High-dimensional Limit of SGD for Diagonal Linear Networks
Pith reviewed 2026-05-20 13:52 UTC · model grok-4.3
The pith
In high dimensions, SGD on diagonal linear networks is approximated by an SDE that decouples drift from noise and converges exponentially to zero risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
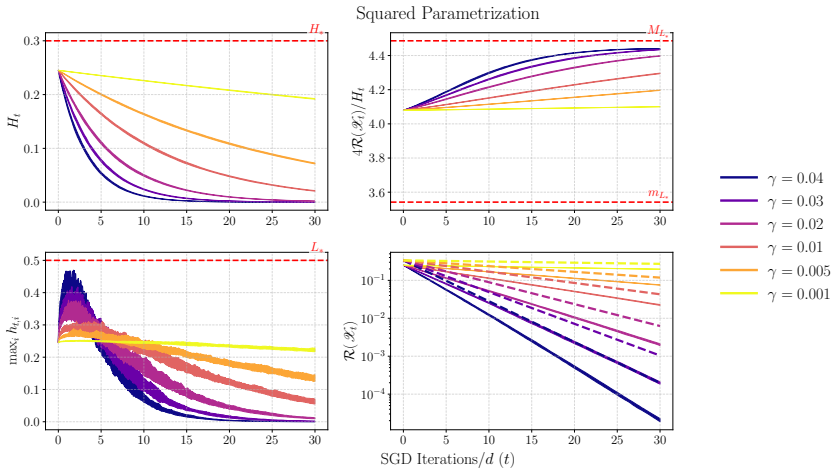
Under a suitable parametrization in the high-dimensional regime, the stochastic dynamics of SGD on diagonal linear networks are globally well posed and converge exponentially fast to zero risk with high probability, yielding a fully explicit non-asymptotic description of their long-time behavior. This is achieved through an SDE approximation that decouples the drift from the gradient noise and a deterministic PDE that propagates the state to characterize observables like risk.
What carries the argument
The stochastic differential equation approximation in the high-dimensional limit, which explicitly decouples the drift from the gradient noise and allows derivation of a deterministic PDE for observable statistics.
If this is right
- The time evolution of risk, curvature, and other optimality metrics can be characterized explicitly via the PDE solution.
- The long-time behavior admits a fully explicit non-asymptotic description.
- Global well-posedness holds for the stochastic dynamics under the chosen parametrization.
- Convergence to zero risk occurs exponentially fast with high probability.
Where Pith is reading between the lines
- This framework might be extended to analyze other simplified neural network models beyond diagonal linear networks.
- Connections to generalization properties could be explored by studying how the risk evolution relates to test performance.
- Numerical experiments comparing discrete SGD to the SDE in finite but large dimensions would validate the approximation quality.
Load-bearing premise
The high-dimensional regime together with the specific scaling for the diagonal linear network must hold to keep the SDE approximation valid and enable the exponential convergence.
What would settle it
Simulations showing that in high-dimensional settings the discrete SGD iterates do not converge exponentially to zero risk or fail to match the SDE predictions would falsify the claims.
Figures




read the original abstract
Understanding the behavior of stochastic gradient methods is a central problem in modern machine learning. Recent work has highlighted diagonal linear networks as a simplified yet expressive setting for analyzing the optimization and generalization properties of neural models. In this work, we show that in the high-dimensional regime, stochastic gradient descent on diagonal linear networks is well-approximated by continuous dynamics governed by a stochastic differential equation (SDE), which explicitly decouples the drift from the gradient noise. We further derive a deterministic partial differential equation whose solution propagates the relevant state of the iterates and characterizes the time evolution of a broad class of observable statistics, including the risk, curvature, and other metrics for optimality. Finally, we show that, under a suitable parametrization, the stochastic dynamics are globally well posed and converge exponentially fast to zero risk with high probability, yielding a fully explicit non-asymptotic description of their long-time behavior. Numerical simulations corroborate our theoretical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies SGD on diagonal linear networks in the high-dimensional regime. It derives an SDE approximation that decouples the deterministic drift from gradient noise, obtains a deterministic PDE whose solution tracks the evolution of observables such as risk and curvature, and proves that under a suitable parametrization the stochastic dynamics are globally well-posed and converge exponentially fast to zero risk with high probability, furnishing an explicit non-asymptotic long-time characterization. Numerical simulations are presented in support of the theory.
