynamic data selection meets data augmentation: Achieving enhanced training acceleration.arXiv preprint arXiv:2505.03809, 2025
-
[57]
Towards sustainable learning: Coresets for data-efficient deep learning
Yu Yang, Hao Kang, and Baharan Mirzasoleiman. Towards sustainable learning: Coresets for data-efficient deep learning. InInternational Conference on Machine Learning, pages 39314–39330. PMLR, 2023
2023
-
[58]
What is yolov8: An in-depth exploration of the internal features of the next-generation object detector, 2024
Muhammad Yaseen. What is yolov8: An in-depth exploration of the internal features of the next-generation object detector, 2024
2024
-
[59]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Spanning training progress: Temporal dual-depth scoring (tdds) for enhanced dataset pruning
Xin Zhang, Jiawei Du, Yunsong Li, Weiying Xie, and Joey Tianyi Zhou. Spanning training progress: Temporal dual-depth scoring (tdds) for enhanced dataset pruning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26223–26232, 2024
2024
-
[61]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
2024
-
[62]
Detrs beat yolos on real-time object detection, 2024
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection, 2024
2024
-
[63]
Coverage-centric coreset selection for high pruning rates
Haizhong Zheng, Rui Liu, Fan Lai, and Atul Prakash. Coverage-centric coreset selection for high pruning rates. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[64]
Yuzhe Zhou, Zhenglin Hua, Haiyun Guo, and Yuheng Jia. Rethinking representativeness and diversity in dynamic data selection.arXiv preprint arXiv:2603.04981, 2026. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.