Qwen-Image-Flash: Beyond Objective Design
Pith reviewed 2026-06-28 10:57 UTC · model grok-4.3
The pith
Effective few-step distillation requires principled organization of the training pipeline beyond the distillation objective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
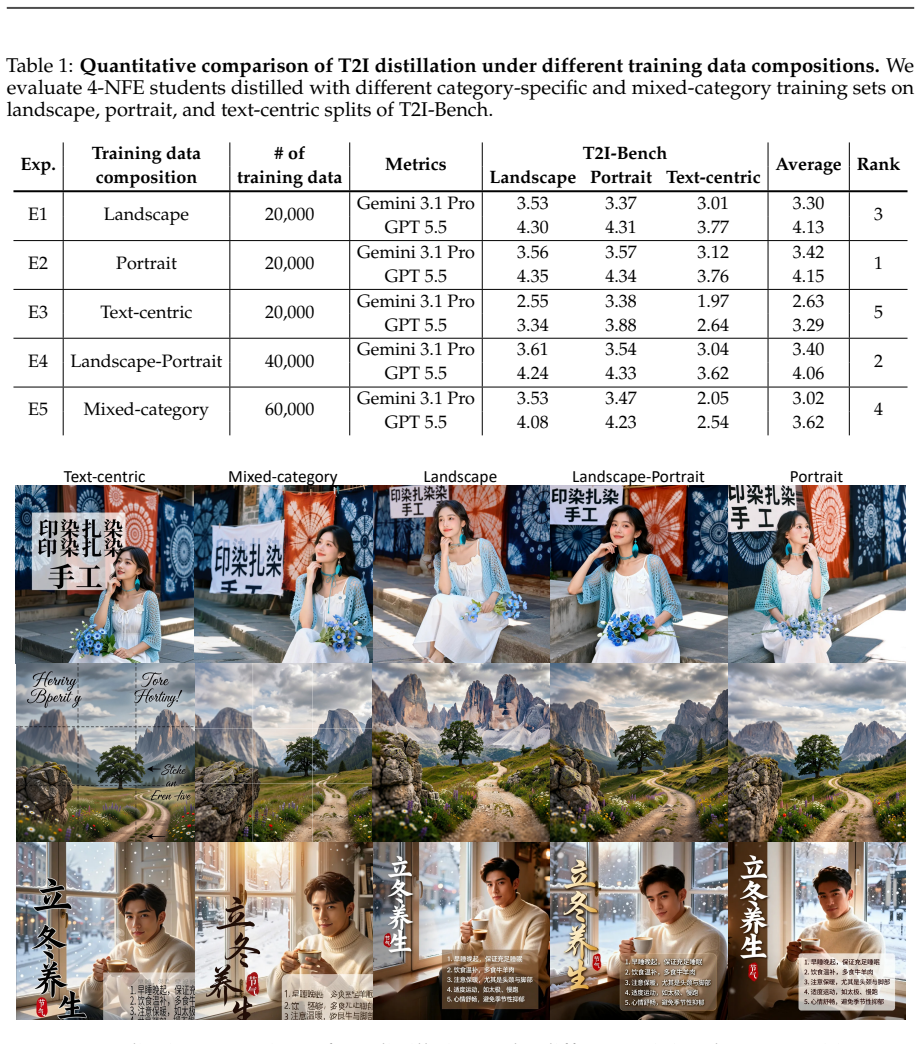
By systematically varying data composition, teacher guidance, and task mixture when distilling Qwen-Image-2.0 for unified text-to-image generation and instruction-guided image editing, the authors identify non-obvious behaviors that motivate Qwen-Image-Flash, establishing that effective few-step distillation requires not only carefully designed objectives but also principled organization of the broader training pipeline.
What carries the argument
Data composition, teacher guidance, and task mixture as the training-pipeline factors that shape student performance in few-step distillation.
If this is right
- Changes in data composition produce non-obvious effects on distilled model quality.
- Different strengths of teacher guidance lead to distinct student outcomes during distillation.
- The ratio of tasks in the mixture between generation and editing influences final performance.
