RecMem: Recurrence-based Memory Consolidation for Efficient and Effective Long-Running LLM Agents
Pith reviewed 2026-05-20 19:15 UTC · model grok-4.3
The pith
RecMem reduces the memory construction token cost of three SOTA memory systems by up to 87% while exceeding their accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RecMem stores incoming interactions in a subconscious memory layer and encodes them using lightweight embedding models for retrieval. LLMs are only invoked to extract episodic and semantic memory when sustained recurrence are observed for semantically similar interactions. Such recurrence-based consolidation works because these interactions correspond to a semantic cluster with rich information and thus are worth extraction and summarization. To improve accuracy, RecMem also incorporates a semantic refinement mechanism that recovers the fine-grained facts omitted by memory extraction.
What carries the argument
Recurrence-based consolidation that triggers LLM memory extraction only after sustained recurrence of semantically similar interactions detected via embeddings.
If this is right
- Memory construction token usage falls by up to 87 percent relative to three prior state-of-the-art systems.
- Task accuracy on agent benchmarks exceeds that of the compared memory systems.
- Long-running agents can sustain effective memory over extended sessions with substantially lower LLM token budgets.
- A post-extraction semantic refinement step restores fine-grained facts that summarization would otherwise omit.
Where Pith is reading between the lines
- The same recurrence filter could be applied to other recurring LLM operations such as planning updates or tool-use logging to cut costs elsewhere.
- Dynamic adjustment of the recurrence threshold per task domain might further optimize the cost-accuracy trade-off.
- Production agents running for days or weeks could maintain coherent memory with token budgets that scale sub-linearly with interaction volume.
Load-bearing premise
Sustained recurrence of semantically similar interactions corresponds to a semantic cluster with rich information and is therefore worth LLM-based extraction and summarization.
What would settle it
On the same long-running agent benchmarks used in the paper, if forcing memory extraction on every interaction produces higher task accuracy than RecMem at comparable or lower token cost, the efficiency claim would be falsified.
Figures















read the original abstract
Memory systems often organize user-agent interactions as retrievable external memory and are crucial for long-running agents by overcoming the limited context windows of LLMs. However, existing memory systems invoke LLMs to process every incoming interaction for memory extraction, and such an eager memory consolidation scheme leads to substantial token consumption. To tackle this problem, we propose RecMem by rethinking when memory consolidation should be conducted. RecMem stores incoming interactions in a subconscious memory layer and encode them using lightweight embedding models for retrieval. LLMs are only invoked to extract episodic and semantic memory when sustained recurrence are observed for semantically similar interactions. Such recurrence-based consolidation works because these interactions correspond to a semantic cluster with rich information and thus are worth extraction and summarization. To improve accuracy, RecMem also incorporates a semantic refinement mechanism that recovers the fine-grained facts omitted by memory extraction. Experiments show that RecMem reduces the memory construction token cost of three SOTA memory systems by up to 87% while exceeding their accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RecMem, a memory consolidation system for long-running LLM agents. Incoming interactions are stored in a subconscious layer and encoded with lightweight embeddings; LLMs are invoked for episodic/semantic memory extraction only upon detection of sustained recurrence among semantically similar interactions. A semantic refinement step is added to recover fine-grained facts omitted during extraction. The central claim is that this recurrence-triggered approach reduces memory-construction token cost by up to 87% relative to three SOTA baselines while exceeding their accuracy.
Significance. If the empirical claims are substantiated, RecMem would provide a practical mechanism for lowering the LLM-token overhead of agent memory systems, potentially enabling longer-running agents at reduced cost. The recurrence-based trigger represents a distinct design choice from eager consolidation and could inform subsequent work on efficient memory architectures.
major comments (1)
- [§3] §3 (method description): The premise that sustained recurrence of embedding-similar interactions corresponds to a semantic cluster containing extractable rich information is load-bearing for both the efficiency and accuracy claims, yet no direct measurement or ablation is reported. An experiment comparing information density (unique facts, entropy, or downstream utility) of recurrence-triggered clusters against random or low-recurrence sets would be required to confirm that the reported 87% token reduction does not trade off omitted facts that the refinement step cannot recover.
minor comments (1)
- The experimental section should specify the exact datasets, interaction lengths, statistical tests for accuracy differences, and full hyper-parameter settings for the three SOTA baselines to permit independent verification of the cost and accuracy results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comment below and have revised the manuscript to incorporate additional analysis as suggested.
read point-by-point responses
-
Referee: [§3] §3 (method description): The premise that sustained recurrence of embedding-similar interactions corresponds to a semantic cluster containing extractable rich information is load-bearing for both the efficiency and accuracy claims, yet no direct measurement or ablation is reported. An experiment comparing information density (unique facts, entropy, or downstream utility) of recurrence-triggered clusters against random or low-recurrence sets would be required to confirm that the reported 87% token reduction does not trade off omitted facts that the refinement step cannot recover.
