DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
Pith reviewed 2026-06-30 21:17 UTC · model grok-4.3
The pith
DiffusionOPD enables multi-task diffusion training by distilling independent teachers into a student along its own trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that lifting online policy distillation to continuous-state Markov processes produces an analytic per-step KL objective based on mean matching; this objective lets a single student acquire multiple task skills from independently trained teachers without the interference of joint optimization or the forgetting of cascade training, and the resulting gradients have lower variance than conventional PPO-style updates.
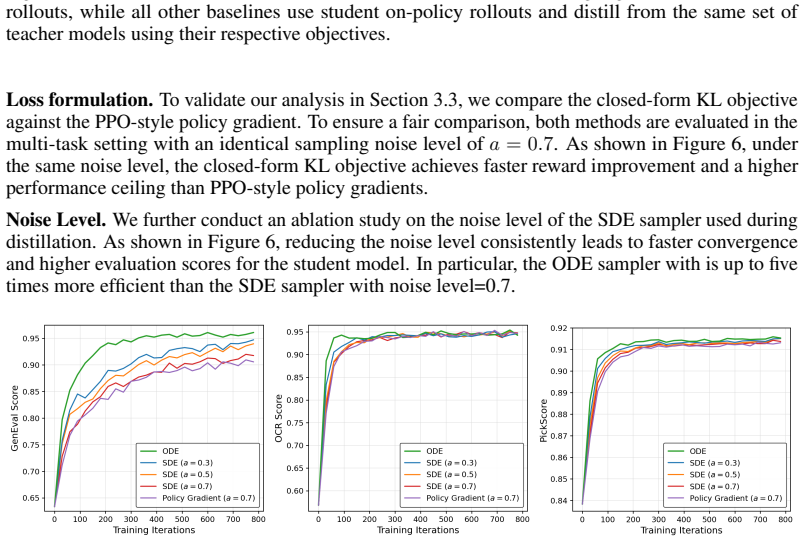
What carries the argument
The per-step KL objective for continuous diffusion processes that unifies SDE and ODE refinement through mean-matching during on-policy distillation.
If this is right
- Single-task exploration is decoupled from the integration of multiple capabilities.
- The analytic gradient exhibits lower variance than PPO-style policy gradients.
- Training efficiency and final performance exceed those of multi-reward RL and cascade RL.
- State-of-the-art results appear on all evaluated text-to-image benchmarks.
Where Pith is reading between the lines
- The mean-matching objective may simplify gradient estimation in other continuous-state generative settings.
- Pre-trained teachers could be reused to add new tasks with reduced total compute.
- The separation of teacher training from student integration might extend to non-diffusion generative models that use policy-based fine-tuning.
Load-bearing premise
Capabilities from separately trained teachers can be combined in the student without cross-task interference or forgetting when distillation follows the student's own trajectories.
What would settle it
A controlled run in which the student model scores lower on any single task after distillation than the dedicated teacher for that task alone.
