ELDOR: A Dataset and Benchmark for Illegal Gold Mining in the Amazon Rainforest
Pith reviewed 2026-05-19 15:30 UTC · model grok-4.3
The pith
ELDOR supplies a 2500-hectare UAV orthomosaic benchmark with pixel labels for illegal gold mining and rainforest ecology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
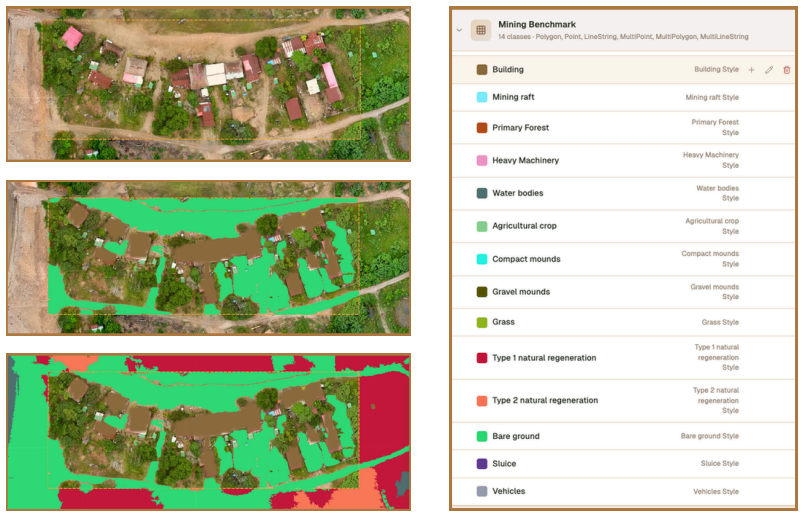
ELDOR is introduced as a unified UAV orthomosaic collection with pixel-level semantic annotations for both mining-related disturbances and ecological features across more than 2500 hectares, which then supports standardized evaluation of four distinct recognition tasks under a closed-set protocol.
What carries the argument
The ELDOR dataset of manually annotated UAV orthomosaics that supplies consistent pixel-level labels for mining activities and ecological structures.
If this is right
- Generic and remote-sensing segmentation models can be directly compared on rainforest mining scenes under identical conditions.
- Vision-language models can be evaluated for class-presence recognition using the same annotation source.
- Poor performance on rare small-scale structures and recovery classes motivates development of context-aware and multimodal methods.
- An interactive explorer built from the dataset lets domain experts inspect data and run model inference in one interface.
Where Pith is reading between the lines
- The dataset could be combined with periodic drone flights to create near-real-time alerts for new mining incursions.
- Similar UAV annotation pipelines might be applied to monitor other forms of resource extraction in biodiverse regions.
- Models improved on ELDOR could supply precise spatial data to support enforcement and restoration planning.
- Multi-scale fusion of ELDOR labels with coarser satellite time series would test whether small-feature detection scales up.
Load-bearing premise
The manual pixel-level annotations on the UAV orthomosaics provide accurate and consistent ground truth for both mining activities and ecological structures across the full 2500 hectares.
What would settle it
An independent ground-truth survey that re-labels a representative subset of the orthomosaics and finds substantial disagreement with the published annotations would invalidate the benchmark results.
