GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction
Pith reviewed 2026-05-20 13:44 UTC · model grok-4.3
The pith
GeoHand adapts geometric priors from a frozen scene estimator to resolve ambiguities in monocular 3D hand reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GeoHand unlocks high-quality geometric priors from a frozen foundational monocular geometry estimator (MoGe2). It introduces a map-level GeoAdapter to recalibrate the spatial features for detailed hand reconstruction, employs a gated cross-modal token fusion strategy to integrate the adapted priors without overwhelming intrinsic RGB appearance cues, and designs a Keypoint-Queried Iterative Refiner (KQIR) that uses projected joint locations to query geometry-aware image features for spatial correction.
What carries the argument
The map-level GeoAdapter that recalibrates spatial features from the general-scene estimator for hand-specific use.
If this is right
- Global geometric disambiguation combined with local keypoint-driven refinement produces more accurate 3D hands on FreiHAND, DexYCB, and HO3Dv3.
- The same pipeline improves results particularly when self-occlusions or hand-object contacts are present.
- Gated fusion prevents the added geometric priors from overwriting useful appearance information.
- Iterative querying of image features at projected joint locations corrects local articulation errors.
Where Pith is reading between the lines
- The same adapter-and-fusion pattern could transfer geometric priors to other articulated objects such as bodies or tools.
- Making the adapter learnable end-to-end rather than map-level might further reduce domain gap between scene geometry and hand geometry.
- The method implies that frozen foundation geometry models can be specialized for narrow tasks with far less data than training a hand-specific estimator from scratch.
Load-bearing premise
The spatial features from the frozen general-scene estimator contain information that can be recalibrated for fine-grained hand geometry without destroying useful cues.
What would settle it
Running the pipeline with the GeoAdapter and geometric priors removed and observing no gain or a clear drop in accuracy on occluded or hand-object test cases relative to an RGB-only baseline.
Figures






read the original abstract
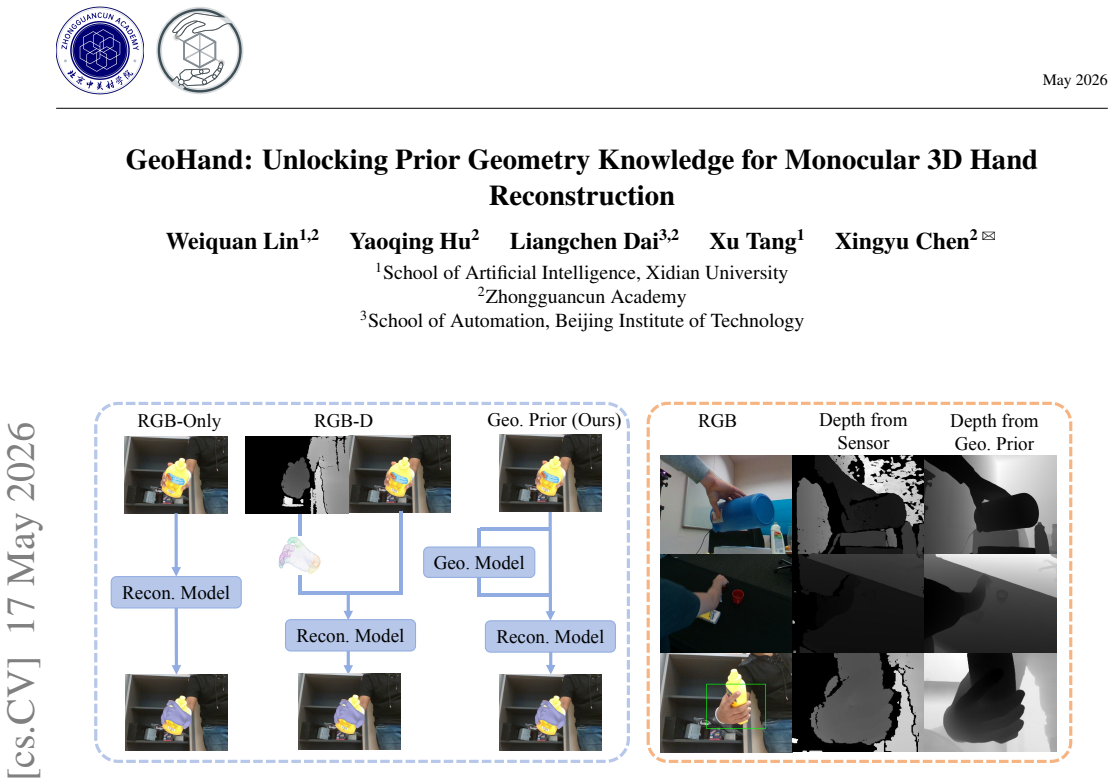
Monocular 3D hand reconstruction is intrinsically a geometric problem, yet RGB appearance features alone often struggle to resolve severe ambiguities caused by self-occlusions and hand-object interactions. While introducing depth can explicitly provide spatial cues, raw sensor-captured depth maps are extensively noisy and incomplete, limiting their usefulness for fine-grained hand reconstruction. To bridge this gap, we propose GeoHand, a novel framework that unlocks high-quality geometric priors from a frozen foundational monocular geometry estimator (MoGe2). Recognizing that these priors are oriented toward general scenes, we introduce a map-level GeoAdapter to recalibrate the spatial features, specifically adapting them for detailed hand reconstruction. Furthermore, to systematically integrate these adapted priors without overwhelming intrinsic RGB appearance cues, we employ a gated cross-modal token fusion strategy. Finally, to secure precise local articulation, we design a Keypoint-Queried Iterative Refiner (KQIR) that uses projected joint locations to query geometry-aware image features