Significance. If the SDE and PDE derivations are rigorous and the exponential convergence holds, the work supplies a concrete, non-asymptotic description of SGD dynamics in a tractable neural-network model. The explicit rates and the decoupling of drift from noise are potentially useful for understanding optimization and generalization in high dimensions. The combination of stochastic analysis with a deterministic PDE limit is a methodological strength when the approximations are justified with error bounds.
major comments (2)
- [§4, Theorem 4.3] §4, Theorem 4.3 (or the main convergence statement): global well-posedness and the exponential convergence rate to zero risk are obtained only after imposing the specific high-dimensional scaling and parametrization (initialization variance, step-size scaling, width-to-dimension ratio). The manuscript does not show that this scaling is essentially minimal; a constant-factor relaxation appears to violate the linear-growth or Lipschitz conditions used for the SDE and to make the fluctuation terms order-1, breaking the explicit long-time description. A sensitivity analysis or explicit counter-example for nearby scalings would be required to substantiate that the claimed regime is the natural one rather than a convenient choice.
- [§3.1, Eq. (8)–(10)] §3.1, Eq. (8)–(10): the SDE approximation is stated to decouple drift from gradient noise under the high-dimensional limit, yet the error bound between the discrete SGD trajectory and the SDE solution is not quantified in terms of the scaling parameters. Without an explicit rate that remains small when the scaling is held fixed, it is unclear whether the subsequent PDE and convergence analysis inherit a controllable approximation error.
minor comments (2)
- [§2] Notation for the diagonal entries and the high-dimensional scaling parameters is introduced in §2 but reused with different normalizations in §3 and §5; a single consolidated table of symbols and scalings would improve readability.
- [§6] The numerical experiments in §6 report risk curves but do not overlay the predicted exponential rate or the PDE solution; adding these overlays would make the corroboration more direct.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We appreciate the recognition of the methodological strengths and the constructive criticism regarding the scaling assumptions and approximation errors. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to implement.
read point-by-point responses
-
Referee: [§4, Theorem 4.3] §4, Theorem 4.3 (or the main convergence statement): global well-posedness and the exponential convergence rate to zero risk are obtained only after imposing the specific high-dimensional scaling and parametrization (initialization variance, step-size scaling, width-to-dimension ratio). The manuscript does not show that this scaling is essentially minimal; a constant-factor relaxation appears to violate the linear-growth or Lipschitz conditions used for the SDE and to make the fluctuation terms order-1, breaking the explicit long-time description. A sensitivity analysis or explicit counter-example for nearby scalings would be required to substantiate that the claimed regime is the natural one rather than a convenient choice.
Authors: We agree that the results rely on a specific scaling regime that ensures the desired decoupling and well-posedness. This scaling is selected because it allows the noise terms to be of constant order while permitting an explicit analysis of the long-time behavior. We will revise the manuscript to include a more detailed discussion in Section 4 explaining the motivation for this parametrization, including how it arises naturally from balancing the high-dimensional effects. However, conducting a full sensitivity analysis or providing explicit counterexamples for relaxed scalings would involve deriving alternative bounds and possibly new counterexamples, which we view as an interesting direction for future research rather than a necessary addition to the current work. We believe the chosen regime is natural for obtaining the explicit non-asymptotic characterization claimed. revision: partial
-
Referee: [§3.1, Eq. (8)–(10)] §3.1, Eq. (8)–(10): the SDE approximation is stated to decouple drift from gradient noise under the high-dimensional limit, yet the error bound between the discrete SGD trajectory and the SDE solution is not quantified in terms of the scaling parameters. Without an explicit rate that remains small when the scaling is held fixed, it is unclear whether the subsequent PDE and convergence analysis inherit a controllable approximation error.
