MHSA: A Lightweight Framework for Mitigating Hallucinations via Steered Attention in LVLMs
Pith reviewed 2026-06-30 21:34 UTC · model grok-4.3
The pith
A three-layer MLP learns to correct cross-modal attention and reduces hallucinations in LVLMs by replacing the original patterns at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
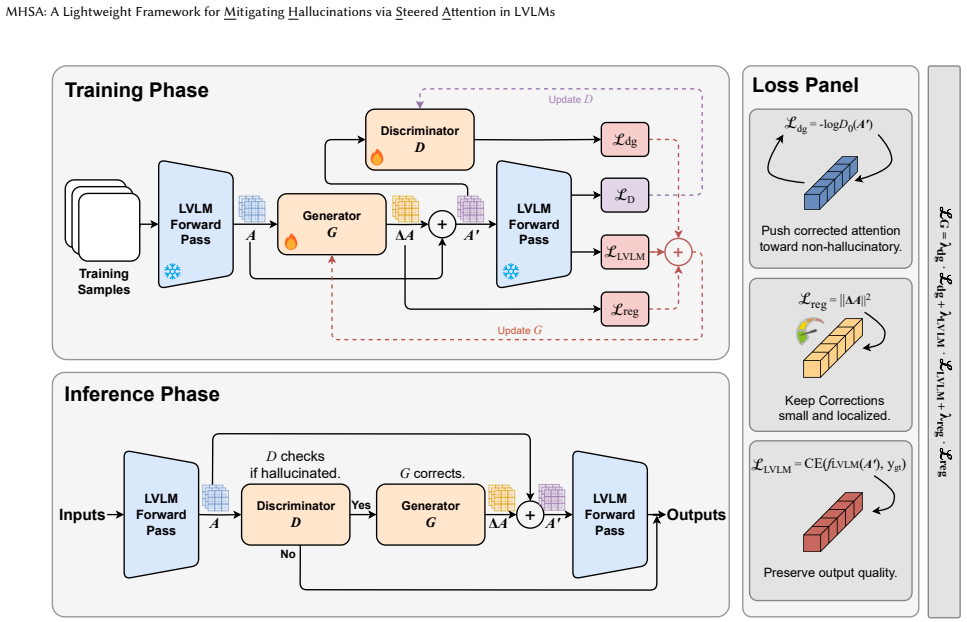
MHSA trains a three-layer MLP generator to produce corrected cross-modal attention patterns, supervised by signals from the DHCP discriminator and the LVLM itself; replacing the original attention maps with these corrections at inference time mitigates both discriminative and generative hallucinations across datasets and LVLMs without any modification to the underlying model parameters.
What carries the argument
Three-layer MLP generator that outputs corrected cross-modal attention maps from the original attention patterns.
If this is right
- Hallucination mitigation becomes possible without retraining or fine-tuning any LVLM weights.
- The same correction mechanism works for both discriminative and generative multimodal tasks.
- Existing DHCP-style attention detectors can be reused as training signals for mitigation.
- The approach extends prior detection work directly into an operational mitigation step.
Where Pith is reading between the lines
- The method could be tested on models larger than those evaluated in the paper to check whether the same three-layer MLP still suffices.
- If the correction generalizes across architectures, it might be applied as a plug-in module to any attention-based multimodal system.
- Combining the steered-attention correction with other post-hoc filters could produce additive gains in reliability.
Load-bearing premise
The MLP corrections learned from one set of models and data will continue to reduce hallucinations when applied to new models and new data without creating fresh errors.
What would settle it
Measure hallucination rates on a held-out collection of LVLMs and datasets after swapping in the MLP-corrected attention; if rates rise or task performance falls compared with the uncorrected baseline, the central claim is false.