for spatial correction. By combining global geometric disambiguation with local refinement in a unified pipeline, GeoHand achieves state-of-the-art performance on FreiHAND, DexYCB, and HO3Dv3, especially under severe occlusions and hand-object interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GeoHand, a framework for monocular 3D hand reconstruction that extracts geometric priors from a frozen general-scene estimator (MoGe2), adapts them via a map-level GeoAdapter for hand-specific use, integrates them with RGB cues through gated cross-modal token fusion, and refines local articulation with a Keypoint-Queried Iterative Refiner (KQIR). The central claim is that this unified pipeline achieves state-of-the-art results on FreiHAND, DexYCB, and HO3Dv3, with particular gains under severe self-occlusions and hand-object interactions.
Significance. If the empirical claims hold after verification, the work would be moderately significant for computer vision: it offers a concrete demonstration of adapting foundational monocular geometry models to a specialized fine-grained task without sensor depth, potentially improving robustness in occluded and interactive settings. The approach is conceptually straightforward and could inspire similar adapter-based transfers in related reconstruction problems.
major comments (2)
- [Section 3.2] Section 3.2 (GeoAdapter): The claim that the map-level GeoAdapter recalibrates MoGe2 spatial features for detailed hand geometry without eroding occlusion-disambiguation cues is load-bearing for the global disambiguation step, yet the manuscript supplies no feature-map visualizations, correlation analysis between adapted depth maps and ground-truth hand surfaces, or ablation isolating adapter performance specifically on occlusion-heavy frames. Without such evidence the assumption that the adapted priors remain usable remains unverified.
- [Section 4] Section 4 (Experiments): The SOTA claims on FreiHAND, DexYCB, and HO3Dv3, especially on occluded subsets, are presented without error bars, full ablation tables isolating each component (GeoAdapter, gated fusion, KQIR), or implementation details such as training schedules and hyper-parameters. This makes it impossible to confirm that reported gains are robust and attributable to the proposed geometry adaptation rather than other factors.
minor comments (2)
- [Section 3.3] Notation for the gated fusion module is introduced without an explicit equation; adding a compact formulation would improve clarity.
- [Figure 5] Figure captions for qualitative results should explicitly label the occlusion and interaction severity levels shown in each row.
Simulated Author's Rebuttal
We thank the referee for their valuable comments and suggestions. We provide detailed responses to each major comment and have made revisions to the manuscript to address the raised concerns.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (GeoAdapter): The claim that the map-level GeoAdapter recalibrates MoGe2 spatial features for detailed hand geometry without eroding occlusion-disambiguation cues is load-bearing for the global disambiguation step, yet the manuscript supplies no feature-map visualizations, correlation analysis between adapted depth maps and ground-truth hand surfaces, or ablation isolating adapter performance specifically on occlusion-heavy frames. Without such evidence the assumption that the adapted priors remain usable remains unverified.