Authors: We agree that a direct ablation measuring information density would strengthen the justification for the recurrence trigger. The original manuscript motivates the approach by noting that sustained recurrence signals semantically coherent clusters worth consolidating, with end-to-end results showing both large token savings and higher accuracy than eager baselines. This outcome provides indirect evidence that non-recurrent interactions contribute less unique value. To directly address the concern, we have added a new analysis (revised §4.3 and new Table 3) that extracts and counts unique facts from recurrence-triggered clusters versus size-matched random and low-recurrence sets. The recurrence clusters yield 2.1–2.4× higher unique-fact density on average across the three evaluation domains, with the semantic refinement step recovering the remaining details. These results confirm that the 87% token reduction does not sacrifice recoverable information. revision: yes
Circularity Check
No significant circularity; design choice is independent of results
full rationale
The paper presents RecMem as an engineering design: store interactions in a subconscious layer, use lightweight embeddings to detect sustained recurrence of similar interactions, and only then invoke LLMs for episodic/semantic extraction plus refinement. The statement that recurrence 'corresponds to a semantic cluster with rich information' is an explicit motivating assumption, not a derived quantity obtained by fitting or by re-using the target accuracy metric. No equations, fitted parameters, or self-citations are shown that would make any reported efficiency gain (the 87 % token reduction) equivalent to the input data or to a prior result by the same authors. The accuracy claim is supported by direct experimental comparison against three external SOTA baselines rather than by internal re-labeling or self-referential uniqueness theorems. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs have limited context windows that necessitate external memory systems for long-running agents.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLMs are only invoked to extract episodic and semantic memory when sustained recurrence are observed for semantically similar interactions. Such recurrence-based consolidation works because these interactions correspond to a semantic cluster with rich information
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Inspired by cognitive science... isolated experiences remain in transient or rapidly-encoded stores, and only repeated or recurring patterns drive consolidation into stable long-term memory
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Evaluating very long-term conversational memory of llm agents.Preprint, arXiv:2402.17753. James L. McClelland, Bruce L. McNaughton, and Ran- dall C. O’Reilly. 1995. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connec- tionist models of learning and memory.Psychologi- cal review,...
work page internal anchor Pith review Pith/arXiv arXiv 1995
-
[2]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A tempo- ral knowledge graph architecture for agent memory. Preprint, arXiv:2501.13956. Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
From isolated conversations to hierarchical schemas: Dynamic tree memory representation for llms.Preprint, arXiv:2410.14052. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Prepri...
-
[4]
A-Mem (Xu et al., 2025b): Inspired by the Zettelkasten method (Kadavy, 2021; Ahrens, 2017), it treats interactions as discrete "notes" in a network, where consolidation involves generating embeddings and establishing asso- ciative links between new and existing notes
work page 2021
-
[5]
TreeMem (Rezazadeh et al., 2025): Maintains a hierarchical summary tree. New information is not just appended but traverses down to spe- cific leaf nodes based on semantic relevance, forcing a recursive chain of summary updates from the leaf back up to the root to keep the hierarchy consistent
work page 2025
-
[6]
Zep (Rasmussen et al., 2025): Parses inter- actions into a "Temporal Knowledge Graph." It actively extracts entities and relationships from each turn, modeling them as nodes and edges while explicitly updating the temporal metadata of these connections
work page 2025
-
[7]
Mem0 (Graph Variant) (Chhikara et al., 2025): Extends atomic fact extraction by organizing data into a graph. It requires per-turn analysis to identify multi-hop relationships between entities, dynamically updating the graph struc- ture as the conversation evolves. Fact and Summary-based ConsolidationThese systems function as active distillers, where the ...
work page 2025
-
[8]
Mem0 (Chhikara et al., 2025): Runs a dedi- cated extraction pipeline after every user mes- sage. It prompts the LLM to identify atomic facts (e.g., entity-relation triplets), instructing it to add, update, or delete records in the vec- tor database to reflect the latest state
work page 2025
-
[9]
MemoryOS (Kang et al., 2025): Features a multi-tiered architecture (Short-, Mid-, and Long-term memories) to manage context flow, emphasizing a dedicated Profile Memory mod- ule that explicitly maintains evolving user per- sonas and agent guidelines
work page 2025
-
[10]
Mirix (Wang and Chen, 2025): Routes ev- ery interaction through a parallel extraction pipeline. Raw text is simultaneously pro- cessed by distinct modules to distill specific "Knowledge" facts and "Event" summaries, creating a synchronized update across multi- ple memory stores
work page 2025
-
[11]
MemGPT (Packer et al., 2024): Treats mem- ory management as an operating system pro- cess, employing self-directed function calls to actively summarize and compress ongoing interactions into a fixed-size "Core Memory" block, ensuring key persona and user details are preserved while offloading raw history. A.2 Retrieval Mechanisms While memory consolidatio...