Figures



read the original abstract
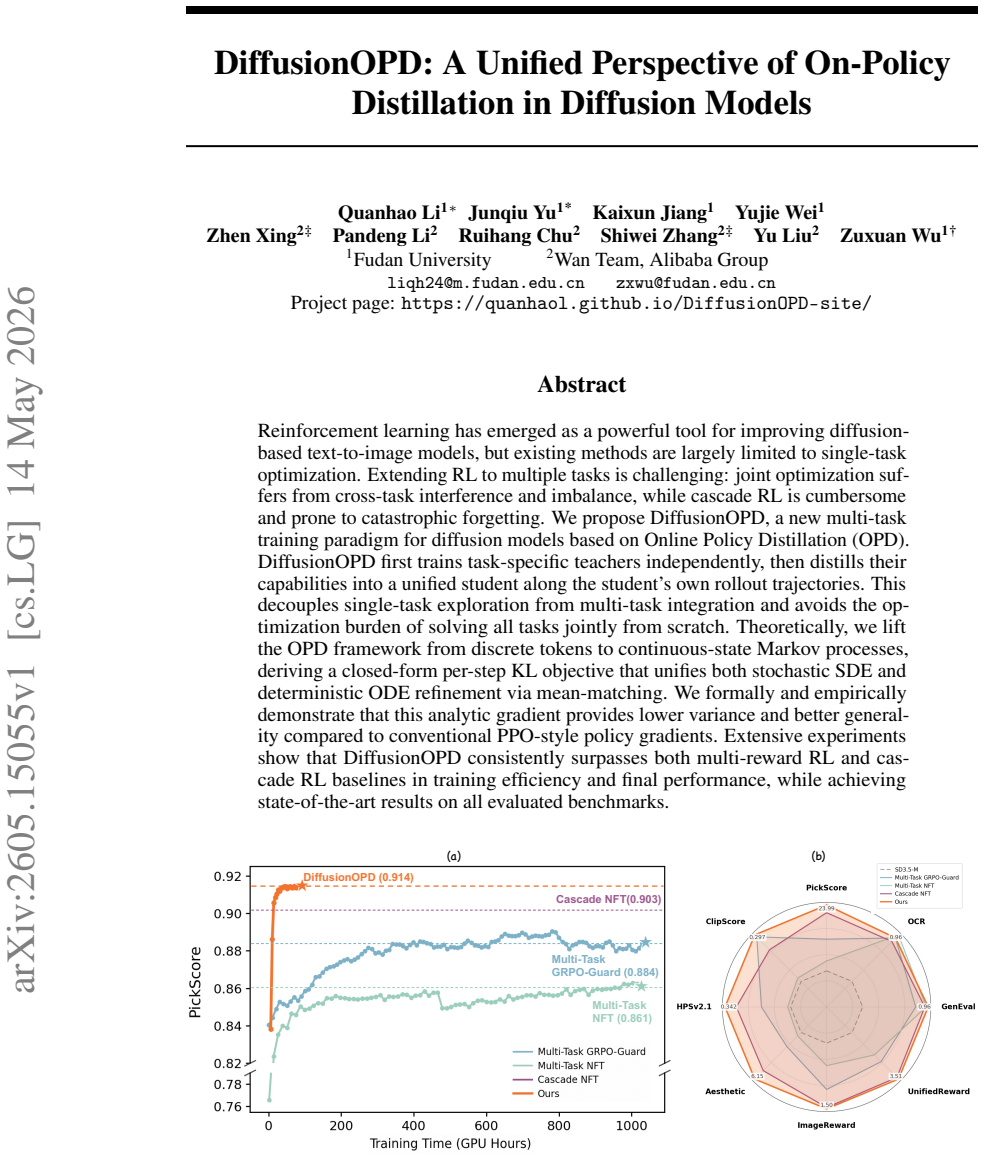
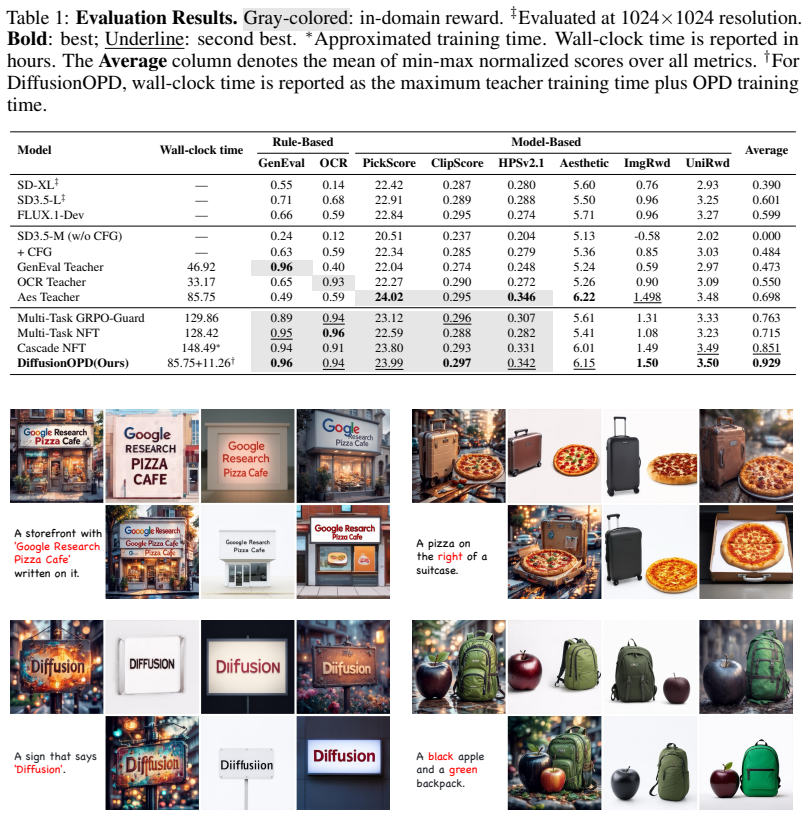
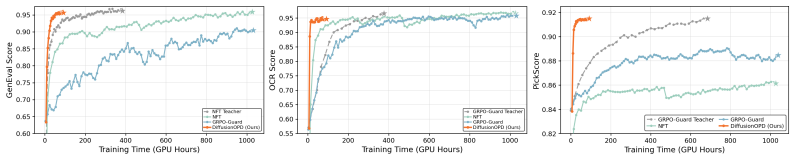
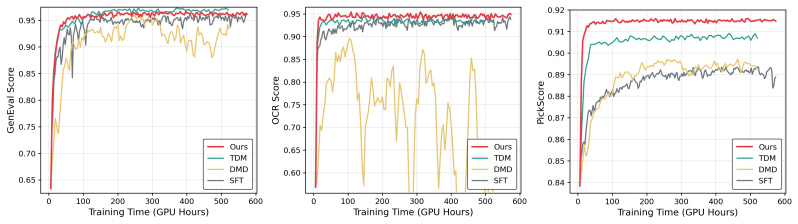
Reinforcement learning has emerged as a powerful tool for improving diffusion-based text-to-image models, but existing methods are largely limited to single-task optimization. Extending RL to multiple tasks is challenging: joint optimization suffers from cross-task interference and imbalance, while cascade RL is cumbersome and prone to catastrophic forgetting. We propose DiffusionOPD, a new multi-task training paradigm for diffusion models based on Online Policy Distillation (OPD). DiffusionOPD first trains task-specific teachers independently, then distills their capabilities into a unified student along the student own rollout trajectories. This decouples single-task exploration from multi-task integration and avoids the optimization burden of solving all tasks jointly from scratch. Theoretically, we lift the OPD framework from discrete tokens to continuous-state Markov processes, deriving a closed-form per-step KL objective that unifies both stochastic SDE and deterministic ODE refinement via mean-matching. We formally and empirically demonstrate that this analytic gradient provides lower variance and better generality compared to conventional PPO-style policy gradients. Extensive experiments show that DiffusionOPD consistently surpasses both multi-reward RL and cascade RL baselines in training efficiency and final performance, while achieving state-of-the-art results on all evaluated benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffusionOPD, a