Recognition: 2 theorem links
· Lean TheoremSat3DGen: Comprehensive Street-Level 3D Scene Generation from Single Satellite Image
Pith reviewed 2026-05-15 03:11 UTC · model grok-4.3
The pith
A geometry-first training strategy generates accurate street-level 3D scenes directly from single satellite images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sat3DGen demonstrates that a geometry-first methodology, which augments a standard feed-forward image-to-3D backbone with novel geometric constraints and a perspective-view training regimen, directly mitigates the viewpoint gap and sparse supervision that previously limited both metric accuracy and visual quality in satellite-to-street scene generation.
What carries the argument
The geometry-first methodology that adds explicit geometric constraints to the feed-forward image-to-3D framework and trains under a perspective-view regime.
If this is right
- Geometric RMSE drops from 6.76 m to 5.20 m on the VIGOR-OOD benchmark paired with high-resolution DSM data.
- FID falls from approximately 40 to 19 against the prior leading method without any extra image-quality components.
- High-quality 3D assets become available for semantic-map-to-3D synthesis, multi-camera video generation, large-scale meshing, and unsupervised single-image DSM estimation.
Where Pith is reading between the lines
- The approach may scale to city-wide 3D reconstruction if satellite coverage density increases.
- Similar constraint-plus-perspective training could be tested on other wide-baseline 3D tasks such as aerial-to-ground fusion.
- The unsupervised DSM recovery path suggests the model learns metric structure without explicit depth labels.
Load-bearing premise
The extreme viewpoint gap and sparse inconsistent supervision between satellite and street views can be overcome by adding geometric constraints and perspective-view training.
What would settle it
If the same Sat3DGen architecture trained on the VIGOR-OOD benchmark with DSM supervision still yields RMSE above 6 m and FID above 30, the claim that geometric constraints plus perspective training close the gap would be falsified.
Figures











read the original abstract
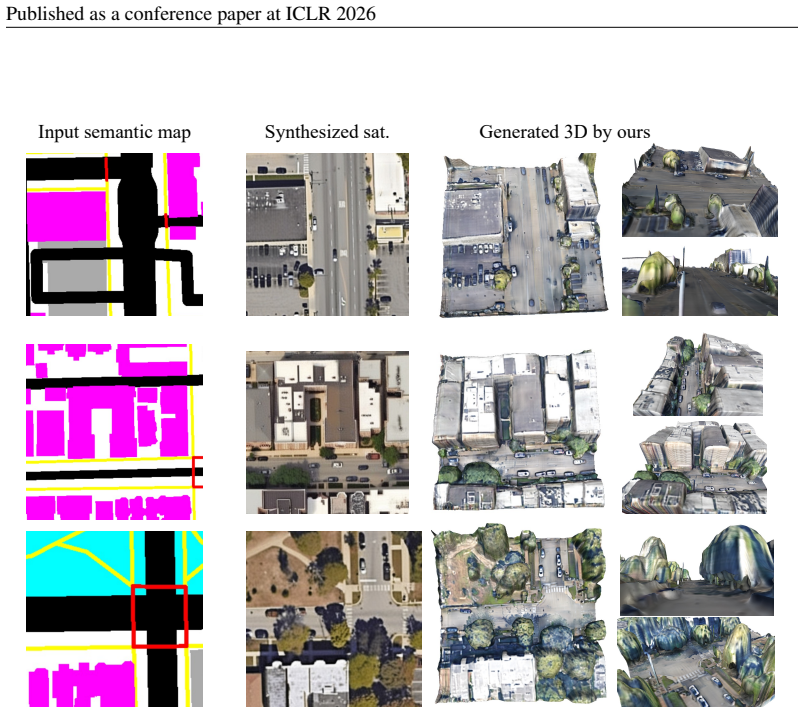
Generating a street-level 3D scene from a single satellite image is a crucial yet challenging task. Current methods present a stark trade-off: geometry-colorization models achieve high geometric fidelity but are typically building-focused and lack semantic diversity. In contrast, proxy-based models use feed-forward image-to-3D frameworks to generate holistic scenes by jointly learning geometry and texture, a process that yields rich content but coarse and unstable geometry. We attribute these geometric failures to the extreme viewpoint gap and sparse, inconsistent supervision inherent in satellite-to-street data. We introduce Sat3DGen to address these fundamental challenges, which embodies a geometry-first methodology. This methodology enhances the feed-forward paradigm by integrating novel geometric constraints with a perspective-view training strategy, explicitly countering the primary sources of geometric error. This geometry-centric strategy yields a dramatic leap in both 3D accuracy and photorealism. For validation, we first constructed a new benchmark by pairing the VIGOR-OOD test set with high-resolution DSM data. On this benchmark, our method improves geometric RMSE from 6.76m to 5.20m. Crucially, this geometric leap also boosts photorealism, reducing the Fr\'echet Inception Distance (FID) from $\sim$40 to 19 against the leading method, Sat2Density++, despite using no extra tailored image-quality modules. We demonstrate the versatility of our high-quality 3D assets through diverse downstream applications, including semantic-map-to-3D synthesis, multi-camera