work page 2024
-
[12]
and LongMemEval-S (Wu et al., 2025). D.1 LoCoMo LoCoMo (Long-Context Memory) is a benchmark designed to evaluate memory systems in casual, social settings. Unlike standard user-agent inter- actions, the source texts consist of multi-session human-to-human dialogues between two distinct speakers, simulating the natural evolution of a long- term relationshi...
work page 2025
-
[13]
Single-hop Retrieval:Questions requiring the retrieval of a specific fact mentioned in a single past session
-
[14]
Multi-hop Reasoning:Questions that require synthesizing information distributed across multiple distinct sessions to derive an answer
-
[15]
Temporal Reasoning:Questions testing the system’s ability to understand the sequence of events and relative time expressions
-
[16]
Open-domain Knowledge:Questions that require combining memory retrieval with ex- ternal world knowledge
-
[17]
We ex- clude this category as it lacks reliable ground- truth answers for automated evaluation
Adversarial (Excluded):Questions designed to trick the model with false premises. We ex- clude this category as it lacks reliable ground- truth answers for automated evaluation. D.2 LongMemEval-S LongMemEval-S is a subset of the LongMemEval benchmark, curated to evaluate memory systems in agentic, task-orientedinteractions with long con- text windows. Dat...
-
[18]
Single-session-user:Evaluates the retrieval of specific details explicitly mentioned by the userwithin the bounds of a single conversa- tion session
-
[19]
Single-session-assistant:Tests the system’s ability to recall information provided by the assistantitself within a single session, ensur- ing consistency in the agent’s own history
-
[20]
Single-session-preference:Assesses whether the model can effectively apply retrieved user information to generate personalized, context- aware responses
-
[21]
Multi-session:Requires the aggregation of disjoint pieces of information scattered across two or more sessions to derive a complete answer
-
[22]
Knowledge-update:Probes the system’s ca- pacity to track dynamic changes in the user’s life state and supersede outdated information with new updates
-
[23]
Temporal-reasoning:Demands chronologi- cal deduction by synthesizing both the session metadata (timestamps) and explicit time ex- pressions found in the text. E Experiment Details E.1 Baseline Configurations To ensure fair and reliable comparisons, we con- figure each baseline to faithfully reflect its original design choices, rather than enforcing a unif...
work page 2025
-
[24]
Identify topic threads - First, mentally group the messages into topic threads. - Messages belong to the same thread if they refer to the same ongoing goal, project, problem, or situation for the conversation participants, even if they are days or weeks apart. - Ignore or down-weight one-off fictional or hypothetical stories that do not affect the speaker...
-
[25]
Build temporal structure for each episode - For each thread that has enough information, order the relevant events chronologically. - Highlight how the situation develops over time: initial situation, updates, changes of plan, decisions, outcomes, and reflections. - Emphasize how the speakers' state (plans, preferences, beliefs, emotional reactions) evolv...
-
[26]
Handle time expressions correctly - The timestamp of a message is the time when the user said it. It is NOT always the time when the described event happened. - If a message uses relative time expressions such as "yesterday", "two days ago", "next week", rewrite them in your episode as explicit expressions relative to the timestamp. For example:- "the day...
work page 2025
-
[27]
the assistant told a story about X to illustrate Y
Focus on episodic narratives, not isolated facts - Your goal is to construct narrative episodes: what happened, how it evolved, and why it matters to the user. - Focus on the outer conversation between the two speakers (their goals, decisions, preferences, constraints, and what has been explained to them). - When a speaker tells a long story, gives an ext...
-
[28]
Style and output format - Write each episode as a short, well-formed paragraph (3 to 6 sentences) in clear, neutral language. - Keep episodes compact. Do not reproduce long fictional plots, full technical explanations, or long lists; refer to them briefly if needed. - Prefer merging related events into a single episode over splitting them into many small ...
-
[29]
USER-CENTRIC: Focus on the user's goals, preferences, constraints, decisions, actions, and recurring plans
-
[30]
TEMPORALLY GROUNDED: For events and changes, include an explicit date anchor when available
-
[31]
Fewer, higher-value facts are better than many low-value facts
COMPACT BUT USEFUL: Output less than 10 facts. Fewer, higher-value facts are better than many low-value facts. Each fact MUST belong to one of these types:
-
[32]
USER_EVENT - The user asked for something, attended something, started or stopped something, or made a concrete decision. - Include a date anchor from R if possible, e.g., "On 2023-05-22, the user ..."
