Seeking the Unfamiliar but Memorable: Conceptual Creativity as Meta-Learning
Pith reviewed 2026-05-20 19:47 UTC · model grok-4.3
The pith
Creativity is generating stimuli that feel unfamiliar at first but become learnable after a few exposures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
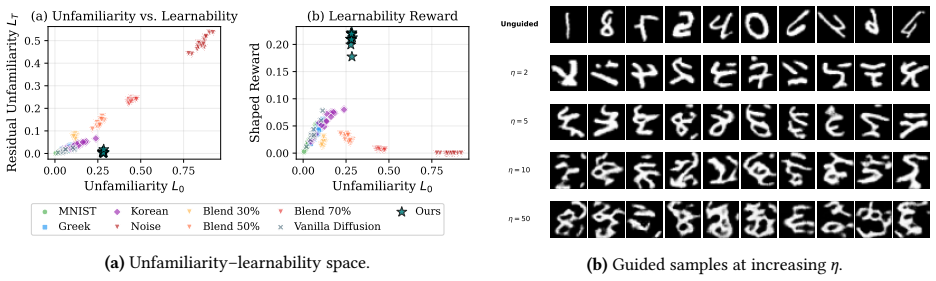
We propose that creativity is the production of stimuli that are unfamiliar to an adaptive observer at first sight, but quickly learnable from a few exposures. We formalize this as a Creator-Appraiser pair: a Creator generates a candidate, an Appraiser adapts to it for a few inner-loop learning steps, and the Appraiser's improvement becomes the reward the Creator optimizes through. We instantiate the framework with diffusion as the Creator, an autoencoder Appraiser on MNIST, and a CLIP Appraiser with a low-rank adapter for natural images. The diffusion model remains frozen with no additional language conditioning; the meta-learning gradient is enough to produce both stylistic variations and
What carries the argument
Creator-Appraiser pair in which the Appraiser's performance gain after a short inner-loop adaptation supplies the scalar reward that the Creator optimizes via meta-gradients.
If this is right
- Stylistic variations and concept compositions appear that the base diffusion model never produces under standard sampling.
- The diffusion generator requires neither parameter updates nor extra language conditioning to exhibit these new outputs.
- The same Creator-Appraiser loop applies across simple data such as MNIST and complex natural images via lightweight adapters.
- Creativity is operationalized as a meta-learning objective rather than as subjective novelty or diversity metrics.
Where Pith is reading between the lines
- The same adaptation-speed reward could be applied to other frozen generators such as autoregressive or flow-based models.
- Creativity scores derived from measured adaptation speed offer a quantitative alternative to human preference ratings.
- The framework suggests experiments that test whether human observers also find these meta-learned stimuli faster to internalize than typical model outputs.
Load-bearing premise
That quick improvement in the Appraiser after a few adaptation steps supplies a stable, usable reward signal the Creator can optimize without any further updates or conditioning on the generator itself.
What would settle it
Generate new samples under the meta-learning objective, then measure whether a fresh Appraiser instance adapts to them in measurably fewer steps than to ordinary diffusion samples drawn from the same prompt; if adaptation speeds are statistically identical, the claimed reward signal is absent.
Figures















read the original abstract
What does it mean to create a new concept, rather than retrieve a familiar one? Repeatedly sampling a generative model at the same prompt produces variations with similar styles and typical content. We propose that creativity is the production of stimuli that are unfamiliar to an adaptive observer at first sight, but quickly learnable from a few exposures. We formalize this as a Creator-Appraiser pair: a Creator generates a candidate, an Appraiser adapts to it for a few inner-loop learning steps, and the Appraiser's improvement becomes the reward the Creator optimizes through. We instantiate the framework with diffusion as the Creator, an autoencoder Appraiser on MNIST, and a CLIP Appraiser with a low-rank adapter for natural images. The diffusion model remains frozen with no additional language conditioning; the meta-learning gradient is enough to produce both stylistic variations and concept compositions that the base model does not generate on its own.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes that creativity consists in producing stimuli unfamiliar to an adaptive observer yet quickly learnable from few exposures. It formalizes this idea as a Creator-Appraiser meta-learning pair: a frozen diffusion Creator generates candidates while an Appraiser (autoencoder on MNIST or CLIP with low-rank adapter on natural images) performs a few inner-loop adaptation steps; the scalar improvement in the Appraiser supplies the reward that the Creator optimizes via meta-gradients. The authors claim that this procedure yields stylistic variations and concept compositions outside the base diffusion model's typical outputs without any additional language conditioning or parameter updates to the Creator.