Figures



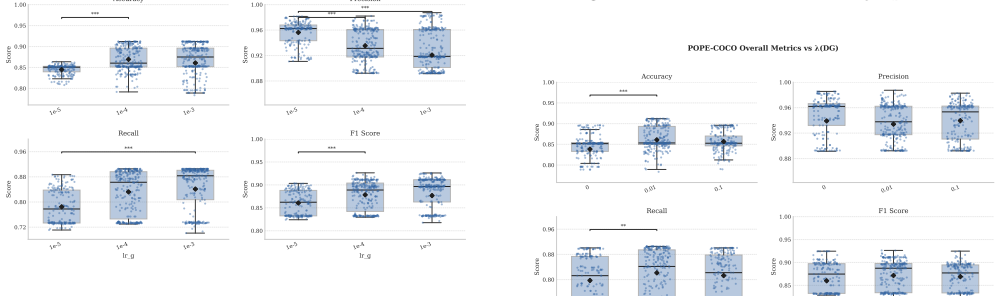
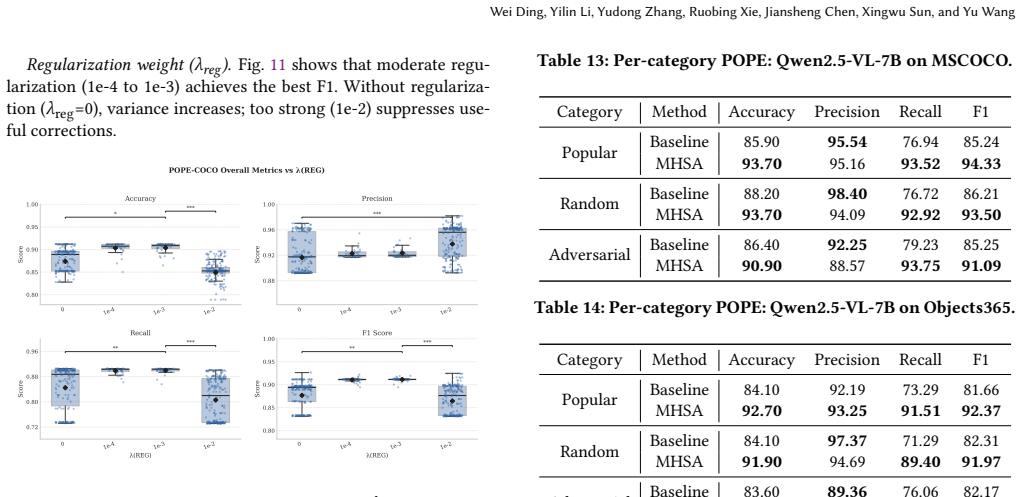
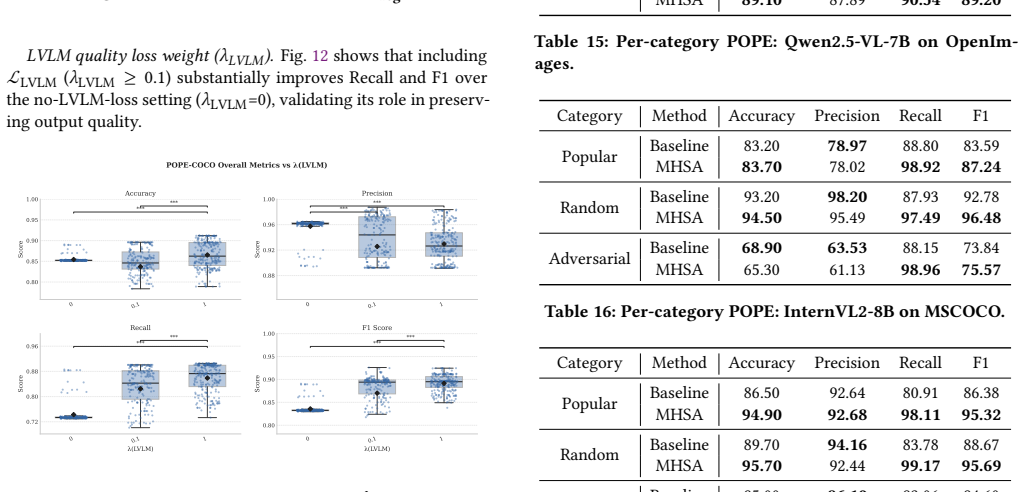



read the original abstract
Large vision-language models (LVLMs) have achieved remarkable performance across diverse multimodal tasks, yet they continue to suffer from hallucinations, generating content that is inconsistent with the visual input. Prior work DHCP (Detecting Hallucinations by Cross-modal Attention Pattern) has explored hallucination detection from the perspective of cross-modal attention, but does not address hallucination mitigation. In this paper, we propose MHSA (Mitigating Hallucinations via Steered Attention), a lightweight framework that mitigates hallucinations by learning to correct cross-modal attention patterns in LVLMs. MHSA trains a simple three-layer MLP generator to produce corrected attention, guided by supervisory signals from the DHCP discriminator and the LVLM itself. During inference, MHSA mitigates both discriminative and generative hallucinations across various datasets and LVLMs by simply replacing the original cross-modal attention with the corrected one, without modifying any LVLM parameters. By extending cross-modal attention mechanisms from hallucination detection to hallucination mitigation, MHSA offers a novel perspective on hallucination research in LVLMs and helps enhance their reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MHSA, a lightweight framework for mitigating hallucinations in LVLMs. It trains a three-layer MLP generator to produce corrected cross-modal attention patterns, guided by supervisory signals from the DHCP discriminator and the LVLM itself. At inference, the original cross-modal attention is replaced by the MLP output to reduce both discriminative and generative hallucinations across datasets and LVLMs, without modifying any parameters of the base LVLM.
Significance. If the central claim holds, the work would provide a parameter-free (for the LVLM) extension of cross-modal attention analysis from detection (DHCP) to mitigation. The lightweight MLP and inference-time replacement approach could be practically useful for improving LVLM reliability.
major comments (2)
- [Abstract] Abstract: the claim of mitigation 'across various datasets and LVLMs' is asserted without any reported metrics, baselines, ablation studies, or quantitative results on hallucination reduction, making it impossible to evaluate whether the central effectiveness claim holds.
- [Abstract] Abstract (and overall claim): the assertion that the three-layer MLP produces attention corrections that reliably transfer to unseen LVLMs and tasks rests on an untested generalization assumption; nothing in the description shows that the corrections are model-agnostic rather than fitted to training attention statistics, which directly undermines the 'without modifying any LVLM parameters' mitigation result.
minor comments (1)
- No equations, loss functions, or training-loop details are provided for the MLP generator or the DHCP/LVLM supervisory signals.