multi-task training paradigm for diffusion-based text-to-image models. Task-specific teachers are trained independently and their capabilities are distilled into a single student model along the student's own rollout trajectories. The central theoretical contribution is an extension of online policy distillation from discrete to continuous-state Markov processes, yielding a claimed closed-form per-step KL objective that unifies stochastic SDE and deterministic ODE refinement via mean-matching; the resulting analytic gradients are asserted to have lower variance than PPO-style policy gradients. Experiments report consistent outperformance over multi-reward RL and cascade RL baselines in efficiency and final performance, together with state-of-the-art results on all evaluated benchmarks.
Significance. If the derivation of the closed-form KL objective is correct and the empirical gains are reproducible, the work offers a practical route to multi-task optimization that avoids joint-training interference and catastrophic forgetting. The unification of SDE/ODE cases and the lower-variance gradient claim, if substantiated, would be a useful technical contribution to the growing literature on RL fine-tuning of diffusion models.
major comments (2)
- [Abstract / §3 (theoretical derivation)] The central theoretical claim (closed-form per-step KL that unifies SDE/ODE via mean-matching) is load-bearing for the paper's novelty; the abstract provides no equations, so it is impossible to verify whether the result is non-circular with respect to quantities already present in the teacher models or standard diffusion training objectives.