work page 2023
-
[33]
USER_CONSTRAINT_OR_PREFERENCE - A relatively stable preference, constraint, or recurring plan (e.g., long-term goals, platform choice, budget range, time constraints, content or style preferences)
-
[34]
- State the new value and, if known, the old value or state, with a clear time anchor
TIME_ANCHORED_UPDATE - A change in behavior, preferences, tools, roles, budgets, relationships, etc. - State the new value and, if known, the old value or state, with a clear time anchor
-
[35]
ENTITY_RELATION (USER-RELEVANT) - A specific relationship between named entities that is relevant to the user (e.g., the user's roles, organizations, projects, courses, tools, locations, or other people they interact with). - Only keep such a fact if it is specific and likely to matter in future reasoning about the user. Do NOT output generic best-practic...
work page 2025
-
[36]
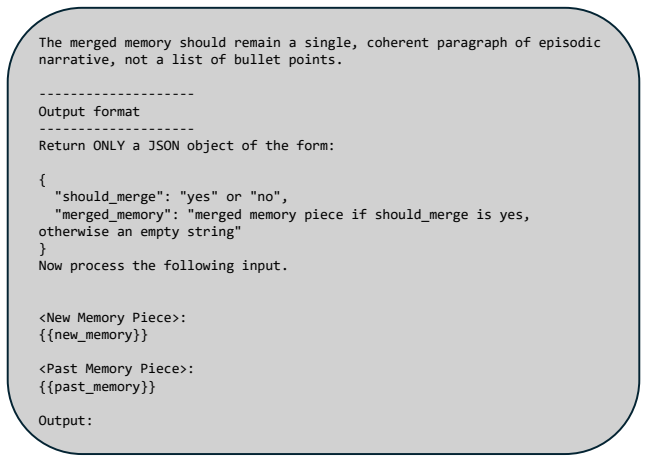
Decide whether the new memory piece and the past memory piece describe the same ongoing topic or episode for the conversation participants
-
[37]
If yes, merge them into ONE coherent episodic memory and return the merged result. Figure 12: Episodic Merging Role Description When to merge: Treat the new and past memory pieces as strongly related (should_merge = "yes") if MOST of the following hold: - They describe the same ongoing situation, goal, project, problem, or life event for the same main per...
work page 2024
-
[38]
Episodic Memories: refined summaries of related conversation turns about the same topic
-
[39]
Semantic Memories: concise, fact-like pieces extracted from conversations
-
[40]
Subconscious Memories: unprocessed conversation snippets between the two speakers. Context Rules:
-
[41]
Episodic and semantic memories may overlap in content (event summary vs. atomic facts). Avoid double-counting redundant evidence
-
[42]
Carefully analyze all three memory types and identify information that is actually useful for answering the question
-
[43]
Figure 15: Answering Role Description # INSTRUCTIONS
Memories within each type are sorted by relevance. Figure 15: Answering Role Description # INSTRUCTIONS
-
[44]
Carefully read all provided memories
-
[45]
Pay close attention to timestamps when time is relevant
-
[46]
If the question asks about a specific event or fact (who / where / when / what), look for direct, explicit evidence in the memories
-
[47]
If the question asks for advice, recommendations, or what kind of response the user would prefer, - first identify any user-specific preferences, habits, constraints, or past actions from the memories, - then base your suggestion primarily on these user-specific signals, - and only fall back to generic advice when no relevant user information exists
-
[48]
If memories contain contradictory information, prioritize the most recent memory
-
[49]
For time references (e.g., "last year", "two months ago"), convert them into concrete dates based on the memory timestamp. For example, if a memory from 4 May 2022 says "went to India last year", infer that the trip happened in 2021, and answer with "2021" or "the year before 2022", not just "last year"
work page 2022
-
[50]
In subconscious memories, the final timestamp marks the conversation time. Do not confuse the time of conversation with the time when an event actually happened if the text distinguishes them
-
[51]
Do not say "no information found" if there are related memories that can reasonably guide a personalized answer. Only abstain when there is truly no relevant evidence. # APPROACH (Think step by step internally)
-
[52]
Identify whether the question is (a) a factual query or (b) an advice/preference/recommendation query
-
[53]
Retrieve all memories that are clearly related to the question
-
[54]
Check timestamps and content to locate the most reliable and up-to-date information
-
[55]
For factual queries, pinpoint explicit mentions of dates, times, locations, entities, or events that directly answer the question
-
[56]
For advice / preference queries, determine what the user has already done, bought, liked, disliked, or constrained, and use these as anchors for a tailored answer
-
[57]
If temporal reasoning or simple calculation is needed, do it internally and convert the result into a concrete, explicit date or time span in the final answer
-
[58]
Formulate a precise, concise answer that directly addresses the question and is fully supported by the memories and reasonable inferences from them. Episodic Memories: {{ episodic_memories }} Subconscious Memories: {{ subconscious_memories }} Semantic Memories: {{ semantic_memories }} Question: {{ question }} Answer: Figure 16: Answering Instruction
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.