Motion Cues from Image-based Point Tracking for LiDAR Scene Flow Estimation
Pith reviewed 2026-05-19 21:05 UTC · model grok-4.3
The pith
Dense image trajectories from point tracking refine static-dynamic labels for LiDAR scene flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
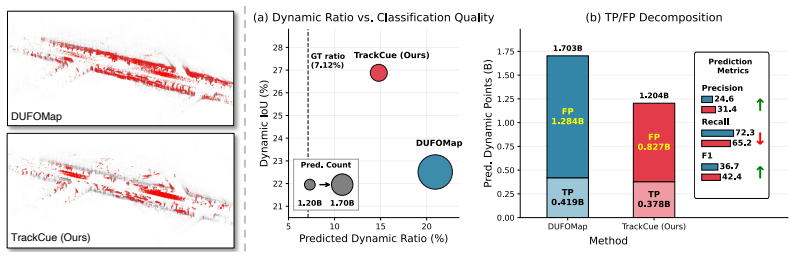
TrackCue repurposes point tracking to obtain dense image-space trajectories anchored to LiDAR points, providing motion cues beyond sparse geometric observations. It presents a visually consistent motion compensation strategy that compares the tracked trajectories with ego-induced rigid trajectories in the image plane, effectively isolating true object motion from ego-induced apparent motion. Visual motion cue lifting then associates ego-compensated image trajectories with LiDAR points for static-dynamic label refinement.
What carries the argument
Visual motion cue lifting that associates ego-compensated image trajectories with LiDAR points to refine static-dynamic labels.
Load-bearing premise
Dense image-space trajectories from point tracking can be accurately associated with and lifted to corresponding LiDAR points without introducing new errors from calibration, viewpoint differences, or tracking failures in occluded regions.
What would settle it
An ablation on standard benchmarks such as KITTI where TrackCue produces no measurable increase in dynamic-label precision or scene-flow end-point error compared with the geometric baseline.
Figures









read the original abstract
LiDAR scene flow estimation is essential for autonomous driving, as it provides 3D motion for each point. Self-supervised approaches use static-dynamic classification to mitigate the imbalance between static and dynamic points, deriving targeted supervision. However, existing methods rely on sparse geometric observations for this classification, making them vulnerable to data sparsity and occlusions. The resulting noisy labels provide incorrect motion guidance and degrade scene flow learning. To address this, we introduce TrackCue, a tracking-guided framework for improving dynamic object representation in LiDAR scene flow estimation. In particular, TrackCue repurposes point tracking to obtain dense image-space trajectories anchored to LiDAR points, providing motion cues beyond sparse geometric observations. Furthermore, we present a visually consistent motion compensation strategy that compares the tracked trajectories with ego-induced rigid trajectories in the image plane, effectively isolating true object motion from ego-induced apparent motion. To transfer these isolated motion cues back to the LiDAR domain, we perform visual motion cue lifting, which associates ego-compensated image trajectories with LiDAR points for static-dynamic label refinement. As a result, TrackCue produces more accurate static-dynamic classification and provides more reliable supervision for scene flow learning. Experimental results show that TrackCue significantly improves the precision and F1 score of dynamic labels, leading to performance gains in self-supervised scene flow estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TrackCue, a framework for self-supervised LiDAR scene flow estimation that leverages dense image-space trajectories from point tracking. It projects LiDAR points into the image domain, applies ego-compensated tracking to isolate true object motion from ego-induced apparent motion, and lifts the resulting refined static-dynamic labels back to the LiDAR points. The central claim is that this produces more accurate dynamic labels (higher precision and F1) than sparse geometric methods, yielding improved scene flow performance.
Significance. If the image-to-LiDAR lifting step can be validated as introducing negligible additional noise, the approach offers a practical way to obtain denser and more reliable supervision signals for scene flow, addressing sparsity and occlusion issues common in LiDAR data for autonomous driving. The cross-modal use of point tracking is a clear strength and could generalize to other 3D perception tasks.
major comments (2)
- [§3.3] §3.3 (Visual motion cue lifting): the description of associating ego-compensated image trajectories with LiDAR points provides no quantitative bound or ablation on projection/association errors arising from calibration drift, parallax between sensors, or tracking failures on occluded dynamic objects. This is load-bearing for the claim of strictly more reliable labels than geometric baselines, as any systematic mismatch would directly degrade the static-dynamic classification precision reported in the experiments.