Significance. If the empirical claims are borne out, the framework would supply a principled, parameter-light route to conceptual novelty in frozen generative models by treating adaptation speed itself as the objective. The approach could influence research on meta-learning for creativity, efficient exploration of latent spaces, and the design of reward signals that do not require external human labels or fine-tuning.
major comments (3)
- [Abstract and §3] Abstract and §3 (formalization of the reward): the scalar improvement in Appraiser loss/accuracy after a small number of inner-loop steps is defined directly as the Creator's reward. Because this quantity is constructed from the same adaptation process the Creator is trying to exploit, and because the diffusion model receives neither language-conditioning updates nor parameter changes, it is unclear whether the resulting meta-gradient reliably selects for conceptual unfamiliarity rather than low-level statistics (pixel histograms, CLIP feature norms, etc.). A variance analysis or comparison against a non-adaptive baseline reward is needed to establish that the signal is load-bearing for the central claim.
- [§4.1] §4.1 (MNIST instantiation): the manuscript asserts that the meta-learning gradient produces outputs the base model does not generate on its own. Without reported quantitative metrics (e.g., novelty scores, human preference rates, or distance from the base distribution), ablations against random or fixed Appraisers, or error analysis, it is impossible to determine whether the observed variations are attributable to the proposed mechanism or to incidental effects of the optimization procedure.
- [§4.2] §4.2 (CLIP + low-rank adapter Appraiser): the rapid adaptability of the low-rank adapter risks eroding selectivity; an adapter that improves on almost any input will yield a reward signal that is only weakly correlated with conceptual novelty. The paper should demonstrate, via controlled experiments, that the adapter's improvement remains informative for the specific notion of “unfamiliar but memorable” rather than collapsing to generic feature statistics.
minor comments (2)
- [Notation and figures] A diagram or pseudocode block illustrating the inner-loop Appraiser updates and the outer-loop meta-gradient flow would clarify the Creator-Appraiser interaction for readers.
- [Introduction] The abstract and early sections would benefit from explicit comparison to prior meta-learning-for-generation and creativity-in-AI literature to better situate the novelty of the reward construction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address each of the major comments below and have revised the manuscript accordingly to clarify the role of the meta-learning signal and to provide additional empirical support.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (formalization of the reward): the scalar improvement in Appraiser loss/accuracy after a small number of inner-loop steps is defined directly as the Creator's reward. Because this quantity is constructed from the same adaptation process the Creator is trying to exploit, and because the diffusion model receives neither language-conditioning updates nor parameter changes, it is unclear whether the resulting meta-gradient reliably selects for conceptual unfamiliarity rather than low-level statistics (pixel histograms, CLIP feature norms, etc.). A variance analysis or comparison against a non-adaptive baseline reward is needed to establish that the signal is load-bearing for the central claim.
Authors: We agree that establishing the specificity of the adaptive reward signal is crucial for supporting our central claim. In the revised manuscript, we have added a non-adaptive baseline where the reward is based on the initial Appraiser loss without any inner-loop adaptation steps. This baseline produces outputs closer to the base diffusion model's typical generations, whereas the adaptive reward leads to more novel compositions. We also include an analysis of the variance in the reward signal across sampled candidates, showing that it varies meaningfully with conceptual features rather than solely low-level statistics. These additions are in the updated §3 and experimental sections. revision: yes
-
Referee: [§4.1] §4.1 (MNIST instantiation): the manuscript asserts that the meta-learning gradient produces outputs the base model does not generate on its own. Without reported quantitative metrics (e.g., novelty scores, human preference rates, or distance from the base distribution), ablations against random or fixed Appraisers, or error analysis, it is impossible to determine whether the observed variations are attributable to the proposed mechanism or to incidental effects of the optimization procedure.
