Learn2Splat: Extending the Horizon of Learned 3DGS Optimization
Pith reviewed 2026-05-20 18:50 UTC · model grok-4.3
The pith
A learned optimizer for 3D Gaussian Splatting avoids performance degradation over much longer optimization runs than it was trained on.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces a learned optimizer for 3DGS that prevents degradation over extended optimization horizons without auxiliary mechanisms. It achieves this via a meta-learning scheme that incorporates a checkpoint buffer and an optimizer rollout strategy, along with an architecture that encodes gradient scale information within its latent states. This results in improved early novel view synthesis quality, long-term stability, and zero-shot generalization to unseen reconstruction settings, supported by a new unified framework for optimizer training and evaluation in sparse and dense view scenarios.
What carries the argument
A meta-learning scheme using a checkpoint buffer, optimizer rollout strategy, and latent-state encoding of gradient scale information to enable stable long-horizon optimization.
If this is right
- Improved early novel view synthesis quality compared to standard optimizers.
- Maintained performance stability over optimization horizons exceeding the training length.
- Zero-shot generalization to different reconstruction settings without retraining.
- Availability of a unified framework for consistent evaluation of learned and conventional optimizers in sparse and dense view setups.
Where Pith is reading between the lines
- This method may allow practitioners to run optimizations longer to reach higher final quality without worrying about late-stage degradation.
- Similar checkpoint and rollout techniques could be adapted to learned optimizers in other domains like neural radiance fields.
- The unified evaluation framework might standardize how future learned optimizers are compared in 3D reconstruction tasks.
Load-bearing premise
The combination of a checkpoint buffer, optimizer rollout strategy, and latent-state encoding of gradient scale is sufficient to prevent performance degradation when the optimizer is unrolled for many more steps than it was trained on.
What would settle it
Observing significant performance degradation or lower final quality when applying the learned optimizer for substantially more iterations than its training horizon on held-out scenes would falsify the stability claim.
Figures



















read the original abstract
3D Gaussian Splatting (3DGS) optimization is most commonly performed using standard optimizers (Adam, SGD). While stable across diverse scenes, standard optimizers are general-purpose and not tailored to the structure of the problem. In particular, they produce independent parameter updates that do not capture the structural and spatial relationships within a scene, leading to inefficient optimization and slow convergence. Recent works introduced learned optimizers that predict correlated updates informed by inter-parameter and inter-Gaussian dependencies. However, these methods are trained for a fixed number of optimization iterations and rely on manually scheduled learning rates to avoid degradation. In this paper, we introduce a learned optimizer for 3DGS that avoids degradation over extended optimization horizons without auxiliary mechanisms. To enable this, we propose a meta-learning scheme that extends the optimization horizon via a checkpoint buffer and an optimizer rollout strategy, combined with an architecture that encodes gradient scale information in its latent states. Results show improved early novel view synthesis quality while remaining stable over long horizons, with zero-shot generalization to unseen reconstruction settings. To support our findings, we introduce the first unified framework for training and evaluating both learned and conventional optimizers across sparse and dense view settings. Code and models will be released publicly. Our project page is available at https://naamapearl.github.io/learn2splat .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Learn2Splat, a learned optimizer for 3D Gaussian Splatting (3DGS) that employs a meta-learning scheme consisting of a checkpoint buffer, an optimizer rollout strategy, and latent-state encoding of gradient scale information. This design is intended to extend the optimization horizon and avoid performance degradation without relying on manual learning-rate schedules or other auxiliary mechanisms. The paper reports improved early novel-view synthesis quality, long-horizon stability, and zero-shot generalization to unseen reconstruction settings, while also contributing a unified framework for training and evaluating both learned and conventional optimizers across sparse and dense view regimes.