video generation, large-scale meshing, and unsupervised single-image Digital Surface Model (DSM) estimation. The code has been released on https://github.com/qianmingduowan/Sat3DGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Sat3DGen, a geometry-first feed-forward method for generating street-level 3D scenes from a single satellite image. It integrates novel geometric constraints with a perspective-view training strategy to address the extreme viewpoint gap and sparse supervision in satellite-to-street data. On a newly constructed VIGOR-OOD benchmark paired with DSM data, the method reports reducing geometric RMSE from 6.76 m to 5.20 m and FID from ~40 to 19 relative to Sat2Density++, while enabling downstream tasks such as semantic-map-to-3D synthesis and unsupervised DSM estimation. The code is released publicly.
Significance. If the central improvements hold under controlled validation, the work would advance satellite-to-street 3D generation by demonstrating that explicit geometric constraints can simultaneously boost accuracy and photorealism without dedicated image-quality modules. The construction of a DSM-augmented benchmark and public code release are concrete strengths that support reproducibility and downstream research in large-scale meshing and multi-view synthesis.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The headline claim that the 1.56 m RMSE reduction and FID halving are driven by the novel geometric constraints plus perspective-view training lacks support from any ablation that removes only those constraints while freezing architecture, data, and other losses. Without this isolation, the measured gains could arise from benchmark construction, training schedule, or capacity changes.
- [Experiments] Experiments section: No error analysis or per-scene breakdown is provided to show where the geometric constraints specifically mitigate the viewpoint gap versus other factors; this is load-bearing for the assertion that the methodology 'explicitly counters the primary sources of geometric error.'
minor comments (2)
- The abstract contains a typesetting artifact ('Fréchet' rendered as 'Fréchet' with backslash); ensure consistent LaTeX rendering and define DSM on first use in the main text.
- Figure captions and table legends should explicitly state whether reported metrics are computed on the full test set or a subset, and whether the baseline Sat2Density++ was retrained on the new DSM-augmented benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to strengthen the experimental validation as suggested.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline claim that the 1.56 m RMSE reduction and FID halving are driven by the novel geometric constraints plus perspective-view training lacks support from any ablation that removes only those constraints while freezing architecture, data, and other losses. Without this isolation, the measured gains could arise from benchmark construction, training schedule, or capacity changes.
Authors: We agree that an ablation isolating only the geometric constraints and perspective-view training (while freezing architecture, data, and remaining losses) would provide stronger evidence for the headline claims. In the revised manuscript we will add this controlled ablation study to demonstrate that the reported RMSE and FID improvements are attributable to the proposed components rather than other factors such as benchmark construction or training schedule. revision: yes
-
Referee: [Experiments] Experiments section: No error analysis or per-scene breakdown is provided to show where the geometric constraints specifically mitigate the viewpoint gap versus other factors; this is load-bearing for the assertion that the methodology 'explicitly counters the primary sources of geometric error.'