Authors: This is a valid concern. In the current manuscript, the SDE approximation is justified in the high-dimensional limit, but we did not provide explicit quantitative error bounds. In the revised version, we will add a theorem or proposition in Section 3 that quantifies the approximation error between the SGD iterates and the SDE solution. Specifically, we will show that the error is bounded by a term that vanishes as the dimension increases, remaining small under the fixed scaling parameters for sufficiently large dimensions. This will ensure that the error propagates controllably through the PDE analysis and does not affect the exponential convergence result up to negligible terms. We thank the referee for pointing this out, as it strengthens the rigor of the presentation. revision: yes
- A comprehensive sensitivity analysis or explicit counter-examples for scalings outside the considered regime would require extensive new theoretical developments and is left for future work.
Circularity Check
No circularity: SDE/PDE derivations and convergence claims are independent of inputs.
full rationale
The paper derives an SDE approximation to SGD in the high-dimensional regime, then a deterministic PDE for observables, and finally proves global well-posedness plus exponential convergence to zero risk under a suitable parametrization. These steps are presented as derived results from the model dynamics rather than tautological restatements. No quoted equations reduce a prediction to a fitted input by construction, no self-citation chain bears the central claim, and the parametrization is an enabling assumption whose necessity is analyzed separately from the derivation itself. The analysis remains self-contained against external benchmarks such as the underlying SGD process.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
homogenized SGD SDE (4) and deterministic PDE (21) for resolvent statistic S(t,z) yielding risk/curvature curves
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
exponential convergence R(Xt) ≤ C e^{-μ t} under squared parametrization and small γ (Thm 3.9)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A Modern Look at the Relationship between Sharpness and Generalization
Maksym Andriushchenko, Francesco Croce, Maximilian Müller, Matthias Hein, and Nicolas Flammarion. A Modern Look at the Relationship between Sharpness and Generalization. InProceedings of the 40th International Conference on Machine Learning, pages 840–902. PMLR, 2023
work page 2023
-
[2]
SGD with Large Step Sizes Learns Sparse Features
Maksym Andriushchenko, Aditya Vardhan Varre, Loucas Pillaud-Vivien, and Nicolas Flammarion. SGD with Large Step Sizes Learns Sparse Features. InProceedings of the 40th International Conference on Machine Learning, pages 903–925. PMLR, 2023
work page 2023
-
[3]
Escaping mediocrity: How two-layer networks learn hard generalized linear models with SGD
Luca Arnaboldi, Florent Krzakala, Bruno Loureiro, and Ludovic Stephan. Escaping mediocrity: How two-layer networks learn hard generalized linear models with SGD. InOPT2023: 15th Annual Workshop on Optimization for Machine Learning, 2023. arXiv preprint
work page 2023
-
[4]
Luca Arnaboldi, Ludovic Stephan, Florent Krzakala, and Bruno Loureiro. From high-dimensional & mean-field dynamics to dimensionless ODEs: A unifying approach to SGD in two-layers networks. In Proceedings of Thirty Sixth Conference on Learning Theory, pages 1199–1227. PMLR, 2023
work page 2023
-
[5]
Asymptotics of SGD in sequence-single index models and single-layer attention networks
Luca Arnaboldi, Bruno Loureiro, Ludovic Stephan, Florent Krzakala, and Lenka Zdeborova. Asymptotics of SGD in sequence-single index models and single-layer attention networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[6]
High-dimensional limit theorems for SGD: Effective dynamics and critical scaling
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. High-dimensional limit theorems for SGD: Effective dynamics and critical scaling. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
work page 2022
-
[7]
Woodworth, Nathan Srebro, Amir Globerson, and Daniel Soudry
Shahar Azulay, Edward Moroshko, Mor Shpigel Nacson, Blake E. Woodworth, Nathan Srebro, Amir Globerson, and Daniel Soudry. On the Implicit Bias of Initialization Shape: Beyond Infinitesimal Mirror Descent. InProceedings of the 38th International Conference on Machine Learning, pages 468–477. PMLR, 2021
work page 2021
-
[8]