- [Experiments section (multi-task results)] The empirical claim of consistent superiority over multi-reward and cascade RL baselines rests on the decoupling premise (independent teachers distilled along student trajectories). No quantitative evidence is supplied in the provided description to confirm absence of cross-task interference or forgetting; this assumption directly supports the multi-task integration claim.
minor comments (2)
- The abstract is dense; separating the theoretical unification, gradient-variance argument, and empirical protocol into distinct sentences would improve readability.
- Notation for the continuous-state Markov decision process (state, action, transition) should be introduced explicitly before the KL derivation to aid readers unfamiliar with the OPD lift.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we address the two major comments point-by-point, clarifying the theoretical derivation and the empirical support for the decoupling premise while remaining faithful to the manuscript content.
read point-by-point responses
-
Referee: [Abstract / §3 (theoretical derivation)] The central theoretical claim (closed-form per-step KL that unifies SDE/ODE via mean-matching) is load-bearing for the paper's novelty; the abstract provides no equations, so it is impossible to verify whether the result is non-circular with respect to quantities already present in the teacher models or standard diffusion training objectives.
Authors: The abstract is intentionally kept equation-free for accessibility, as is conventional. The complete derivation appears in §3: we lift the discrete OPD objective to continuous-state Markov processes by expressing the per-step KL between student and teacher transition kernels, which reduces exactly to a mean-matching term. This term is identical for both the SDE (with its stochastic component) and ODE (deterministic) cases because the KL depends only on the mean of the reverse process at each timestep. The construction uses only the teachers' standard sampling distributions and the student's own rollout trajectories; no additional teacher-specific quantities or standard diffusion losses are presupposed, so the result is not circular. The paper also supplies the formal variance comparison to PPO-style gradients. We can insert a single teaser equation into the abstract in revision if the editor prefers. revision: partial
-
Referee: [Experiments section (multi-task results)] The empirical claim of consistent superiority over multi-reward and cascade RL baselines rests on the decoupling premise (independent teachers distilled along student trajectories). No quantitative evidence is supplied in the provided description to confirm absence of cross-task interference or forgetting; this assumption directly supports the multi-task integration claim.
Authors: The experiments section reports that DiffusionOPD outperforms both multi-reward RL (known to suffer interference) and cascade RL (known to suffer forgetting) in training efficiency and final performance while reaching SOTA on every benchmark. These consistent gains across tasks constitute indirect empirical support for the decoupling premise, because interference or forgetting would have narrowed or reversed the observed margins. Direct per-task retention curves or explicit interference coefficients are not tabulated in the current version. We are prepared to add such quantitative diagnostics in a revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central theoretical step is the lift of OPD from discrete tokens to continuous-state Markov processes, yielding a claimed closed-form per-step KL objective via mean-matching that unifies SDE/ODE cases. The provided abstract and description contain no equations or self-citations that reduce this derivation to fitted inputs, prior self-authored results, or definitional tautologies. The decoupling premise (independent teachers distilled on student trajectories) is presented as an empirical design choice rather than a mathematical reduction. No load-bearing step matches any of the enumerated circularity patterns; the argument remains self-contained against external benchmarks and empirical validation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
DanceOPD: On-Policy Generative Field Distillation
DanceOPD routes samples across capability velocity fields in flow-matching models and trains via on-policy student-induced states to compose T2I, local editing, and global editing without mutual interference.
-
MaineCoon: Pursuing A Real-Time Audio-Visual Social World Model
MaineCoon is presented as the first 22B-parameter real-time streaming audio-visual autoregressive model optimized for social-interactive applications, using novel training techniques and an agentic inference framework.
-
Qwen-Image-Flash: Beyond Objective Design
Empirical analysis of data, guidance, and task mixture in few-step distillation of Qwen-Image-2.0 produces the Qwen-Image-Flash model with improved performance in unified generation and editing tasks.