Significance. If the central stability claim is substantiated, the work would be significant for the 3DGS community by reducing dependence on hand-tuned schedules and making learned optimizers more practical for extended training. The unified evaluation framework is a constructive addition that enables systematic comparisons. Public release of code and models would further increase utility.
major comments (2)
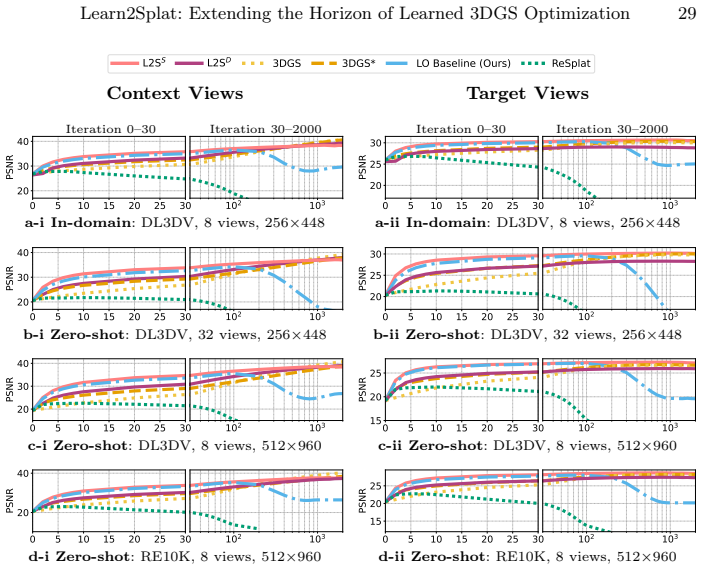
- [§5] §5 (Experiments): the manuscript states that the method remains stable over long horizons, yet provides no quantitative tables, ablation details on the individual contributions of the checkpoint buffer, rollout strategy, and latent encoding, or error-bar statistics. Without these, it is impossible to verify whether the combination prevents degradation or merely postpones it when unrolled far beyond the training horizon.
- [§4.2] §4.2 (Optimizer rollout strategy): the description of how the checkpoint buffer interacts with the latent-state encoding during extended unrolls does not include a concrete test (e.g., horizon length in multiples of the training horizon) that would confirm the scheme eliminates the instability previously observed in learned optimizers.
minor comments (2)
- The abstract would be strengthened by reporting specific quantitative gains (e.g., PSNR or SSIM deltas) rather than qualitative statements of improvement.
- [§4.1] Notation for the latent-state variables in §4.1 could be clarified with an explicit equation relating gradient scale to the hidden state.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and indicate the revisions we will make to strengthen the experimental validation and methodological description.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): the manuscript states that the method remains stable over long horizons, yet provides no quantitative tables, ablation details on the individual contributions of the checkpoint buffer, rollout strategy, and latent encoding, or error-bar statistics. Without these, it is impossible to verify whether the combination prevents degradation or merely postpones it when unrolled far beyond the training horizon.
Authors: We agree that the current presentation of results in §5 would benefit from more granular quantitative support. In the revised manuscript we will add tables reporting PSNR, SSIM and LPIPS at regular intervals up to 10× the training horizon, together with ablations that isolate the checkpoint buffer, rollout strategy and latent gradient-scale encoding. All metrics will be reported as mean ± standard deviation over at least three independent runs with different random seeds. These additions will allow readers to assess whether stability is maintained rather than merely delayed. revision: yes
-
Referee: [§4.2] §4.2 (Optimizer rollout strategy): the description of how the checkpoint buffer interacts with the latent-state encoding during extended unrolls does not include a concrete test (e.g., horizon length in multiples of the training horizon) that would confirm the scheme eliminates the instability previously observed in learned optimizers.