Figures

































read the original abstract
Illegal gold mining in the Amazon rainforest causes deforestation, water contamination, and long-term ecosystem disruption, yet remains difficult to monitor at fine spatial scales. Satellite imagery supports large-scale observation, but often misses small mining-related structures and subtle land-cover transitions, especially under frequent cloud cover. We introduce ELDOR, a large-scale UAV benchmark for monitoring environmental and landscape disturbance from illegal gold mining in the rainforest. ELDOR contains manually annotated orthomosaic imagery covering over 2,500 hectares, with pixel-level semantic labels for both mining-related activities and surrounding ecological structures. With this unified annotation source, we establish four benchmark tasks: semantic segmentation, segmentation-derived recognition, direct multi-label classification, and class-presence recognition with vision-language models. Across these tasks, we compare generic and remote-sensing-specific segmentation models, vision foundation model-related segmentation methods, direct multi-label classification methods, and vision-language models under a controlled closed-set protocol. Results show that current methods still struggle with rare small-scale mining structures and fine-grained recovery classes, suggesting the need for context-aware and multimodal modeling. To support domain analysis and practical use, we further build an interactive explorer for domain experts that provides a unified interface for data exploration and model inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ELDOR, a UAV orthomosaic dataset covering over 2,500 hectares in the Amazon rainforest with manually annotated pixel-level semantic labels for illegal gold mining activities and surrounding ecological structures. It defines four benchmark tasks (semantic segmentation, segmentation-derived recognition, direct multi-label classification, and vision-language model class-presence recognition) and compares generic, remote-sensing-specific, and foundation-model-based approaches under a closed-set protocol, concluding that current methods struggle with rare small-scale mining structures and fine-grained recovery classes.
Significance. If the ground-truth annotations are reliable, ELDOR would fill an important gap by supplying high-resolution, multi-class UAV data for fine-scale disturbance detection where satellite imagery is limited by resolution and cloud cover. The multi-task formulation and interactive explorer are practical strengths that could support both algorithmic development and domain-expert use in conservation monitoring.
major comments (2)
- [Dataset construction / annotation subsection] Dataset construction / annotation subsection: the manuscript describes the labels only as 'manually annotated' with no reported inter-annotator agreement (Cohen's kappa, IoU between labelers), annotation protocol, number of annotators, or external validation against field data or higher-resolution imagery. This directly undermines the reliability of the benchmark results for rare classes, as label noise on minority mining structures or recovery classes could artifactually inflate the reported performance gaps.
- [Results and evaluation section] Results and evaluation section: the claim that models 'still struggle with rare small-scale mining structures and fine-grained recovery classes' is presented without accompanying quantitative metrics (e.g., per-class IoU, precision-recall curves, or confusion matrices) or ablation on how class imbalance was handled in the closed-set protocol, making it impossible to separate model limitations from potential annotation inconsistencies.
minor comments (2)
- [Abstract] Abstract: adding one or two concrete performance numbers (e.g., best mIoU or F1 for the rare classes) would give readers an immediate sense of the benchmark difficulty.
- [Figures and tables] Figure captions and table legends: ensure all class definitions and color mappings are explicitly listed so that readers can interpret the semantic segmentation visualizations without ambiguity.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us improve the clarity and rigor of our presentation regarding the ELDOR dataset's construction and evaluation. We address each major comment in detail below.
read point-by-point responses
-
Referee: [Dataset construction / annotation subsection] Dataset construction / annotation subsection: the manuscript describes the labels only as 'manually annotated' with no reported inter-annotator agreement (Cohen's kappa, IoU between labelers), annotation protocol, number of annotators, or external validation against field data or higher-resolution imagery. This directly undermines the reliability of the benchmark results for rare classes, as label noise on minority mining structures or recovery classes could artifactually inflate the reported performance gaps.
Authors: We agree that more details on the annotation process are essential for establishing trust in the benchmark, especially for rare classes. In the revised manuscript, we have expanded the relevant subsection to describe the annotation protocol, the involvement of multiple annotators, and steps taken to maintain consistency. We also include a discussion of external validation using higher-resolution imagery. However, inter-annotator agreement metrics such as Cohen's kappa were not computed as part of the original annotation workflow. We acknowledge this as a limitation and have noted it in the paper, along with its potential impact on reported results for minority classes. revision: partial
-
Referee: [Results and evaluation section] Results and evaluation section: the claim that models 'still struggle with rare small-scale mining structures and fine-grained recovery classes' is presented without accompanying quantitative metrics (e.g., per-class IoU, precision-recall curves, or confusion matrices) or ablation on how class imbalance was handled in the closed-set protocol, making it impossible to separate model limitations from potential annotation inconsistencies.