Authors: We acknowledge that per-scene error breakdowns and targeted analysis would better illustrate how the geometric constraints address the viewpoint gap. In the revision we will incorporate additional error analysis, including per-scene RMSE statistics, error map visualizations, and breakdowns by scene characteristics to show the specific mitigation of viewpoint-related errors. revision: yes
Circularity Check
No circularity: empirical gains presented as direct benchmark outcomes without self-referential reductions
full rationale
The paper's central claims rest on measured RMSE (6.76 m to 5.20 m) and FID (~40 to 19) improvements on a newly constructed VIGOR-OOD + DSM benchmark. These are reported as empirical results of the geometry-first pipeline rather than quantities derived from fitted parameters or self-cited uniqueness theorems. No equations appear that define geometric constraints in terms of the target accuracy metrics, no predictions are statistically forced by training-set fits, and no load-bearing premises reduce to prior self-citations. The methodology is described at the level of architectural choices and training strategies whose effects are validated externally on held-out data.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Gravity-based Density Variation Loss ... σ should generally be non-increasing with altitude ... Lgrav = E[ReLU(σ(x+δz)−σ(x)−ϵ)]
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Monocular Relative-Depth Prior ... Ldepth = scale-shift invariant MiDaS-style loss on satellite-view depth
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Eric R. Chan and Connor Z. Lin and Matthew A. Chan and Koki Nagano and Boxiao Pan and Shalini De Mello and Orazio Gallo and Leonidas Guibas and Jonathan Tremblay and Sameh Khamis and Tero Karras and Gordon Wetzstein , title =
-
[5]
3D-aware Conditional Image Synthesis , author=
-
[6]
Ricardo Martin. NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections , booktitle = CVPR, pages =. 2021 , doi =
work page 2021
-
[7]
Regmi, Krishna and Borji, Ali , title =
-
[8]
Oswald and Marc Pollefeys and Rongjun Qin , title =
Xiaohu Lu and Zuoyue Li and Zhaopeng Cui and Martin R. Oswald and Marc Pollefeys and Rongjun Qin , title =
-
[9]
Krishna Regmi and Ali Borji , title =
-
[10]
Hao Tang and Dan Xu and Nicu Sebe and Yanzhi Wang and Jason J. Corso and Yan Yan , title =
-
[11]
Yujiao Shi and Dylan Campbell and Xin Yu and Hongdong Li , title =
-
[12]
Li, Zuoyue and Li, Zhenqiang and Cui, Zhaopeng and Qin, Rongjun and Pollefeys, Marc and Oswald, Martin R. , booktitle=ICCV, title=. 2021 , volume=
work page 2021
- [13]
-
[14]
Ming Qian and Jincheng Xiong and Gui-Song Xia and Nan Xue , booktitle = ICCV, title =. 2023 , volume =
work page 2023
-
[15]
Park, Taesung and Liu, Ming-Yu and Wang, Ting-Chun and Zhu, Jun-Yan , booktitle=CVPR, title=. 2019 , volume=
work page 2019
-
[16]
Kajiya and Brian Von Herzen , title =
James T. Kajiya and Brian Von Herzen , title =. Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques,. 1984 , doi =
work page 1984
-
[17]
Srinivasan and Matthew Tancik and Jonathan T
Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng , title =. 2020 , timestamp =
work page 2020
-
[18]
StyleNeRF: A Style-based 3D Aware Generator for High-resolution Image Synthesis , author=
-
[19]
Advances in Neural Information Processing Systems , year =
A Shading-Guided Generative Implicit Model for Shape-Accurate 3D-Aware Image Synthesis , author =. Advances in Neural Information Processing Systems , year =
-
[20]
Jiaming Zhang and Kailun Yang and Chaoxiang Ma and Simon Rei. Bending Reality: Distortion-aware Transformers for Adapting to Panoramic Semantic Segmentation , booktitle = CVPR, pages =
