EfficientTDMPC: Improved MPC Objectives for Sample-Efficient Continuous Control
Pith reviewed 2026-05-20 18:55 UTC · model grok-4.3
The pith
By averaging return estimates over model ensembles and rollout depths while penalizing uncertainty, EfficientTDMPC reaches leading sample efficiency on hard continuous control tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EfficientTDMPC improves the return estimation inside the model predictive controller by averaging the outputs of an ensemble of dynamics models over both the different models and different rollout depths, and by optionally subtracting an uncertainty term from the objective. Combined with updates that keep the replay buffer fresher and cut unnecessary computation, the algorithm can safely increase its update-to-data ratio and thereby learn more quickly from limited interaction data, reaching state-of-the-art sample efficiency on HumanoidBench-Hard and hard DeepMind Control tasks.
What carries the argument
Ensemble averaging of return estimates across multiple dynamics models and rollout depths, combined with an optional uncertainty penalty inside the planner objective.
If this is right
- Higher update-to-data ratios become usable without causing instability or overfitting.
- The planner selects actions on the basis of more reliable return estimates.
- Sample-efficiency gains appear across both hard and easy continuous-control benchmarks.
- Practical buffer and compute tweaks reduce the overhead of running model-based planning.
Where Pith is reading between the lines
- The same averaging and penalty ideas could be applied to other learned-model planners that currently rely on single-model rollouts.
- In physical robotics the uncertainty penalty might lower the chance of executing actions that exploit model errors.
- Scaling the ensemble size further could produce additional gains if the extra compute remains affordable.
Load-bearing premise
The ensemble averaging and uncertainty penalty genuinely reduce return estimation error rather than introducing compensating biases that only appear helpful on the tested benchmarks.
What would settle it
An ablation experiment on HumanoidBench-Hard in which removing either the ensemble averaging or the uncertainty penalty produces no measurable drop in sample efficiency would show that the claimed error reduction is not the operative mechanism.
Figures


















read the original abstract
We introduce EfficientTDMPC, a sample-efficient model-based reinforcement learning method for continuous control built on the TD-MPC family of algorithms. Central to this family is a planner that aims to find an action sequence that maximizes the estimated return. The return is estimated using a learned model and value networks, each of which can introduce error. EfficientTDMPC proposes to reduce this error in two ways. First, it introduces an ensemble of dynamics models and averages the return estimates across those models and across different rollout depths. Second, it adds the option to apply an uncertainty penalty to the planner objective, yielding a planner that avoids actions with uncertain return estimates. It then adds practical improvements which increase buffer data freshness and reduce compute. Lastly, we find that our contributions enable EfficientTDMPC to benefit more from a higher update-to-data (UTD) ratio, further improving sample efficiency. To the best of our knowledge, in the low data regime of each benchmark, EfficientTDMPC achieves state-of-the-art (SOTA) in terms of sample efficiency on HumanoidBench-Hard and DMC hard, while matching SOTA on DMC easy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EfficientTDMPC, an extension of the TD-MPC family for sample-efficient model-based RL in continuous control. It proposes averaging return estimates over an ensemble of dynamics models and multiple rollout depths, an optional uncertainty penalty in the planner objective to avoid uncertain actions, practical improvements for buffer data freshness and reduced compute, and the ability to leverage higher update-to-data (UTD) ratios. The authors claim these changes yield state-of-the-art sample efficiency in the low-data regime on HumanoidBench-Hard and DMC hard tasks while matching SOTA on DMC easy.
Significance. If the empirical results are robust, the work offers a practical route to lower return-estimation error in MPC planning without requiring new model architectures. The ensemble averaging and uncertainty penalty are straightforward to implement and could be adopted by other model-based methods. No machine-checked proofs or parameter-free derivations are presented, but the focus on higher UTD ratios and data freshness provides concrete, falsifiable improvements that address known bottlenecks in sample-efficient RL.