- [§4] §4 (Experiments): the reported gains in dynamic label precision and F1, and downstream scene flow metrics, are presented without baselines explicitly listed, ablation isolating the lifting component, error bars across runs, or analysis of how post-hoc threshold choices affect results. This prevents verification that the improvements are robust rather than sensitive to implementation details.
minor comments (2)
- [§3.1] Clarify the exact point-tracking backbone (e.g., which off-the-shelf method is used) and any fine-tuning performed, as this affects reproducibility.
- [Figure 3] Figure 3 or equivalent qualitative results: include side-by-side comparisons of labels before and after lifting on sequences with heavy occlusion to illustrate the claimed robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and outline the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Visual motion cue lifting): the description of associating ego-compensated image trajectories with LiDAR points provides no quantitative bound or ablation on projection/association errors arising from calibration drift, parallax between sensors, or tracking failures on occluded dynamic objects. This is load-bearing for the claim of strictly more reliable labels than geometric baselines, as any systematic mismatch would directly degrade the static-dynamic classification precision reported in the experiments.
Authors: We agree that the current description in §3.3 would be strengthened by quantitative analysis of potential error sources. The manuscript explains the association process but does not report explicit bounds or ablations on calibration drift, parallax, or tracking failures. In the revised version we will add a dedicated ablation that perturbs the camera-LiDAR extrinsics within realistic ranges, measures the resulting drop in dynamic-label precision and F1, and compares against the geometric baseline under the same perturbations. We will also report the fraction of tracked points that fall on occluded dynamic objects and show how the ego-compensated comparison reduces false positives relative to raw geometric methods. These additions will provide the requested bounds and directly support the reliability claim. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains in dynamic label precision and F1, and downstream scene flow metrics, are presented without baselines explicitly listed, ablation isolating the lifting component, error bars across runs, or analysis of how post-hoc threshold choices affect results. This prevents verification that the improvements are robust rather than sensitive to implementation details.
Authors: We concur that clearer experimental reporting is needed. While the manuscript states that TrackCue improves precision, F1, and scene-flow metrics, §4 does not enumerate all baselines, isolate the lifting step, or include variability measures. In the revision we will (1) list every baseline with its exact configuration, (2) add an ablation that disables only the visual-motion-cue-lifting module while keeping all other components fixed, (3) report mean and standard deviation over five independent runs with different random seeds, and (4) include a sensitivity plot showing precision/F1 as the static-dynamic threshold varies. These changes will demonstrate that the observed gains are robust and not artifacts of particular implementation choices. revision: yes
Circularity Check
No significant circularity; method introduces independent visual motion cue lifting
full rationale
The derivation chain relies on projecting LiDAR points to image space, applying point tracking to obtain dense trajectories, comparing against ego-induced rigid motion in the image plane to isolate object motion, and lifting refined static-dynamic labels back to LiDAR. This sequence is presented as a geometric procedure using external point trackers and calibration, without reducing to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations whose validity depends on the current paper. The abstract and described steps treat the motion compensation and lifting as independent operations that can be evaluated against ground-truth labels, keeping the central claim self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TrackCue repurposes point tracking to obtain dense image-space trajectories anchored to LiDAR points... visual motion cue lifting, which associates ego-compensated image trajectories with LiDAR points for static-dynamic label refinement.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present a visually consistent motion compensation strategy that compares the tracked trajectories with ego-induced rigid trajectories in the image plane