Simulated Author's Rebuttal
We thank the referee for highlighting issues in the abstract. We agree that the abstract overstates claims without supporting details and will revise it to include quantitative results and clarify the scope of generalization and model applicability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of mitigation 'across various datasets and LVLMs' is asserted without any reported metrics, baselines, ablation studies, or quantitative results on hallucination reduction, making it impossible to evaluate whether the central effectiveness claim holds.
Authors: The full manuscript contains experiments with metrics, baselines, and ablations showing hallucination reduction. We acknowledge the abstract lacks these specifics and will revise it to report key quantitative results on mitigation performance across datasets and LVLMs. revision: yes
-
Referee: [Abstract] Abstract (and overall claim): the assertion that the three-layer MLP produces attention corrections that reliably transfer to unseen LVLMs and tasks rests on an untested generalization assumption; nothing in the description shows that the corrections are model-agnostic rather than fitted to training attention statistics, which directly undermines the 'without modifying any LVLM parameters' mitigation result.
Authors: The MLP is trained with signals from DHCP and the LVLM to correct attention patterns, and the method requires no changes to LVLM weights at inference. Experiments demonstrate results on multiple LVLMs, but we agree the abstract does not explicitly address whether corrections generalize to completely unseen models versus being fitted per model. We will revise the abstract to clarify the training and evaluation scope, avoiding any implication of untested zero-shot transfer. revision: yes
Circularity Check
No circularity: empirical MLP training for attention correction stands independent of inputs
full rationale
The paper presents MHSA as training a three-layer MLP generator on supervisory signals from the prior DHCP discriminator and the target LVLM, then applying the corrected attention at inference by direct replacement. No equations, derivations, or self-definitional reductions appear in the provided text. The central claim is an empirical assertion about generalization of the learned corrections, not a mathematical identity or fitted quantity renamed as prediction. The DHCP citation supports only the detection stage and is not invoked as a uniqueness theorem or load-bearing premise for the mitigation result. The method is therefore self-contained against external benchmarks rather than circular by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Menick, Sebas- tian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karén Si- monyan
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhi- tao Gong, Sina Samangooei, Marianne Monteiro, Jacob L. Menick, Sebas- tian Borgeaud, Andy Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj B...