major comments (2)
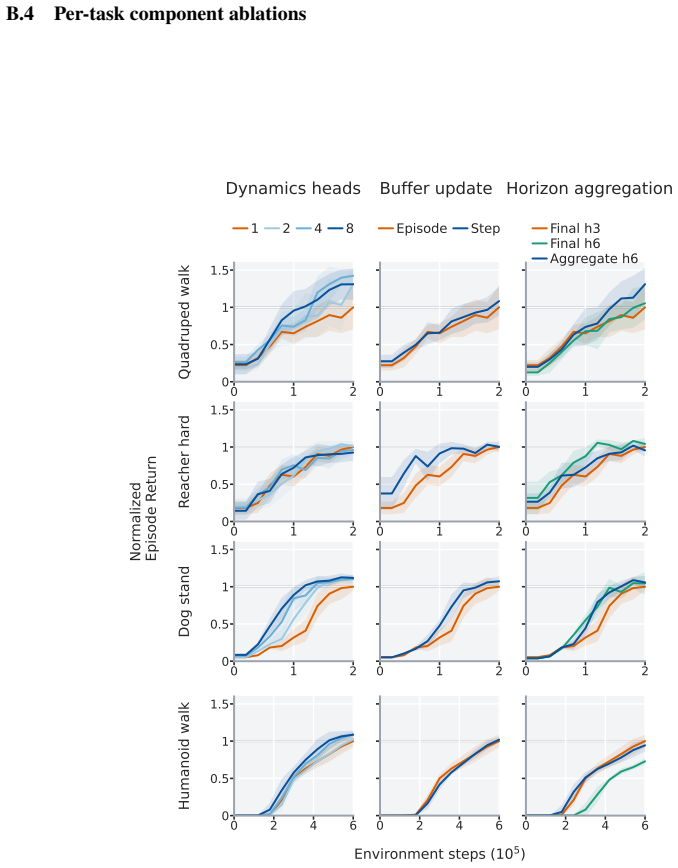
- [Abstract and §3] Abstract and §3: The central claim that ensemble averaging across models and rollout depths plus the uncertainty penalty produces lower-variance or lower-bias return estimates is load-bearing for the sample-efficiency results, yet the manuscript provides no direct quantitative evidence (e.g., MSE of estimated returns versus ground-truth rollouts or ablation curves isolating the averaging step). If model errors are correlated across depths, the averaging may not reduce error net of bias.
- [§5.2 and Table 3] §5.2 and Table 3: The reported SOTA claims on HumanoidBench-Hard and DMC hard in the low-data regime rest on the assumption that the uncertainty penalty weight and ensemble size do not require extensive per-benchmark tuning. The ablation results show performance sensitivity to these hyperparameters; without evidence that a single setting works across tasks, the headline sample-efficiency advantage is at risk of being undermined by hidden tuning costs.
minor comments (2)
- [Figure 2] Figure 2: Learning curves for the uncertainty-penalty ablation would benefit from shaded standard-error regions across all seeds to allow visual assessment of robustness.
- [§4.1] §4.1: The notation for the averaged return estimate (e.g., how depths are sampled and weighted) could be clarified with a short pseudocode block or explicit equation.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the practical contributions of EfficientTDMPC. We address each major comment below with clarifications and commit to revisions that strengthen the manuscript without overstating our results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The central claim that ensemble averaging across models and rollout depths plus the uncertainty penalty produces lower-variance or lower-bias return estimates is load-bearing for the sample-efficiency results, yet the manuscript provides no direct quantitative evidence (e.g., MSE of estimated returns versus ground-truth rollouts or ablation curves isolating the averaging step). If model errors are correlated across depths, the averaging may not reduce error net of bias.
Authors: We agree that direct quantitative evidence, such as MSE between estimated and ground-truth returns or isolated ablations of the averaging mechanism, would provide stronger support for the claim. The current manuscript offers indirect support via end-to-end sample-efficiency gains and ablations on ensemble size and the uncertainty penalty. To address the concern directly, including potential correlation of errors across rollout depths, we will add a new analysis section in the revision that reports return-estimation error metrics on a feasible subset of tasks using ground-truth rollouts. This addition will help verify net error reduction. revision: yes
-
Referee: [§5.2 and Table 3] §5.2 and Table 3: The reported SOTA claims on HumanoidBench-Hard and DMC hard in the low-data regime rest on the assumption that the uncertainty penalty weight and ensemble size do not require extensive per-benchmark tuning. The ablation results show performance sensitivity to these hyperparameters; without evidence that a single setting works across tasks, the headline sample-efficiency advantage is at risk of being undermined by hidden tuning costs.