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Neural scene flow prior.Advances in Neural Information Processing Systems, 34:7838–7851, 2021
Xueqian Li, Jhony Kaesemodel Pontes, and Simon Lucey. Neural scene flow prior.Advances in Neural Information Processing Systems, 34:7838–7851, 2021
work page 2021
-
[2]
Xueqian Li, Jianqiao Zheng, Francesco Ferroni, Jhony Kaesemodel Pontes, and Simon Lucey. Fast neural scene flow. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9878–9890, 2023
work page 2023
-
[3]
Siyi Li, Qingwen Zhang, Ishan Khatri, Kyle Vedder, Deva Ramanan, and Neehar Peri. Uniflow: Towards zero-shot lidar scene flow for autonomous vehicles via cross-domain generalization, 2025
work page 2025
-
[4]
Deltaflow: An efficient multi-frame scene flow estimation method
Qingwen Zhang, Xiaomeng Zhu, Yushan Zhang, Yixi Cai, Olov Andersson, and Patric Jensfelt. Deltaflow: An efficient multi-frame scene flow estimation method. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[5]
Neural eulerian scene flow fields
Kyle Vedder, Neehar Peri, Ishan Khatri, Siyi Li, Eric Eaton, Mehmet Kemal Kocamaz, Yue Wang, Zhiding Yu, Deva Ramanan, and Joachim Pehserl. Neural eulerian scene flow fields. 2025
work page 2025
-
[6]
Floxels: Fast unsupervised voxel based scene flow estimation
DavidTHoffmann,SyedHaseebRaza,HanqiuJiang,DenisTananaev,SteffenKlingenhoefer,and Martin Meinke. Floxels: Fast unsupervised voxel based scene flow estimation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22328–22337, 2025
work page 2025
-
[7]
Qingwen Zhang, Ajinkya Khoche, Yi Yang, Li Ling, Sina Sharif Mansouri, Olov Andersson, and Patric Jensfelt. HiMo: High-speed objects motion compensation in point cloud.IEEE Transactions on Robotics, 41:5896–5911, 2025
work page 2025
-
[8]
SeFlow: A self- supervised scene flow method in autonomous driving
Qingwen Zhang, Yi Yang, Peizheng Li, Olov Andersson, and Patric Jensfelt. SeFlow: A self- supervised scene flow method in autonomous driving. InEuropean Conference on Computer Vision (ECCV), page 353–369. Springer, 2024
work page 2024
-
[9]
Daniel Duberg, Qingwen Zhang, Mingkai Jia, and Patric Jensfelt. Dufomap: Efficient dynamic awareness mapping.IEEE Robotics and Automation Letters, 9(6):5038–5045, 2024
work page 2024
-
[10]
Voteflow: Enforcing local rigidity in self-supervised scene flow
Yancong Lin, Shiming Wang, Liangliang Nan, Julian Kooij, and Holger Caesar. Voteflow: Enforcing local rigidity in self-supervised scene flow. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17155–17164, 2025
work page 2025
-
[11]
ZeroFlow: Fast Zero Label Scene Flow via Distillation
KyleVedder,NeeharPeri,NathanielChodosh,IshanKhatri,EricEaton,DineshJayaraman,Yang Liu Deva Ramanan, and James Hays. ZeroFlow: Fast Zero Label Scene Flow via Distillation. International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[12]
Cotracker3: Simpler and better point tracking by pseudo-labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker3: Simpler and better point tracking by pseudo-labelling real videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6013–6022, 2025. 10
work page 2025
-
[13]
Alltracker: Efficient dense point tracking at high resolution
AdamWHarley,YangYou,XinglongSun,YangZheng,NikhilRaghuraman,YunqiGu,Sheldon Liang, Wen-Hsuan Chu, Achal Dave, Suya You, et al. Alltracker: Efficient dense point tracking at high resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5253–5262, 2025
work page 2025
-
[14]
Tapnext: Trackingany point (tap) as next token prediction
Artem Zholus, Carl Doersch, Yi Yang, Skanda Koppula, Viorica Patraucean, Xu Owen He, IgnacioRocco,MehdiS.M.Sajjadi,SarathChandar,andRossGoroshin. Tapnext: Trackingany point (tap) as next token prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9693–9703, October 2025
work page 2025
-
[15]
PhilippJund,ChrisSweeney,NicholaAbdo,ZhifengChen,andJonathonShlens. Scalablescene flowfrompointcloudsintherealworld.IEEERoboticsandAutomationLetters,7(2):1589–1596, 2021
work page 2021
-
[16]
I can’t believe it’s not scene flow! InEuropean Conference on Computer Vision, pages 242–257
Ishan Khatri, Kyle Vedder, Neehar Peri, Deva Ramanan, and James Hays. I can’t believe it’s not scene flow! InEuropean Conference on Computer Vision, pages 242–257. Springer, 2024
work page 2024
-
[17]
Ssf: Sparse long-range scene flow for autonomous driving
Ajinkya Khoche, Qingwen Zhang, Laura Pereira Sánchez, Aron Asefaw, Sina Sharif Mansouri, and Patric Jensfelt. Ssf: Sparse long-range scene flow for autonomous driving. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2025
work page 2025
-
[18]
Jaeyeul Kim, Jungwan Woo, Ukcheol Shin, Jean Oh, and Sunghoon Im. Flow4d: Leveraging 4d voxel network for lidar scene flow estimation.IEEE Robotics and Automation Letters, 2025