Authors: We appreciate the referee's observation regarding the need for more direct evidence supporting the GeoAdapter. Although the overall performance improvements on occlusion-heavy scenarios in our experiments suggest the effectiveness of the adapted priors, we acknowledge that explicit visualizations and targeted ablations would provide stronger verification. In the revised manuscript, we have added feature-map visualizations of the original and adapted depth maps, a correlation analysis with ground-truth hand surfaces, and an ablation isolating the GeoAdapter's performance on occlusion-heavy frames. These additions confirm that the occlusion-disambiguation cues are preserved and enhanced for hand-specific reconstruction. revision: yes
-
Referee: [Section 4] Section 4 (Experiments): The SOTA claims on FreiHAND, DexYCB, and HO3Dv3, especially on occluded subsets, are presented without error bars, full ablation tables isolating each component (GeoAdapter, gated fusion, KQIR), or implementation details such as training schedules and hyper-parameters. This makes it impossible to confirm that reported gains are robust and attributable to the proposed geometry adaptation rather than other factors.
Authors: We agree that including error bars, comprehensive ablations, and implementation details is essential for demonstrating the robustness of our results. We have updated the experimental section to include error bars for all quantitative results, expanded the ablation tables to isolate the contributions of the GeoAdapter, gated fusion, and KQIR individually, and provided full details on training schedules, hyper-parameters, and other implementation aspects in the revised manuscript and supplementary material. This allows readers to better assess the attribution of the performance gains to our proposed components. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a pipeline that takes outputs from an external frozen model (MoGe2) as input, applies a map-level GeoAdapter for recalibration, uses gated fusion to integrate with RGB features, and adds a KQIR module for local refinement. No equations, self-citations, or fitted parameters are shown in the provided text that reduce the claimed SOTA performance or geometric disambiguation to a quantity defined by the target metrics or by the authors' own prior results. The central claims rest on the independent utility of the external priors plus standard benchmark evaluation, making the derivation self-contained against external references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geometric priors from a frozen general-scene monocular estimator (MoGe2) contain transferable spatial information that can be recalibrated for detailed hand reconstruction.
invented entities (2)
-
map-level GeoAdapter
no independent evidence
-
Keypoint-Queried Iterative Refiner (KQIR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a map-level GeoAdapter to recalibrate the spatial features... gated cross-modal token fusion strategy... Keypoint-Queried Iterative Refiner (KQIR) that uses projected joint locations to query geometry-aware image features
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GeoHand achieves state-of-the-art performance on FreiHAND, DexYCB, and HO3Dv3, especially under severe occlusions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Frei- hand: A dataset for markerless capture of hand pose and shape from single rgb images
Christian Zimmermann, Duygu Ceylan, Jimei Yang, Bryan Russell, Max Argus, and Thomas Brox. Frei- hand: A dataset for markerless capture of hand pose and shape from single rgb images. InProceedings of the IEEE/CVF international conference on computer vision, pages 813–822, 2019. 10 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction
work page 2019
-
[2]
Mobrecon: Mobile-friendly hand mesh reconstruction from monocular image
Xingyu Chen, Yufeng Liu, Yajiao Dong, Xiong Zhang, Chongyang Ma, Yanmin Xiong, Yuan Zhang, and Xi- aoyan Guo. Mobrecon: Mobile-friendly hand mesh reconstruction from monocular image. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20544–20554, 2022
work page 2022
-
[3]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InPro- ceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 9826–9836, 2024
work page 2024
-
[4]
Expressive body capture: 3d hands, face, and body from a single image
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10975–10985, 2019
work page 2019
-
[5]
Em- bodied hands: Modeling and capturing hands and bodies to- gether