Authors: We concur that the original results section lacked sufficient quantitative detail to fully support the claims about model struggles with rare classes. We have revised this section to incorporate per-class IoU metrics, precision-recall analysis for challenging classes, and confusion matrices. Furthermore, we have added an ablation study examining the effects of class imbalance handling within the closed-set protocol, using techniques such as class-weighted losses. These changes allow for a clearer separation of model performance issues from any potential annotation noise. revision: yes
- Inter-annotator agreement was not quantified during dataset annotation, preventing us from reporting specific metrics like Cohen's kappa or labeler IoU at this stage.
Circularity Check
No circularity: dataset introduction and benchmark with no derivations or self-referential predictions
full rationale
The paper introduces the ELDOR UAV dataset covering >2500 ha with manual pixel-level semantic annotations for mining and ecological classes, then defines four benchmark tasks (semantic segmentation, segmentation-derived recognition, multi-label classification, and VLM class-presence recognition) and reports model comparisons under a closed-set protocol. No equations, fitted parameters, predictions, or uniqueness theorems appear in the abstract or described structure. The central claim reduces to data release plus empirical benchmarking rather than any derivation chain that could collapse to its inputs by construction. Annotation reliability (e.g., inter-annotator agreement) is a validity issue outside the scope of circularity analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jorge Caballero Espejo, Max Messinger, Francisco Román-Dañobeytia, Cesar Ascorra, Luis E Fernandez, and Miles Silman. Deforestation and forest degradation due to gold mining in the peruvian amazon: A 34-year perspective.Remote sensing, 10(12):1903, 2018
work page 1903
-
[2]
Seda Camalan, Kangning Cui, Victor Paul Pauca, Sarra Alqahtani, Miles Silman, Raymond Chan, Robert Jame Plemmons, Evan Nylen Dethier, Luis E Fernandez, and David A Lutz. Change detection of amazonian alluvial gold mining using deep learning and sentinel-2 imagery.Remote Sensing, 14(7):1746, 2022
work page 2022
-
[3]
Mining drives extensive deforestation in the brazilian amazon.Nature communications, 8(1):1013, 2017
Laura J Sonter, Diego Herrera, Damian J Barrett, Gillian L Galford, Chris J Moran, and Britaldo S Soares-Filho. Mining drives extensive deforestation in the brazilian amazon.Nature communications, 8(1):1013, 2017
work page 2017
-
[4]
Abra Atwood, Shreya Ramesh, Jennifer Angel Amaya, Hinsby Cadillo-Quiroz, Daxs Coayla, Chan-Mao Chen, and A Joshua West. Landscape controls on water availability limit revegeta- tion after artisanal gold mining in the peruvian amazon.Communications Earth & Environment, 6(1):419, 2025
work page 2025
-
[5]
Evan N Dethier, Miles Silman, Jimena Díaz Leiva, Sarra Alqahtani, Luis E Fernandez, Paúl Pauca, Seda Çamalan, Peter Tomhave, Francis J Magilligan, Carl E Renshaw, et al. A global rise in alluvial mining increases sediment load in tropical rivers.Nature, 620(7975):787–793, 2023
work page 2023
-
[6]
Evan N Dethier, Miles R Silman, Luis E Fernandez, Jorge Caballero Espejo, Sarra Alqahtani, Paúl Pauca, and David A Lutz. Operation mercury: Impacts of national-level armed forces intervention and anticorruption strategy on artisanal gold mining and water quality in the peruvian amazon.Conservation Letters, 16(5):e12978, 2023
work page 2023
-
[7]
Juliana Siqueira-Gay, Jean Paul Metzger, Luis E Sánchez, and Laura J Sonter. Strategic planning to mitigate mining impacts on protected areas in the brazilian amazon.Nature Sustainability, 5(10):853–860, 2022
work page 2022
-
[8]