work page 2025
-
[19]
TeFlow: Enabling multi-frame supervision for self-supervised feed-forward scene flow estimation
Qingwen Zhang, Chenhan Jiang, Xiaomeng Zhu, Yunqi Miao, Yushan Zhang, Olov Andersson, and Patric Jensfelt. TeFlow: Enabling multi-frame supervision for self-supervised feed-forward scene flow estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2026
work page 2026
-
[20]
ICP-Flow: Lidarsceneflowestimationwithicp
YancongLinandHolgerCaesar. ICP-Flow: Lidarsceneflowestimationwithicp. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15501–15511, June 2024
work page 2024
-
[21]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation
Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela L Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In2023 IEEE international conference on robotics and automation (ICRA), pages 2774–2781. IEEE, 2023
work page 2023
-
[22]
Bevdilation: Lidar-centric multi- modal fusion for 3d object detection
Guowen Zhang, Chenhang He, Liyi Chen, and Lei Zhang. Bevdilation: Lidar-centric multi- modal fusion for 3d object detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12448–12456, 2026
work page 2026
-
[23]
Unitr: A unified and efficient multi-modal transformer for bird’s-eye-view representation
Haiyang Wang, Hao Tang, Shaoshuai Shi, Aoxue Li, Zhenguo Li, Bernt Schiele, and Liwei Wang. Unitr: A unified and efficient multi-modal transformer for bird’s-eye-view representation. InProceedingsoftheIEEE/CVFinternationalconferenceoncomputervision,pages6792–6802, 2023
work page 2023
-
[24]
Detectingaslabeling: Rethinking lidar-camera fusion in 3d object detection
JunjieHuang,YunYe,ZhujinLiang,YiShan,andDalongDu. Detectingaslabeling: Rethinking lidar-camera fusion in 3d object detection. InEuropean Conference on Computer Vision, pages 439–455. Springer, 2024
work page 2024
-
[25]
Cmda: Cross-modal and domain adversarial adaptation for lidar-based3dobjectdetection
Gyusam Chang, Wonseok Roh, Sujin Jang, Dongwook Lee, Daehyun Ji, Gyeongrok Oh, Jinsun Park, Jinkyu Kim, and Sangpil Kim. Cmda: Cross-modal and domain adversarial adaptation for lidar-based3dobjectdetection. InProceedingsoftheAAAIConferenceonArtificialIntelligence, volume 38, pages 972–980, 2024
work page 2024
-
[26]
Learning modality-agnostic representation for semantic segmentation from any modalities
Xu Zheng, Yuanhuiyi Lyu, and Lin Wang. Learning modality-agnostic representation for semantic segmentation from any modalities. InEuropean Conference on Computer Vision, pages 146–165. Springer, 2024
work page 2024
-
[27]
Delivering arbitrary-modal semantic segmentation
Jiaming Zhang, Ruiping Liu, Hao Shi, Kailun Yang, Simon Reiß, Kunyu Peng, Haodong Fu, Kaiwei Wang, and Rainer Stiefelhagen. Delivering arbitrary-modal semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1136–1147, 2023. 11
work page 2023
-
[28]
Jingyi Pan, Zipeng Wang, and Lin Wang. Co-occ: Coupling explicit feature fusion with volume rendering regularization for multi-modal 3d semantic occupancy prediction.IEEE Robotics and Automation Letters, 9(6):5687–5694, 2024
work page 2024
-
[29]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception
Xiaofeng Wang, Zheng Zhu, Wenbo Xu, Yunpeng Zhang, Yi Wei, Xu Chi, Yun Ye, Dalong Du, Jiwen Lu, and Xingang Wang. Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17850–17859, 2023
work page 2023
-
[30]
Image-to-lidar self-supervised distillation for autonomous driving data
Corentin Sautier, Gilles Puy, Spyros Gidaris, Alexandre Boulch, Andrei Bursuc, and Renaud Marlet. Image-to-lidar self-supervised distillation for autonomous driving data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9891–9901, 2022
work page 2022
-
[31]
Xiang Xu, Lingdong Kong, Song Wang, Chuanwei Zhou, and Qingshan Liu. Beyond one shot, beyondoneperspective: Cross-viewandlong-horizondistillationforbetterlidarrepresentations. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 25506–25518, October 2025
work page 2025
-
[32]
Segment any point cloud sequences by distilling vision foundation models
Youquan Liu, Lingdong Kong, Jun Cen, Runnan Chen, Wenwei Zhang, Liang Pan, Kai Chen, and Ziwei Liu. Segment any point cloud sequences by distilling vision foundation models. Advances in Neural Information Processing Systems, 36:37193–37229, 2023
work page 2023
-
[33]
Camliflow: bidirectional camera-lidar fusion for joint optical flow and scene flow estimation
Haisong Liu, Tao Lu, Yihui Xu, Jia Liu, Wenjie Li, and Lijun Chen. Camliflow: bidirectional camera-lidar fusion for joint optical flow and scene flow estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5791–5801, 2022
work page 2022
-
[34]
Particle video revisited: Tracking through occlusions using point trajectories