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610, 2022
-
[6]
Keep it smpl: Automatic estimation of 3d human pose and shape from a single image
Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. InEuropean conference on computer vision, pages 561–578. Springer, 2016
work page 2016
-
[7]
Learning to reconstruct 3d hu- man pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d hu- man pose and shape via model-fitting in the loop. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2252–2261, 2019
work page 2019
-
[8]
Hands Deep in Deep Learning for Hand Pose Estimation
Markus Oberweger, Paul Wohlhart, and Vincent Lep- etit. Hands deep in deep learning for hand pose estima- tion.arXiv preprint arXiv:1502.06807, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[9]
3d hand shape and pose from images in the wild
Adnane Boukhayma, Rodrigo de Bem, and Philip HS Torr. 3d hand shape and pose from images in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10843– 10852, 2019
work page 2019
-
[10]
End-to-end hand mesh recovery from a monocular rgb image
Xiong Zhang, Qiang Li, Hong Mo, Wenbo Zhang, and Wen Zheng. End-to-end hand mesh recovery from a monocular rgb image. InProceedings of the IEEE/CVF international conference on computer vision, pages 2354–2364, 2019
work page 2019
-
[11]
Awr: Adaptive weighting regression for 3d hand pose estimation
Weiting Huang, Pengfei Ren, Jingyu Wang, Qi Qi, and Haifeng Sun. Awr: Adaptive weighting regression for 3d hand pose estimation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 11061–11068, 2020
work page 2020
-
[12]
Ganerated hands for real-time 3d hand tracking from monocular rgb
Franziska Mueller, Florian Bernard, Oleksandr Sotny- chenko, Dushyant Mehta, Srinath Sridhar, Dan Casas, and Christian Theobalt. Ganerated hands for real-time 3d hand tracking from monocular rgb. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 49–59, 2018
work page 2018
-
[13]
Weakly- supervised mesh-convolutional hand reconstruction in the wild
Dominik Kulon, Riza Alp Guler, Iasonas Kokkinos, Michael M Bronstein, and Stefanos Zafeiriou. Weakly- supervised mesh-convolutional hand reconstruction in the wild. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 4990–5000, 2020
work page 2020
-
[14]
Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering
Seungryul Baek, Kwang In Kim, and Tae-Kyun Kim. Pushing the envelope for rgb-based dense 3d hand pose estimation via neural rendering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1067–1076, 2019
work page 2019
-
[15]
3d hand shape and pose estimation from a single rgb image
Liuhao Ge, Zhou Ren, Yuncheng Li, Zehao Xue, Yingy- ing Wang, Jianfei Cai, and Junsong Yuan. 3d hand shape and pose estimation from a single rgb image. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10833–10842, 2019
work page 2019
-
[16]
Convolutional mesh regression for single-image human shape reconstruction
Nikos Kolotouros, Georgios Pavlakos, and Kostas Dani- ilidis. Convolutional mesh regression for single-image human shape reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4501–4510, 2019
work page 2019
-
[17]
Camera-space hand mesh recovery via semantic aggregation and adaptive 2d-1d registration
Xingyu Chen, Yufeng Liu, Chongyang Ma, Jianlong Chang, Huayan Wang, Tian Chen, Xiaoyan Guo, Pengfei Wan, and Wen Zheng. Camera-space hand mesh recovery via semantic aggregation and adaptive 2d-1d registration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13274–13283, 2021
work page 2021
-
[18]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 11 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction 16x16 words: Transformers for image recognition at scale.arXiv preprint ar...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[20]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
work page 2021
-
[21]
Wilor: End-to- end 3d hand localization and reconstruction in-the-wild
Rolandos Alexandros Potamias, Jinglei Zhang, Jiankang Deng, and Stefanos Zafeiriou. Wilor: End-to- end 3d hand localization and reconstruction in-the-wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
work page 2025
-
[22]
End-to-end human pose and mesh reconstruction with transformers
Kevin Lin, Lijuan Wang, and Zicheng Liu. End-to-end human pose and mesh reconstruction with transformers. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 1954–1963, 2021
work page 1954
-
[23]
Kevin Lin, Lijuan Wang, and Zicheng Liu. Mesh graphormer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 12939– 12948, 2021
work page 2021
-
[24]