Krishnakumar Balasubramanian, Promit Ghosal, and Ye He. High-dimensional scaling limits and fluctuations of online least-squares SGD with smooth covariance.The Annals of Applied Probability, 35 (5), 2025. ISSN 1050-5164. doi: 10.1214/24-AAP2123
-
[9]
Nicholas Barnfield, Hugo Cui, and Yue M. Lu. High-dimensional analysis of single-layer attention for sparse-token classification. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[10]
On-Line Learning with a Perceptron.Europhysics Letters (EPL), 28(7):525–530,
M Biehl and P Riegler. On-Line Learning with a Perceptron.Europhysics Letters (EPL), 28(7):525–530,
-
[11]
doi: 10.1209/0295-5075/28/7/012
ISSN 0295-5075, 1286-4854. doi: 10.1209/0295-5075/28/7/012. 17
-
[12]
M Biehl and H Schwarze. Learning by on-line gradient descent.Journal of Physics A: Mathematical and General, 28(3):643–656, 1995. ISSN 0305-4470, 1361-6447. doi: 10.1088/0305-4470/28/3/018
-
[13]
The high-dimensional asymptotics of first order methods with random data, 2021
Michael Celentano, Chen Cheng, and Andrea Montanari. The high-dimensional asymptotics of first order methods with random data, 2021
work page 2021
-
[14]
Zico Kolter, and Ameet Talwalkar
Jeremy Cohen, Simran Kaur, Yuanzhi Li, J. Zico Kolter, and Ameet Talwalkar. Gradient Descent on Neural Networks Typically Occurs at the Edge of Stability. InInternational Conference on Learning Representations, 2021
work page 2021
-
[15]
High-dimensional limit of one-pass SGD on least squares
Elizabeth Collins–Woodfin and Elliot Paquette. High-dimensional limit of one-pass SGD on least squares. Electronic Communications in Probability, 29(none), 2024. ISSN 1083-589X. doi: 10.1214/23-ECP571
-
[16]
Elizabeth Collins-Woodfin, Courtney Paquette, Elliot Paquette, and Inbar Seroussi. Hitting the High- dimensional notes: An ODE for SGD learning dynamics on GLMs and multi-index models.Information and Inference: A Journal of the IMA, 13(4):iaae028, 2024. ISSN 2049-8772. doi: 10.1093/imaiai/iaae028
-
[17]
The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms
Elizabeth Collins-Woodfin, Inbar Seroussi, Begoña García Malaxechebarría, Andrew Mackenzie, Elliot Paquette, and Courtney Paquette. The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[18]
Adaptive Methods through the Lens of SDEs: Theoretical Insights on the Role of Noise
Enea Monzio Compagnoni, Tianlin Liu, Rustem Islamov, Frank Norbert Proske, Antonio Orvieto, and Aurelien Lucchi. Adaptive Methods through the Lens of SDEs: Theoretical Insights on the Role of Noise. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[19]
Alex Damian, Eshaan Nichani, Rong Ge, and Jason D Lee. Smoothing the Landscape Boosts the Signal for SGD: Optimal Sample Complexity for Learning Single Index Models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 752–784. Curran Associates, Inc., 2023
work page 2023
-
[20]
Lijun Ding, Dmitriy Drusvyatskiy, Maryam Fazel, and Zaid Harchaoui. Flat minima generalize for low-rank matrix recovery.Information and Inference: A Journal of the IMA, 13(2):iaae009, 2024. ISSN 2049-8772. doi: 10.1093/imaiai/iaae009
-
[21]
Stewart N. Ethier and Thomas G. Kurtz.Markov Processes: Characterization and Convergence. Wiley Series in Probability and Mathematical Statistics. Wiley-Interscience, Hoboken, NJ, 1986. ISBN 978-0-470-31665-8 978-0-470-31732-7. doi: 10.1002/9780470316658
-
[22]
(S)GD over Diagonal Linear Networks: Implicit bias, Large Stepsizes and Edge of Stability
Mathieu Even, Scott Pesme, Suriya Gunasekar, and Nicolas Flammarion. (S)GD over Diagonal Linear Networks: Implicit bias, Large Stepsizes and Edge of Stability. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 29406–29448. Curran Associates, Inc., 2023
work page 2023
-
[23]
Cédric Gerbelot, Emanuele Troiani, Francesca Mignacco, Florent Krzakala, and Lenka Zdeborová. Rigorous Dynamical Mean-Field Theory for Stochastic Gradient Descent Methods.SIAM Journal on Mathematics of Data Science, 6(2):400–427, 2024. doi: 10.1137/23M1594388
-
[24]
Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup
Sebastian Goldt, Madhu Advani, Andrew Saxe, Florent Krzakala, and Lenka Zdeborová. Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[25]
Sebastian Goldt, Marc Mézard, Florent Krzakala, and Lenka Zdeborová. Modeling the Influence of Data Structure on Learning in Neural Networks: The Hidden Manifold Model.Physical Review X, 10(4): 041044, 2020. ISSN 2160-3308. doi: 10.1103/PhysRevX.10.041044
-
[26]
The Gaussian equivalence of generative models for learning with shallow neural networks