2022
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming- Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[3]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. 2023. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. CoRR abs/2312.14238 (2023). arXiv:2312.14238 doi:10.48550/ARXIV.2312.14238
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.14238 2023
-
[4]
Zhaorun Chen, Zhuokai Zhao, Hongyin Luo, Huaxiu Yao, Bo Li, and Jiawei Zhou. 2024. HALC: Object Hallucination Reduction via Adaptive Focal-Contrast Decoding. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 (Proceedings of Machine Learning Re- search), Ruslan Salakhutdinov, Zico Kolter, Katherine A....
2024
-
[5]
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven C. H. Hoi
-
[6]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , Al- ice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levin...
2023
-
[7]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Ima- geNet: A large-scale hierarchical image database. In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA . IEEE Computer Society, 248–255. doi:10.1109/CVPR. 2009.5206848
-
[8]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. 2023. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. CoRR abs/2306.13394 (2023). arXiv: 2306.13394 doi:10.48550/ ARXIV.2306.13394
Pith/arXiv arXiv 2023
-
[9]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. 2014. Generative Adversarial Nets. In Advances in Neural Information Process- ing Systems 27: Annual Conference on Neural Information Processing Sys- tems 2014, December 8-13 2014, Montreal, Quebec, Canada , Zoubin Ghahra-...
2014
-
[10]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xi- jun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. 2024. Hallusionbench: An Advanced Diagnostic Suite for En- tangled Language Hallucination and Visual Illusion in Large Vision-Language Models. In IEEE/CVF Conference on Computer Vision and Patter...
arXiv 2024
-
[11]
Anisha Gunjal, Jihan Yin, and Erhan Bas. 2024. Detecting and Preventing Hallu- cinations in Large Vision Language Models. In Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Appli- cations of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence...
-
[12]
Qidong Huang, Xiaoyi Dong, Pan Zhang, Bin Wang, Conghui He, Jiaqi Wang, Dahua Lin, Weiming Zhang, and Nenghai Yu. 2024. OPERA: Alleviating Hal- lucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation. In IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2...
-
[13]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper R. R. Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Tom Duerig, and Vittorio Ferrari. 2018. The Open Images Dataset V4: Unified image clas- sification, object detection, and visual relationship detection at scale. CoRR abs/1811.00982 (2018). arXiv: 1811.00982 http:/...
arXiv 2018
-
[14]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating Object Hallucinations in Large Vision- Language Models through Visual Contrastive Decoding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024. IEEE, 13872–13882. doi:10.1109/CVPR52733.2...
-
[15]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven C. H. Hoi. 2023. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research), Andreas Krause, Emma Brunskill, Kyunghyun C...
2023
-
[16]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Evaluating Object Hallucination in Large Vision-Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computa...
-
[17]
Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Com- mon Objects in Context. In Computer Vision - ECCV 2014 - 13th European Con- ference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V (Lecture Notes in Computer Science), David J. Fleet, T...
-
[18]
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, and Lijuan Wang
-
[19]
In The Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Mitigating Hallucination in Large Multi-Modal Models via Robust In- struction Tuning. In The Twelfth International Conference on Learning Represen- tations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net. https: //openreview.net/forum?id=J44HfH4JCg
2024
-
[20]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. Improved Base- lines with Visual Instruction Tuning. In IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, CVPR 2024, Seattle, W A, USA, June 16-22, 2024. IEEE, 26286–26296. doi:10.1109/CVPR52733.2024.02484
-
[21]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Vi- sual Instruction Tuning. In Advances in Neural Information Processing Sys- tems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey...
2023
-
[22]
Shi Liu, Kecheng Zheng, and Wei Chen. 2024. Paying More Attention to Im- age: A Training-Free Method for Alleviating Hallucination in LVLMs. In Com- puter Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29- October 4, 2024, Proceedings, Part LXXXIII (Lecture Notes in Computer Science) , Ales Leonardis, Elisa Ricci, Stefan Roth, Olga...