Cross-attention of disentangled modalities for 3d hu- man mesh recovery with transformers
Junhyeong Cho, Kim Youwang, and Tae-Hyun Oh. Cross-attention of disentangled modalities for 3d hu- man mesh recovery with transformers. InEuro- pean Conference on Computer Vision, pages 342–359. Springer, 2022
work page 2022
-
[25]
A simple baseline for efficient hand mesh reconstruction
Zhishan Zhou, Shihao Zhou, Zhi Lv, Minqiang Zou, Yao Tang, and Jiajun Liang. A simple baseline for efficient hand mesh reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1367–1376, 2024
work page 2024
-
[26]
Gyeongsik Moon, Ju Yong Chang, and Kyoung Mu Lee. V2v-posenet: V oxel-to-voxel prediction network for accurate 3d hand and human pose estimation from a single depth map. InProceedings of the IEEE con- ference on computer vision and pattern Recognition, pages 5079–5088, 2018
work page 2018
-
[27]
Dexycb: A benchmark for capturing hand grasping of objects
Yu-Wei Chao, Wei Yang, Yu Xiang, Pavlo Molchanov, Ankur Handa, Jonathan Tremblay, Yashraj S Narang, Karl Van Wyk, Umar Iqbal, Stan Birchfield, et al. Dexycb: A benchmark for capturing hand grasping of objects. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 9044–9053, 2021
work page 2021
-
[28]
Honnotate: A method for 3d annota- tion of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. Honnotate: A method for 3d annota- tion of hand and object poses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
work page 2020
-
[29]
Grab: A dataset of whole-body human grasping of objects
Omid Taheri, Nima Ghorbani, Michael J Black, and Dimitrios Tzionas. Grab: A dataset of whole-body human grasping of objects. InEuropean conference on computer vision, pages 581–600. Springer, 2020
work page 2020
-
[30]
Learning joint reconstruction of hands and manipulated objects
Yana Hasson, Gul Varol, Dimitrios Tzionas, Igor Kale- vatykh, Michael J Black, Ivan Laptev, and Cordelia Schmid. Learning joint reconstruction of hands and manipulated objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11807–11816, 2019
work page 2019
-
[31]
Contactpose: A dataset of grasps with object contact and hand pose
Samarth Brahmbhatt, Chengcheng Tang, Christopher D Twigg, Charles C Kemp, and James Hays. Contactpose: A dataset of grasps with object contact and hand pose. InEuropean Conference on Computer Vision, pages 361–378. Springer, 2020
work page 2020
-
[32]
Keypoint fusion for rgb-d based 3d hand pose esti- mation
Xingyu Liu, Pengfei Ren, Yuanyuan Gao, Jingyu Wang, Haifeng Sun, Qi Qi, Zirui Zhuang, and Jianxin Liao. Keypoint fusion for rgb-d based 3d hand pose esti- mation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 3756–3764, 2024
work page 2024
-
[33]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
work page 2017
-
[34]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
work page 2017
-
[35]
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: 12 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction Unleashing the power of large-scale unlabeled data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
work page 2024
-
[36]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocu- lar geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Learning to estimate 3d hand pose from single rgb images
Christian Zimmermann and Thomas Brox. Learning to estimate 3d hand pose from single rgb images. In Proceedings of the IEEE international conference on computer vision, pages 4903–4911, 2017
work page 2017
-
[38]
Hand pose estimation via latent 2.5 d heatmap regression
Umar Iqbal, Pavlo Molchanov, Thomas Breuel Juergen Gall, and Jan Kautz. Hand pose estimation via latent 2.5 d heatmap regression. InProceedings of the Eu- ropean conference on computer vision (ECCV), pages 118–134, 2018
work page 2018
-
[39]
Weakly-supervised 3d hand pose estimation from monocular rgb images
Yujun Cai, Liuhao Ge, Jianfei Cai, and Junsong Yuan. Weakly-supervised 3d hand pose estimation from monocular rgb images. InProceedings of the Eu- ropean conference on computer vision (ECCV), pages 666–682, 2018
work page 2018
-
[40]
Hand pointnet: 3d hand pose estimation using point sets
Liuhao Ge, Yujun Cai, Junwu Weng, and Junsong Yuan. Hand pointnet: 3d hand pose estimation using point sets. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 8417–8426, 2018
work page 2018
-
[41]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE confer- ence on computer vision and pattern recognition, pages 7122–7131, 2018
work page 2018
-
[42]
Frankmocap: A monocular 3d whole-body pose es- timation system via regression and integration