Sebastian Goldt, Bruno Loureiro, Galen Reeves, Florent Krzakala, Marc Mezard, and Lenka Zdeborova. The Gaussian equivalence of generative models for learning with shallow neural networks. InProceedings of the 2nd Mathematical and Scientific Machine Learning Conference, pages 426–471. PMLR, 2022. 18
work page 2022
-
[27]
HaoChen, Colin Wei, Jason Lee, and Tengyu Ma
Jeff Z. HaoChen, Colin Wei, Jason Lee, and Tengyu Ma. Shape Matters: Understanding the Implicit Bias of the Noise Covariance. InProceedings of Thirty Fourth Conference on Learning Theory, pages 2315–2357. PMLR, 2021
work page 2021
-
[28]
Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence
Fengxiang He, Tongliang Liu, and Dacheng Tao. Control Batch Size and Learning Rate to Generalize Well: Theoretical and Empirical Evidence. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[29]
Elad Hoffer, Itay Hubara, and Daniel Soudry. Train longer, generalize better: Closing the generalization gap in large batch training of neural networks. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[30]
On the Relation Between the Sharpest Directions of DNN Loss and the SGD Step Length
Stanisław Jastrzębski, Zachary Kenton, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amost Storkey. On the Relation Between the Sharpest Directions of DNN Loss and the SGD Step Length. InInternational Conference on Learning Representations, 2019
work page 2019
-
[31]
Miller, and Michael Shvartsman
Dayal Singh Kalra, Jean-Christophe Gagnon-Audet, Andrey Gromov, Ishita Mediratta, Kelvin Niu, Alexander H. Miller, and Michael Shvartsman. A Scalable Measure of Loss Landscape Curvature for Analyzing the Training Dynamics of LLMs, 2026
work page 2026
-
[32]
Varun Kanade, Patrick Rebeschini, and Tomas Vaškevičius. The statistical complexity of early-stopped mirror descent.Information and Inference: A Journal of the IMA, 12(4):3010–3041, 2023. ISSN 2049-8772. doi: 10.1093/imaiai/iaad047
-
[33]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. In International Conference on Learning Representations, 2017
work page 2017
-
[34]
Bobby Kleinberg, Yuanzhi Li, and Yang Yuan. An Alternative View: When Does SGD Escape Local Minima? InProceedings of the 35th International Conference on Machine Learning, pages 2698–2707. PMLR, 2018
work page 2018
-
[35]
Harold J. Kushner and Dean S. Clark.Weak Convergence for Unconstrained Systems, volume 26, pages 106–157. Springer New York, New York, NY, 1978. ISBN 978-0-387-90341-5 978-1-4684-9352-8. doi: 10.1007/978-1-4684-9352-8_4
-
[36]
Trajectory of Mini-Batch Momentum: Batch Size Saturation and Convergence in High Dimensions
Kiwon Lee, Andrew Nicholas Cheng, Elliot Paquette, and Courtney Paquette. Trajectory of Mini-Batch Momentum: Batch Size Saturation and Convergence in High Dimensions. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
work page 2022
-
[37]
Qianxiao Li, Cheng Tai, and Weinan E. Stochastic Modified Equations and Dynamics of Stochastic Gradient Algorithms I: Mathematical Foundations.Journal of Machine Learning Research, 20(40):1–47, 2019
work page 2019
-
[38]
A Minimalist Example of Edge-of-Stability and Progressive Sharpening
Liming Liu, Zixuan Zhang, Simon Shaolei Du, and Tuo Zhao. A Minimalist Example of Edge-of-Stability and Progressive Sharpening. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[39]
On progressive sharpening, flat minima and generalisation, 2023
Lachlan Ewen MacDonald, Jack Valmadre, and Simon Lucey. On progressive sharpening, flat minima and generalisation, 2023
work page 2023
-
[40]
On the SDEs and Scaling Rules for Adaptive Gradient Algorithms
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora. On the SDEs and Scaling Rules for Adaptive Gradient Algorithms. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
work page 2022
-
[41]
Dynamical mean- field theory for stochastic gradient descent in Gaussian mixture classification
Francesca Mignacco, Florent Krzakala, Pierfrancesco Urbani, and Lenka Zdeborová. Dynamical mean- field theory for stochastic gradient descent in Gaussian mixture classification. InAdvances in Neural Information Processing Systems, volume 33, pages 9540–9550. Curran Associates, Inc., 2020. 19
work page 2020
-
[42]
Alireza Mousavi-Hosseini, Sejun Park, Manuela Girotti, Ioannis Mitliagkas, and Murat A. Erdogdu. Neural Networks Efficiently Learn Low-Dimensional Representations with SGD. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[43]
Implicit Bias of the Step Size in Linear Diagonal Neural Networks
Mor Shpigel Nacson, Kavya Ravichandran, Nathan Srebro, and Daniel Soudry. Implicit Bias of the Step Size in Linear Diagonal Neural Networks. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learni...