-
[23]
Holy Lovenia, Wenliang Dai, Samuel Cahyawijaya, Ziwei Ji, and Pascale Fung
-
[24]
Negative Object Presence Evaluation (NOPE) to Measure Object Hallucina- tion in Vision-Language Models. CoRR abs/2310.05338 (2023). arXiv: 2310.05338 doi:10.48550/ARXIV.2310.05338
-
[25]
Bryan A. Plummer, Liwei Wang, Chris M. Cervantes, Juan C. Caicedo, Ju- lia Hockenmaier, and Svetlana Lazebnik. 2017. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models. Int. J. Comput. Vis. 123, 1 (2017), 74–93. doi:10.1007/S11263-016-0965-7
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Mod- els From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 Ju...
2021
-
[27]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. Object Hallucination in Image Captioning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018 , Ellen Riloff, David Chiang, Julia Hock- enmaier, and Jun’ichi Tsujii (Eds.). Associa...
-
[28]
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. 2019. Objects365: A Large-Scale, High-Quality Dataset for Object Detection. In 2019 IEEE/CVF International Conference on Computer Vision, MHSA: A Lightweight Framework for M itigating Hallucinations via S teered Attention in LVLMs ICCV 2019, Seoul, Korea (Sout...
-
[29]
Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to summarize with human feedback. In Advances in Neural In- formation Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , Hu...
2020
-
[30]
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. 2024. Aligning Large Multimodal Models with Factually Augmented RLHF. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-...
-
[31]
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Ming Yan, Ji Zhang, and Jitao Sang. 2023. An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation. CoRR abs/2311.07397 (2023). arXiv:2311.07397 doi:10.48550/ARXIV.2311.07397
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.07397 2023
-
[32]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. 2024. Mitigating Hallucinations in Large Vision-Language Models with Instruction Contrastive Decoding. In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 (Findings of ACL), Lun- Wei Ku, Andre Martins, and Vivek Srikumar...
-
[33]
Yudong Zhang, Ruobing Xie, Jiansheng Chen, Xingwu Sun, and Yu Wang. 2024. PIP: Detecting Adversarial Examples in Large Vision-Language Models via At- tention Patterns of Irrelevant Probe Questions. In Proceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024 , Jianfei Cai, Moh...
-
[34]
Yudong Zhang, Ruobing Xie, Yiqing Huang, Jiansheng Chen, Xingwu Sun, Zhanhui Kang, Di Wang, and Yu Wang. 2025. Fighting Fire with Fire (F3): A Training-free and Efficient Visual Adversarial Example Purification Method in LVLMs. In Proceedings of the 33rd ACM International Conference on Multime- dia, MM 2025, Dublin, Ireland, October 27-31, 2025 , Cathal G...
-
[35]
Yudong Zhang, Ruobing Xie, Xingwu Sun, Yiqing Huang, Jiansheng Chen, Zhan- hui Kang, Di Wang, and Yu Wang. 2025. DHCP: Detecting Hallucinations by Cross-modal Attention Pattern in Large Vision-Language Models. In Proceed- ings of the 33rd ACM International Conference on Multimedia, MM 2025, Dublin, Ireland, October 27-31, 2025, Cathal Gurrin, Klaus Schoef...