- These pipeline adjustments enable the construction of Qwen-Image-Flash with improved few-step results.
Where Pith is reading between the lines
- The same pipeline factors could be tuned when distilling other text-to-image models to achieve similar gains.
- Automated search over data composition and task mixture might further improve distillation efficiency.
- This emphasis on training organization could extend to few-step distillation of video or 3D generative models.
Load-bearing premise
The non-obvious behaviors observed when varying data composition, teacher guidance, and task mixture on Qwen-Image-2.0 will hold for other base models and distillation settings.
What would settle it
Repeating the same variations of data composition, teacher guidance, and task mixture on a different base model and finding that they produce no performance change or the opposite effect from what was observed with Qwen-Image-2.0.
Figures



read the original abstract
Few-step distillation has become an effective strategy for accelerating advanced visual generative models, yet prior work has largely focused on distillation objectives. In this work, we revisit few-step distillation from a complementary perspective, focusing on the training recipe that critically shapes student performance. Using Qwen-Image-2.0 as a representative case, we systematically investigate three factors in unified text-to-image generation and instruction-guided image editing distillation: data composition, teacher guidance, and task mixture. Our empirical analysis reveals several non-obvious behaviors, which motivate the development of Qwen-Image-Flash. Overall, our results suggest that effective few-step distillation requires not only carefully designed objectives, but also principled organization of the broader training pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on few-step distillation for text-to-image generation and instruction-guided editing. Using Qwen-Image-2.0 as the base model, it systematically ablates data composition, teacher guidance, and task mixture, identifies non-obvious behaviors from these factors, develops the Qwen-Image-Flash recipe, and concludes that effective few-step distillation requires principled organization of the broader training pipeline in addition to objective design.
Significance. If the observed behaviors prove robust, the work usefully shifts focus from distillation objectives alone to pipeline-level choices, with credit for the unified treatment of generation and editing tasks. The single-model scope, however, limits the strength of the broader claim about pipeline organization.
major comments (2)
- [Abstract] Abstract: the claim of a 'systematic empirical investigation' revealing non-obvious behaviors is unsupported by any quantitative results, ablation tables, controls, or statistical details in the abstract, preventing verification of the central claim.
- [Empirical analysis] Empirical analysis (throughout): all ablations and the resulting Qwen-Image-Flash recipe are performed exclusively on Qwen-Image-2.0; the paper provides no experiments on other base models, which is load-bearing for the general recommendation that pipeline organization is required beyond objectives.
minor comments (1)
- The title is somewhat generic; a more specific subtitle referencing the three pipeline factors would better convey the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve clarity and accuracy where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'systematic empirical investigation' revealing non-obvious behaviors is unsupported by any quantitative results, ablation tables, controls, or statistical details in the abstract, preventing verification of the central claim.
Authors: We agree that the abstract should better substantiate the central claims with concrete evidence. In the revised manuscript, we have updated the abstract to include specific quantitative highlights from the ablations, such as the performance gains in unified generation and editing tasks from the optimized data composition, teacher guidance, and task mixture. revision: yes
-
Referee: [Empirical analysis] Empirical analysis (throughout): all ablations and the resulting Qwen-Image-Flash recipe are performed exclusively on Qwen-Image-2.0; the paper provides no experiments on other base models, which is load-bearing for the general recommendation that pipeline organization is required beyond objectives.
Authors: We acknowledge the single-model scope as a limitation that restricts the strength of broader claims. The work is framed as a detailed case study on Qwen-Image-2.0 as a representative model. We have revised the manuscript to moderate the general recommendation, emphasizing the findings as suggestive for this model and calling for future validation on additional base models. revision: partial
- Experiments on additional base models to support the general claim that pipeline organization is required beyond objectives.