work page 2022
-
[44]
SGD in the Large: Average- case Analysis, Asymptotics, and Stepsize Criticality
Courtney Paquette, Kiwon Lee, Fabian Pedregosa, and Elliot Paquette. SGD in the Large: Average- case Analysis, Asymptotics, and Stepsize Criticality. In Mikhail Belkin and Samory Kpotufe, editors, Proceedings of Thirty Fourth Conference on Learning Theory, volume 134 ofProceedings of Machine Learning Research, pages 3548–3626. PMLR, 2021
work page 2021
-
[45]
Courtney Paquette, Elliot Paquette, Ben Adlam, and Jeffrey Pennington. Homogenization of SGD in high-dimensions: Exact dynamics and generalization properties.Mathematical Programming, 214(1-2): 1–90, 2025. ISSN 0025-5610, 1436-4646. doi: 10.1007/s10107-024-02171-3
-
[46]
Implicit Bias of SGD for Diagonal Linear Networks: A Provable Benefit of Stochasticity
Scott Pesme, Loucas Pillaud-Vivien, and Nicolas Flammarion. Implicit Bias of SGD for Diagonal Linear Networks: A Provable Benefit of Stochasticity. InAdvances in Neural Information Processing Systems, volume 34, pages 29218–29230. Curran Associates, Inc., 2021
work page 2021
-
[47]
Dynamics of On-Line Gradient Descent Learning for Multilayer Neural Networks
David Saad and Sara Solla. Dynamics of On-Line Gradient Descent Learning for Multilayer Neural Networks. InAdvances in Neural Information Processing Systems, volume 8. MIT Press, 1995
work page 1995
-
[48]
David Saad and Sara A. Solla. Exact Solution for On-Line Learning in Multilayer Neural Networks. Physical Review Letters, 74(21):4337–4340, 1995. ISSN 0031-9007, 1079-7114. doi: 10.1103/PhysRevLett. 74.4337
-
[49]
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
work page 2018
-
[50]
SGD vs GD: Rank Deficiency in Linear Networks
Aditya Varre, Margarita Sagitova, and Nicolas Flammarion. SGD vs GD: Rank Deficiency in Linear Networks. InHigh-Dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning, 2024
work page 2024
-
[51]
Implicit Regularization for Optimal Sparse Recovery
Tomas Vaskevicius, Varun Kanade, and Patrick Rebeschini. Implicit Regularization for Optimal Sparse Recovery. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[52]
Label noise (stochastic) gradient descent implicitly solves the Lasso for quadratic parametrisation
Loucas Pillaud Vivien, Julien Reygner, and Nicolas Flammarion. Label noise (stochastic) gradient descent implicitly solves the Lasso for quadratic parametrisation. InProceedings of Thirty Fifth Conference on Learning Theory, pages 2127–2159. PMLR, 2022
work page 2022
-
[53]
Chuang Wang, Jonathan Mattingly, and Yue M. Lu. Scaling Limit: Exact and Tractable Analysis of Online Learning Algorithms with Applications to Regularized Regression and PCA, 2017
work page 2017
-
[54]
A Solvable High-Dimensional Model of GAN
Chuang Wang, Hong Hu, and Yue Lu. A Solvable High-Dimensional Model of GAN. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[55]
Kaiyue Wen, Tengyu Ma, and Zhiyuan Li. How Sharpness-Aware Minimization Minimizes Sharpness? InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[56]
Lee, Edward Moroshko, Pedro Savarese, Itay Golan, Daniel Soudry, and Nathan Srebro
Blake Woodworth, Suriya Gunasekar, Jason D. Lee, Edward Moroshko, Pedro Savarese, Itay Golan, Daniel Soudry, and Nathan Srebro. Kernel and Rich Regimes in Overparametrized Models. InProceedings of Thirty Third Conference on Learning Theory, pages 3635–3673. PMLR, 2020. 20