Authors: We acknowledge the need for quantitative validation in the MNIST experiments. The revised version includes novelty scores computed as the increase in reconstruction accuracy after adaptation, along with distances in latent space from the base model's typical outputs. We also report results from ablations using a fixed (non-adapting) Appraiser and a random Appraiser, both of which fail to yield the same level of conceptual variation. A small-scale human study on preference for novelty is added as well. These changes strengthen the evidence that the meta-learning mechanism is responsible. revision: yes
-
Referee: [§4.2] §4.2 (CLIP + low-rank adapter Appraiser): the rapid adaptability of the low-rank adapter risks eroding selectivity; an adapter that improves on almost any input will yield a reward signal that is only weakly correlated with conceptual novelty. The paper should demonstrate, via controlled experiments, that the adapter's improvement remains informative for the specific notion of “unfamiliar but memorable” rather than collapsing to generic feature statistics.
Authors: This is a valid concern regarding the selectivity of the low-rank adapter. To address it, we have performed additional controlled experiments in the revision: we compare the reward signal on held-out novel concepts versus on-distribution images and versus images with manipulated low-level features (e.g., altered histograms). The results show that the improvement is significantly higher for conceptually novel but learnable stimuli, and does not correlate strongly with generic statistics like feature norms. We have included these experiments and corresponding figures in §4.2. revision: yes
Circularity Check
Reward defined directly as Appraiser adaptation improvement implements the proposed definition of creativity by construction
specific steps
-
self definitional
[Abstract]
"We propose that creativity is the production of stimuli that are unfamiliar to an adaptive observer at first sight, but quickly learnable from a few exposures. We formalize this as a Creator-Appraiser pair: a Creator generates a candidate, an Appraiser adapts to it for a few inner-loop learning steps, and the Appraiser's improvement becomes the reward the Creator optimizes through."
The definition of creativity is explicitly tied to 'quickly learnable from a few exposures,' which is then operationalized as the scalar improvement after inner-loop steps; therefore the Creator's meta-optimization of that improvement is optimizing the defined creativity quantity by construction.
full rationale
The paper proposes a formalization of creativity and then defines the optimization objective to be exactly the quantity named in that formalization. While the overall framework is a novel modeling choice and the experiments may demonstrate interesting outputs, the central reward signal reduces to the input definition without an independent external benchmark. This matches the moderate circularity noted in the reader's take. No self-citations, uniqueness theorems, or other enumerated patterns appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rapid inner-loop adaptation improvement reliably indicates conceptual novelty and learnability.
invented entities (1)
-
Creator-Appraiser pair
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose that creativity is the production of stimuli that are unfamiliar to an adaptive observer at first sight, but quickly learnable from a few exposures. We formalize this as a Creator-Appraiser pair: ... the Appraiser's improvement becomes the reward the Creator optimizes through.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The diffusion model remains frozen with no additional language conditioning; the meta-learning gradient is enough to produce both stylistic variations and concept compositions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Creative Mind: Myths and Mechanisms , author=. 2004 , publisher=
work page 2004
-
[2]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Image Style Transfer Using Convolutional Neural Networks , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[3]
Generative Adversarial Networks
Generative Adversarial Nets , author=. Advances in Neural Information Processing Systems (NIPS) , year=. 1406.2661 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
A Style-Based Generator Architecture for Generative Adversarial Networks
A Style-Based Generator Architecture for Generative Adversarial Networks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 1812.04948 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2006.11239 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[6]
Jack Lu and Ryan Teehan and Mengye Ren , title =. Computer Vision -. 2024 , url =. doi:10.1007/978-3-031-73027-6\_23 , timestamp =
-
[7]
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
work page 2018
-
[8]
ACM Transactions on Graphics , volume=
Conceptlab: Creative concept generation using vlm-guided diffusion prior constraints , author=. ACM Transactions on Graphics , volume=. 2024 , publisher=
work page 2024
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Enhancing creative generation on stable diffusion-based models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2503.23538 , archivePrefix=
-
[10]
arXiv preprint arXiv:2505.03667 , year=