Circularity Check
No circularity: empirical study with independent experimental support
full rationale
The paper contains no equations, derivations, or first-principles claims. It is framed entirely as an empirical investigation that reports ablation results on data composition, teacher guidance, and task mixture using Qwen-Image-2.0. The central recommendation about pipeline organization follows directly from those observed behaviors rather than reducing to any fitted parameter, self-definition, or self-citation chain. No load-bearing step equates its output to its input by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Optimizing few-step generation with adaptive matching distillation.arXiv preprint arXiv:2602.07345,
Lichen Bai, Zikai Zhou, Shitong Shao, Wenliang Zhong, Shuo Yang, Shuo Chen, Bojun Chen, and Zeke Xie. Optimizing few-step generation with adaptive matching distillation.arXiv preprint arXiv:2602.07345,
-
[2]
Flow-OPD: On-policy distillation for flow matching models.arXiv preprint arXiv:2605.08063,
Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, et al. Flow-OPD: On-policy distillation for flow matching models.arXiv preprint arXiv:2605.08063,
-
[3]
Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
-
[4]
Distribution matching distillation meets reinforcement learning.arXiv preprint arXiv:2511.13649,
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Changsheng Lu, Zhen Li, et al. Distribution matching distillation meets reinforcement learning.arXiv preprint arXiv:2511.13649,
-
[5]
Quanhao Li, Junqiu Yu, Kaixun Jiang, Yujie Wei, Zhen Xing, Pandeng Li, Ruihang Chu, Shiwei Zhang, Yu Liu, and Zuxuan Wu. DiffusionOPD: A unified perspective of on-policy distillation in diffusion models.arXiv preprint arXiv:2605.15055,
-
[6]
Dongyang Liu, Peng Gao, David Liu, Ruoyi Du, Zhen Li, Qilong Wu, Xin Jin, Sihan Cao, Shifeng Zhang, Hongsheng Li, et al. Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield.arXiv preprint arXiv:2511.22677,
-
[7]
ERNIE-Image technical report.arXiv preprint arXiv:2605.25347, 2026a
Jiaxiang Liu, Zhida Feng, Pengyu Zou, Zhenyu Qian, Tianrui Zhu, Jun Xia, Yuehu Dong, Yanzheng Lin, Honglin Xiong, et al. ERNIE-Image technical report.arXiv preprint arXiv:2605.25347, 2026a. Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online...
-
[8]
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378,
-
[9]
Yihong Luo, Tianyang Hu, Weijian Luo, and Jing Tang. TDM-R1: Reinforcing few-step diffusion models with non-differentiable reward.arXiv preprint arXiv:2603.07700,
-
[10]
Wan-Image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858,
Chaojie Mao, Chen-Wei Xie, Chongyang Zhong, Haoyou Deng, Jiaxing Zhao, Jie Xiao, Jinbo Xing, Jingfeng Zhang, Jingren Zhou, Jingyi Zhang, et al. Wan-Image: Pushing the boundaries of generative visual intelligence.arXiv preprint arXiv:2604.19858,
-
[11]
Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
-
[12]
Lin Song, Wenbo Li, Guoqing Ma, Wei Tang, Bo Wang, Yuan Zhang, Yijun Yang, Yicheng Xiao, Jianhui Liu, Yanbing Zhang, et al. JoyAI-Image: Awaking spatial intelligence in unified multimodal understanding and generation.arXiv preprint arXiv:2605.04128,
-
[13]
TIIF-Bench: How does your T2I model follow your instructions?arXiv preprint arXiv:2506.02161,
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. TIIF-Bench: How does your T2I model follow your instructions?arXiv preprint arXiv:2506.02161,
-
[14]
Tianhe Wu, Ruibin Li, Lei Zhang, and Kede Ma. Diversity-preserved distribution matching distillation for fast visual synthesis.arXiv preprint arXiv:2602.03139,
-
[15]
MiMo-V2-Flash technical report.arXiv preprint arXiv:2601.02780,
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. MiMo-V2-Flash technical report.arXiv preprint arXiv:2601.02780,
-
[16]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[17]
Qwen-Image-2.0 technical report.arXiv preprint arXiv:2605.10730,
Bing Zhao, Chenfei Wu, Deqing Li, Hao Meng, Jiahao Li, Jie Zhang, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kuan Cao, et al. Qwen-Image-2.0 technical report.arXiv preprint arXiv:2605.10730,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.