-
[21]
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data , author=
-
[22]
R. Zhang and P. Isola and A. A. Efros and E. Shechtman and O. Wang , booktitle = CVPR, title =. 2018 , volume =
work page 2018
-
[23]
Zoedepth: Zero-shot transfer by combining relative and metric depth , author=. Arxiv , year=
-
[24]
Omnidata: A Scalable Pipeline for Making Multi-Task Mid-Level Vision Datasets From 3D Scans , author=
-
[25]
3D Common Corruptions and Data Augmentation , author=
-
[26]
Ian J. Goodfellow and Jean Pouget. Generative Adversarial Nets , booktitle = NIPS, pages =. 2014 , timestamp =
work page 2014
-
[27]
Mescheder and Andreas Geiger and Sebastian Nowozin , title =
Lars M. Mescheder and Andreas Geiger and Sebastian Nowozin , title =. 2018 , timestamp =
work page 2018
-
[28]
Tero Karras and Samuli Laine and Miika Aittala and Janne Hellsten and Jaakko Lehtinen and Timo Aila , title =
-
[29]
VIGOR: Cross-View Image Geo-localization beyond One-to-one Retrieval , author=
-
[30]
Lentsch, Ted and Xia, Zimin and Caesar, Holger and Kooij, Julian F. P. , title =. 2023 , pages =
work page 2023
-
[31]
Liu, Andrew and Tucker, Richard and Jampani, Varun and Makadia, Ameesh and Snavely, Noah and Kanazawa, Angjoo , title =
-
[32]
InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images , author =
-
[33]
Yuanbo Yang and Yifei Yang and Hanlei Guo and Rong Xiong and Yue Wang and Yiyi Liao , title =
-
[34]
Yuanbo Xiangli and Linning Xu and Xingang Pan and Nanxuan Zhao and Bo Dai and Dahua Lin , title =. 2023 , doi =
work page 2023
-
[35]
Lin, Chieh Hubert and Lee, Hsin-Ying and Menapace, Willi and Chai, Menglei and Siarohin, Aliaksandr and Yang, Ming-Hsuan and Tulyakov, Sergey , booktitle=ICCV, year=. Infini
-
[36]
Xie, Haozhe and Chen, Zhaoxi and Hong, Fangzhou and Liu, Ziwei , booktitle = CVPR, year =. City
-
[37]
Menghua Zhai and Zachary Bessinger and Scott Workman and Nathan Jacobs , title =
-
[38]
Spatial-aware feature aggregation for image based cross-view geo-localization , author=
-
[39]
Yujiao Shi and Liu Liu and Xin Yu and Hongdong Li , title =
-
[40]
Yujiao Shi and Xin Yu and Liu Liu and Tong Zhang and Hongdong Li , title =
-
[41]
Scott Workman and Muhammad Usman Rafique and Hunter Blanton and Nathan Jacobs , title =
-
[42]
Scott Workman and Hunter Blanton , title =
-
[43]
Image-to-Image Translation with Conditional Adversarial Networks , booktitle = CVPR, pages =
Phillip Isola and Jun. Image-to-Image Translation with Conditional Adversarial Networks , booktitle = CVPR, pages =
-
[44]
Thomas Unterthiner and Sjoerd van Steenkiste and Karol Kurach and Rapha. 2019 , timestamp =
work page 2019
-
[45]
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation , booktitle = CVPR, pages =
Cheng. MaskGAN: Towards Diverse and Interactive Facial Image Manipulation , booktitle = CVPR, pages =. 2020 , doi =
work page 2020
-
[46]
StarGAN v2: Diverse Image Synthesis for Multiple Domains , booktitle = CVPR, pages =
Yunjey Choi and Youngjung Uh and Jaejun Yoo and Jung. StarGAN v2: Diverse Image Synthesis for Multiple Domains , booktitle = CVPR, pages =. 2020 , doi =
work page 2020
-
[47]
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang and Thomas A. Funkhouser and Leonidas J. Guibas and Pat Hanrahan and Qi. ShapeNet: An Information-Rich 3D Model Repository , journal =. 2015 , eprinttype =. 1512.03012 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[48]
Qiuyu Wang and Zifan Shi and Kecheng Zheng and Yinghao Xu and Sida Peng and Yujun Shen , title =. 2023 , timestamp =
work page 2023
-
[49]
Alex Krizhevsky and Ilya Sutskever and Geoffrey E. Hinton , title =. 2012 , timestamp =
work page 2012