Ramzy Kahhat, Eduardo Parodi, Gustavo Larrea-Gallegos, Carlos Mesta, and Ian Vázquez- Rowe. Environmental impacts of the life cycle of alluvial gold mining in the peruvian amazon rainforest.Science of the Total Environment, 662:940–951, 2019
work page 2019
-
[9]
Evan N Dethier, Shannon L Sartain, and David A Lutz. Heightened levels and seasonal inversion of riverine suspended sediment in a tropical biodiversity hot spot due to artisanal gold mining.Proceedings of the National Academy of Sciences, 116(48):23936–23941, 2019
work page 2019
-
[10]
Imelda M Dossou Etui, Malgorzata Stylo, Kenneth Davis, David C Evers, Vera I Slaveykova, Caroline Wood, and Mark EH Burton. Artisanal and small-scale gold mining and biodiversity: a global literature review.Ecotoxicology, 33(4):484–504, 2024
work page 2024
-
[11]
Remote sensing of artisanal and small-scale mining: A review of scalable mapping approaches
Ilyas Nursamsi, Stuart R Phinn, Noam Levin, Matthew Scott Luskin, and Laura Jane Sonter. Remote sensing of artisanal and small-scale mining: A review of scalable mapping approaches. Science of the Total Environment, 951:175761, 2024. 10
work page 2024
-
[12]
Mensah Isaac Obour, Barrett Brian, and Cahalane Conor. Assessing change point detection methods to enable robust detection of early stage artisanal and small-scale mining (asm) in the tropics using sentinel-1 time series data.International Journal of Applied Earth Observation and Geoinformation, 139:104525, 2025
work page 2025
-
[13]
Kangning Cui, Seda Camalan, Ruoning Li, Victor Paul Pauca, Sarra Alqahtani, Robert Plemmons, Miles Silman, Evan Nylen Dethier, David Lutz, and Raymond Chan. Semi- supervised change detection of small water bodies using rgb and multispectral images in peruvian rainforests. In2022 12th Workshop on Hyperspectral Imaging and Signal Processing: Evolution in Re...
work page 2022
-
[14]
Classifying land use within 80,000 mining sites on a global scale.Scientific Data, 2026
Yu-Tong Cheng, Nguyen Tien Hoang, Lou Maupu, and Keiichiro Kanemoto. Classifying land use within 80,000 mining sites on a global scale.Scientific Data, 2026
work page 2026
-
[15]
Yangchen Zeng, Zhenyu Yu, Dongming Jiang, Wenbo Zhang, Yifan Hong, Zhanhua Hu, Jiao Luo, and Kangning Cui. Learning where to embed: Noise-aware positional embedding for query retrieval in small-object detection.arXiv preprint arXiv:2604.15065, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Renxiang Guan, Zihao Li, Teng Li, Xianju Li, Jinzhong Yang, and Weitao Chen. Classification of heterogeneous mining areas based on rescapsnet and gaofen-5 imagery.Remote Sensing, 14 (13):3216, 2022
work page 2022
-
[17]
Dhruba Pikha Shrestha, Asep Saepuloh, and Freek van der Meer. Land cover classification in the tropics, solving the problem of cloud covered areas using topographic parameters. International Journal of Applied Earth Observation and Geoinformation, 77:84–93, 2019
work page 2019
-
[18]
Clement Nyamekye, Benjamin Ghansah, Emmanuel Agyapong, Emmanuel Obuobie, Alfred Awuah, and Samuel Kwofie. Examining the performances of true color rgb bands from landsat-8, sentinel-2 and uav as stand-alone data for mapping artisanal and small-scale mining (asm).Remote Sensing Applications: Society and Environment, 24:100655, 2021
work page 2021
-
[19]
Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation
Junjue Wang, Zhuo Zheng, Xiaoyan Lu, Yanfei Zhong, et al. Loveda: A remote sensing land-cover dataset for domain adaptive semantic segmentation. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
work page 2021
-
[20]
Jackson Simionato, Gabriel Bertani, and Liliana Sayuri Osako. Identification of artisanal mining sites in the amazon rainforest using geographic object-based image analysis (geobia) and data mining techniques.Remote Sensing Applications: Society and Environment, 24: 100633, 2021
work page 2021
-
[21]
An update on global mining land use.Scientific data, 9(1):433, 2022