Authors: We used a single fixed hyperparameter configuration—including the uncertainty penalty weight and ensemble size—across all tasks and benchmarks, with the exact values reported in the appendix. The ablations were performed to characterize sensitivity rather than to select per-task values. To clarify that the SOTA results do not rely on hidden per-benchmark tuning, we will revise the text in §5.2 and the appendix to explicitly state that hyperparameters were chosen once on representative tasks and transferred without further adjustment. This will better document the robustness of the reported gains. revision: yes
Circularity Check
No circularity: empirical algorithmic improvements validated on external benchmarks
full rationale
The paper describes an extension of the TD-MPC family with ensemble averaging of return estimates across models and rollout depths, an optional uncertainty penalty, buffer freshness improvements, and higher UTD ratios. These are presented as practical algorithmic changes whose value is assessed through benchmark experiments on HumanoidBench and DMC. No equations, predictions, or first-principles claims are shown that reduce the reported performance gains to quantities defined by the method's own fitted parameters or prior self-citations. The central results rest on external empirical evaluation rather than any self-referential derivation, satisfying the self-contained criterion against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- ensemble size
- uncertainty penalty weight
Reference graph
Works this paper leans on
- [1]
-
[2]
International Conference on Machine Learning (ICML) , year =
Temporal Difference Learning for Model Predictive Control , author =. International Conference on Machine Learning (ICML) , year =
-
[3]
Nicklas Hansen and Hao Su and Xiaolong Wang , booktitle =
-
[4]
TD-M(PC) ^2 : Improving Temporal Difference MPC Through Policy Constraint , author=. 2025 , eprint=
work page 2025
-
[5]
The Thirteenth International Conference on Learning Representations , year =
Bootstrapped Model Predictive Control , author =. The Thirteenth International Conference on Learning Representations , year =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Bootstrap Off-policy with World Model , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Ensemble Trajectory Sampling , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
When to Trust Your Model: Model-Based Policy Optimization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[9]
Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning
Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning , author =. arXiv preprint arXiv:1803.00101 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
International Conference on Learning Representations (ICLR) , year =
Dream to Control: Learning Behaviors by Latent Imagination , author =. International Conference on Learning Representations (ICLR) , year =
-
[12]
Mastering diverse control tasks through world models , author =. Nature , volume =. 2025 , month = apr, doi =
work page 2025
-
[13]
International Conference on Learning Representations (ICLR) , year =
High-Dimensional Continuous Control Using Generalized Advantage Estimation , author =. International Conference on Learning Representations (ICLR) , year =
-
[14]
Xinyue Chen and Che Wang and Zijian Zhou and Keith Ross , booktitle =. Randomized Ensembled Double
-
[15]
IEEE Transactions on Computational Intelligence and AI in Games , volume =
A Survey of Monte Carlo Tree Search Methods , author =. IEEE Transactions on Computational Intelligence and AI in Games , volume =
-
[16]
Masked Generative Priors Improve World Models Sequence Modelling Capabilities , author=. 2025 , eprint=
work page 2025
-
[17]
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm , author =. arXiv preprint arXiv:1712.01815 , year =
work page internal anchor Pith review Pith/arXiv arXiv
- [18]
-
[19]
Grady Williams and Paul Drews and Brian Goldfain and James M. Rehg and Evangelos A. Theodorou , journal =. Information Theoretic. 2018 , doi =
work page 2018
-
[20]
Soft Actor-Critic Algorithms and Applications
Soft Actor-Critic Algorithms and Applications , author =. arXiv preprint arXiv:1812.05905 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
International conference on machine learning , pages=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[22]
Wurman and Jaegul Choo , booktitle =
Hojoon Lee and Dongyoon Hwang and Donghu Kim and Hyunseung Kim and Jun Jet Tai and Kaushik Subramanian and Peter R. Wurman and Jaegul Choo , booktitle =
-
[23]
Hyperspherical Normalization for Scalable Deep Reinforcement Learning , author =. arXiv preprint arXiv:2502.15280 , year =
-
[24]
Yuval Tassa and Yotam Doron and Alistair Muldal and Tom Erez and Yazhe Li and Diego de Las Casas and David Budden and Abbas Abdolmaleki and Josh Merel and Andrew Lefrancq and Timothy Lillicrap and Martin Riedmiller , journal =
-
[25]
Learning to Predict by the Methods of Temporal Differences , author =. Machine Learning , volume =
-
[26]
Tianhe Yu and Garrett Thomas and Lantao Yu and Stefano Ermon and James Zou and Sergey Levine and Chelsea Finn and Tengyu Ma , booktitle =
-
[27]
International Conference on Learning Representations , year =
Epistemic Monte Carlo Tree Search , author =. International Conference on Learning Representations , year =
-
[28]
arXiv preprint arXiv:2406.01423 , year =
Value Improved Actor Critic Algorithms , author =. arXiv preprint arXiv:2406.01423 , year =
-
[29]
arXiv preprint arXiv:2511.14220 , year =
Twice Sequential Monte Carlo for Tree Search , author =. arXiv preprint arXiv:2511.14220 , year =
work page internal anchor Pith review arXiv
-
[30]
The Surprising Difficulty of Search in Model-Based Reinforcement Learning , author =. 2026 , eprint =
work page 2026
-
[31]
Dyna, an Integrated Architecture for Learning, Planning, and Reacting , author =. SIGART Bulletin , volume =
-
[32]
World Models , author =. arXiv preprint arXiv:1803.10122 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Robotics: Science and Systems (RSS) , year =
HumanoidBench: Simulated Humanoid Benchmark for Whole-Body Locomotion and Manipulation , author =. Robotics: Science and Systems (RSS) , year =
-
[34]
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners , author=. 2025 , eprint=
work page 2025
- [35]
-
[36]
Bridging Offline Reinforcement Learning and Imitation Learning: A Tale of Pessimism , author=. 2023 , eprint=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.