-
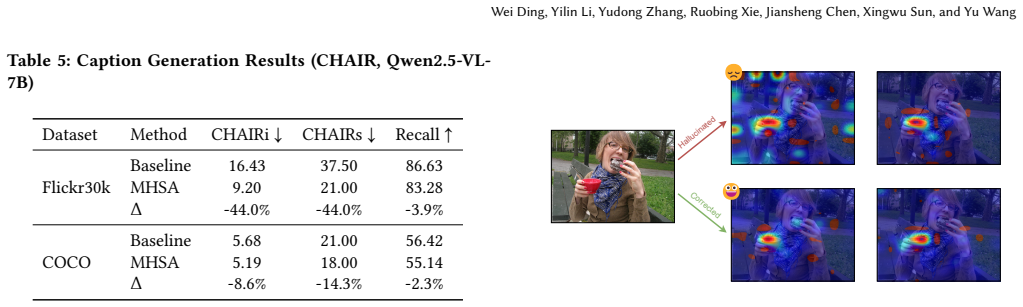
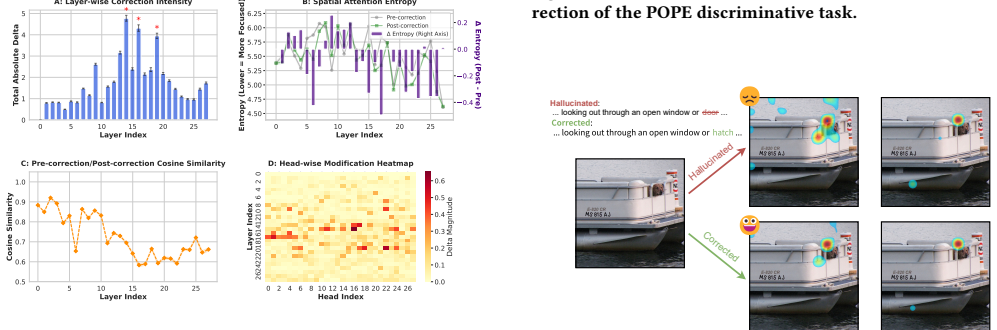
[36]
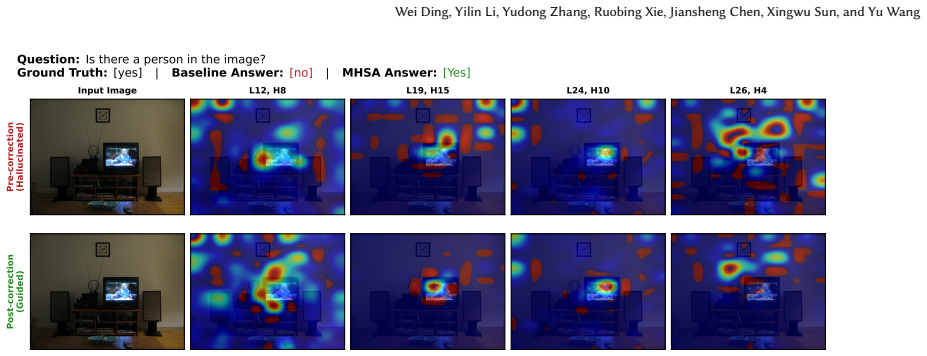
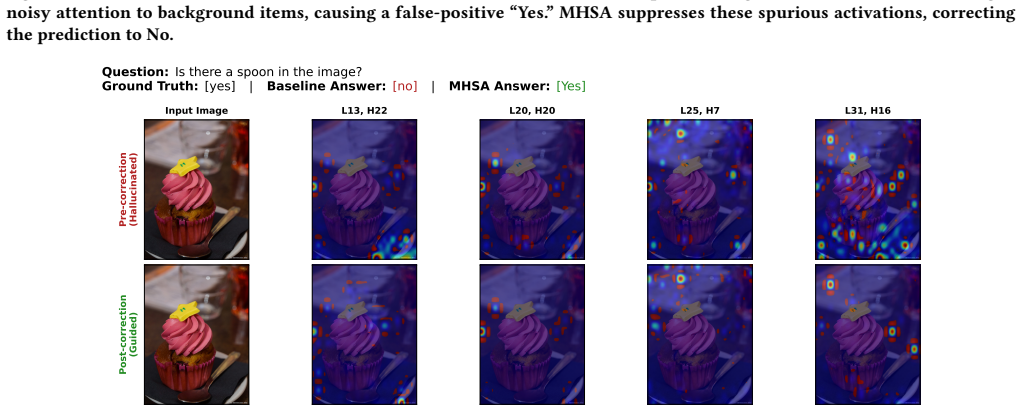
No” due to diffuse, unfocused attention, while MHSA concentrates attention on the person region and corrects the an- swer to “Yes
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. 2024. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. In The Twelfth International Conference on Learning Repre- sentations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net. https: //openreview.net/forum?id=1tZbq88f27 Wei Ding, Yilin Li...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.