Victor Maus, Stefan Giljum, Dieison M Da Silva, Jakob Gutschlhofer, Robson P Da Rosa, Sebastian Luckeneder, Sidnei LB Gass, Mirko Lieber, and Ian McCallum. An update on global mining land use.Scientific data, 9(1):433, 2022
work page 2022
-
[22]
Alexandre Lacoste, Nils Lehmann, Pau Rodriguez, Evan Sherwin, Hannah Kerner, Björn Lütjens, Jeremy Irvin, David Dao, Hamed Alemohammad, Alexandre Drouin, et al. Geo- bench: Toward foundation models for earth monitoring.Advances in Neural Information Processing Systems, 36:51080–51093, 2023
work page 2023
-
[23]
Ezra MacDonald, Derek Jacoby, and Yvonne Coady. Minesegsat: An automated system to eval- uate mining disturbed area extents from sentinel-2 imagery.arXiv preprint arXiv:2311.01676, 2023
-
[24]
Liang Tang and Tim T Werner. Global mining footprint mapped from high-resolution satellite imagery.Communications Earth & Environment, 4(1):134, 2023
work page 2023
-
[25]
Minenetcd: A benchmark for global mining change detection on remote sensing imagery
Weikang Yu, Xiaokang Zhang, Richard Gloaguen, Xiao Xiang Zhu, and Pedram Ghamisi. Minenetcd: A benchmark for global mining change detection on remote sensing imagery. IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024
work page 2024
-
[26]
Milagros Becerra, Lucio Villa, Andréa Puzzi Nicolau, Kelsey E Herndon, Sidney Novoa, Vanesa Martín-Arias, Karen Dyson, Kaitlin Walker, Karis Tenneson, and David Saah. Creating near real-time alerts of illegal gold mining in the peruvian amazon using synthetic aperture radar.Environmental Research Communications, 6(12):125022, 2024. 11
work page 2024
-
[27]
Stella Ofori-Ampofo, Antony Zappacosta, Rıdvan Salih Kuzu, Peter Schauer, Martin Willberg, and Xiao Xiang Zhu. Smallminesds: A multi-modal dataset for mapping artisanal and small- scale gold mines.IEEE Geoscience and Remote Sensing Letters, 2025
work page 2025
-
[28]
Muhamad Risqi U Saputra, Irfan Dwiki Bhaswara, Bahrul Ilmi Nasution, Michelle Ang Li Ern, Nur Laily Romadhotul Husna, Tahjudil Witra, Vicky Feliren, John R Owen, Deanna Kemp, and Alex M Lechner. Multi-modal deep learning approaches to semantic segmentation of mining footprints with multispectral satellite imagery.Remote Sensing of Environment, 318: 114584, 2025
work page 2025
-
[29]
He Ren, Yanling Zhao, Wu Xiao, and Zhenqi Hu. A review of uav monitoring in mining areas: Current status and future perspectives.International journal of coal science & technology, 6 (3):320–333, 2019
work page 2019
-
[30]
Aerial drones for geophysical prospection in mining: A review.Drones, 9 (5):383, 2025
Dimitris Perikleous, Katerina Margariti, Pantelis Velanas, Cristina Saez Blazquez, and Diego Gonzalez-Aguilera. Aerial drones for geophysical prospection in mining: A review.Drones, 9 (5):383, 2025
work page 2025
-
[31]
Detection and geographic localization of natural objects in the wild: a case study on palms
Kangning Cui, Rongkun Zhu, Manqi Wang, Wei Tang, Gregory D Larsen, Victor P Pauca, Sarra Alqahtani, Fan Yang, David Segurado, David A Lutz, et al. Detection and geographic localization of natural objects in the wild: a case study on palms. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 9601–9609, 2025
work page 2025
-
[32]
Rongkun Zhu, Kangning Cui, Wei Tang, Rui-Feng Wang, Sarra Alqahtani, David Lutz, Fan Yang, Paul Fine, Jordan Karubian, Robert Plemmons, et al. From orthomosaics to raw uav imagery: Enhancing palm detection and crown-center localization.arXiv preprint arXiv:2509.12400, 2025
-
[33]
Sam L Polk, Kangning Cui, Aland HY Chan, David A Coomes, Robert J Plemmons, and James M Murphy. Unsupervised diffusion and volume maximization-based clustering of hyperspectral images.Remote Sensing, 15(4):1053, 2023
work page 2023
-
[34]
Kangning Cui, Ruoning Li, Sam L Polk, Yinyi Lin, Hongsheng Zhang, James M Murphy, Robert J Plemmons, and Raymond H Chan. Superpixel-based and spatially regularized diffusion learning for unsupervised hyperspectral image clustering.IEEE Transactions on Geoscience and Remote Sensing, 62:1–18, 2024