-
[50]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size , author=. 2016 , eprint=
work page 2016
-
[51]
A. Toker and Q. Zhou and M. Maximov and L. Leal-Taixe , booktitle = CVPR, title =. 2021 , volume =
work page 2021
- [52]
-
[53]
Yichao Zhou and Jingwei Huang and Xili Dai and Linjie Luo and Zhili Chen and Yi Ma , title =. CoRR , volume =. 2020 , eprinttype =. 2008.03286 , timestamp =
- [54]
- [55]
-
[56]
3D Gaussian Splatting for Real-Time Radiance Field Rendering , journal = TOG, number =
Kerbl, Bernhard and Kopanas, Georgios and Leimk. 3D Gaussian Splatting for Real-Time Radiance Field Rendering , journal = TOG, number =
-
[57]
Xiaomou Hou and Wanshui Gan and Naoto Yokoya , title =. CoRR , volume =. 2023 , doi =
work page 2023
-
[58]
Konstantinos Rematas and Andrew Liu and Pratul P. Srinivasan and Jonathan T. Barron and Andrea Tagliasacchi and Thomas A. Funkhouser and Vittorio Ferrari , title =
-
[59]
Jean. Estimating the Natural Illumination Conditions from a Single Outdoor Image , journal = IJCV, volume =. 2012 , doi =
work page 2012
-
[60]
Tang, Jiajun and Zhu, Yongjie and Wang, Haoyu and Chan, Jun-Hoong and Li, Si and Shi, Boxin , title =
-
[61]
Deep sky modeling for single image outdoor lighting estimation , author=
-
[62]
Wimbauer, Felix and Yang, Nan and Rupprecht, Christian and Cremers, Daniel , booktitle = CVPR, title =. 2023 , volume =
work page 2023
-
[63]
Yu, Alex and Ye, Vickie and Tancik, Matthew and Kanazawa, Angjoo , booktitle = CVPR, title =. 2021 , volume =
work page 2021
-
[64]
On Aliased Resizing and Surprising Subtleties in GAN Evaluation , author=
- [65]
- [66]
-
[67]
Yinghao Xu and Hao Tan and Fujun Luan and Sai Bi and Peng Wang and Jiahao Li and Zifan Shi and Kalyan Sunkavalli and Gordon Wetzstein and Zexiang Xu and Kai Zhang , booktitle=ICLR, year=
-
[68]
Yinghao Xu and Zifan Shi and Yifan Wang and Hansheng Chen and Ceyuan Yang and Sida Peng and Yujun Shen and Gordon Wetzstein , title =
-
[69]
Xinyang Li and Zhangyu Lai and Linning Xu and Jianfei Guo and Liujuan Cao and Shengchuan Zhang and Bo Dai and Rongrong Ji , title =. CoRR , volume =. 2024 , eprinttype =
work page 2024
-
[70]
DINOv2: Learning Robust Visual Features without Supervision
DINOv2: Learning Robust Visual Features without Supervision , author=. arXiv:2304.07193 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
2017 , booktitle = NIPS, pages =
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , title =. 2017 , booktitle = NIPS, pages =
work page 2017
-
[72]
Sutherland and Michael Arbel and Arthur Gretton , booktitle=ICLR, year=
Mikołaj Bińkowski and Dougal J. Sutherland and Michael Arbel and Arthur Gretton , booktitle=ICLR, year=. Demystifying
-
[73]
Zekun Hao and Arun Mallya and Serge Belongie and Ming-Yu Liu , booktitle=ICCV, year=
-
[74]
Alex Yu and Vickie Ye and Matthew Tancik and Angjoo Kanazawa , year=
-
[75]
Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting , author=
-
[76]
Street view imagery in urban analytics and GIS: A review , journal =. 2021 , issn =
work page 2021
-
[77]
Proceedings of the 18th International Conference on Mobile and Ubiquitous Multimedia , articleno =
Kostakos, Panos and Alavesa, Paula and Oppenlaender, Jonas and Hosio, Simo , title =. Proceedings of the 18th International Conference on Mobile and Ubiquitous Multimedia , articleno =. 2019 , isbn =
work page 2019
-
[78]
Li, Guopeng and Qian, Ming and Xia, Gui-Song , title =. 2024 , pages =
work page 2024
-
[79]
Abhishek Kar and Christian H\"ane and Jitendra Malik , title =
-
[80]
Groueix, Thibault and Fisher, Matthew and Kim, Vladimir G. and Russell, Bryan C. and Aubry, Mathieu , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.