Distribution-Conditional Generation: From Class Distribution to Creative Generation , author=. arXiv preprint arXiv:2505.03667 , year=
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
One-shot learning of object categories , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2006 , publisher =
work page 2006
-
[12]
Proceedings of the Annual Meeting of the Cognitive Science Society (CogSci) , year =
One shot learning of simple visual concepts , author =. Proceedings of the Annual Meeting of the Cognitive Science Society (CogSci) , year =
-
[13]
Prototypical Networks for Few-shot Learning
Prototypical networks for few-shot learning , author =. Advances in Neural Information Processing Systems (NIPS) , year =. 1703.05175 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Language models are few-shot learners , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=. 2020 , eprint=
work page 2020
-
[15]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
Model-agnostic meta-learning for fast adaptation of deep networks , author=. International Conference on Machine Learning (ICML) , year=. 1703.03400 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2301.08243 , archivePrefix=
-
[17]
Proceedings of the 25th International Conference on Machine Learning (ICML) , pages=
Extracting and composing robust features with denoising autoencoders , author=. Proceedings of the 25th International Conference on Machine Learning (ICML) , pages=. 2008 , doi=
work page 2008
-
[18]
Learning internal representations by error propagation , author=. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations , editor=. 1986 , doi=
work page 1986
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2022 , eprint=
work page 2022
-
[20]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=. 2019 , eprint=
work page 2019
-
[21]
A fast learning algorithm for deep belief nets , author=. Neural Computation , volume=. 2006 , publisher=
work page 2006
-
[22]
Auto-Encoding Variational Bayes
Auto-encoding variational bayes , author=. arXiv preprint arXiv:1312.6114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Journal of Machine Learning Research (JMLR) , volume=
A neural probabilistic language model , author=. Journal of Machine Learning Research (JMLR) , volume=. 2003 , doi=
work page 2003
-
[24]
Can: Creative adversarial networks, generating" art" by learning about styles and deviating from style norms , author=. arXiv preprint arXiv:1706.07068 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
ACM Computing Surveys , volume=
Creativity and machine learning: A survey , author=. ACM Computing Surveys , volume=. 2024 , publisher=
work page 2024
-
[26]
arXiv preprint arXiv:2510.10715 , year=
VLM-Guided Adaptive Negative Prompting for Creative Generation , author=. arXiv preprint arXiv:2510.10715 , year=
- [27]
-
[28]
Problems of Information Transmission , volume=
Three approaches to the quantitative definition of information , author=. Problems of Information Transmission , volume=. 1965 , annote=
work page 1965
-
[29]
The Universal Turing Machine: A Half-Century Survey , editor=
Logical depth and physical complexity , author=. The Universal Turing Machine: A Half-Century Survey , editor=. 1988 , doi=
work page 1988
-
[30]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
An image is worth one word: Personalizing text-to-image generation using textual inversion , author=. International Conference on Learning Representations (ICLR) , year=. 2208.01618 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year=. 2304.07193 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
IEEE Transactions on Autonomous Mental Development , volume=
Formal theory of creativity, fun, and intrinsic motivation (1990--2010) , author=. IEEE Transactions on Autonomous Mental Development , volume=. 2010 , publisher=
work page 1990
-
[33]
Srivastava, Rupesh Kumar and Steunebrink, Bas R. and Schmidhuber, J. First experiments with. Neural Networks , volume=. 2013 , publisher=. doi:10.1016/j.neunet.2013.01.022 , eprint=
- [34]
-
[35]
Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning (ICML) , year=. 2103.00020 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and others , journal=
-
[37]
High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2112.10752 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=. 2022 , eprint=
work page 2022
-
[39]
Curiosity-driven Exploration by Self-supervised Prediction
Curiosity-Driven Exploration by Self-Supervised Prediction , author=. International Conference on Machine Learning (ICML) , year=. 1705.05363 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
arXiv preprint arXiv:2601.03220 , year=
From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence , author=. arXiv preprint arXiv:2601.03220 , year=
-
[41]
Modeling by shortest data description , author=. Automatica , volume=. 1978 , publisher=
work page 1978
-
[42]
arXiv preprint arXiv:2206.08549 , year=
Rarity score: A new metric to evaluate the uncommonness of synthesized images , author=. arXiv preprint arXiv:2206.08549 , year=
-
[43]
The Philosophy of Creativity: New Essays , editor=
An experiential account of creativity , author=. The Philosophy of Creativity: New Essays , editor=. 2014 , doi=
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.