work page 2024
-
[35]
Rui-Feng Wang, Daniel Petti, Yue Chen, and Changying Li. Dinov3 visual representations for blueberry perception toward robotic harvesting.arXiv preprint arXiv:2603.02419, 2026
-
[36]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), pages 801–818, 2018
work page 2018
-
[37]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[38]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. Vmamba: Visual state space model.Advances in neural information processing systems, 37:103031–103063, 2024
work page 2024
-
[39]
Xianghao Jiao, Yaohua Liu, Jiaxin Gao, Xinyuan Chu, Xin Fan, and Risheng Liu. Pearl: Pre- processing enhanced adversarial robust learning of image deraining for semantic segmentation. InProceedings of the 31st ACM International Conference on Multimedia, pages 8185–8194, 2023
work page 2023
-
[40]
Libo Wang, Rui Li, Ce Zhang, Shenghui Fang, Chenxi Duan, Xiaoliang Meng, and Peter M Atkinson. Unetformer: A unet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery.ISPRS Journal of Photogrammetry and Remote Sensing, 190: 196–214, 2022. 12
work page 2022
-
[41]
Kangning Cui, Wei Tang, Rongkun Zhu, Manqi Wang, Gregory D Larsen, Victor P Pauca, Sarra Alqahtani, Fan Yang, David Segurado, Paul Fine, et al. Efficient localization and spatial distribution modeling of canopy palms using uav imagery.IEEE Transactions on Geoscience and Remote Sensing, 2025
work page 2025
-
[42]
Wei Zhang, Qin Huang, Mengting Ma, Yizhen Jiang, Yun Chen, Zhenhua Huang, Wangyu Wu, Kangning Cui, Rongrong Lian, Zhenkai Wu, et al. Center-guided classifier for semantic segmentation of remote sensing images.IEEE Transactions on Geoscience and Remote Sensing, 2026
work page 2026
-
[43]
Libo Wang, Dongxu Li, Sijun Dong, Xiaoliang Meng, Xiaokang Zhang, and Danfeng Hong. Pyramidmamba: Rethinking pyramid feature fusion with selective space state model for semantic segmentation of remote sensing imagery.International Journal of Applied Earth Observation and Geoinformation, 144:104884, 2025
work page 2025
-
[44]
General multi-label image classification with transformers
Jack Lanchantin, Tianlu Wang, Vicente Ordonez, and Yanjun Qi. General multi-label image classification with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16478–16488, 2021
work page 2021
-
[45]
Residual attention: A simple but effective method for multi-label recognition
Ke Zhu and Jianxin Wu. Residual attention: A simple but effective method for multi-label recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 184–193, 2021
work page 2021
-
[46]
Ml-decoder: Scalable and versatile classification head
Tal Ridnik, Gilad Sharir, Avi Ben-Cohen, Emanuel Ben-Baruch, and Asaf Noy. Ml-decoder: Scalable and versatile classification head. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 32–41, 2023
work page 2023
-
[47]
Yuansheng Hua, Lichao Mou, and Xiao Xiang Zhu. Relation network for multilabel aerial image classification.IEEE Transactions on Geoscience and Remote Sensing, 58(7):4558–4572, 2020
work page 2020
-
[48]
Jian Kang, Ruben Fernandez-Beltran, Danfeng Hong, Jocelyn Chanussot, and Antonio Plaza. Graph relation network: Modeling relations between scenes for multilabel remote-sensing image classification and retrieval.IEEE Transactions on Geoscience and Remote Sensing, 59 (5):4355–4369, 2020
work page 2020
-
[49]
Yongkun Liu, Kesong Ni, Yuhan Zhang, Lijian Zhou, and Kun Zhao. Semantic interleaving global channel attention for multilabel remote sensing image classification.International Journal of Remote Sensing, 45(2):393–419, 2024
work page 2024
-
[50]
Debashis Gupta, Aditi Golder, Rongkhun Zhu, Kangning Cui, Wei Tang, Fan Yang, Ovidiu Csillik, Sarra Alaqahtani, and V Paul Pauca. Mosaic: Multi-modal multi-label supervision- aware contrastive learning for remote sensing.arXiv preprint arXiv:2507.08683, 2025