Adam W Harley, Zhaoyuan Fang, and Katerina Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Computer Vision, pages 59–75. Springer, 2022
work page 2022
-
[35]
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Recasens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. Tap-vid: A benchmark for tracking any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022
work page 2022
-
[36]
TAPIR: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. TAPIR: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10061–10072, 2023
work page 2023
-
[37]
Mel Vecerik, Carl Doersch, Yi Yang, Todor Davchev, Yusuf Aytar, Guangyao Zhou, Raia Hadsell, Lourdes Agapito, and Jon Scholz. RoboTAP: Tracking arbitrary points for few-shot visual imitation.International Conference on Robotics and Automation, pages 5397–5403, 2024
work page 2024
-
[38]
BootsTAP: Bootstrapped training for tracking-any-point.Asian Conference on Computer Vision, 2024
Carl Doersch, Pauline Luc, Yi Yang, Dilara Gokay, Skanda Koppula, Ankush Gupta, Joseph Heyward, Ignacio Rocco, Ross Goroshin, João Carreira, and Andrew Zisserman. BootsTAP: Bootstrapped training for tracking-any-point.Asian Conference on Computer Vision, 2024
work page 2024
-
[39]
TAPVid-3D: A benchmark for tracking any point in 3D
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, João Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch. TAPVid-3D: A benchmark for tracking any point in 3D. Advances in Neural Information Processing Systems, 2024
work page 2024
-
[40]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Cotracker: It is better to track together. InEuropean conference on computer vision, pages 18–35. Springer, 2024
work page 2024
-
[41]
Local all-pair correspondence for point tracking
Seokju Cho, Jiahui Huang, Jisu Nam, Honggyu An, Seungryong Kim, and Joon-Young Lee. Local all-pair correspondence for point tracking. InEuropean conference on computer vision, pages 306–325. Springer, 2024
work page 2024
-
[42]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21686–21697, 2024. 12
work page 2024
-
[43]
Denseopticaltracking: Connectingthe dots
GuillaumeLeMoing,JeanPonce,andCordeliaSchmid. Denseopticaltracking: Connectingthe dots. InProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecognition, pages 19187–19197, 2024
work page 2024
-
[44]
NanHuang,WenzhaoZheng,ChenfengXu,KurtKeutzer,ShanghangZhang,AngjooKanazawa, andQianqianWang. Segmentanymotioninvideos. InProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition, pages 3406–3416, 2025
work page 2025
-
[45]
Segment anything meets point tracking
Frano Rajič, Lei Ke, Yu-Wing Tai, Chi-Keung Tang, Martin Danelljan, and Fisher Yu. Segment anything meets point tracking. InProceedings of the Winter Conference on Applications of Computer Vision, pages 9284–9293, 2025
work page 2025
-
[46]
Argoverse 2: Next generation datasets for self-driving perception and forecasting
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InProceedings of the Neural Information Processing Systems Track on D...
work page 2021
-
[47]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020
work page 2020
-
[48]
nuscenes: A multimodal datasetforautonomousdriving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal datasetforautonomousdriving. InProceedingsoftheIEEE/CVFconferenceoncomputervision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[49]
FelixFent,FabianKuttenreich,FlorianRuch,FarijaRizwin,StefanJuergens,LorenzLechermann, Christian Nissler, Andrea Perl, Ulrich Voll, Min Yan, et al. Man truckscenes: A multimodal dataset for autonomous trucking in diverse conditions.Advances in Neural Information Processing Systems, 37:62062–62082, 2024
work page 2024
-
[50]
Aevascenes: A dataset and benchmark for fmcw lidar perception, 2025
Gautham Narayan Narasimhan, Heethesh Vhavle, Kumar Bhargav Vishvanatha, and James Reuther. Aevascenes: A dataset and benchmark for fmcw lidar perception, 2025
work page 2025
-
[51]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
work page 2023
-
[52]
Deflow: Decoder of scene flow network in autonomous driving
Qingwen Zhang, Yi Yang, Heng Fang, Ruoyu Geng, and Patric Jensfelt. Deflow: Decoder of scene flow network in autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 2105–2111. IEEE, 2024
work page 2024
-
[53]
Density-based clustering based on hierarchical density estimates
Ricardo JGB Campello, Davoud Moulavi, and Jörg Sander. Density-based clustering based on hierarchical density estimates. InPacific-Asia conference on knowledge discovery and data mining, pages 160–172. Springer, 2013. 13 Appendix A Experiment settings A.1 Dataset Details Inthissection,weprovideadditionaldetailsontheArgoverse2leaderboard[ 3]testset,whichco...
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.