work page 2020
-
[57]
Geonhui Yoo, Minhak Song, and Chulhee Yun. Understanding Sharpness Dynamics in NN Training with a Minimalist Example: The Effects of Dataset Difficulty, Depth, Stochasticity, and More. In Forty-Second International Conference on Machine Learning, 2025
work page 2025
-
[58]
Yuki Yoshida and Masato Okada. Data-Dependence of Plateau Phenomenon in Learning with Neural Network — Statistical Mechanical Analysis. InAdvances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
work page 2019
-
[59]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. InInternational Conference on Learning Representations, 2017
work page 2017
-
[60]
Libin Zhu, Chaoyue Liu, Adityanarayanan Radhakrishnan, and Mikhail Belkin. Catapults in SGD: Spikes in the training loss and their impact on generalization through feature learning. InProceedings of the 41st International Conference on Machine Learning, ICML’24, Vienna, Austria, 2024. JMLR.org. 21 Outline of the paper.The remainder of the article is struc...
work page 2024
-
[61]
Appendix A collects notation and auxiliary tools used throughout the proofs. It fixes our conventions for complex-valued tensor products, coordinate contractions, and tensor norms; records derivative computations for the special functionsψ,Ψ, and S appearing in the proof of Theorem 3.7; and recalls the concentration and pseudo-Lipschitz estimates used in ...
-
[62]
Appendix B develops the main dynamical argument. It introduces the partial integro-differential equation (33) and the notion of approximate solutions, proves a stability principle for these solutions, and applies it to the resolvent statisticS along SGD and homogenized SGD. This yields Theorem B.7; the result is then transferred to general statistics sati...
-
[63]
Appendix C proves that the resolvent statisticst7→S (x⌊td⌋,· )and t7→S (Xt,· ), associated respectively with SGD and homogenized SGD(14), are approximate solutions of the partial integro-differential equation(33). The proof uses Doob/Itô decompositions, a net argument over the fixed contour, and martingale and Taylor-error bounds
-
[64]
Appendix D studies the homogenized SDE in the isotropic squared-parameterization setting. It introduces an empirical entropy adapted to the coordinatewise dynamics, proves an exact entropy SDE and barrier estimates, and uses an exponential supermartingale argument to obtain high-probability global existence and exponential decay of the risk. The section a...
-
[65]
Appendix E presents key examples illustrating our concentration risk framework
-
[66]
Contents 1 Introduction 1 1.1 Literature Review
Appendix F provides additional details on the numerical simulations used to produce the figures in the main text. Contents 1 Introduction 1 1.1 Literature Review . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 1.2 High-dimensional Model Structure . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.3 Algorithm Formulat...
-
[67]
On the other hand, sinceτM+1,0 = t < ΘM,η, then either S(x⌊td⌋,·) Γ ⩾M or ∥S(Xt,·)∥ Γ ⩾M and thensup ˆB /∈U B(x⌊td⌋)− ˆB > ηorsup ˆB /∈U B(Xt)− ˆB > η. Now we consider cases. Suppose∥S(Xt,·)∥ Γ ⩾M + 1. Then ∥S(Xt,·)∥ Γ cannot be less than or equal to M so it must have been that S(x⌊td⌋,·) Γ ⩽M . Since t = τM+1,0, working on the event that (54) occurs, we ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.