-
[51]
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, and Jun Zhou. Remoteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024
work page 2024
-
[52]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large- scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–23, 2024
work page 2024
-
[53]
Geochat: Grounded large vision-language model for remote sensing
Kartik Kuckreja, Muhammad Sohail Danish, Muzammal Naseer, Abhijit Das, Salman Khan, and Fahad Shahbaz Khan. Geochat: Grounded large vision-language model for remote sensing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 27831–27840, 2024
work page 2024
-
[54]
Yakoub Bazi, Laila Bashmal, Mohamad Mahmoud Al Rahhal, Riccardo Ricci, and Farid Melgani. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery.Remote Sensing, 16(9):1477, 2024. 13
work page 2024
-
[55]
Vhm: Versatile and honest vision language model for remote sensing image analysis
Chao Pang, Xingxing Weng, Jiang Wu, Jiayu Li, Yi Liu, Jiaxing Sun, Weijia Li, Shuai Wang, Litong Feng, Gui-Song Xia, et al. Vhm: Versatile and honest vision language model for remote sensing image analysis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6381–6388, 2025
work page 2025
-
[56]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. InProceedings of the European conference on computer vision (ECCV), pages 418–434, 2018
work page 2018
-
[57]
Object-contextual representations for semantic segmentation
Yuhui Yuan, Xilin Chen, and Jingdong Wang. Object-contextual representations for semantic segmentation. InEuropean conference on computer vision, pages 173–190. Springer, 2020
work page 2020
-
[58]
Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation
Changqian Yu, Changxin Gao, Jingbo Wang, Gang Yu, Chunhua Shen, and Nong Sang. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. International journal of computer vision, 129(11):3051–3068, 2021
work page 2021
-
[59]
Rethinking bisenet for real-time semantic segmentation
Mingyuan Fan, Shenqi Lai, Junshi Huang, Xiaoming Wei, Zhenhua Chai, Junfeng Luo, and Xiaolin Wei. Rethinking bisenet for real-time semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9716–9725, 2021
work page 2021
-
[60]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022
work page 2022
-
[61]
Meng-Hao Guo, Cheng-Ze Lu, Qibin Hou, Zhengning Liu, Ming-Ming Cheng, and Shi-Min Hu. Segnext: Rethinking convolutional attention design for semantic segmentation.Advances in neural information processing systems, 35:1140–1156, 2022
work page 2022
-
[62]
Huihui Pan, Yuanduo Hong, Weichao Sun, and Yisong Jia. Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes.IEEE Transactions on Intelligent Transportation Systems, 24(3):3448–3460, 2022
work page 2022
-
[63]
Head-free lightweight semantic segmentation with linear transformer
Bo Dong, Pichao Wang, and Fan Wang. Head-free lightweight semantic segmentation with linear transformer. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 516–524, 2023
work page 2023
-
[64]
Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction
Han Cai, Junyan Li, Muyan Hu, Chuang Gan, and Song Han. Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 17302–17313, 2023
work page 2023
-
[65]
Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation
Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, and Li Zhang. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. InThe eleventh international conference on learning representations, 2023
work page 2023
-
[66]
Pidnet: A real-time semantic segmentation network inspired by pid controllers
Jiacong Xu, Zixiang Xiong, and Shankar P Bhattacharyya. Pidnet: A real-time semantic segmentation network inspired by pid controllers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19529–19539, 2023
work page 2023
-
[67]
Context-guided spatial feature reconstruction for efficient semantic segmentation