Authors: We accept that an explicit empirical demonstration of the interaction during extended unrolls would improve clarity. We will expand §4.2 with a new experiment that unrolls the optimizer for horizons that are exact multiples of the training horizon (2×, 5× and 10×). The experiment will track performance degradation while ablating the checkpoint buffer and latent-state encoding, directly comparing against previously reported instability patterns in learned optimizers. The results and accompanying analysis will be included in the revised version. revision: yes
Circularity Check
No circularity in meta-learning scheme or optimizer design
full rationale
The paper presents an empirical ML method: a neural network learned optimizer trained via meta-learning with a checkpoint buffer, rollout strategy, and latent gradient-scale encoding. Claims of extended-horizon stability and improved early NVS quality rest on experimental results across sparse/dense views, not on any closed-form derivation, self-referential definition, or fitted parameter renamed as prediction. No equations or uniqueness theorems are invoked that reduce to the method's own inputs. The design choices are architectural and training-procedural; they do not create the self-definitional or fitted-input circularity patterns. The work is self-contained against external benchmarks (standard Adam/SGD baselines) and introduces a unified evaluation framework, confirming an independent empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Journal of Computer Vision (IJCV) (2016) 3, 12, 13, 21, 35, 40
Aanæs, H., Jensen, R.R., Vogiatzis, G., Tola, E., Dahl, A.B.: Large-scale data for multiple-view stereopsis. International Journal of Computer Vision (IJCV) (2016) 3, 12, 13, 21, 35, 40
work page 2016
- [2]
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) (2016) 2, 4
Andrychowicz, M., Denil, M., Gomez, S., Hoffman, M.W., Pfau, D., Schaul, T., Shillingford, B., De Freitas, N.: Learning to learn by gradient descent by gradient descent. Advances in Neural Information Processing Systems (NeurIPS) (2016) 2, 4
work page 2016
-
[4]
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2022) 3, 12, 13, 21, 35, 40
work page 2022
- [5]
-
[6]
In: Optimality in Biological and Artificial Networks (1992) 4
Bengio, S., Bengio, Y., Cloutier, J., Gecsei, J.: On the optimization of a synaptic learning rule. In: Optimality in Biological and Artificial Networks (1992) 4
work page 1992
-
[7]
Bengio, Y., Bengio, S., Cloutier, J.: Learning a synaptic learning rule. Citeseer (1990) 4
work page 1990
-
[8]
IEEE/CAA Journal of Automatica Sinica (2021) 11
Bertsekas, D.: Multiagent reinforcement learning: Rollout and policy iteration. IEEE/CAA Journal of Automatica Sinica (2021) 11
work page 2021
- [9]
- [10]
-
[11]
Journal of Machine Learning Research (JMLR) (2022) 4
Chen, T., Chen, X., Chen, W., Heaton, H., Liu, J., Wang, Z., Yin, W.: Learning to optimize: A primer and a benchmark. Journal of Machine Learning Research (JMLR) (2022) 4
work page 2022
-
[12]
Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views,
Chen, T., Xiang, W., Han, K., Lu, Y., Wu, D., Liu, G., Kompella, R.R.: Gifsplat: Generative prior-guided iterative feed-forward 3d gaussian splatting from sparse views. arXiv:2602.22571 (2026) 5 16 N. Pearl, S. Esposito et al
- [13]
- [14]
- [15]
-
[16]
RealLiFe: Real-Time Light Field Reconstruction via Hierarchical Sparse Gradient Descent
Deng, Y., Han, L., Lin, T., Li, L., Zhang, J., Fang, L.: Efflife: Efficient light field generation via hierarchical sparse gradient descent. arXiv:2307.03017 (2023) 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [17]
- [18]
- [19]
- [20]
-
[21]
The annals of Mathematical Statistics (1952) 2
Kiefer, J., Wolfowitz, J.: Stochastic estimation of the maximum of a regression function. The annals of Mathematical Statistics (1952) 2
work page 1952
- [22]
-
[23]
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Bengio, Y., LeCun, Y. (eds.) Proc. of the International Conf. on Learning Representations (ICLR) (2015) 19
work page 2015
-
[24]
arXiv preprint arXiv:2504.13204 , year=