Yu Rong, Takaaki Shiratori, and Hanbyul Joo. Frankmocap: A monocular 3d whole-body pose es- timation system via regression and integration. InPro- ceedings of the IEEE/CVF International Conference on Computer Vision, pages 1749–1759, 2021
work page 2021
-
[43]
Collaborative learning for hand and object reconstruction with attention-guided graph convolution
Tze Ho Elden Tse, Kwang In Kim, Ales Leonardis, and Hyung Jin Chang. Collaborative learning for hand and object reconstruction with attention-guided graph convolution. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 1664–1674, 2022
work page 2022
-
[44]
Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose
Hongsuk Choi, Gyeongsik Moon, and Kyoung Mu Lee. Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. InEuropean Conference on Computer Vision, pages 769–787. Springer, 2020
work page 2020
-
[45]
Disentangling latent hands for image synthesis and pose estimation
Linlin Yang and Angela Yao. Disentangling latent hands for image synthesis and pose estimation. InPro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 9877–9886, 2019
work page 2019
-
[46]
Densepose: Dense human pose estimation in the wild
Rıza Alp G¨uler, Natalia Neverova, and Iasonas Kokki- nos. Densepose: Dense human pose estimation in the wild. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 7297–7306, 2018
work page 2018
-
[47]
Gyeongsik Moon and Kyoung Mu Lee. I2l-meshnet: Image-to-lixel prediction network for accurate 3d hu- man pose and mesh estimation from a single rgb image. InEuropean Conference on Computer Vision, pages 752–768. Springer, 2020
work page 2020
-
[48]
Probabilistic modeling for human mesh recovery
Nikos Kolotouros, Georgios Pavlakos, Dinesh Jayara- man, and Kostas Daniilidis. Probabilistic modeling for human mesh recovery. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 11605–11614, 2021
work page 2021
-
[49]
Handoccnet: Occlusion-robust 3d hand mesh estimation network
JoonKyu Park, Yeonguk Oh, Gyeongsik Moon, Hong- suk Choi, and Kyoung Mu Lee. Handoccnet: Occlusion-robust 3d hand mesh estimation network. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 1496–1505, 2022
work page 2022
-
[50]
H2onet: Hand-occlusion-and-orientation-aware network for real-time 3d hand mesh reconstruction
Hao Xu, Tianyu Wang, Xiao Tang, and Chi-Wing Fu. H2onet: Hand-occlusion-and-orientation-aware network for real-time 3d hand mesh reconstruction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17048–17058, 2023
work page 2023
-
[51]
First-person hand action benchmark with rgb-d videos and 3d hand pose an- notations
Guillermo Garcia-Hernando, Shanxin Yuan, Seungryul Baek, and Tae-Kyun Kim. First-person hand action benchmark with rgb-d videos and 3d hand pose an- notations. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 409– 419, 2018
work page 2018
-
[52]
Gyeongsik Moon, Shoou-I Yu, He Wen, Takaaki Shira- tori, and Kyoung Mu Lee. Interhand2. 6m: A dataset 13 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction and baseline for 3d interacting hand pose estimation from a single rgb image. InEuropean Conference on Computer Vision, pages 548–564. Springer, 2020
work page 2020
-
[53]
H2o: Two hands manipulating objects for first person interaction recognition
Taein Kwon, Bugra Tekin, Jan St¨uhmer, Federica Bogo, and Marc Pollefeys. H2o: Two hands manipulating objects for first person interaction recognition. InPro- ceedings of the IEEE/CVF international conference on computer vision, pages 10138–10148, 2021
work page 2021
-
[54]
Oakink: A large-scale knowledge repository for understanding hand-object interaction
Lixin Yang, Kailin Li, Xinyu Zhan, Fei Wu, Anran Xu, Liu Liu, and Cewu Lu. Oakink: A large-scale knowledge repository for understanding hand-object interaction. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 20953–20962, 2022
work page 2022
-
[55]
Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation,
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. Dexgrasp- net: A large-scale robotic dexterous grasp dataset for general objects based on simulation.arXiv preprint arXiv:2210.02697, 2022
-
[56]
Contactopt: Optimizing contact to improve grasps
Patrick Grady, Chengcheng Tang, Christopher D Twigg, Minh V o, Samarth Brahmbhatt, and Charles C Kemp. Contactopt: Optimizing contact to improve grasps. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1471–1481, 2021
work page 2021
-
[57]
Grasping field: Learn- ing implicit representations for human grasps