Zhenliang Ni, Xinghao Chen, Yingjie Zhai, Yehui Tang, and Yunhe Wang. Context-guided spatial feature reconstruction for efficient semantic segmentation. InEuropean conference on computer vision, pages 239–255. Springer, 2024
work page 2024
-
[68]
Pem: Prototype-based efficient maskformer for image segmentation
Niccolo Cavagnero, Gabriele Rosi, Claudia Cuttano, Francesca Pistilli, Marco Ciccone, Giuseppe Averta, and Fabio Cermelli. Pem: Prototype-based efficient maskformer for image segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15804–15813, 2024
work page 2024
-
[69]
Zhuo Zheng, Yanfei Zhong, Junjue Wang, and Ailong Ma. Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4096–4105, 2020. 14
work page 2020
-
[70]
Libo Wang, Rui Li, Dongzhi Wang, Chenxi Duan, Teng Wang, and Xiaoliang Meng. Trans- former meets convolution: A bilateral awareness network for semantic segmentation of very fine resolution urban scene images.Remote Sensing, 13(16):3065, 2021
work page 2021
-
[71]
Rui Li, Shunyi Zheng, Ce Zhang, Chenxi Duan, Libo Wang, and Peter M Atkinson. Abcnet: Attentive bilateral contextual network for efficient semantic segmentation of fine-resolution remotely sensed imagery.ISPRS journal of photogrammetry and remote sensing, 181:84–98, 2021
work page 2021
-
[72]
Multiattention network for semantic segmentation of fine-resolution remote sensing images
Rui Li, Shunyi Zheng, Ce Zhang, Chenxi Duan, Jianlin Su, Libo Wang, and Peter M Atkinson. Multiattention network for semantic segmentation of fine-resolution remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 60:1–13, 2021
work page 2021
-
[73]
A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images
Libo Wang, Rui Li, Chenxi Duan, Ce Zhang, Xiaoliang Meng, and Shenghui Fang. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters, 19:1–5, 2022
work page 2022
-
[74]
Rui Li, Libo Wang, Ce Zhang, Chenxi Duan, and Shunyi Zheng. A2-fpn for semantic segmentation of fine-resolution remotely sensed images.International journal of remote sensing, 43(3):1131–1155, 2022
work page 2022
-
[75]
Log-can: Local-global class-aware network for semantic segmentation of remote sensing images
Xiaowen Ma, Mengting Ma, Chenlu Hu, Zhiyuan Song, Ziyan Zhao, Tian Feng, and Wei Zhang. Log-can: Local-global class-aware network for semantic segmentation of remote sensing images. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[76]
Zhuo Zheng, Yanfei Zhong, Junjue Wang, Ailong Ma, and Liangpei Zhang. Farseg++: Foreground-aware relation network for geospatial object segmentation in high spatial resolution remote sensing imagery.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 (11):13715–13729, 2023
work page 2023
-
[77]
Sacanet: Scene-aware class attention network for semantic segmentation of remote sensing images
Xiaowen Ma, Rui Che, Tingfeng Hong, Mengting Ma, Ziyan Zhao, Tian Feng, and Wei Zhang. Sacanet: Scene-aware class attention network for semantic segmentation of remote sensing images. In2023 IEEE International Conference on Multimedia and Expo (ICME), pages 828–833. IEEE, 2023
work page 2023
-
[78]
Docnet: Dual-domain optimized class-aware network for remote sensing image segmentation
Xiaowen Ma, Rui Che, Xinyu Wang, Mengting Ma, Sensen Wu, Tian Feng, and Wei Zhang. Docnet: Dual-domain optimized class-aware network for remote sensing image segmentation. IEEE Geoscience and Remote Sensing Letters, 21:1–5, 2024
work page 2024
-
[79]
Juwei Mu, Shangbo Zhou, and Xingjie Sun. Ppmamba: Enhancing semantic segmentation in remote sensing imagery by ss2d.IEEE Geoscience and Remote Sensing Letters, 22:1–5, 2024
work page 2024
-
[80]
Xianping Ma, Xiaokang Zhang, and Man-On Pun. Rs 3 mamba: Visual state space model for remote sensing image semantic segmentation.IEEE Geoscience and Remote Sensing Letters, 21:1–5, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.