Kotovenko, D., Grebenkova, O., Ommer, B.: Edgs: Eliminating densification for efficient convergence of 3dgs. arXiv:2504.13204 (2025) 4
-
[25]
Lan, L., Shao, T., Lu, Z., Zhang, Y., Jiang, C., Yang, Y.: 3dgs2: Near second-order converging 3d gaussian splatting. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers (2025) 4
work page 2025
-
[26]
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., et al.: Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (2024) 1, 11, 12, 13, 21, 22, 34, 35, 38, 39, 40
work page 2024
- [27]
-
[28]
Worldmirror: Universal 3d world reconstruction with any-prior prompting,
Liu,Y.,Min,Z.,Wang,Z.,Wu,J.,Wang,T.,Yuan,Y.,Luo,Y.,Guo,C.:Worldmir- ror: Universal 3d world reconstruction with any-prior prompting. arXiv:2510.10726 (2025) 2, 4, 34
-
[29]
Liu, Y.C., Höllein, L., Nießner, M., Dai, A.: Quicksplat: Fast 3d surface reconstruc- tion via learned gaussian initialization. In: Proc. of the IEEE International Conf. on Computer Vision (ICCV) (2025) 1, 3, 4, 5, 9, 14, 28 Learn2Splat: Extending the Horizon of Learned 3DGS Optimization 17
work page 2025
- [30]
- [31]
- [32]
-
[33]
Metz, L., Harrison, J., Freeman, C.D., Merchant, A., Beyer, L., Bradbury, J., Agrawal, N., Poole, B., Mordatch, I., Roberts, A., et al.: Velo: Training versatile learned optimizers by scaling up. arXiv:2211.09760 (2022) 4
-
[34]
Metz, L., Maheswaranathan, N., Freeman, C.D., Poole, B., Sohl-Dickstein, J.: Tasks, stability, architecture, and compute: Training more effective learned op- timizers, and using them to train themselves. arXiv:2009.11243 (2020) 4
- [35]
- [36]
- [37]
-
[38]
The annals of Math- ematical Statistics (1951) 2, 4
Robbins, H., Monro, S.: A stochastic approximation method. The annals of Math- ematical Statistics (1951) 2, 4
work page 1951
- [39]
-
[40]
In: Advances in Neural Information Processing Systems (NeurIPS) (2017) 28
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS) (2017) 28
work page 2017
-
[41]
Zpressor: Bottleneck-aware compression for scalable feed-forward 3dgs,
Wang, W., Chen, D.Y., Zhang, Z., Shi, D., Liu, A., Zhuang, B.: Zpressor: Bottleneck-aware compression for scalable feed-forward 3dgs. arXiv:2505.23734 (2025) 4
-
[42]
V olsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction,
Wang, W., Chen, Y., Zhang, Z., Liu, H., Wang, H., Feng, Z., Qin, W., Zhu, Z., Chen, D.Y., Zhuang, B.: Volsplat: Rethinking feed-forward 3d gaussian splatting with voxel-aligned prediction. arXiv:2509.19297 (2025) 4
- [43]
- [44]
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) (2022) 9
Wu, X., Lao, Y., Jiang, L., Liu, X., Zhao, H.: Point transformer v2: Grouped vector attention and partition-based pooling. Advances in Neural Information Processing Systems (NeurIPS) (2022) 9
work page 2022
- [46]
-
[47]
Resplat: Learning recurrent gaussian splatting,
Xu, H., Barath, D., Geiger, A., Pollefeys, M.: Resplat: Learning recurrent gaussian splatting. arXiv:2510.08575 (2025) 1, 2, 3, 4, 5, 8, 9, 11, 14, 20, 21, 23, 28, 30, 34, 36
- [48]
-
[49]
Journal of Machine Learning Research (JMLR) (2025) 11
Ye, V., Li, R., Kerr, J., Turkulainen, M., Yi, B., Pan, Z., Seiskari, O., Ye, J., Hu, J., Tancik, M., Kanazawa, A.: gsplat: An open-source library for gaussian splatting. Journal of Machine Learning Research (JMLR) (2025) 11
work page 2025
- [50]
- [51]
-
[52]
Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: learn- ing view synthesis using multiplane images. ACM Trans. on Graphics (2018) 3, 12, 13, 21, 34, 36, 39 Learn2Splat: Extending the Horizon of Learned 3DGS Optimization 19 Supplementary Material We provide additional technical details and results complementing the main paper....
work page 2018
-
[53]
(see Table 1). The learning rate for the Gaus- sian means is scaled based on the number of op- timization steps performed (log-linear interpola- tion). Adam’s betas hyper-parameters are kept at their default values (β1 = 0.9, β2 = 0.999). Unlike the standard setting, we always use a batch size of 8 views for rendering and loss computation. In the sparse s...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.