Korrawe Karunratanakul, Adrian Spurr, Zicong Muigai, Otmar Hilliges, and Siyu Tang. Grasping field: Learn- ing implicit representations for human grasps. InInter- national Conference on 3D Vision (3DV), 2020
work page 2020
-
[58]
Interacting at- tention graph for single image two-hand reconstruction
Mengcheng Li, Liang An, Hongwen Zhang, Lianpeng Wu, Feng Chen, Tao Yu, and Yebin Liu. Interacting at- tention graph for single image two-hand reconstruction. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 2761–2770, 2022
work page 2022
-
[59]
Complementing event streams and rgb frames for hand mesh recon- struction
Jianping Jiang, Xinyu Zhou, Bingxuan Wang, Xiaom- ing Deng, Chao Xu, and Boxin Shi. Complementing event streams and rgb frames for hand mesh recon- struction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24944–24954, 2024
work page 2024
-
[60]
Cross-modal deep variational hand pose es- timation
Adrian Spurr, Jie Song, Seonwook Park, and Otmar Hilliges. Cross-modal deep variational hand pose es- timation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 89–98, 2018
work page 2018
-
[61]
Ren´e Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monoc- ular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
work page 2020
-
[62]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9492–9502, 2024
work page 2024
-
[63]
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xi- ang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training super- vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5261–5271, 2025
work page 2025
-
[64]
Contrastive representation learning for hand shape esti- mation
Christian Zimmermann, Max Argus, and Thomas Brox. Contrastive representation learning for hand shape esti- mation. InProceedings of the DAGM German Confer- ence on Pattern Recognition, pages 250–264, 2021
work page 2021
-
[65]
Lixin Yang, Jiasen Li, Wenqiang Xu, Yiqun Diao, and Cewu Lu. Bihand: Recovering hand mesh with multi- stage bisected hourglass networks.arXiv preprint arXiv:2008.05079, 2020
-
[66]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[67]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[68]
Haoye Dong, Aviral Chharia, Wenbo Gou, Fran- cisco Vicente Carrasco, and Fernando De la Torre. Hamba: Single-view 3d hand reconstruction with graph-guided bi-scanning mamba.arXiv preprint arXiv:2407.09646, 2024. 14 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction
-
[69]
Handos: 3d hand reconstruction in one stage
Xingyu Chen, Zhuheng Song, Xiaoke Jiang, Yaoqing Hu, Junzhi Yu, and Lei Zhang. Handos: 3d hand reconstruction in one stage. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17304–17314, 2025
work page 2025
-
[70]
Maskhand: Generative masked modeling for robust hand mesh reconstruc- tion in the wild
Muhammad Usama Saleem, Ekkasit Pinyoanuntapong, Mayur Jagdishbhai Patel, Hongfei Xue, Ahmed Helmy, Srijan Das, and Pu Wang. Maskhand: Generative masked modeling for robust hand mesh reconstruc- tion in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8372–8383, 2025
work page 2025
-
[71]
Haofan Lu, Shuiping Gou, and Ruimin Li. Spmhand: Segmentation-guided progressive multi-path 3d hand pose and shape estimation.IEEE Transactions on Mul- timedia, 26:6822–6833, 2024. 15 GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand Reconstruction Appendix A.1 Detailed Training Objectives GeoHand is optimized using a physically motivated ...
work page 2024
-
[72]
Exploration of Cross-Modal Extraction Limits.Al- though the simple token concatenation and map-level GeoAdapter mechanism have proven highly effective against domain gaps without complex volume-rendering overheads, explicitly exploring more sophisticated mul- timodal Transformer frameworks with cross-attention between appearance tokens and coordinate-boun...
-
[73]
Bounding-Box Reliance vs. End-to-End Synergy. GeoHand functions under a top-down paradigm depen- dent on an independent 2D hand detector’s bounding-box cropping stage. Consequently, final 3D reconstruction quality remains partially bounded by this preprocessing stage. Tightly unifying high-quality object detection within the same ViT-based pipeline would ...
-
[74]
Temporal & Multi-View Contextual Recovery for Oc- clusions.While geometry priors substantially aid oc- cluded interactions, recovering radically invisible topo- logical boundaries remains inherently mathematically impossible from a static single viewpoint alone. Utiliz- ing sequential historical motion context (temporal kine- matic pipelines) or complemen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.