Reference graph
Works this paper leans on
-
[1]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InInternational Conference on Learning Representations, volume 2024, pages 4965–4987, 2024
2024
-
[2]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[4]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[5]
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning.arXiv preprint arXiv:2104.08718, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
2017
-
[7]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[8]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde, 2025. URL https: //arxiv.org/abs/2507.21802
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. Advances in neural information processing systems, 38:40783–40818, 2026
2026
-
[11]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Learning few-step diffusion models by trajectory distribution matching
Yihong Luo, Tianyang Hu, Jiacheng Sun, Yujun Cai, and Jing Tang. Learning few-step diffusion models by trajectory distribution matching. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17719–17728, 2025
2025
-
[13]
Wan-Image: Pushing the Boundaries of Generative Visual Intelligence
Chaojie Mao, Chen-Wei Xie, Chongyang Zhong, Haoyou Deng, Jiaxing Zhao, Jie Xiao, Jinbo Xing, Jingfeng Zhang, Jingren Zhou, Jingyi Zhang, et al. Wan-image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14297–14306, June 2023. 11
2023
-
[15]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[16]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[17]
Photorealistic text-to-image diffusion models with deep language understanding.NeurIPS, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.NeurIPS, 2022
2022
-
[18]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InInternational Conference on Learning Representations, 2022
2022
-
[19]
Adversarial diffusion distillation, 2023
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation, 2023
2023
-
[20]
Laion-aesthetics
Christoph Schuhmann. Laion-aesthetics. https://laion.ai/blog/laion-aesthetics/, 2022
2022
-
[21]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=WNzy9bRDvG
2024
-
[24]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.arXiv preprint arXiv:2303.01469, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think
Bingda Tang, Yuhui Zhang, Xiaohan Wang, Jiayuan Mao, Ludwig Schmidt, and Serena Yeung- Levy. V-grpo: Online reinforcement learning for denoising generative models is easier than you think.arXiv preprint arXiv:2604.23380, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
On-policy distillation
Thinking Machines Lab. On-policy distillation. https://thinkingmachines.ai/blog/ on-policy-distillation/, 2026
2026
-
[27]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[28]
Jing Wang, Jiajun Liang, Jie Liu, Henglin Liu, Gongye Liu, Jun Zheng, Wanyuan Pang, Ao Ma, Zhenyu Xie, Xintao Wang, et al. Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping.arXiv preprint arXiv:2510.22319, 2025
-
[29]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[30]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Yiyang Wang, Xi Chen, Xiaogang Xu, Yu Liu, and Hengshuang Zhao. Gdro: Group-level reward post-training suitable for diffusion models.arXiv preprint arXiv:2601.02036, 2026
-
[32]
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. arXiv preprint arXiv:2305.16213, 2023. 12
-
[33]
Rewarddance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. Rewarddance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
-
[34]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023
2096
-
[35]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[36]
Yanwu Xu, Yang Zhao, Zhisheng Xiao, and Tingbo Hou. Ufogen: You forward once large scale text-to-image generation via diffusion gans.ArXiv, abs/2311.09257, 2023. URL https: //api.semanticscholar.org/CorpusID:265221033
-
[37]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation.arXiv preprint arXiv:2311.18828, 2023
-
[39]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. InNeurIPS, 2024
2024
-
[40]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Frédo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In CVPR, 2024
2024
-
[41]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
2025
-
[42]
DiffusionNFT: Online Diffusion Reinforcement with Forward Process
Kaiwen Zheng, Huayu Chen, Haotian Ye, Haoxiang Wang, Qinsheng Zhang, Kai Jiang, Hang Su, Stefano Ermon, Jun Zhu, and Ming-Yu Liu. Diffusionnft: Online diffusion reinforcement with forward process.arXiv preprint arXiv:2509.16117, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InInternational Conference on Machine Learning, 2024. 13 An old photograph of a 1920s airship shaped like a pig, floating over a wheat field. New York Skyline with ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.